Retour sur l’AWS Summit Paris 2025
Le 9 avril dernier, j’ai eu le plaisir d’assister à l’AWS Summit Paris 2025 au Palais des Congrès. C’était ma deuxième participation à cet événement incontournable dédié au cloud, à la data, et bien sûr, à l’intelligence artificielle générative.
J’y suis allée pour découvrir les dernières tendances, échanger avec d’autres passionnés et approfondir certaines thématiques qui me tiennent à cœur. Ce que je retiens principalement de cette journée, c’est que les deux prochaines années seront marquées par une évolution vers la décentralisation de la donnée, ainsi que par l'importance croissante d’avoir des bases de données SQL distribuées et scalables pour répondre aux besoins d'agilité et de performance des entreprises.
Sessions marquantes auxquelles j'ai participé
Grâce à l’application AWS Events, j’avais planifié mon programme à l’avance en sélectionnant les sessions les plus pertinentes pour moi. L’organisation était fluide, et j’ai apprécié la diversité des thématiques abordées.
REX: L'avenir est à la décentralisation de la donnée — L’approche Data Mesh à La Centrale
Un contexte familier
Comme beaucoup d’entreprises aujourd’hui, La Centrale (leader de la vente de véhicules d’occasion en France) fait face à une explosion du volume de données et à la multiplication des sources. Leur ambition est claire : mieux valoriser leurs données pour :
- suivre leur activité,
- prendre des décisions plus éclairées,
- et construire des produits innovants basés sur la data.
Les limites d’un modèle centralisé
L’entreprise avait d’abord mis en place un data lake centralisé, regroupant toutes les données de l’entreprise (structurées, semi-structurées, non structurées). L’idée était de répondre à tous les besoins à partir de cette plateforme unique.
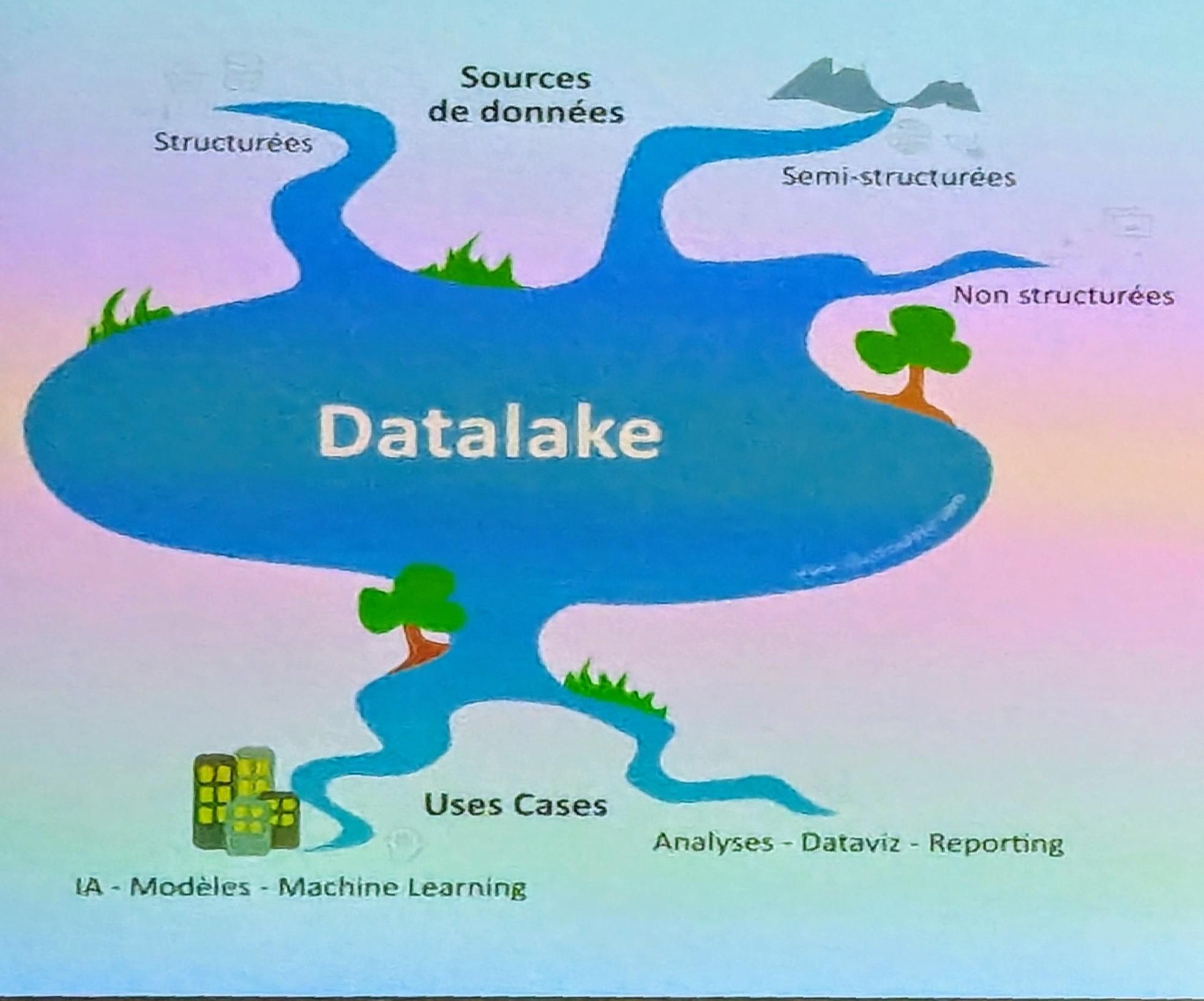
Si l’approche permettait d’agréger toutes les données dans un même espace, elle a rapidement montré ses limites:
- L’équipe data (chargée de la collecte, du traitement et de la mise à disposition des données) devenait un goulot d’étranglement.
- Chaque demande de données passait par elle, ce qui ralentissait les projets.
- Les utilisateurs avaient peu de visibilité sur les données existantes, et il était difficile de les exploiter de manière autonome.
Le passage au Data Mesh
Pour répondre à ces limites, La Centrale a engagé une transformation vers un modèle Data Mesh, structuré autour de quatre piliers :
- La décentralisation des données par domaines métiers.
- Une gestion des données pensées comme des produits.
- Une plateforme en self-service.
- Une gouvernance fédérée.
Une mise en œuvre concrète et progressive
La Centrale a opté pour une transition incrémentale vers le Data Mesh, en construisant les bons outils au fur et à mesure.
Un découpage en domaines métier
Chaque domaine devient responsable de ses propres jeux de données, ce qui rapproche la donnée de celles et ceux qui la comprennent le mieux. Résultat : plus d’implication, de réactivité, et une meilleure qualité.
Une plateforme data en Self-Service
Cette plateforme donne aux équipes les outils pour produire, documenter et surveiller leurs propres Data Products, tout en restant alignées sur les standards de l’entreprise.
Elle permet notamment de :
1- Simplifier la création de Data Products
- Simplifier le process d’historisation des données.
- Offrir plus d’autonomie aux feature teams (également appelées domain teams).
- Standardiser la construction des data products.
2- Monitorer la qualité des données
- Déployer automatiquement les outils de contrôle et de monitoring grâce à une librairie CDK.
- Suivre la qualité des données via Amazon Quicksight pour l’analyse et le monitoring.
- Mettre en place des alertes via AWS Glue Data Quality pour détecter les anomalies.
3- Simplifier l’accès aux données et industrialiser la création des Data Products
- Utiliser DBT Core pour une création simplifiée et l’industrialisation de Datamarts et Datasources.
- Utiliser DBT Cloud pour simplifier l’accès, la collaboration et l’exploitation des données via une UI, une orchestration et un contrôle d’accès.
4- Simplifier la documentation de la donnée
- Générer automatiquement le squelette des documentations avec une librairie CDK dédiée.
- Centraliser la documentation dans un Product Catalog, incluant glossaire, structure des tables et lineage.
Une architecture Data Lake House
Côté infrastructure, l’entreprise a évolué vers une architecture Data Lakehouse, combinant la flexibilité d’un data lake avec la puissance analytique d’un entrepôt de données.

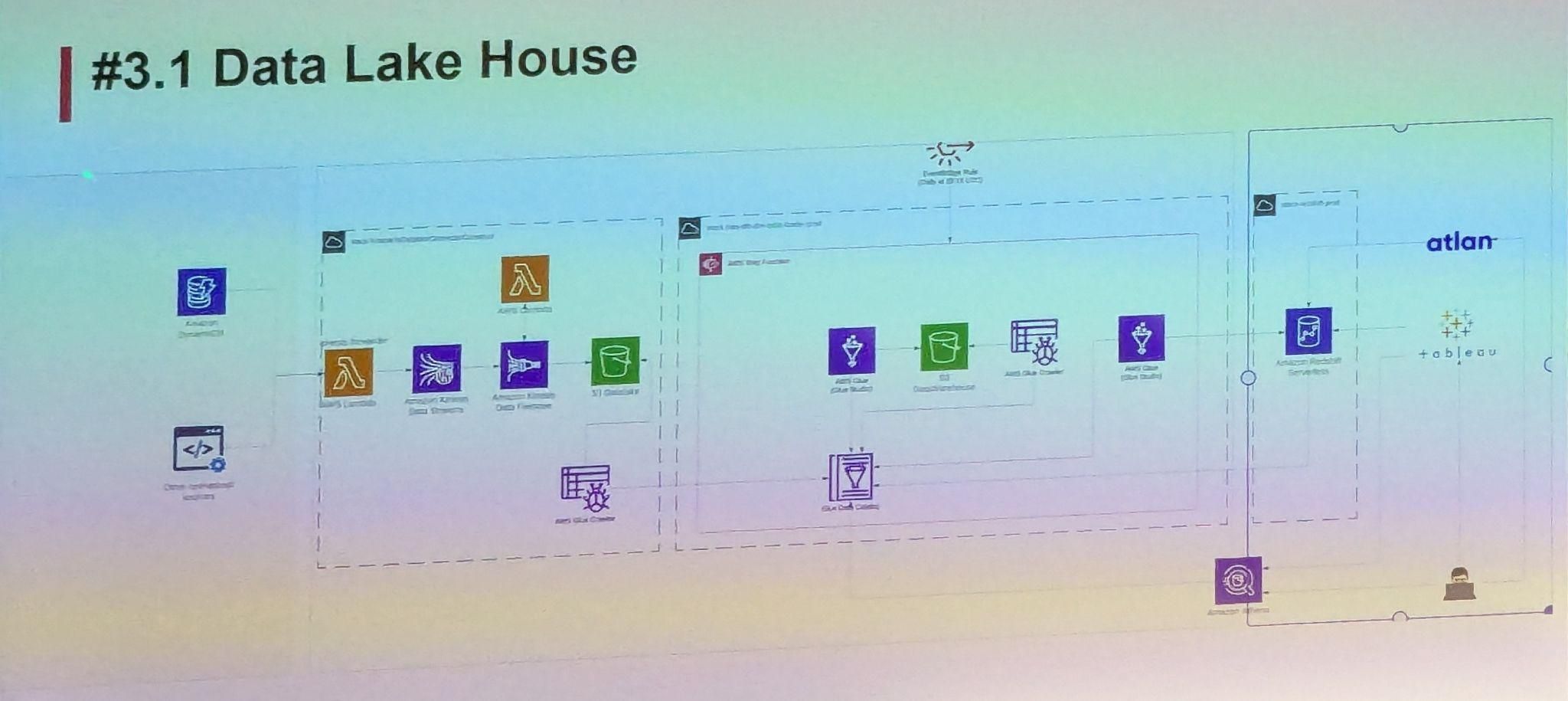
Data Mesh - une transformation culturelle aussi
L’adoption du Data Mesh ne repose pas uniquement sur une évolution technique ou l’ajout de nouveaux outils : elle implique une redéfinition des rôles, des responsabilités et de la culture autour de la donnée.
Dans l’ancien modèle centralisé, la donnée était souvent perçue comme une ressource “technique”, pilotée par une équipe spécialisée. Le Data Mesh vient casser cette logique en réinjectant la responsabilité de la donnée au plus près des métiers.
Dans les Feature Teams:
- Le Data Owner, proche d'un rôle de Product Manager, est responsable de la définition, de la qualité et de la gouvernance de ses Data Products.
- Le Data Product Developer, généralement un développeur généraliste, développe et maintient les Data Products de son périmètre, en s’appuyant sur les outils fournis par la Data Platform.
Au sein de la Data Platform Team:
- Le PO Data joue un rôle transversal. Il accompagne les Feature Teams dans l’adoption du modèle et assure le lien entre les feature teams et l’équipe Data pour l’évolution des outils.
- Le Data Engineer développe, maintient et fait évoluer la Data Platform et les outils et accompagne les feature teams dans l’implémentation technique des Data Products.
En résumé
L’expérience de La Centrale montre que le Data Mesh n’est pas seulement une nouvelle architecture : c’est une transformation organisationnelle, qui redonne aux équipes métier la main sur leurs données et favorise l’agilité à l’échelle de l’entreprise.
REX: Bases de données SQL distribuées et scalables — Aurora DSQL
Parmi les sessions techniques de la journée, celle dédiée à Aurora DSQL une base de données SQL distribuée serverless. Elle a été annoncée à AWS re:Invent qui a eu lieu en décembre 2024. Cette session a soulevé des questionnements sur la gestion des bases de données relationnelles à l’échelle : comment allier cohérence forte et scalabilité multirégionale, tout en limitant la charge opérationnelle ?
Une architecture multirégionale active-active
Aurora DSQL permet une disponibilité quasi permanente (99.999%), avec une architecture active-active entre plusieurs régions. Les applications peuvent écrire et lire depuis n’importe quelle région, tout en ayant l’assurance que les données sont fortement consistantes d’un point de terminaison à l’autre. Il n’y a plus de notion de primaire/secondaire : toutes les régions sont égales.
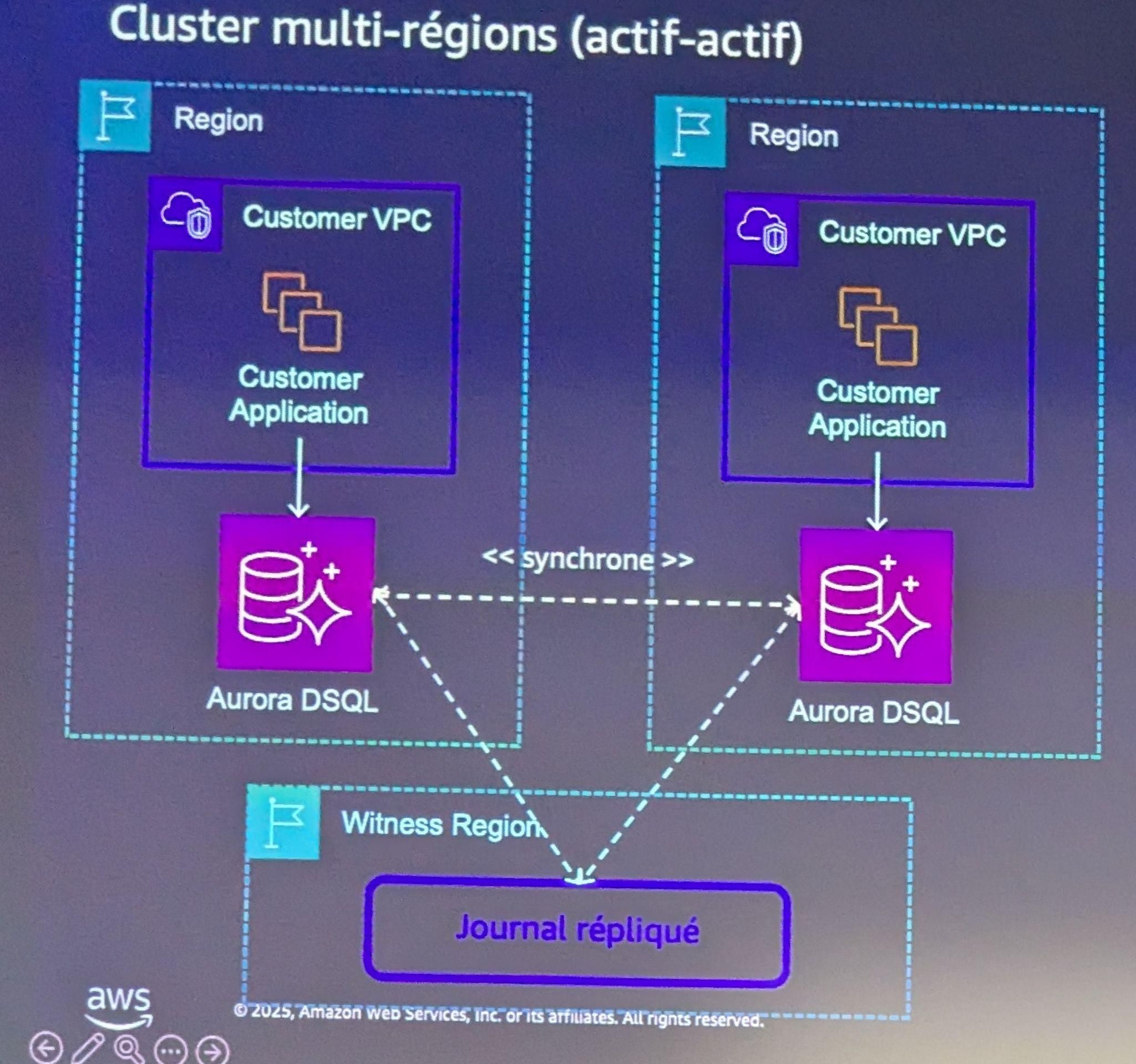
Une gestion de la concurrence optimiste
Dans un environnement multirégional, la gestion de la concurrence devient un sujet sensible. Aurora DSQL fait le choix d’un contrôle optimiste : les transactions ne sont pas bloquées en amont par des verrous (pas de verrouillage pessimiste), mais validées à la fin de leur exécution, après vérification de l'absence de conflit.
Ce modèle permet de traiter efficacement les transactions en lecture seule ou celles qui manipulent des clés différentes, qui n'entrent pas en conflit entre elles. En revanche, deux transactions concurrentes qui modifient la même donnée peuvent se heurter lors de la validation. L’enjeu ici est d’assurer une cohérence forte sans pour autant sacrifier la scalabilité.
Le modèle est particulièrement adapté aux applications modernes qui ont besoin de résilience multirégionale, mais il demande une adaptation côté développement : il faut repenser la façon dont on structure les écritures et accepter que certaines transactions puissent échouer et nécessiter une relance.
Un fonctionnement sans serveur
Autre aspect notable de la solution : la suppression quasi totale des opérations d’infrastructure côté utilisateurs. Dans Aurora DSQL, il n’y a aucun serveur à provisionner, ni à maintenir : pas de patchs, pas de gestion de dimensionnement, pas de planification de fenêtres de maintenance. Cette approche “serverless” s’accompagne d’un ajustement automatique et indépendant des ressources de calcul et de stockage, à la hausse comme à la baisse.
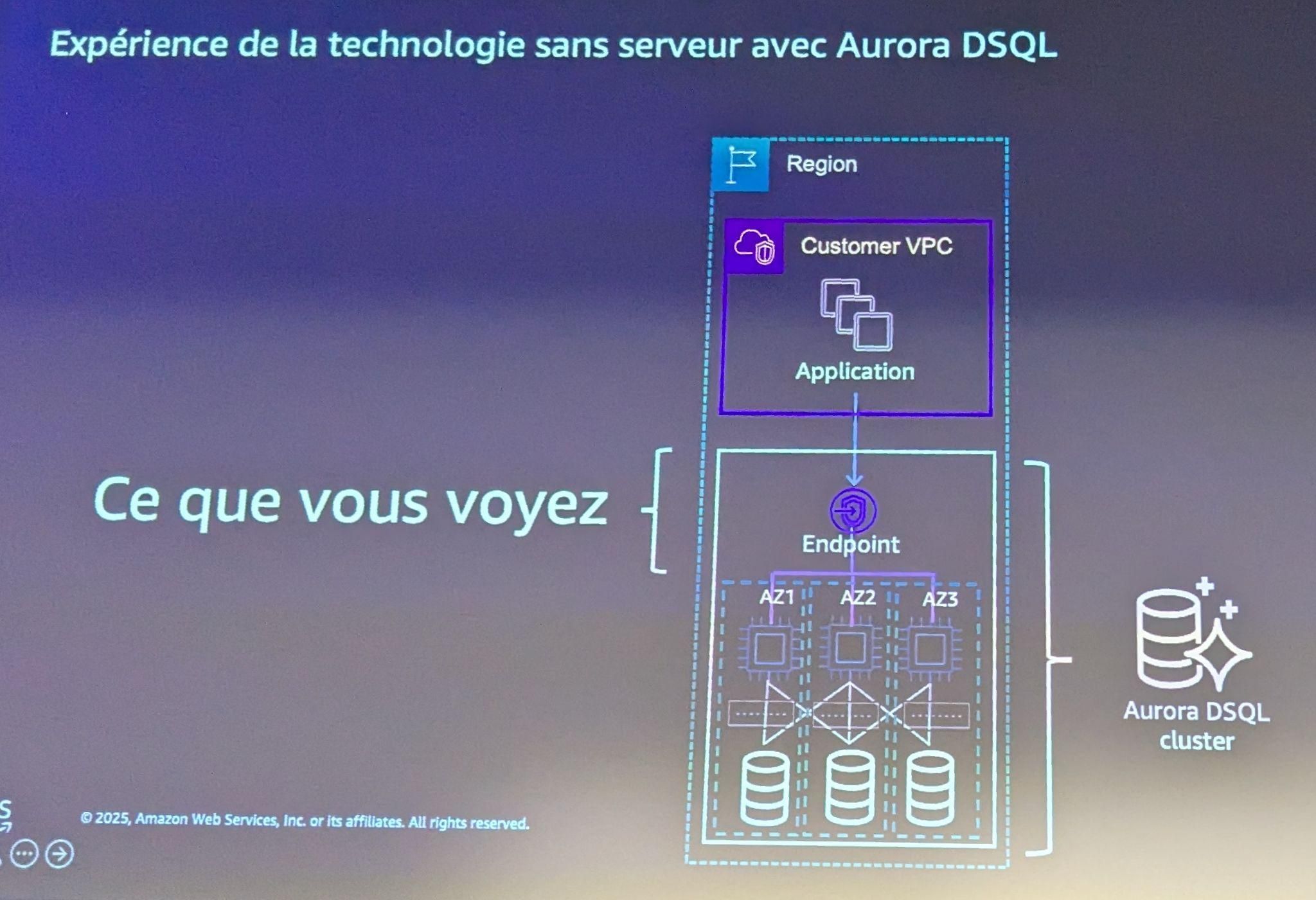
Ce fonctionnement promet un gain opérationnel non négligeable. Il permet aussi de réduire le risque de downtime planifié, un point souvent sous-estimé mais critique pour certaines applications à forte exigence de disponibilité.
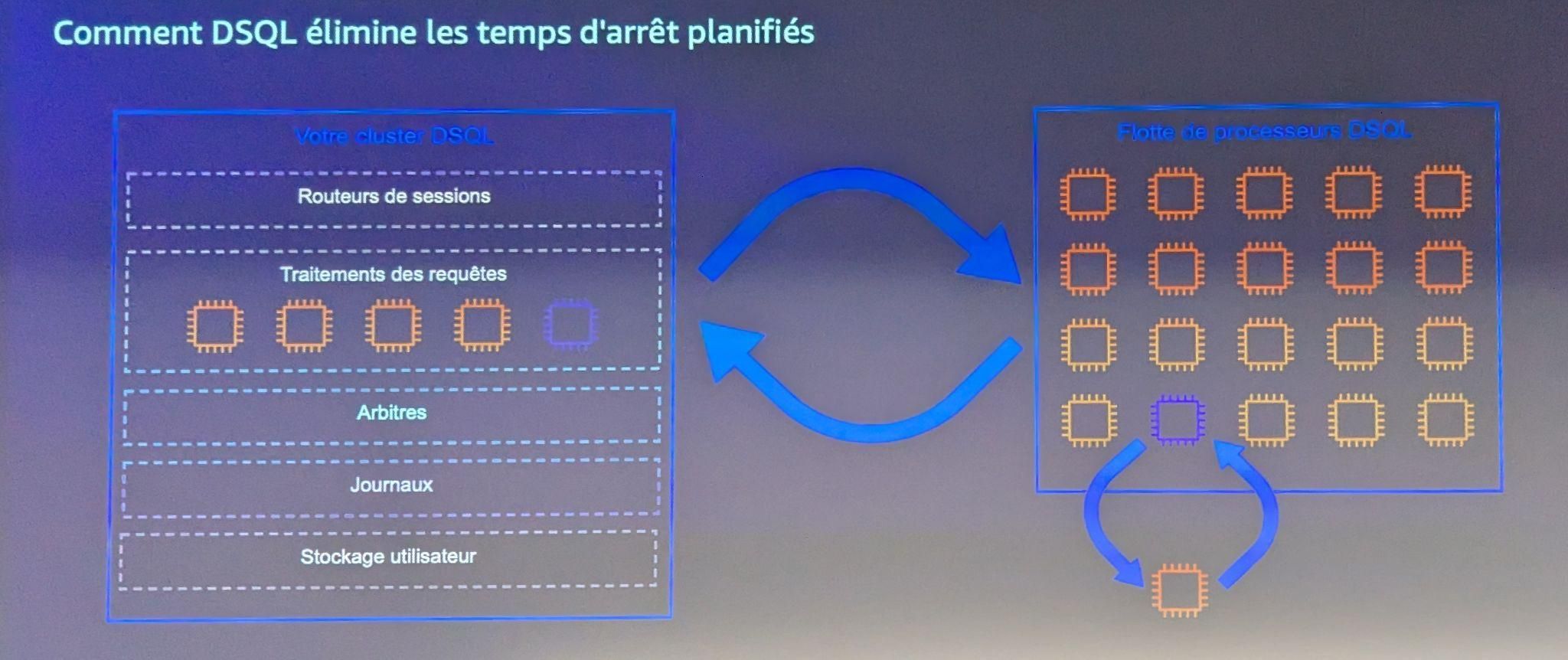

Bien sûr, cela implique une dépendance forte à l’infrastructure AWS, et demande une compréhension fine du modèle pour anticiper les coûts ou diagnostiquer les comportements.
En résumé
La session consacrée à Aurora DSQL a mis en lumière deux tendances structurantes pour les systèmes de données modernes : la montée en complexité des environnements distribués et la volonté croissante de réduire la charge opérationnelle. Le choix d’un modèle de concurrence optimiste dans un contexte multirégional soulève des questions intéressantes sur la conception des applications et sur les compromis entre fluidité d’exécution et contrôle des conflits.
Pour aller plus loin
Pour approfondir certains sujets évoqués lors de cette journée, n’hésitez pas à consulter la chaîne YouTube AWS Events.
À ce jour, les replays du AWS Summit Paris 2025 ne sont pas encore disponibles, mais vous pouvez déjà visionner les conférences et ateliers enregistrés lors du AWS Summit Paris 2024, qui couvrent de nombreuses thématiques toujours d'actualité.
Conclusion générale
Au-delà des technologies et des architectures, ce sont les retours d’expérience concrets qui ont véritablement marqué cette journée.
La présentation de La Centrale a mis en lumière une réalité souvent sous-estimée : réussir une transition vers le Data Mesh ne repose pas uniquement sur l’adoption d’outils, mais implique une transformation culturelle en profondeur, une redéfinition des responsabilités et un engagement fort des équipes métier.
La session consacrée à Aurora DSQL a, quant à elle, souligné les nouveaux défis liés à la gestion des bases de données distribuées : garantir une cohérence forte à l’échelle tout en simplifiant les opérations grâce à des modèles serverless oblige à repenser en profondeur nos pratiques de développement.
Ce qui ressort clairement de cette journée, c’est que la donnée devient un produit à part entière, au service de l’agilité et de l’innovation. La redéfinition des responsabilités autour de la donnée et l’essor des bases SQL distribuées et scalables apparaissent aujourd’hui comme des leviers clés pour bâtir des systèmes robustes, évolutifs et résilients.