Retour aux bases avec l'UDD : pour construire une Business Intelligence de qualité, agile et industrielle
A l’heure de la Business Intelligence 2.0 et 3.0, je suis d’accord que le titre de ce billet n’est pas très vendeur. Cependant, il est encore difficile d'attribuer ces 3 qualités à nos systèmes décisionnels, c’est pourquoi j’aime à croire que le sujet reste d'actualité.
L'objectif de ce post n’est pas de résoudre tous les problèmes des systèmes décisionnels mais de formuler une proposition qui a le mérite de fournir un premier pas pour tendre vers ces 3 qualités simultanément.
Tout d’abord, pour éviter les incompréhensions, j’aimerais définir un peu les 3 qualités susnommées.
La qualité des systèmes d’informations décisionnels :
Quand je parle de qualité, je ne parle de la qualité de données (un autre sujet sans fin dans le décisionnel), mais plutôt de qualité logicielle. Je vais ici m’intéresser à l’un des axes de la qualité au sens OCTO lorsque nous réalisons des audits, à savoir les tests. En effet, il y a une corrélation forte entre la qualité d’un système et sa politique de test et malheureusement, ce n’est pas le fort des systèmes décisionnels : au-delà de quelques tests unitaires et de la recette, on est loin d’une politique de tests exhaustive comme peut le représenter le schéma ci-dessous :
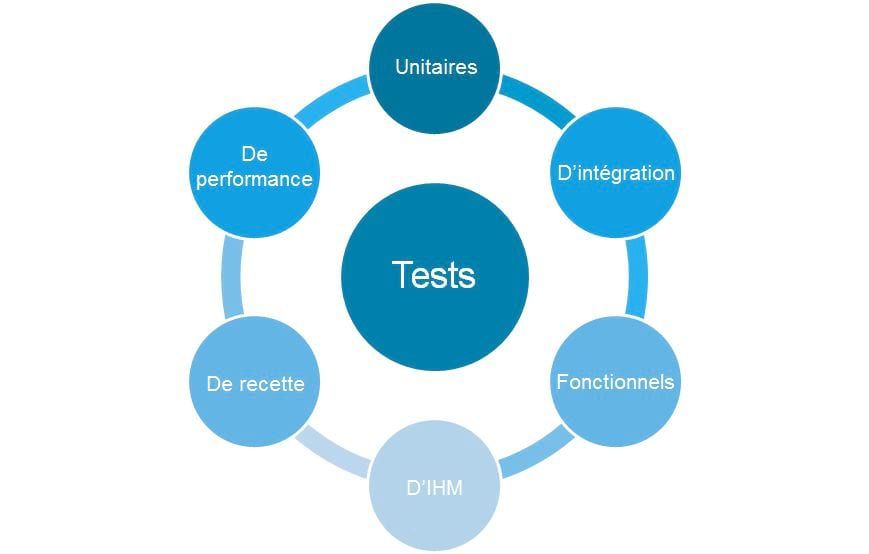
Bien sûr, ces tests sont à réaliser à chaque livraison pour éviter les régressions. Retrouver un tel harnais de test incluant la non-régression est extrêmement rare dans les projets décisionnels.
Un système décisionnel, qui souhaite prendre le chemin de la qualité, ne présente peut-être pas tous ces tests mais doit au moins comprendre des tests unitaires, des tests d’intégration et des tests de performances.
L’agilité des systèmes d’informations décisionnels :
Sans rentrer sur l’opportunité ou non des méthodes agiles, je présenterais un système agile comme un système regroupant les qualités suivantes :
- Il livre régulièrement et sans retard,
- Il sait s’adapter aux changements au cours d’une release,
- Il n’attend pas des spécifications exhaustives pour commencer à travailler,
- Son leadtime est compatible avec les attentes du business (en moyenne inférieur à un 1 mois),
- Il s’améliore en continu sur la base de feedback.
C’est un vaste programme mais pas irréalisable, à partir du moment où l’on respecte quelques pré-requis. Il y a en 2 sur lesquels j’insiste systématiquement lorsque je travaille en clientèle sur la mise en place d’une méthode agile : les tests et l’industrialisation…
L'industrialisation des systèmes d’informations décisionnels :
Des trois qualités, c’est sûrement celle qui mérite le plus un éclaircissement au sens où l’industrialisation, quand on parle de développement logiciel, porte en elle à la fois le meilleur et le pire en termes de pratiques. Ce qui m’intéresse dans l’industrialisation, c’est principalement l’automatisation de tâches à faible valeur ajoutée et/ou répétitives, et le partage de standard au sens lean :
- l’automatisation va permettre de sécuriser des tâches en soulageant les personnes les réalisant et en réaffectant leur temps sur des travaux à plus forte valeur ajoutée,
- le partage de standard apporte, quant à lui, de l’efficacité et une certaine forme de cohérence.
Ce qui est bien plus douteux quand on parle d’industrialisation, se cache derrière les approches top-down visant à maîtriser le développement logiciel et mène souvent à l'échec en dehors de cas balisés, par exemple : les pratiques de type MDA et les frameworks de génération de code, la spécialisation des acteurs et le sur-découpage des tâches, ou n’importe quelle approche de modélisation mise en oeuvre sans discernement (3NF , datavault…). Toutes ces mauvaises pratiques partagent en fait un même ADN : pousser à l’extrême une initiative intéressante dans un contexte, ou un modèle élégant sur le plan théorique ne résistant pas à la mise en pratique.
Un système d’information décisionnel industriel est donc selon moi un système ayant réalisé l’automatisation de tâches à faible valeur ajoutée et/ou répétitives et partageant des standards, tout cela avec bon sens et un souci constant de remise en question.
Ma proposition : l'UDD aka l’usine de développement
Comme je le disais en introduction, ma proposition constitue un premier pas pour améliorer les 3 qualités précédemment explicités simultanément. Cette proposition n’apporte rien de très neuf si l’on regarde les systèmes opérationnels où elle est courante depuis la fin de la décennie précédente. Cette proposition, c’est l’usine de développement.
La promesse de cette usine est de jouer sur 3 facteurs comme indiquer dans le schéma ci-dessous :
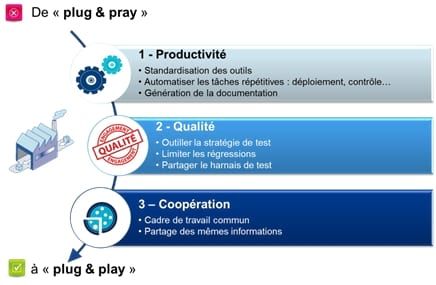
Cette usine est constituée d’une panoplie d’outils mise à la disposition d’un projet combinée avec la définition d’un processus et de règles. Pour la description fonctionnelle précise d’une usine et de ce qu’elle permet de réaliser en détail, je vous renvoie vers ce très bon article (la suite de ce billet risque d’ailleurs d’être un peu abscond si vous n’êtes pas familiarisé avec ces concepts).
Attention tout de même, pas de silver bullet, cette usine ne résoudra pas tous vos problèmes, ce n’est qu’une première pierre à l’édifice pour consolider les bases de votre système d’information décisionnel et surtout ce n’est pas :
- une fin en soi,
- un outil de contrôle,
- la fin des intégrateurs.
Illustration d’une usine de développement BI
Alors qu’est-ce que serait une usine de développement pour un système décisionnel ? Prenons comme exemple l’usine de développement ci-dessous :
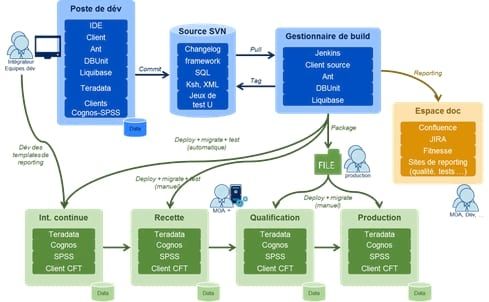
Illustrons tout d'abord le fonctionnement de cette usine sur le cas d'usage suivant : une modification du modèle de base de données. Tout d’abord le développeur opère sa modification, réalise les tests associés et commit finalement cette modification vers le gestionnaire de source (notamment des scripts de bases de données sont envoyés comprenant les modifications, ses différentes étapes et le retour arrière). Ensuite via le gestionnaire de build, nous avons maintenant la possibilité de tagger cette modification pour une release et de déployer automatiquement ces modifications sur les environnements souhaités. Ce déploiement pourra prendre une forme différente pour la production par exemple, mais sera toujours réalisé à partir des mêmes sources afin d’éviter les erreurs.
Pour préciser le fonctionnement, je ne reviendrai pas sur les composants de base d’une usine de développement (gestionnaire de source, de build et le serveur d’intégration, reporting, wiki que vous retrouverez dans l'article en suivant le lien précédent) mais je vais revenir sur les spécificités d’une usine de développement BI.
Les spécificités d'une usine BI
Une grande différence réside dans la place centrale de la donnée et des bases de données dans l’architecture. A ce titre, des outils spécifiques sont nécessaires pour gérer les modifications de base de données (ici liquibase) sur le principe de refactoring database et les tests sur les bases de données via l’utilisation d’un framework de test unitaire (ici dbunit).
Concernant les tests unitaires, si l'on peut rappeler qu'ils sont importants, il faut bien comprendre qu'ils sont en fait vitaux dans ce type d'architecture. La spécificité des tests unitaires dans le décisionnel est qu'ils sont rattachés à des langages scriptés (script shell par exemple) ou à des L4G qui sont bien moins servis en analyseur de code qu'un langage de programmation comme Java disposant de plus de la compilation comme verrou supplémentaire de vérification.
Une autre spécificité se cache derrière l'importance et la complexité des tests d'intégration. En effet, dans un contexte de système d'information décisionnel fortement corrélé avec les systèmes en amont voire en aval, ces tests prennent une ampleur et une importance capitale pour garantir la qualité et éviter les régressions vis-à-vis de systèmes évoluant eux aussi. Cela constitue d'ailleurs un très bon test pour identifier, à posteriori, des modifications de systèmes sources ayant échappé à votre attention...
Dans le même ordre d'idée, les tests de performance dans un contexte à forte volumétrie sont clés. Dans un monde où Big Data est notre pain quotidien, la recherche de la performance (ou son maintien) est vitale. Cependant, au lieu de parler de disponibilité ou d'utilisateurs concurrents (quoique), c'est bien la performance des flux et des transformations qui doit être testée via une usine BI.
En conséquence, c'est la logique de build qui doit être adaptée. On peut par exemple mettre un build d'intégration continue pour vérifier toute la chaîne sur une volumétrie raisonnable et un build de nuit orienté performance notamment pour les batchs consommateurs. Cette notion de build pourra aussi nous permettre de tester des scénarios que l'on retrouve souvent dans le décisionnel comme une initialisation ou une pré-production, une migration ou des rejeux.
Enfin, certains composants ou pratiques ne sont pas transposables d'une usine traditionnelle vers une usine BI. Par exemple, la notion de couverture du code ou l'utilisation de Sonar dans un contexte où le reporting est une fonctionnalité de base du système paraissent inappropriées. Un vrai travail d'adaptation des usines traditionnelles à votre contexte et à vos usages est donc à réaliser.
Les limitations et les difficultés
Bien entendu, tout n’est pas parfait et quelques limitations freinent le déploiement de ce type de solution :
- la connaissance de base du monde java est un pré-requis pour monter cette usine ainsi que pour l’utilisation ce certains frameworks (dbunit par exemple),
- les outils ou composants d’architectures décisionnelles peuvent être des boîtes noires interdisant les imports/exports de code, les opérations scriptées donc automatisables et rendant l’utilisation de framework de test unitaire impossible,
- une fois surmontée, il restera à affronter la principale difficulté, à savoir maintenir des données de tests en relation avec les différents types de tests à mettre en œuvre par environnement et de les faire évoluer avec la vie du projet. Cette maintenance peut être plus ou moins difficile selon les typologies d'interfaces en jeu.
La mise en place de ce type d'usine n'est pas difficile techniquement mais une implémentation progressive est à privilégier (comme tout projet en fait) afin notamment d'adapter les processus associés et la culture des acteurs du projet. Un premier PoC, se limitant par exemple aux modifications de la base de données, permettra rapidement de se rendre compte des impacts et des intérêts de ce type de solution. Le fait que votre projet soit déjà commencé depuis des mois n'est pas une excuse valable pour ne pas essayer (dans la majorité des cas observés l'usine était arrivée en cours de projet).
Pour conclure
Véritable pré-requis à la mise en place d’une approche agile, vraie garantie de la qualité de votre système et source de productivité par l’automatisation qu’elle apporte, l’usine de développement est aujourd’hui incontournable si vous souhaitez relever ces challenges.
L’investissement initial, comme nous l’avons observé sur plusieurs projets, a toujours été amplement remboursé au bout de quelques mois jusqu’à faire de l’usine de développement la pierre angulaire de ces projets.