Reprise de données lors d'une refonte IT agile
Les données sont au cœur de votre business. Susceptible de reporter la mise en production de votre nouvelle application, il faut considérer la reprise de données comme une étape importante de votre processus de refonte.
La reprise de données est un aspect technique particulier de la refonte qui doit être pris en charge par une équipe dédiée (il suffit d'un développeur et d'un PO pour former une équipe) dès le début du projet afin d'anticiper la complexité des règles de reprise, de vérifier le bon fonctionnement de l'application (et oui !) et d'éviter des choix de conception logicielle pouvant bloquer la reprise.
Si vous comptez vous lancer dans cet exercice périlleux, voici quelques retours d'expériences issus d'un projet de refonte d'une application client lourd vers une architecture cible classique (web, java, hibernate, ...), mené en agile, avec en parallèle et sur le même rythme agile, le projet de reprise de données.
Préparer sa reprise de données
Comme pour tout projet, la première étape est la phase de cadrage.
Il s'agit ici d'ouvrir votre base de données, de faire un état des lieux de votre modèle - nombre de tables et d'objets par table, lien entre les tables, données mal formatées dont il va falloir améliorer la qualité, nettoyage/traitement manuel (ex: les infos dans les commentaires !), ... - et de définir avec les utilisateurs métier les données les plus importantes à leurs yeux (s’imprégner du contexte métier).
A ce stade, vous aurez alors une idée de l’ampleur du travail en terme de volume et de complexité. Cela va vous aider à prioriser les stories de reprise.
Effectuer cette reprise
A savoir : la refonte est en agile, ce qui a pour conséquence que la base de données évolue en fonction des besoins implémentés dans l'application. C’est l’équipe projet applicatif qui construit la base et le projet de reprise qui s’appuie sur cette dernière.
Choix technique
Deux choix techniques principaux s’offrent à vous :
- Le projet de reprise se repose sur le même langage que votre application (Java + Hibernate pour votre couche de données)
- Utilisation d'un outil spécifique à la migration de données, type ETL (Talend)
Mais lequel choisir ?
| Avantages | Inconvénients | |
| - Homogénéité entre l'application, le projet de reprise et les tests- Vos objets métiers cibles sont déjà définis dans le code de votre application, vous pouvez les utiliser immédiatement dans votre projet de reprise | - Le code peut vite être lourd (verbeux) et les règles métiers complexes à coder- Les scripts de reprise sont assez long à l’exécution- Il va falloir décrire toutes les tables de la base de données source afin de les utiliser en tant qu'objets dans le projet de repris | |
 | - Performance et rapidité d’exécution- Gestion des statistiques, des logs et des cas en erreur (rejets)- Facilité de mise en œuvre et de configuration (accès base, mapping, ...)<br><br>- Outil graphique | - Besoin de synchronisation entre le projet ETL et le modèle de données défini dans le code applicatif- Nécessite un projet ETL pour la reprise et un autre projet (Java) pour les tests fonctionnels- Montée en compétence sur l'outil |
Dans notre cas, il était important d'avoir des logs, de gérer de gros volumes mémoire, etc. Nous avons donc opté pour la solution ETL.
NB : Lors de votre choix, il faut également prendre en compte les éventuels coûts de licence et de montée en compétence sur les outils.
Ecriture des User Stories
Lors des ateliers avec les métiers, il est nécessaire de mettre en parallèle les données de l'application source avec celles de l'application de destination. Pour cela, un tableau Excel avec les éléments suivants est d'une grande aide :
- nom du champ dans la base de données source
- nom du champ dans l'IHM de l'application source (les noms en bdd ne sont pas toujours explicites)
- nom du champ dans la base de donnée cible
- règle de transformation.
Les deux premières colonnes peuvent être rempli dès le début du projet par une personne maitrisant l'application existante. Les deux autres seront complétées au fur et à mesure des itérations.
Cette "étape" peut s'avérer fastidieuse mais est essentielle. Ce fichier sera en quelque sorte votre cahier des charges et pourra servir à connaitre l'avancement de la reprise de données (il suffit pour cela d'ajouter une colonne "Done"). N'oubliez pas de renseigner également les champs non repris - qui seront "Done" immédiatement - ceci afin de ne pas se reposer les questions sur l'utilité de tel ou tel attribut.
Et maintenant, on code et on fait des...
Tests : unitaires, fonctionnels, ...
Le seul moyen de s’assurer que vos données à l’arrivée sont correctes est bien évidemment de faire des tests.

Si votre reprise de données se fait via un module Java, des tests unitaires (basiques) permettront de valider vos méthodes de reprise : création de données "fictives", appel de la méthode à tester et vérification des données en sortie.
Si votre reprise se fait via un ETL, il sera très compliqué - voire impossible- d'effectuer de tests unitaires à proprement parler (utilisation de jUnit par exemple). Par contre, l'outillage habituellement utilisé pour les tests fonctionnels (ex : Concordion, Fitnesse) s'adapte très bien : il faudra juste créer un projet dédié pour les faire tourner. Ces tests seront en conditions réelles, c’est-à-dire : avoir une réplique de la base de donnée source qui n'est pas utilisée et dans laquelle vous pourrez faire des modifications, jouer la reprise de données (lancer vos jobs de reprise) sur une base cible qui sert exclusivement à vos tests et exécuter vos tests.
Nous venons de tester la qualité de nos données (savoir si elles ont correctement été transformées) sur un périmètre restreint, mais il faut également s’assurer que le nombre total de données attendu est correct pour vérifier que nous n’avons pas oublié un cas fonctionnel (si tel est le cas il faudra penser à ajouter un test unitaire de ce cas).
Pour cela, il faut avoir un jeu de requête SQL "select count(*) from ..." à exécuter dans les bases source et cible et comparer les résultats obtenus (cela peut être fait automatiquement dans votre module de tests).
Attention, ces requêtes peuvent vite être complexes à écrire en fonction des règles de transformation, des changements de référentiels, ...
Bases de données nécessaires
En plus de(s) base(s) de données utilisée(s) par l’application, il en faudra une spécifique pour les tests fonctionnels - si vous passez par un ETL - et une pour tester la reprise totale. Pourquoi en plus ? pour ne pas impacter les bases et le développement de l’application.
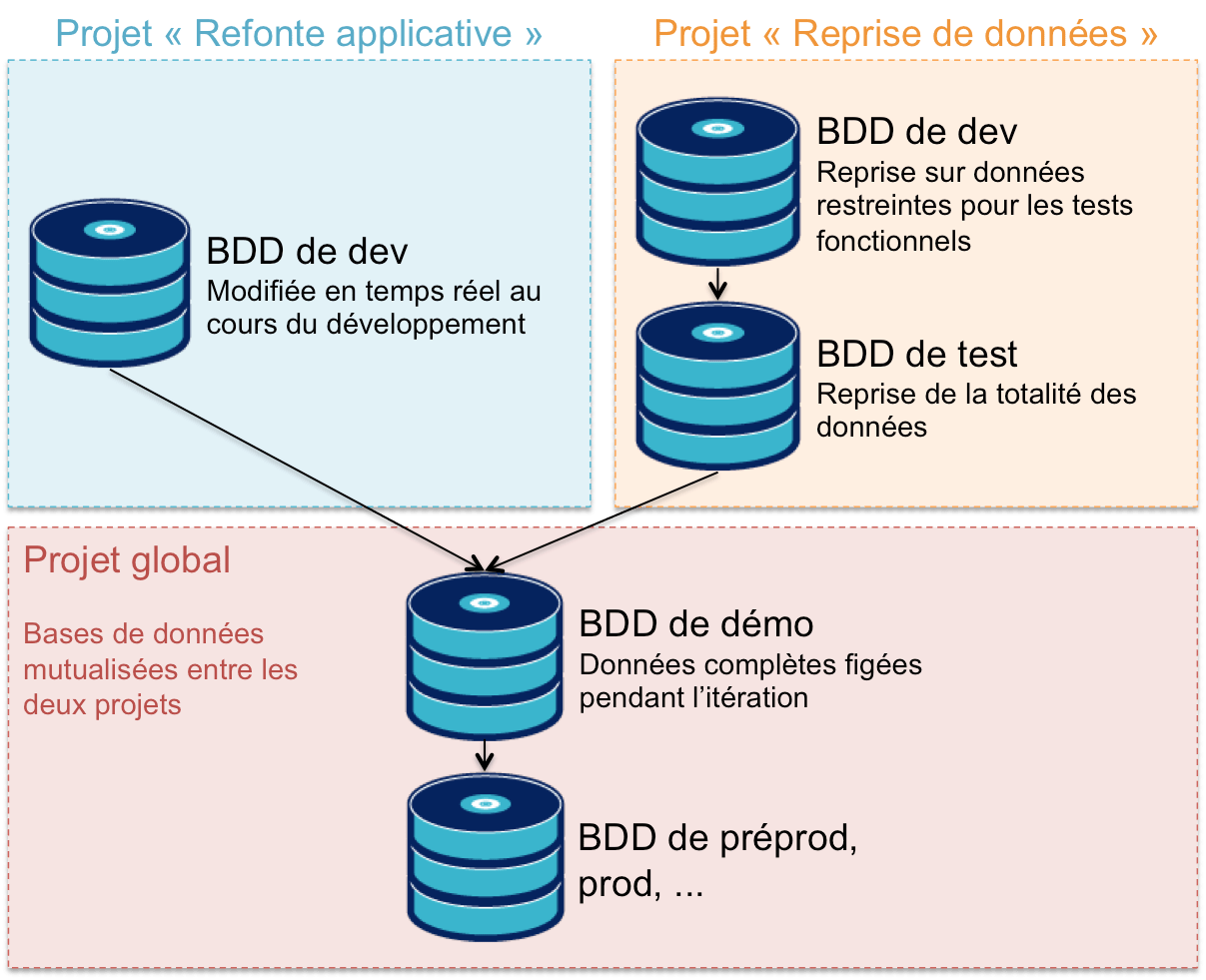
Stratégies de reprise
Exemple de reprise : J'ai une table "Commande", une table "Matériel" et une table de jointure "Commande-Materiel". Une commande peut avoir plusieurs matériels et un matériel peut être dans plusieurs commandes.
Deux stratégies de reprise possibles :
- Je reprend mes données table par table
- Je reprends un ensemble de données cohérent
Cas 1 :
Avantage : Je commence par reprendre tous mes matériels, puis je reprend toutes mes commandes (peu importe l'ordre) et enfin je remplis ma table de jointure. Cette approche est simple : les méthodes Java - ou jobs Talend - sont faciles à lire et à écrire, elles sont indépendantes (sauf la table de jointure) et je parcours une seule fois mes tables. De plus, si l'application ne gère dans un premier temps que les matériels, je peux me concentrer uniquement sur cette table.
Désavantage : si je ne veux reprendre qu'une sous-partie des objets (ex: commande pour les matériels X et Y), je dois mettre des filtres sur chacune de mes méthodes.
Cas 2 :
Avantage : Je parcours ma table Commande et pour chaque commande, je reprend les matériels correspondants (attention, il faut vérifier ici que le matériel n'existe pas déjà) et je crée la liaison. Je récupère ainsi un ensemble de données restreint mais complet pour mon application.
Désavantage : le code devient très vite illisible, les dépendances sont partout et on peut tirer beaucoup d'objet de cette façon (on "tire sur la pelote de laine").
Dans le cas d'une reprise qui s'effectuera one-shot (= le jour J, on éteint l'ancien système et on ouvre le nouveau avec toutes les données), l’utilisation de la 1ère méthode est plus simple dans les faits. Si vous faites du double-run, alors la 2ème pourra être plus avantageuse car on pourra reprendre les données en fonction de leur date de création/modification mais l'exercice est plus risqué et des vérifications de cohérence de données doivent être faites...
Quand effectuer la reprise ?
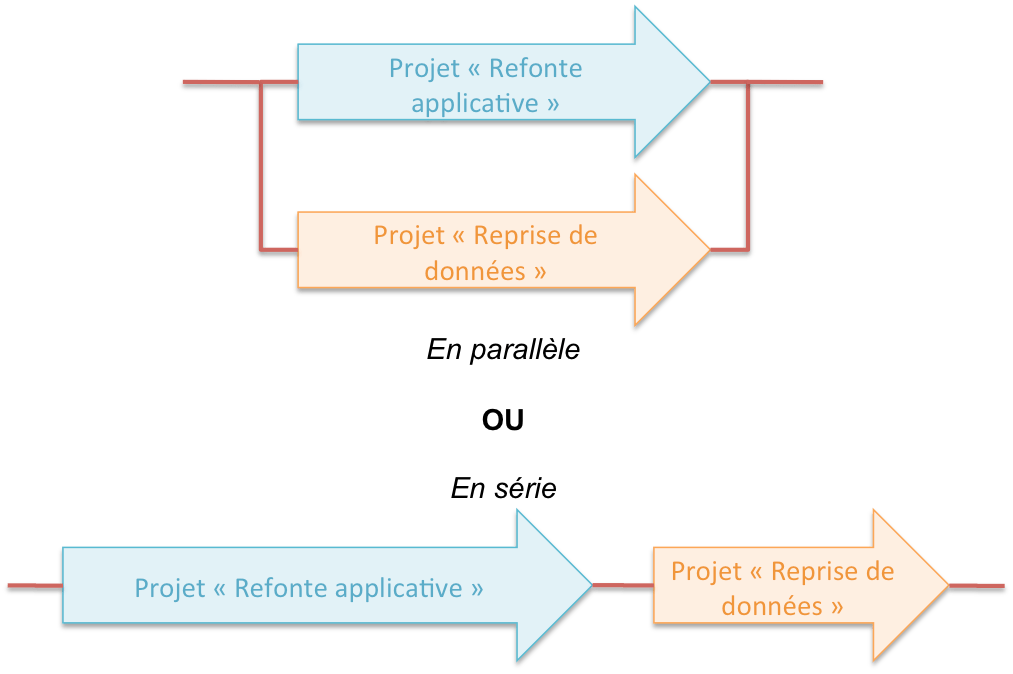
Comme dit précédemment, la reprise est une étape importante du processus de refonte et peut bloquer votre mise en production si elle commencée trop tard. Votre reprise de données doit s'effectuer en même temps que le développement de l'application car cela permet de :
Voir que certaines données de l'ancien système ne sont pas utilisées dans la nouvelle application
Est-ce normal ? (donnée vide / en doublon / inutilisé)
A-t-on oublié d'implémenter une fonctionnalité dans l'application ?
S'agit-il d'une donnée non exploitée par l'application mais utile aux SI externes ? (dans les interfaces par exemple)
S’apercevoir qu’un besoin a été mal spécifié/conçu dans la nouvelle application
Par exemple, lors de la reprise on voit que tels et tes objets sont liés dans l’ancienne application mais que ce lien n'existe pas dans la nouvelle base de donnée. La reprise est donc impossible telle que décrite. Il faut revoir avec les métiers pourquoi il y a cette différence. La demande a peut-être été mal exprimée et/ou mal comprise et le besoin mal implémenté.
Tester l'application en conditions réelles
Cette dernière est livrée en continu avec les données correspondantes aux fonctionnalités développées, on peut donc :
- Se rendre compte des éventuels problèmes d'ergonomie (ex : une liste qui peut contenir 1000 champs va nécessiter une auto-complétion)
- Effectuer des tests de performance et voir si l'application tient la charge
- Impliquer plus facilement les utilisateurs et rendre l'application plus concrète. Pendant les séances de tests, ils utilisent les données qu'ils connaissent; ils savent lesquelles peuvent poser problème.
La reprise peut être longue à développer et à tester, surtout si les schémas de base de données sont structurellement différents et s'il y a beaucoup de nettoyage à faire (formatage, fusion/éclatement de données, ...). De plus, elle peut être bénéfique aux tests de l'application. Et puis, une nouvelle application c'est bien... mais une nouvelle application utilisable c'est mieux ! Alors à vous de jouer et surtout pensez-y tôt dans votre processus de refonte !