Visibilité de la chaîne de valeur : Optimiser vos projets de Machine Learning
“Make the flow of work visible through the value stream. Teams should have a good understanding of and visibility into the flow of work from the business all the way through to customers, including the status of products and features. Our research has found this has a positive impact on IT performance." Extrait de : Forsgren PhD. « Accelerate. »
Cet article fait partie de la série “Accélérer le Delivery de projets de Machine Learning**”, traitant de l’application d’Accelerate [1] dans un contexte incluant du Machine Learning. Si vous n’êtes pas familier avec Accelerate, ou si vous souhaitez avoir plus de détails sur le contexte de cet article, nous vous invitons à commencer par lire l’article introduisant cette série. Vous y trouverez également le lien vers le reste des articles pour aller plus loin.
Introduction
Une grosse différence entre le monde du logiciel et le monde industriel est que le travail n’est pas immédiatement visible. En effet, en arrivant sur un plateau de delivery, il est difficile de voir si le travail avance bien, comment est créé le produit final.
Un axe de travail est de rendre visible le travail en mettant en place par exemple un Kanban, cet axe est abordé dans cet article. Cependant, voir le travail n’est pas toujours suffisant, les outils présentés dans l’article référencé donnent une vision du travail telle qu’il est quotidiennement réalisé. Ils sont très opérationnels. Ils peuvent permettre de faire des améliorations locales (à l’échelle d’une personne, d’une équipe).
Il est important aussi de pouvoir prendre de la hauteur pour voir ce qui est vraiment utile (et donc ce qui ne l'est pas), ce qui crée de la valeur (et ce qui n’en crée pas), etc.
Rendre visible la chaîne de création de valeur doit permettre de travailler sur des améliorations globales de la façon dont est construit un produit.
Dans cet article, nous allons proposer une méthode qui permet de visualiser la chaîne de valeur, puis l’appliquer au delivery de machine learning, et enfin proposer des exemples concrets de pertes, et d’améliorations possibles que vous pouvez rencontrer dans vos organisations.
Qu’est-ce que la représentation de la chaîne de valeur ?
Inspirée du lean management, la représentation chaîne de valeur est un outil de visualisation qui consiste à représenter les différentes étapes de production d’un artefact (un objet en usine, une application en développement logiciel).
Les objectifs en réalisant un tel exercice sont :
Comprendre le fonctionnement réel de l’organisation et aligner les différentes parties prenantes sur la façon dont est produit l’artefact.
Identifier les causes des gaspillages et les goulots d’étranglement. Il en existe différents types que l’on détaillera plus loin.
Identifier des axes d’amélioration pour produire plus efficacement.
Prioriser les investissements sur les étapes les plus efficaces (qui créent le plus de valeur, ou qui gagnerait le plus à être optimisée)
Améliorer le lead time (le temps entre la première étape et la mise à disposition de l’artefact aux utilisateurs), ainsi que diminuer le nombre de défauts. Ce sont d’ailleurs 2 des 4 métriques accelerates.
Les actions que l’on peut tirer d’un tel outil sont :
Organisationnelle : par exemple redéfinir les périmètres d’équipe / de responsabilité,
Culturelles : par exemple faciliter les échanges au sein d’une équipe,
Techniques : par exemple automatiser certaines étapes qui sont des goulots d’étranglements ou qui produisent beaucoup de valeur.
Dans cet article, nous allons nous concentrer sur la représentation de la chaîne de valeur dans un projet de delivery de Machine Learning. Si vous voulez creuser cet outil en développement logiciel, ces deux sites en français, en anglais pourront vous aider.
La valeur en Machine Learning
Nous pouvons aujourd’hui observer trois moyens classiques d’apporter de la valeur en projet de delivery de Machine Learning, cette liste n’étant pas exhaustive.
L’analyse descriptive va nous permettre de mieux comprendre un phénomène ou un ensemble de données, par exemple mieux comprendre une population de clients. Au moment des premières étapes de cette approche, nous ne savons pas forcément ce que nous cherchons, et allons donc utiliser des méthodes de classification non supervisée ou de statistique descriptive. La valeur apportée par ce genre d’approche est une meilleure compréhension du phénomène ou des données étudiées.
L’analyse statistique consiste à éclairer une prise de décision, par exemple un nouveau confinement est-il nécessaire ou non. La différence entre cette approche et l’analyse descriptive est que nous savons déjà ce que nous cherchons. La valeur ajoutée de cette approche se trouve dans des décisions plus informées et appuyées par des données.
La dernière des 3 approches est l’inférence, qui consiste à prendre une décision ou à générer une prédiction qui va directement alimenter une décision. Un exemple peut être de déterminer si une photographie d’un produit comporte un défaut ou non, ce qui va alimenter la décision de vendre le produit ou le garder. La valeur ajoutée par cette approche est une décision très peu coûteuse en temps, car automatisée, et une décision potentiellement plus pertinente que si elle était prise par un humain.
Dans les exemples de cet article, nous parlerons principalement de l’inférence, car c’est celle-ci qui génère le plus de valeur directement mesurable. En projet de Delivery de Machine Learning, l’inférence est souvent privilégiée.
Les éléments de la chaîne de valeur en Machine Learning
L’application de la représentation de la chaîne de valeur sur un projet de delivery de Machine Learning s’accompagne de nouveaux éléments spécifiques au Machine Learning ou un peu différent du développement logiciel.
En effet, le Machine Learning est une discipline relativement nouvelle dans nos environnements de travail, son utilisation doit être accompagnée par une acculturation au travail du Data Scientist afin que toutes les parties prenantes comprennent quelles sont les étapes créatrices de valeur.
Vous pouvez trouver, ci dessous, un schéma représentant les différentes étapes du travail du Data Scientist.
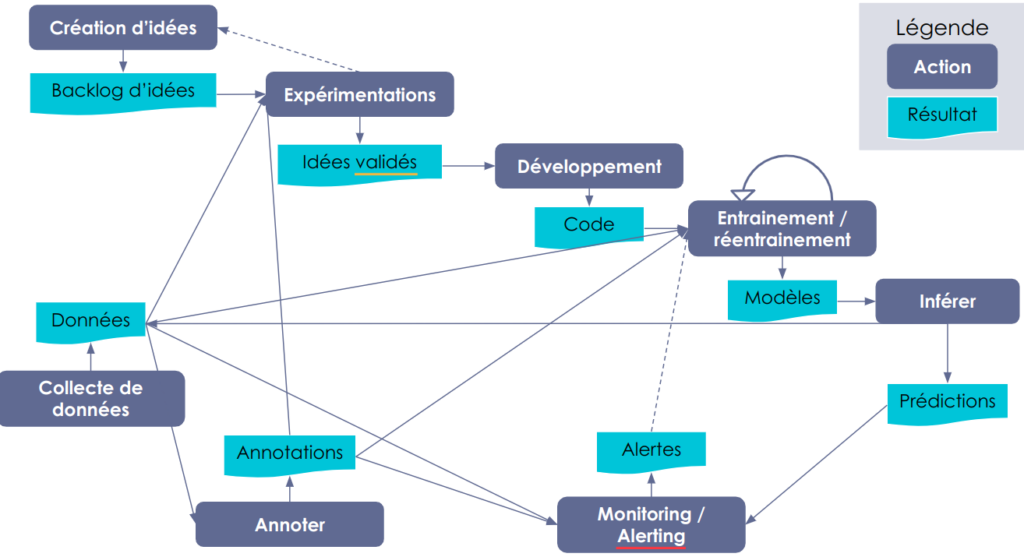
Figure 1 : Les différentes étapes et livrables du travail du Data Scientist
Dans un premier temps, le Data Scientist récolte les idées générées par les utilisateurs, le métier, l’équipe, voire lui-même. Ces idées peuvent être stockées dans un backlog contenant les idées priorisées (selon la potentielle valeur et la complexité de mise en œuvre).
La seconde étape consiste à prendre des idées contenues dans le backlog et à réaliser des expérimentations (Proof Of Concept) en utilisant les données et annotations disponibles afin de parvenir à une conclusion. Le résultat est une validation ou invalidation de l’idée : est-elle réalisable et apporte-t-elle de la valeur ?
Les idées valides seront ensuite reprises pour produire du code permettant de réaliser des entraînements de manière reproductible et peu chronophage. Ces entraînements permettent de générer des modèles. Il peut y avoir une rétroaction qui consiste à relancer un entraînement si la performance n’est pas assez bonne.
Une fois que le modèle est assez bon, il est déployé en production pour être utilisé et donc produire des prédictions. Ce modèle est utilisé tant qu'il donne un niveau de performance jugé satisfaisant (suivi par le monitoring).
Comme nous pouvons le constater sur le schéma plus haut, il existe de nombreuses étapes, successives ou non, avec des rétroactions. En effet, de nouvelles données annotations peuvent débloquer une idée jugée jusqu’ici trop complexe pour être poursuivie.
Certaines étapes sont bien entendu présentes en développement logiciel, mais prennent une proportion ou une forme différente dans un projet de Machine Learning. Par exemple, les expérimentations sont souvent plus nombreuses.
Chaque étape apporte une valeur différente au produit et cet apport de valeur peut varier dans le temps. Par exemple, les expérimentations vont probablement en apporter beaucoup au début du projet (car la performance du modèle va régulièrement augmenter) et sans doute moins au bout d’un certain temps. Une bonne pratique, très en lien avec le monitoring, consiste à tracer l’apport de valeur des différentes briques.
La chaîne de production de prédictions est complexe, et peut varier d’un contexte à l’autre. Pour optimiser cette production, il est donc essentiel de visualiser la chaîne de valeur.
Comment rendre visible la chaîne de valeur ?
Afin de permettre la visualisation de la chaîne de valeur, nous allons dans un premier temps devoir répertorier tous les acteurs de la production, ainsi que toutes les étapes présentes dans un cycle de production.
Dans un deuxième temps, nous allons diviser notre tableau blanc en 3 parties (de haut en bas) :
Information Flow : cette partie contient l’ensemble des acteurs, des équipes aux utilisateurs, ainsi que la communication et les transmissions d’informations entre ces parties prenantes
Product flow : cette partie contient quant à elle les étapes de productions, sans se soucier des temps d’attente ou de transmission d’information
Time Ladder : cette dernière partie est représentée par une échelle permettant de comparer le Production Lead Time (temps passé à créer de la valeur) et le Processing Time (temps d’attente et de transmission d’information entre deux étapes ).
Pour une tâche donnée, nous traçons une flèche entre l’acteur qui réalise et l’étape de production, puis une entre l’étape de production et l’acteur qui reçoit le livrable ou l’information. Sur l’échelle de temps, nous mesurons le temps pour faire et le temps pour transmettre.
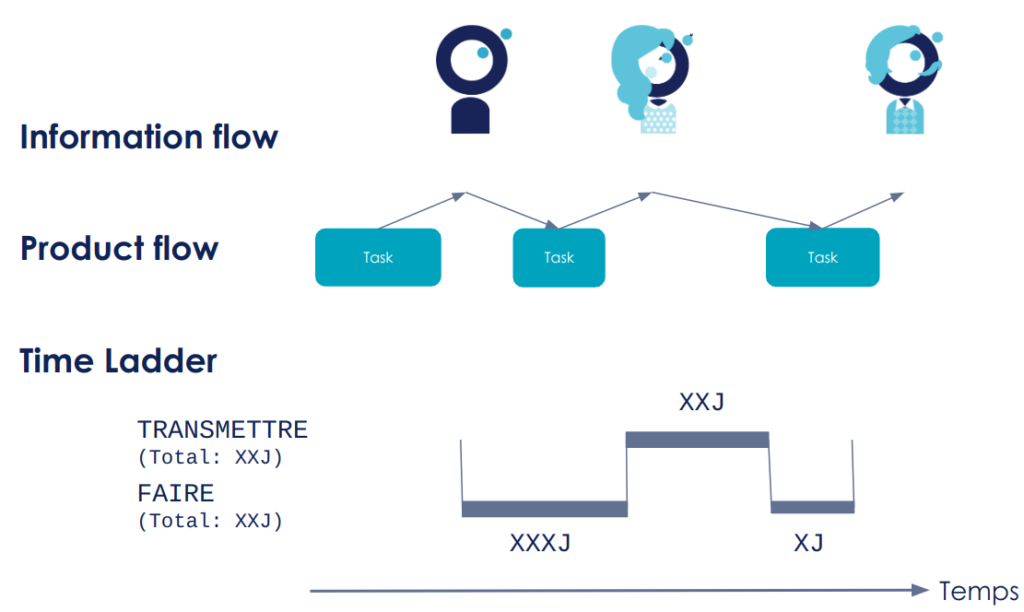
Figure 2 : Exemple de représentation de chaîne de valeur
Une fois la représentation de la chaîne de valeur actuelle terminée, nous devons maintenant identifier les “waste areas”, les pertes de temps.
Il existe sept types de “waste areas”, listées ci-dessous :
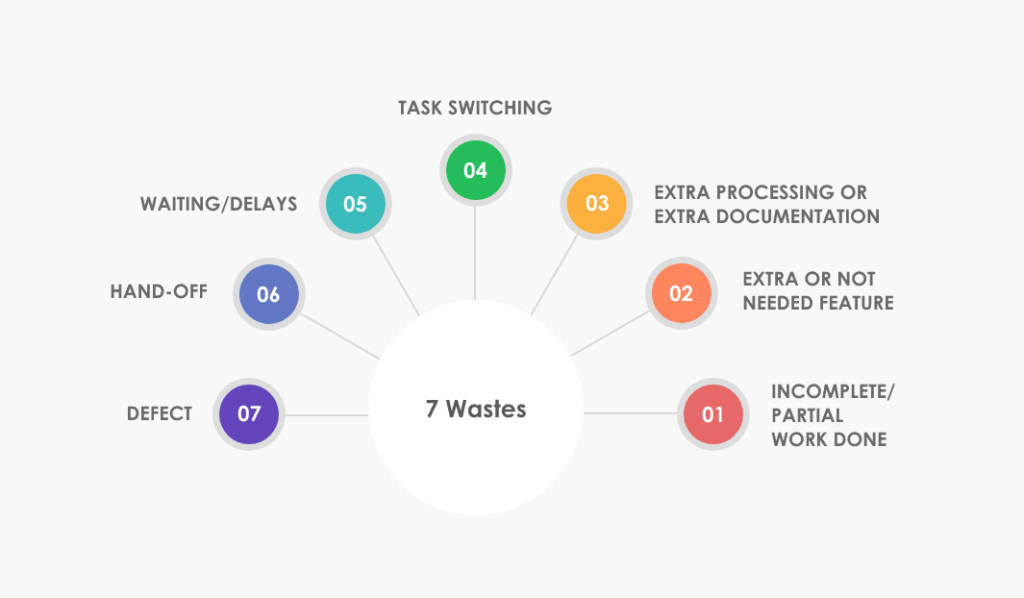
Figure 3 : Différents types de pertes (Source : https://www.edvantis.com/blog/vsm-definition/)
Travail non terminé : Le travail commencé qui n’a jamais été terminé. Par exemple, une exploration commencée, mais sur laquelle on n'a pas tiré de conclusions
Fonctionnalité non-nécessaires : par exemple une amélioration de 0.01% de la performance du modèle, qui n’a aucun impact sur la métrique métier
Des étapes ou de la documentation inutiles : Par exemple, attendre la validation d’un acteur qui ne va pas apporter de valeur ou des commentaires inutiles dans le code
Du multitâche (task switching) : par exemple un entraînement qui requiert de faire régulièrement des petites étapes manuelles, coupant le DS dans d’autres tâches qu’il aurait pu faire
Des temps d’attentes : par exemple, attendre les annotations avant de pouvoir réentrainer
Du passage de relais : par exemple, expliquer les nouvelles fonctionnalités du modèle pour que l’ops sache comment le déployer
Défaut : l’écart entre l’attendue et le réel, par exemple, un modèle qui ne fonctionne pas avec le reste du pipeline
Une fois la chaîne de valeur actuelle réalisée, nous devons maintenant faire la chaîne de valeur cible en essayant de supprimer les pertes, cela peut impliquer de changer l’organisation, d’automatiser des tâches, ainsi que de nombreuses autres actions.
La chaîne de valeur n’est pas figée dans le temps, il faut régulièrement la retravailler afin de pouvoir identifier de nouvelles pertes et les éliminer. Cela permet aussi de rentrer dans une démarche d’amélioration continue au sein de l’équipe.
Un exemple de chaîne de valeur
Pour rendre les choses plus concrètes, nous vous proposons un exemple de chaîne de valeur qui concentre un certain nombre de difficultés que nous avons déjà rencontrées.
Pour cet exemple, nous allons nous placer dans le cas d’une équipe chargée de réaliser les entraînements et les ré-entraînements de modèles de deep learning. Ces modèles servent à réaliser de l’inspection visuelle en usine. Il existe un modèle par usine.
L’équipe est notamment constituée des 4 profils clefs suivants :
Product Owner (PO) : C’est le relais entre les utilisateurs et l’équipe, il valide les nouveaux modèles avant de les proposer aux utilisateurs
Data Scientist (DS) : C’est le responsable de la sélection des images et du développement du modèle
Annotateur : Il annote les images sélectionnées par le Data Scientist
Ops : Récupère les modèles développés et validé afin de les déployer en production
Étape 1 : Représenter la chaîne de valeur actuelle
Nous avons construit la chaîne de valeur pour cette production de nouveaux modèles, et le résultat est le suivant :
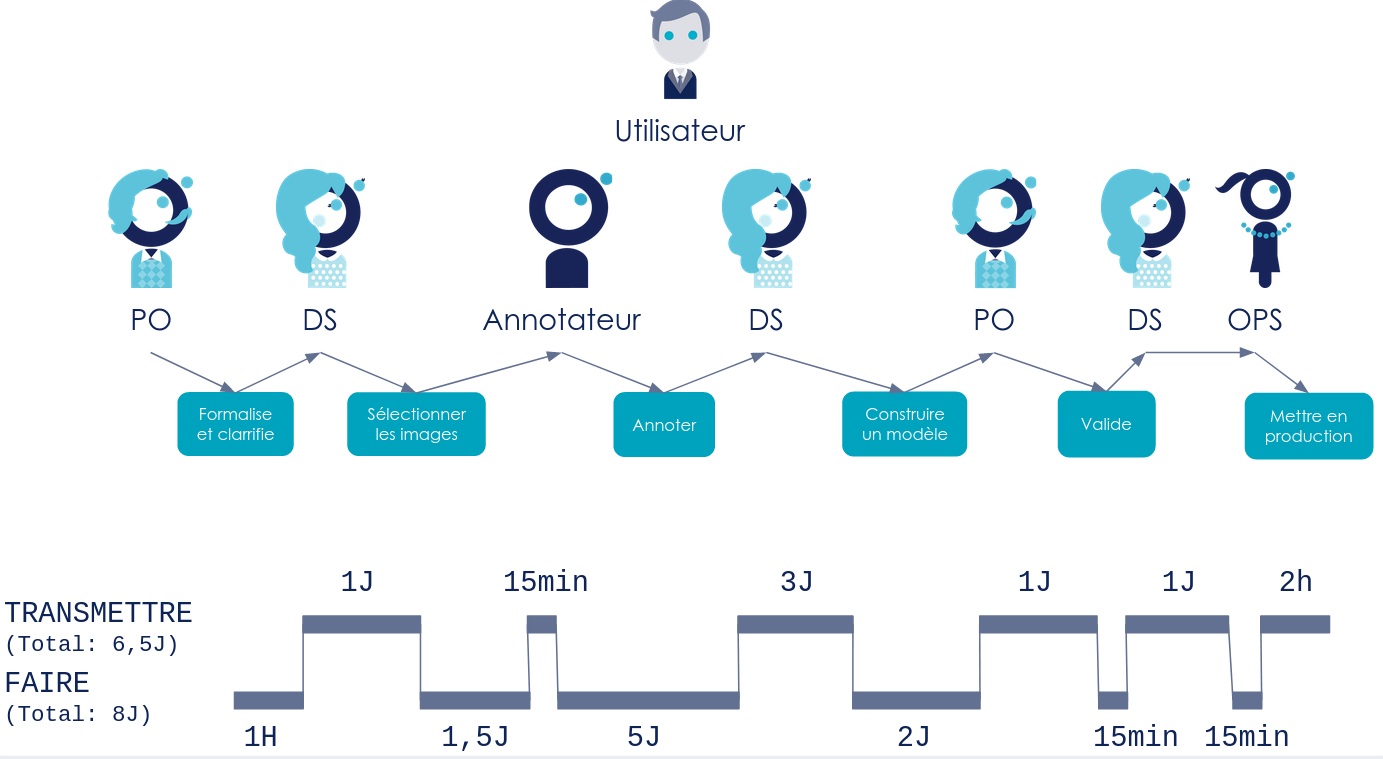
Figure 4 : Représentation de la chaine de valeur actuelle
Ce que l’on peut observer sur cette chaîne de valeur est que :
Le PO clarifie assez vite les nouveaux besoins de l’utilisateur, mais il attend le daily du lendemain pour communiquer avec le DS
La sélection d'images est chronophage : 1,5 jours. Actuellement, il faut ouvrir les images une à une pour trouver des images qui correspondent au besoin.
L’annotateur commence vite l’annotation, en effet, il est externe à l’équipe et lié à un contrat qui lui demande de commencer les chantiers d’annotations rapidement.
L’annotation quant à elle est assez longue, en effet, elle est, elle aussi, mal outillée.
Il y a un long temps de transmission avant de commencer la construction du modèle, car il faut attendre que le DS ait de la bande passante pour lancer l'entraînement.
L’entraînement prend 2 jours, avec de nombreuses tâches manuelles (exporter des variables d'environnement, lancer successivement plusieurs scripts, déplacer des images dans les bons dossiers…).
Il faut attendre le daily suivant pour que le PO sache qu’il peut valider le modèle produit. Cette validation est rapide.
Finalement, le DS s’occupe de contacter l’Ops qui lance en 15 min le pipeline de déploiement. Celui-ci met 2h à se réaliser.
À la vue de ce schéma, à la lecture de ces explications, le lecteur a sans doute un certain nombre d’idées de pertes présentent de cette chaîne de valeur. Nous vous proposons de prendre un instant de réflexion pour les lister avant de lire ce que nous proposons dans la suite.
Étape 2 : Identifier les pertes
Les pertes que l’on peut identifier dans cette chaîne de valeurs sont de différents types.
Il y a de nombreuses pertes liées à l’attente (Waiting / delays) :
- L’attente du daily suivant pour que le PO, le DS et l’Ops communiquent entre eux : en cumulé il y a environ 3 jours.
- L’attente de disponibilité du DS : il y a 3 jours de pertes
Très corrélées à l’attente, il y a 6 passations (hands off) au total. Elles ne semblent pas toutes utiles.
Comme il y a beaucoup de tâches manuelles, notamment au moment de l’entraînement, il y a sans doute un nombre important d'erreurs (defect).
Finalement, comme la chaîne de valeur est longue, il y a beaucoup de travail en cours, et probablement des choses jamais terminées.
À nouveau, nous invitons le lecteur à faire une pause dans sa lecture. Au vu des défauts que nous avons identifiés, nous vous invitons à dessiner une chaîne de valeur idéale.
Étape 3 : Réaliser la chaîne de valeur cible
Il s’agit maintenant de se projeter sur une chaîne de valeur cible. Celle-ci nous aidera à lister puis prioriser les changements à faire dans l’organisation, dans les outils, …
Voici la chaîne de valeur, telle que nous proposons de l’optimiser :
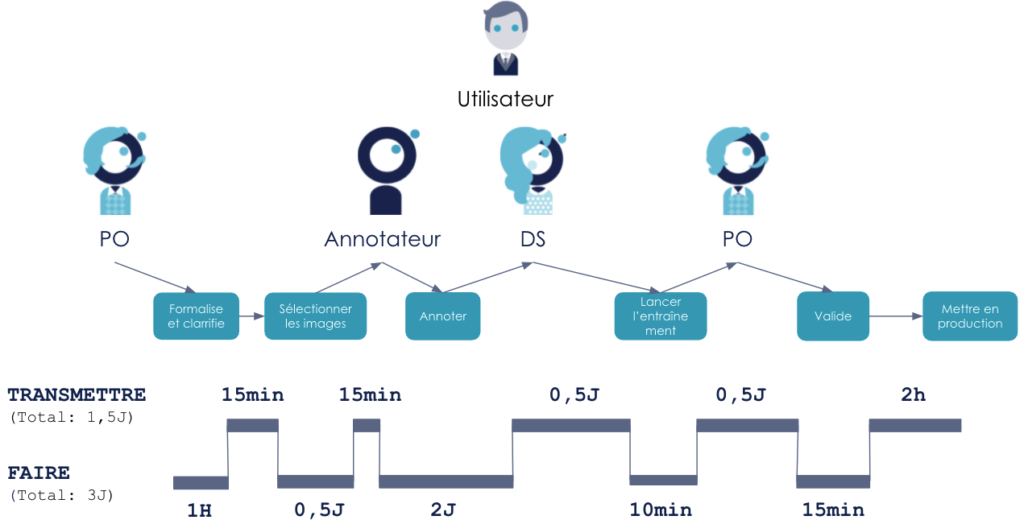
Figure 5 : Représentation de la chaine de valeur cible
Dans l’ordre des tâches, nous proposons de :
Outiller la sélection d'images pour permettre de requêter les images facilement (exemple : obtenir les images de telles pièces produites dans telle usine entre tel jour et tel jour). Cet outillage permet de gagner du temps sur la sélection d’image (1 jour) et de permettre au PO de le faire (ainsi retirer une transmission).
Rendre l'outil d’annotation plus efficace afin de gagner 3 jours sur la réalisation de cette tâche.
Automatiser autant que possible les tâches manuelles du réentraînement. Cela nous permet de réduire à 10 minutes le temps nécessaire pour lancer le réentraînement. Le DS peut donc également se libérer plus vite pour faire cette tâche.
Finalement, nous proposons de donner au PO un “bouton” qui lui permet de lancer automatiquement le déploiement en production lorsque le modèle produit lui convient.
Ces 4 actions, plus ou moins complexes à mettre en place, permettent de réduire
les transferts entre personnes et donc le changement de tâche ainsi que les temps d'attente.
les temps d’attentes à nouveau car les tâches sont plus rapide à réaliser donc plus facile à placer dans la journée
les défauts, via l’automatisation
Ces propositions d'améliorations permettent donc de passer d’un flux de création de modèle réentraîner de 15 jours à un peu moins de 4 jours. Il permet aussi de gagner du temps de travail à faible valeur ajoutée (car automatisable) et donc se consacrer sur des tâches à plus fortes valeurs ajoutées.
Étape 4 : Prioriser
Maintenant que nous avons construit une vision commune de l’organisation cible, la dernière étape est de prioriser et de faire ces changements. Cette priorisation doit considérer la complexité du changement ainsi que la valeur qu’il va apporter.
Quelques anti-patterns classiques
Au fil de nos missions, nous avons rencontré un certain nombre d’anti-patterns, de pratiques qui font que la production de valeur est ralentie. Ces patterns s’observent bien lorsque l’on pense en termes de chaîne de valeur.
Anti-pattern 1 : Les expérimentations éternelles en vue d’une performance de modèle idéalisée. Cela a souvent été vu dans des organisations/équipes qui ont du mal à mettre en production. Le pattern est que le DS fait des expérimentations à l’infini en espérant obtenir un modèle un peu plus performant. Dans ce cas, il y a beaucoup de travail non fini.
Pour résoudre ce genre de problème, nous recommandons de mettre en place dès le début un pipeline de bout en bout qui collecte les données, entraîne le modèle, fait des prédictions et les sert à un pool d’utilisateurs. Cela permettra de valider plus vite la valeur / l’utilité de certains travaux.
Anti-pattern 2 : les équipes silotées et non alignées sur un objectif commun. le DS qui produit un notebook, qu’il envoie par mail à un MLEngineer qui le transforme en librairie python, qu’il envoie par email à une équipe de MLOps en vue de la mise en production. Dans ce cas, chaque personne a son objectif propre qui ne sert pas la valeur globale. En plus de créer des tensions entre les équipes, cela augmente significativement le temps de transmission.
Pour résoudre ce genre de problème, nous recommandons de créer des feature teams qui ont un objectif commun et du collective ownership.
Anti-pattern 3 : Les tâches longues et rébarbatives que l’équipe ne prend jamais le temps de faciliter. La sélection d'images manuelles que nous proposions en exemple plus tôt en est une illustration.
Dans ce cas, le premier problème est souvent de prendre conscience en équipe des douleurs. Ce qu’il est possible de faire, c’est d’inciter l’équipe à dire en daily : “j’ai fait telle tâche et c’était long et rébarbatif”. Si la même tâche revient souvent, alors l’équipe pourra poser un ticket dans le backlog, discuter de comment la faciliter, et enfin prioriser la solution.
Conclusion
Prendre le temps, régulièrement ou ponctuellement, de visualiser la façon dont les choses se passent dans l’organisation permet d’identifier des pertes. Ces pertes en Machine Learning peuvent être du temps perdu dans des explorations inutiles, dans des hands-off entre Data Scientist, ML Engineer, MLOps, dans la réalisation de tâches non automatisées, etc.
Le delivery de Machine Learning étant un secteur qui gagne régulièrement en maturité, les outils, les besoins, voire les tâches changent régulièrement. Ces changements impliquent souvent une évolution organique de l’organisation, des rôles et des responsabilités. Il est alors d’autant plus important de visualiser et challenger régulièrement la façon dont est créée la valeur.
La représentation de la chaîne de valeur est un outil puissant et assez simple à prendre en main qui vous permettra de trouver des améliorations globales dans votre delivery et donc l’accélérer.
Remerciements : Nous tenons à remercier nos relecteurs Antoine Moreau, Basile Du Plessis, Samuel Retiere, Capucine Claude
Pour approfondir vos connaissances sur les méthodes de déploiement, consultez notre article sur les Stratégies et patterns pour déployer automatiquement un modèle de machine learning.