Rendre son code Python performant grâce au profiling
Dans ce REX, nous allons décrire comment nous sommes parvenus à diviser le temps d'exécution de notre application en Python, appelée MOMA, par 50 et stabiliser son empreinte mémoire à 200 Mo grâce au profiling. Notre application est un système de génération de fichiers binaires par traitement batch soumis à de fortes contraintes de performances (CPU & mémoire). Les fichiers binaires générés encodent des messages qui sont ensuite diffusés par satellite.
Nous allons vous décrire ici notre stratégie de refactoring et comment nous l’avons appliquée pour rendre notre code beaucoup plus rapide et stable.
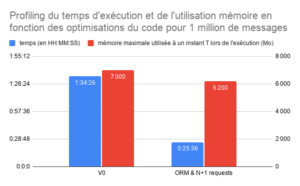
Initialement, notre application ne passait pas à l’échelle du million d’enregistrements. Pour 1 million d’enregistrements en entrée :
- l’exécution durait plus d’une heure et demie
- la mémoire dépassait les 7 Go.
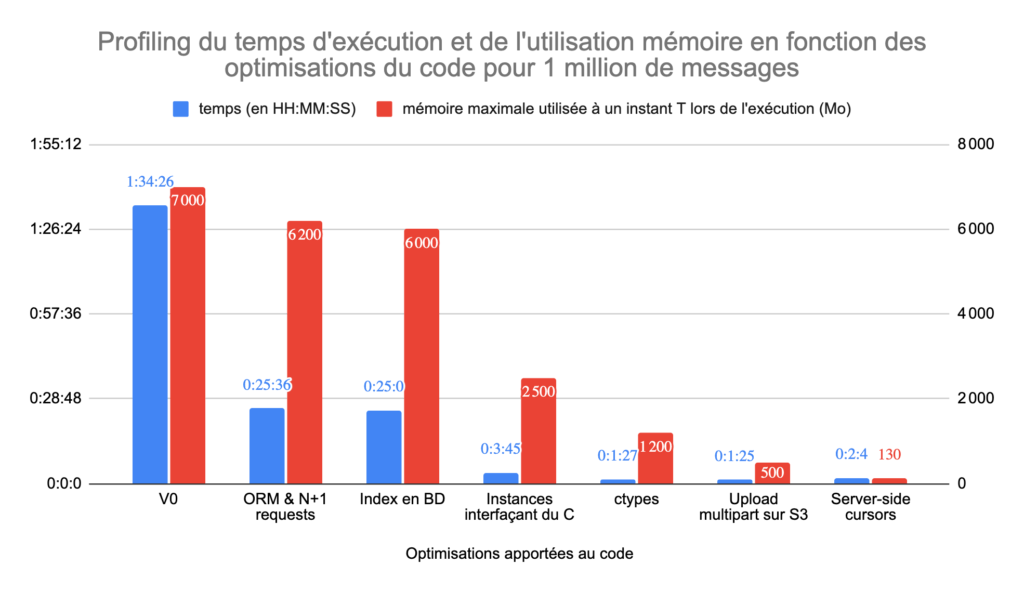
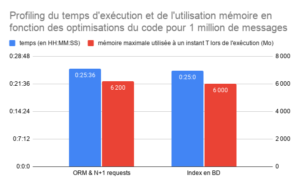
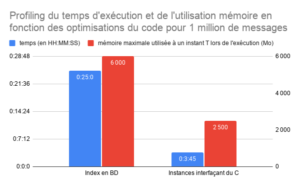
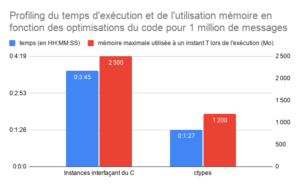
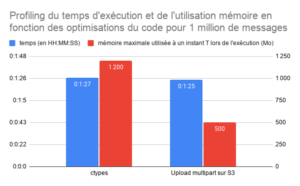
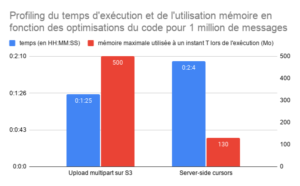
Ce graphique présente l’évolution du temps d’exécution et de l’utilisation de la mémoire de notre application en fonction des optimisations du code que nous avons apportées.
- Contexte
- 1. Optimiser la récupération des données (requêtage de la BD)
- 2. Optimiser la sérialisation de la section MPEG
- 3. Optimisation de la mémoire utilisée
- Conclusion
L’outil MOMA, quèsaco ?
Le système de génération MOMA a pour objectif de générer un fichier binaire au format MPEG, appelé carrousel, encodant des messages à destination d’abonnés Canal +.
Ces abonnés sont répartis dans différentes zones géographiques :
- l’Afrique
- les Caraïbes
- la Nouvelle Calédonie
- la Réunion
Un message adressé à un abonné fait partie d’une campagne marketing. Une campagne vise plusieurs abonnés d’une même zone géographique pendant une certaine durée (date de début et de fin de validité).
Ainsi, pour chacune de ces zones géographiques, générer le carrousel se fait en trois étapes :
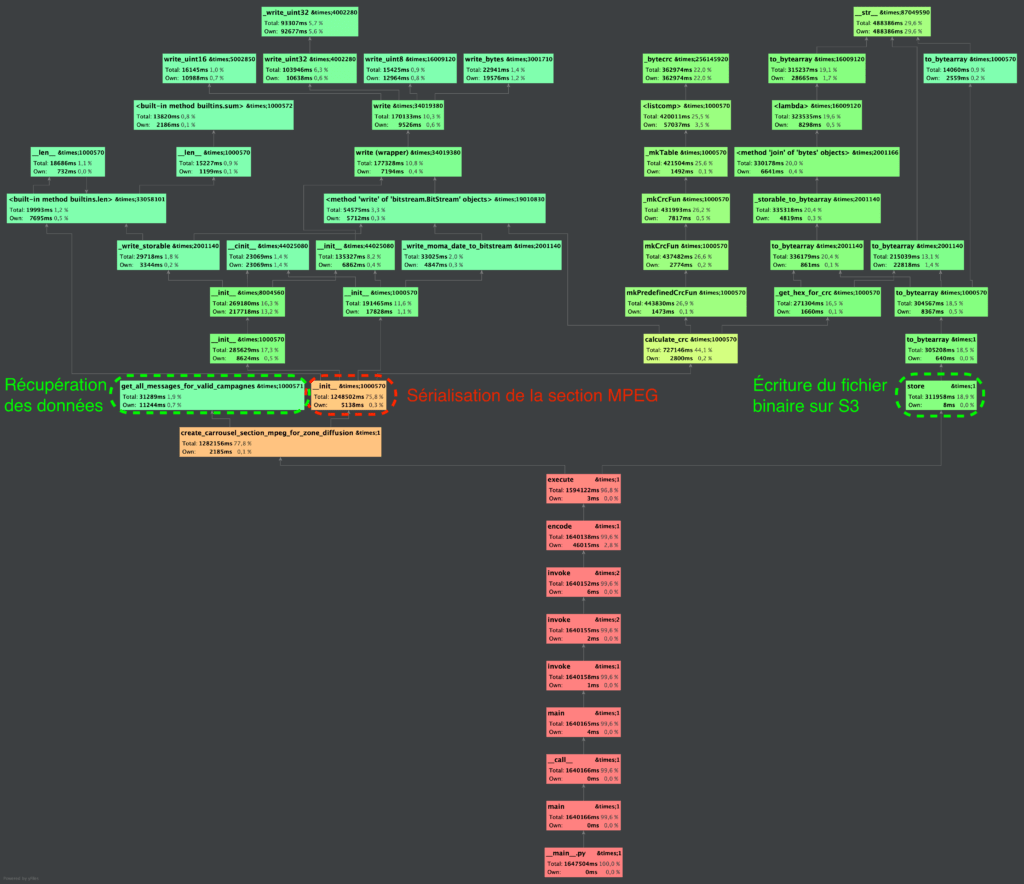
- Aller chercher les messages associés à des campagnes valides à destination d’abonnés d’une zone géographique en base de données
- Sérialiser les messages dans une structure de données binaire (bitwise)
- Écrire la structure de données binaire encodant les messages sur un dépôt de fichiers (AWS S3)
Voici un diagramme de séquence illustrant ces étapes :
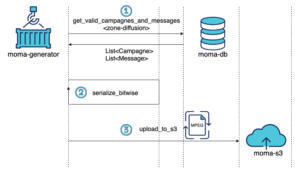
Une fois le fichier binaire généré et présent sur le dépôt de fichier (AWS S3), celui-ci est transféré du dépôt de fichiers (AWS S3) vers un autre serveur. Dès lors, il est mis en diffusion par satellite et les abonnés de la zone géographique concernée le recevront directement sur leur télévision grâce au décodeur Canal +.
Contraintes métiers et performances du système
Une telle génération a lieu plusieurs fois par jour pour chaque zone géographique. S’ensuit leur mise en diffusion imminente. Ainsi, pour assurer cette cadence de diffusion, la génération doit être de l’ordre de la dizaine de minutes pour une volumétrie en entrée de l’ordre de quelques dizaines de millions d'enregistrements.
D’autre part, notre système de génération doit pouvoir produire ce fichier binaire que la volumétrie en entrée soit de 15 000 000 d’enregistrements comme 40 000 000. Le système doit tenir la charge en conservant une empreinte mémoire stable et maîtrisée quelque soit la volumétrie en entrée.
Voici la cible que nous devons atteindre :
| Nombre d'enregistrements retournés par la BD à traiter par la génération | Durée d’exécution maximale de la génération | RAM maximale utilisable |
| 40 000 000 | 1h20 | 200 MB |
| 15 000 000 | 0h30 | 200 MB |
| __500 0__00 | 0h01 | 200 MB |
Voici les performances initiales de notre système :
| Nombre d'enregistrements retournés par la BD à traiter par la génération | Durée d’exécution maximale de la génération | RAM maximale utilisée |
| 40 000 000 | ?? | ?? |
| 15 000 000 | 17h30 | +7000 MB |
| __500 00__0 | 0h35 | 6000 MB |
Il s’agit de diviser le temps de génération par 35 et l’usage de la mémoire par plus de 30.
Code profiling
Le code profiling est une technique permettant d'analyser l’exécution d’un logiciel pour en connaître son comportement à l’exécution (Wikipedia).
Il permet de se rendre compte lors de l’exécution d’un logiciel de :
- la liste des fonctions appelées et le temps passé dans chacune d'elles
- l'utilisation processeur
- l'utilisation mémoire
Cette technique est utilisée pour identifier les goulots d’étranglement dans le code à des fins d’optimisation.
Stratégie et outillage pour réduire le temps d’exécution et l’empreinte mémoire
Pour réduire le temps d’exécution, nous avons adopté la stratégie suivante :
- Exécuter notre application de génération avec du profiling (temps d’exécution et charge mémoire)
- Cibler l’opération la plus chronophage dans l’exécution proportionnellement à la durée totale d’exécution
- Comprendre pourquoi l’opération est si chronophage
- Refactorer l’opération pour la rendre moins chronophage
- Réitérer au point 1. jusqu’à avoir un temps d’exécution total satisfaisant
Pour réduire l’empreinte mémoire, nous avons utilisé un profiler de mémoire de deux manières :
- En annotant les appels de fonctions qu’on pense être gourmands en mémoire
- En exécutant notre application via le profiler pour avoir un rapport de l’usage mémoire globale au cours du temps.
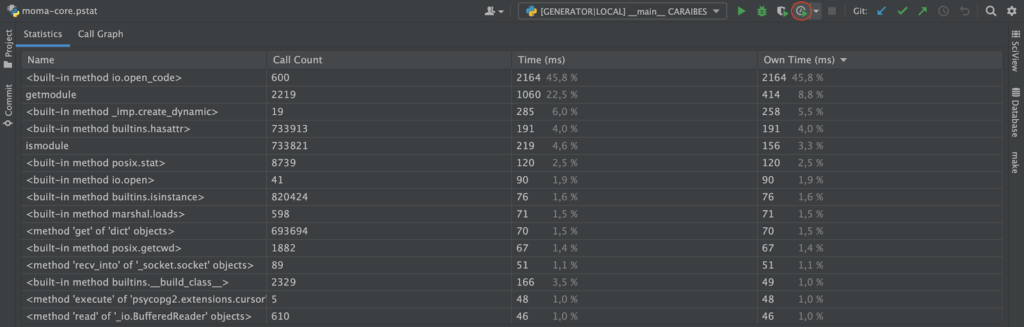
Les outils que nous avons choisi sont :
- PyCharm (1) et son mode d’exécution profilé pour les durées d’exécution
- memory_profiler une librairie Python pour mesurer l’empreinte mémoire
Voici un aperçu dans PyCharm (2) :
Considérations générales
Dans notre quête de réduction du temps d’exécution, nous ne voulions pas complexifier l'architecture de l'application, dans un souci de maintenabilité. En conséquence, les pistes faisant appel à de la parallélisation, comme du multiprocessing ou du multithreading, ne seront explorées qu’en dernier recours. L’idée est de s’efforcer de comprendre l’impact de chaque ligne de code en l’état et d’apporter les optimisations nécessaires. Si ces optimisations n’étaient pas suffisantes, les pistes de la parallélisation seraient à envisager.
D’autre part, nous n’exécutons qu’une seule fois notre application avec du profiling avant de chercher des optimisations, car il n’est pas envisageable de lancer plusieurs exécutions profilées lorsque celles-ci durent plusieurs heures. En effet, notre code est déterministe et s'exécute toujours de la même façon.
1. Optimiser la récupération des données (requêtage de la BD)
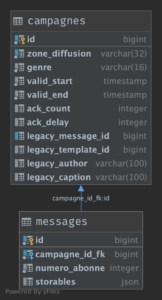
- la table messages : contient des messages à destination des abonnés
- la table campagnes : contient des campagnes marketing pour différentes zones géographiques et avec leurs plages de temps de diffusion
Une campagne regroupe un ensemble de messages. La table messages contient donc une clé étrangère vers la table campagnes.
Pour pouvoir récupérer les différents messages associés aux campagnes valides, il faut :
- Filtrer les campagnes pour récupérer celles qui sont valides
- Récupérer tous les messages associés à ces campagnes par une jointure sur l’identifiant de campagne (clé étrangère).
ORM & N+1 requests
Pour rappel, Wikipédia nous définit un ORM (object-relational mapping) comme étant une interface entre un applicatif et une base de données relationnelle. Il fait le lien entre les schémas de la base de données et le modèle objet de l’application. C’est une couche d'abstraction facilitant les échanges entre le monde objet et le monde relationnel.
Pour MOMA, nous utilisons l’ORM peewee pour sa simplicité et sa légèreté.
Définition
Le problème des N+1 requêtes est un problème classique qui peut arriver lors du requêtage d’une base de données à travers un ORM. Lorsqu’une application fait une première requête à une base de données, puis au moins une requête pour chacun des enregistrements retournés par cette première requête, alors nous sommes dans une situation de N+1 requêtes.
Notre usage de la base de données
Nous requêtons la base de données pour récupérer toutes les campagnes valides, puis pour chaque campagne valide, tous les messages associés.
<br>SELECT *<br>FROM campagnes<br>WHERE c.valid_start <= ? AND c.valid_end >= ? AND ... ;<br>
Et pour chaque campagne retournée :
<br>SELECT *<br>FROM messages<br>WHERE messages.campagne_id_fk = ?;<br>
Notre choix d’implémentation consiste à faire une requête pour récupérer les campagnes valides puis, pour chaque campagne valide, une requête pour récupérer ses messages associés.
Constat et problèmes
Dans ce cas, nous nous attendions à réaliser :
- une requête pour récupérer une liste de P campagnes valides (P étant le nombre de campagnes valides)
- P requêtes pour récupérer les messages associés à chacunes de ces P campagnes
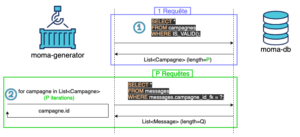
Or, en faisant du profiling, nous nous sommes rendu compte que notre application réalisait beaucoup plus de requêtes qu’attendu (>P+1).
Voici le code Python pour récupérer les campagnes et les messages associés :
<br>valid_campagne_entities = CampagneEntity.select().where(<br> (fn.date_trunc("day", CampagneEntity.valid_start) <= current_date)<br> & (current_date <= fn.date_trunc("day", CampagneEntity.valid_end))<br> & (CampagneEntity.zone_diffusion == zone_diffusion))<br><br>for campagne_entity in valid_campagne_entities:<br> campagne = campagne_entity.to_model()<br> for message_entity in MessageEntity.select().where(MessageEntity.campagne == campagne_id):<br> message = message_entity.to_model()<br> DO_SOME_STUFF(campagne, message)<br>
Rien de surprenant dans ce code. Allons voir les objets MessageEntity et CampagneEntity.
Voici le code implémentant l’objet ORM MessageEntity faisant le pont entre la table messages de la base de données et l’objet Python Message :
<br>class MessageEntity(BaseEntity):<br> class Meta:<br> table_name = "messages"<br><br> id = BigAutoField(...)<br> campagne = ForeignKeyField(...)<br> numero_abonne = BigIntegerField(...)<br> storables = JSONField(...)<br><br> def to_model(self) -> Message:<br> return Message(self.campagne.id, self.numero_abonne, self.storables)<br>
La méthode to_model permet de construire un objet Message (notre objet Python modélisant un message au sens métier) à partir d’un objet MessageEntity (objet de l’ORM qui représente la modélisation en base de données).
L’investigation nous a montré qu’à chaque instanciation d’un objet Message l’usage de self.campagne.id impliquait une requête supplémentaire pour résoudre la clé primaire de la campagne associée. Ainsi, pour une campagne valide en BDD associée à 5 messages, nous avons :
- 1 requête en BDD pour récupérer la campagne valide
- 1 requête pour récupérer les messages associés
- 5 requêtes supplémentaires pour résoudre la clé primaire de la campagne associée aux 5 messages.
Soit 7 requêtes au total au lieu des 2 initialement attendues.
Dans le schéma ci-dessous, nous nous focalisons sur la partie de la requête qui récupère des messages associés à chaque campagne valide et nous génère des requêtes supplémentaires non-souhaitées. On peut notamment voir qu’une requête pour récupérer les messages associés à une campagne valide génère Q requêtes supplémentaires :
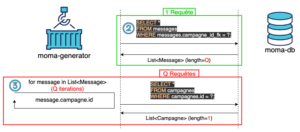
Pour rappel, dans un scénario idéal, on aurait :
- 1 requête en BDD pour récupérer la campagne valide
- 1 requête en BDD pour récupérer les messages associés.
Soit 2 requêtes (cf ce schéma).
Solution
Pour résoudre ce problème, il nous a suffit d’utiliser directement l’attribut campagne_id_fk de l’objet MessageEntity qui est valorisé lorsqu’un message est récupéré de la BD.
<br>class MessageEntity(...):<br> [...]<br> campagne = ForeignKeyField(column_name="campagne_id_fk", ...)<br><br> def to_model(self) -> Message:<br> return Message(self.campagne_id_fk, self.numero_abonne, self.storables)<br>
Take away
- Être vigilant aux requêtes SQL réellement produites par notre code applicatif. Par exemple en activant le logging des requêtes SQL au niveau de l’ORM et/ou au niveau de la base de données
- Les ORMs sont des outils puissants, souvent bien optimisés, mais à manier avec précaution. Bien prendre le temps de s’approprier la documentation de son ORM pour en connaître les bonnes pratiques et les limites.
- Lire attentivement la documentation de son ORM au sujet des bonnes pratiques à suivre pour prévenir le phénomène de N+1 requests.
- Ne pas hésiter à creuser le code sous-jacent aux objets de l’ORM car ils peuvent impliquer des requêtes en BDD.
- Utiliser les objets de l’ORM uniquement pour interagir avec la BDD pour éviter toute erreur d’utilisation qui pourrait engendrer des requêtes à la BDD.
Ajout d’index en BD
Définition
Selon Wikipedia :
En informatique, dans les bases de données, un index est une structure de données utilisée et entretenue par le système de gestion de base de données (SGBD) pour lui permettre de retrouver rapidement les données. L'utilisation d'un index simplifie et accélère les opérations de recherche, de tri, de jointure ou d'agrégation effectuées par le SGBD.
L’index placé sur une table va permettre au SGBD d'accéder très rapidement aux enregistrements, selon la valeur d'un ou plusieurs champs.
Notre usage de la base de données
Nous requêtons toujours la base de données de la manière suivante :
<br>SELECT *<br>FROM messages m<br> JOIN campagnes c on c.id = m.campagne_id_fk<br>WHERE c.valid_start <= ? AND c.valid_end >= ? AND ... ;<br>
Constat et problèmes
Nous avons réalisé un EXPLAIN (4) sur notre requête SQL pour comprendre la stratégie du moteur de requête PostgreSQL pour exécuter cette requête. Voici le résultat :
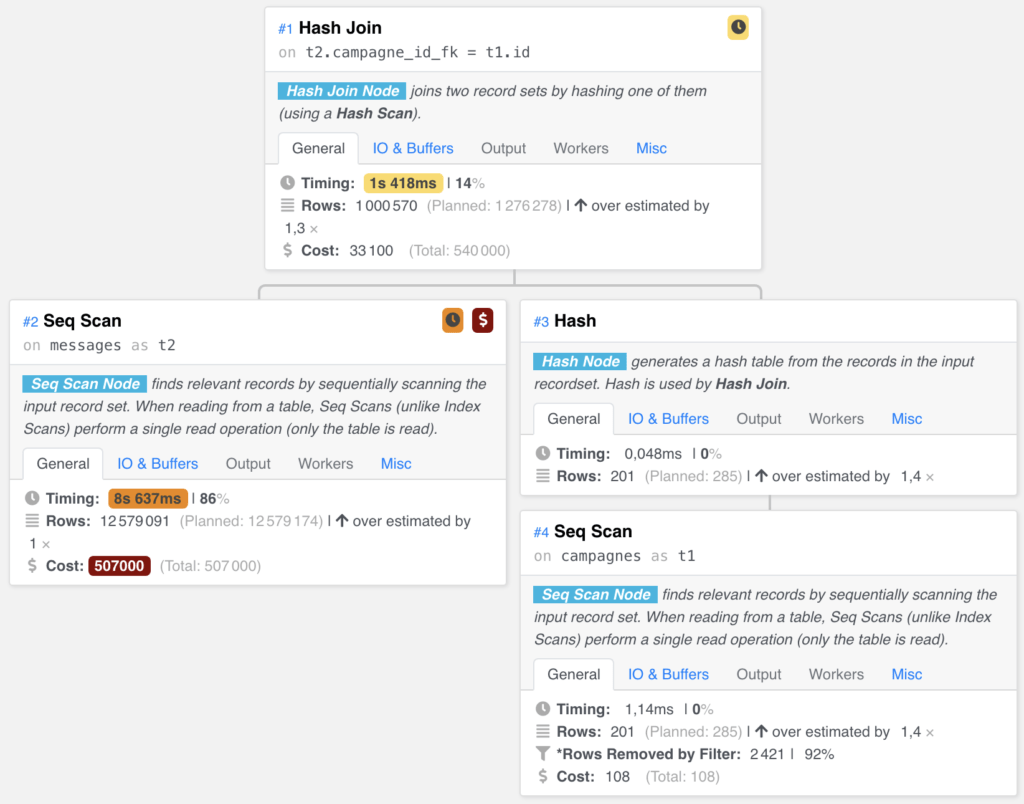
Nous nous sommes aperçu qu’il faisait :
- Un scan séquentiel pour trouver les campagnes valides (en bas à droite dans l’image #4 Seq Scan),
- un autre scan séquentiel pour récupérer tous les messages (en bas à gauche #2 Seq Scan),
- une jointure par hachage pour récupérer seulement les messages associés à des campagnes valides (en haut #1 Hash join).
Nous pensions que le moteur de requête ferait une jointure d’index entre les clés primaires des campagnes et les clés étrangères des messages (campagne_id_fk). Pour information, les scans séquentiels sont les opérations les plus lentes à exécuter.
En creusant la documentation, nous avons découvert que par défaut Postgresql ne pose pas d’index sur les clés étrangères. En effet la documentation stipule la chose suivante :
A foreign key must reference columns that either are a primary key or form a unique constraint. This means that the referenced columns always have an index (the one underlying the primary key or unique constraint); so checks on whether a referencing row has a match will be efficient. Since a DELETE of a row from the referenced table or an UPDATE of a referenced column will require a scan of the referencing table for rows matching the old value, it is often a good idea to index the referencing columns too. Because this is not always needed, and there are many choices available on how to index, declaration of a foreign key constraint does not automatically create an index on the referencing columns.
Solution
Nous avons posé un index sur la clé étrangère campagne_id_fk de la table messages puisqu’elle devrait être constamment utilisée dans la jointure entre les tables :
<br>CREATE INDEX campagne_id_fk_index ON MESSAGES (campagne_id_fk);<br>
Pour le vérifier, nous avons créé cet index et exécuté à nouveau la requête avec EXPLAIN :
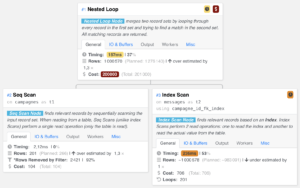
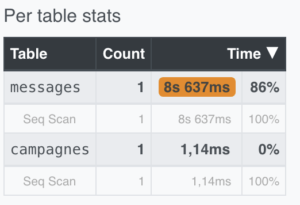
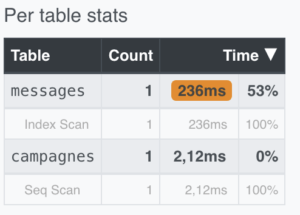
Nous voyions désormais que le moteur de requête réaliserait un scan d’index pour récupérer les messages valides. De plus, en comparant les temps passés sur chaque tables, nous constations que le temps a grandement diminué grâce à l’index :
Enfin, nous avons posé un index sur le champ zone_diffusion de la table campagnes, puisque ce champ est utilisé pour effectuer une sélection sur la zone de diffusion en question (6) :
<br>CREATE INDEX zone_diffusion_index ON CAMPAGNES (zone_diffusion);<br>
En revanche, le moteur PostgreSQL n’utilise pas cet index, car la sélection est faite sur trois champs : zone_diffusion, valid_start et valid_end. Or, pour être utilisés les index doivent être compatibles avec la clause WHERE. Ceux-ci peuvent être incompatibles pour diverses raisons :
- index incompatible avec le type de recherche effectuée (index “normal” sur une chaîne texte et les recherches sont de type LIKE)
- Application d’une fonction sur la colonne indexée (index “normal” sur une date et on cherche à filtrer sur le mois en tronquant la date)
- Les valeurs passées doivent être exactement du même type que la colonne indexée
Puisque trois champs interviennent dans notre requête, il faudrait construire un index multi-colonne. De plus, deux des champs de sélection sont des dates tronquées. Ainsi construire un tel index multi-colonne n’a rien de trivial. Sachant que le requêtage à la BDD n’était plus le goulot d'étranglement principale, nous avons abandonné la piste de ce dernier index multi-colonne.
Take away
- Attention à la base de données relationnelle utilisée, certaines ne posent pas d’index par défaut sur les clés étrangères (Postgresql notamment).
- Si un champ est régulièrement utilisé pour faire une sélection, poser un index dessus peut accélérer cette sélection. Mais attention, cela dégradera vos insertions, suppressions et modifications !
- Bien vérifier avec la commande EXPLAIN de PostgreSQL qu’une optimisation (comme un index) a un impact sur la stratégie mise en œuvre par le moteur pour exécuter la requête. Attention notamment aux index multi-colonne qui sont plus complexes à mettre en œuvre.
- Ne pas perdre de vue la stratégie globale d’optimisation de notre application (optimiser l’instruction la plus chronophage), on peut rapidement perdre beaucoup de temps à essayer d’optimiser une requête à la base de données pour un gain négligeable voire nul.
2. Optimiser la sérialisation de la section MPEG
Après avoir récupéré les messages valides pour une zone géographique, il faut les sérialiser dans une structure de données binaire permettant une manipulation bit à bit.
En effet, le fichier binaire résultant de la génération, appelé section MPEG, doit respecter la spécification DVB (Digital Video Broadcasting). Celle-ci spécifie notamment comment doivent être agencés les champs à encoder, elle s’appuie sur le schéma d’encodage TLV (Type-Length-Value), c’est-à-dire :
- Type : une série de bits qui indique le type de champ à venir ;
- Length : une série de bits qui indique la taille du champ Value ;
- Value : une série de bits de taille Length encodant des données.
Pour pouvoir générer une section MPEG, il est nécessaire de pouvoir manipuler une structure de données à l’échelle du bit.
Utilisation d’une librairie implémentée en Cython (bitstream)
Pour nous faciliter la tâche, nous avons fait le choix de nous appuyer sur la librairie bitstream. Cette librairie est implémentée en Cython. Cython est à la fois un compilateur et un langage de programmation. Cython permet d’étendre le langage C en utilisant Python. Le langage est assez proche du Python et permet d’obtenir jusqu’à un facteur 100 sur les performances.
Constat et problèmes
Pour sérialiser une section MPEG, par facilité d’implémentation, nous avons répété l’instanciation d’objets Bitstream volontairement plusieurs fois. En voici un aperçu au travers de la classe SectionHeader qui modélise l'en-tête d’une section MPEG :
<br>class SectionHeader:<br> [...]<br><br> def __init__(self, campagne: Campagne, message: Message):<br> self.table_id = BitStream(0x92, np.uint8)<br> self.section_syntax_indicator = BitStream(0b0, bool)<br> self.reserved_future_use = BitStream(0b1, bool)<br> self.reserved = BitStream([0b1, 0b1], bool)<br> self.section_length = BitStream()<br> self.index = BitStream(0, np.uint8)<br> self.total_count = BitStream(1, np.uint8)<br> self.target_filter = BitStream(message.numero_abonne, np.uint32)<br> self.network_id = BitStream(campagne.zone_diffusion, np.uint8)<br> self.message_id = BitStream(campagne.id, np.uint32)<br> self.template_id = BitStream(message.template_id, np.uint32)<br> self.genre = BitStream(campagne.genre, bytes)<br> self.valid_start = BitStream()<br> self.valid_end = BitStream()<br> self.message_ack_count = BitStream(campagne.ack_count, np.uint8)<br> self.message_ack_delay = BitStream(campagne.ack_delay, np.uint16)<br> self.offset_appearance = BitStream(0, np.uint16)<br> self.offset_filter = BitStream(0, np.uint16)<br> self.offset_addressee = BitStream()<br>
Le problème de cette implémentation est que chaque instanciation d’un objet BitStream crée une structure C sous-jacente avec une allocation mémoire. Or le changement de contexte (Python vers C), l’overhead, est extrêmement coûteux en temps d'exécution.
Solution
Pour diminuer l’overhead, nous avons limité l’instanciation d’objet BitStream au strict minimum. Nous nous sommes appuyé sur la méthode write de bitstream comme suit :
<br>class SectionHeader:<br> [...]<br><br> def __init__(self, campagne: Campagne, message: Message):<br> self.debut = BitStream()<br> self.debut.write(0x92, np.uint8)<br> self.debut.write(0b0, bool)<br> self.debut.write(0b1, bool)<br> self.debut.write([0b1, 0b1], bool)<br><br> self.section_length = BitStream()<br><br> self.fin = BitStream()<br> self.fin.write(0, np.uint8)<br> self.fin.write(1, np.uint8)<br>
Cependant, nous n’avons pas pu réduire le nombre d’instances de cet objet à un seul, car un certain nombre de champs dans la section MPEG sont à valoriser avant de pouvoir en valoriser d’autres positionnés en amont dans la section. Il faudrait disposer d’une méthode d’insertion sur un BitStream, qui n’est pas disponible. D’où les trois instanciations visibles dans le code ci-dessus.
Enfin, la réduction de ces instances a également permis de réduire l’empreinte mémoire.
Take away
- Utiliser des librairies interfaçant d’autres langages (C, Fortran, par exemple), plus performants en temps de calcul que celui du runtime pour exécuter une tâche précise, permet de gagner en performance et de ne pas réinventer la roue.
- Attention toutefois à l’overhead engendrant une perte de performance si la librairie est utilisée à mauvais escient.
- Attention aussi à la surcharge de la mémoire liée aux multiples instanciations.
Utilisation des ctypes en Python
Définition
“ctypes est une bibliothèque d'appel à des fonctions externes en python. Elle fournit des types de données compatibles avec le langage C et permet d'appeler des fonctions depuis des DLL ou des bibliothèques partagées, rendant ainsi possible l'interfaçage de ces bibliothèques avec du pur code Python.”
En d’autres termes, la bibliothèque ctypes permet d’exécuter du code C en écrivant du pur code Python. Rappelons, que le langage C est un langage de programmation bas niveau et compilé : deux caractéristiques qui le rendent extrêmement performant. En outre, il laisse à la charge du développeur la gestion de la mémoire. Ainsi, en C nous pouvons allouer des buffers de mémoire de taille souhaitées de manière très simple et directe.
Enfin, la bibliothèque ctypes définit plusieurs types de données de base compatibles avec le C, par exemple : le type c_uint en Python représente le type unsigned int en C.
Constat et problèmes
Rappelons que pour sérialiser, nos sections MPEG nous faisons toujours face à de multiples instanciations d’objets interfaçant du C via la librairie bitstream. En effet, si on regarde dans les sources de bitstream, lorsqu’on souhaite écrire un bit (méthode write_bool ici), le buffer est augmenté à la volée, ligne 762 :
<br>stream._extend(1)<br>
Or la méthode _extend, ici, s’appuie sur la fonction realloc, ligne 220:
<br>self._bytes = <unsigned char *>realloc(self._bytes, new_num_bytes)<br>
Et réallouer un buffer, utiliser realloc(), pénalise les performances, car cette méthode crée un autre buffer, recopie dedans le contenu du premier buffer, et supprime ce premier buffer. Pour optimiser les performances, une solution est de pré-allouer un buffer suffisamment grand pour ne jamais avoir à invoquer cette fonction.
Enfin, bitstream fonctionne "bit à bit" dans le sens où les bits produits ne sont pas des bits "calés" sur des frontières de 8 bits. Ceci n'est pas efficace, car les processeurs travaillent avec des mots (64 bits maintenant) et il est préférable de travailler avec des structures de données au plus proche du mot du processeur.
Pour revenir à ces instanciations, certes elles sont en nombre très limités mais elles restent notre goulot d’étranglement principal en matière de temps d’exécution.
Solution
S’appuyer sur les ctypes pour allouer une structure de données sur mesure. En effet, ctypes permet de définir des structures comme dans le langage C. Ces structures définissent des champs avec une taille et un type. De plus, le choix du bit de poids fort est également paramétrable (BigEndianStructure / LittleEndianStructure) ce qui est important pour nous, la spécification nous imposant un encodage en BigEndian. Enfin, nous avons également la possibilité d’overrider la façon dont le compilateur C va aligner les champs pour qu'ils soient contigus.
Ainsi, nous avons défini une telle structure pour faciliter la sérialisation et réduire l’overhead à son minimum :
<br>class HeaderStruct(BigEndianStructure):<br> _pack_ = 1<br> _fields_ = [("header_table_id", c_uint32, 8),<br> ("header_section_syntax_indicator", c_uint32, 1),<br> ("header_reserved_future_use", c_uint32, 1),<br> ("header_reserved", c_uint32, 2),<br> ("header_total_count", c_uint8),<br> ...<br> ]<br><br> def set_header_struct(self, campagne: Campagne, message: Message):<br> self.header_table_id = 0x92<br> self.header_section_syntax_indicator = 0b0<br> self.header_reserved_future_use = 0b1<br> self.header_reserved = 0b11<br> self.header_template_id = message.template_id<br> self.header_genre = campagne.genre.value.encode("utf-8")<br> ...<br>
Take away
- Penser à la bibliothèque ctypes de Python quand des traitements bas niveau nécessitent d’être performant
- Envisager l'utilisation de bibliothèque interfaçant des langages bas niveau / plus performants dédiés à des traitements spécifiques (numpy pour le calcul matriciel par exemple)
Autres pistes envisagées
Nous avons également envisagé d’autres pistes pour la sérialisation. Celles-ci n’ont pas été retenues car elles ne permettaient pas de répondre aux contraintes de performances. Voici ces pistes et la raison de leur abandon :
- La librairie Python bitstring : sous le capot la librairie instancie beaucoup d’objets Python et manipule l’objet bytearray sans se préoccuper des impacts sur la performance (recopie de tableau, redimensionnement).
- Implémentation d’une librairie Python custom s’appuyant sur le bytearray : nous avons implémenté notre propre librairie de sérialisation en nous inspirant de la librairie bitstring. L’idée était de s’appuyer sur l’objet bytearray avec parcimonie en économisant les coûts de recopie et de redimensionnement du tableau. Malgré cela, les performances n’étaient pas au rendez-vous, car la manipulation de bits (décalage de bits) a un coût important et la solution à base de ctypes avait abouti plus tôt.
3. Optimisation de la mémoire utilisée
Écriture du fichier binaire en multipart sur S3
La dernière étape de la génération consiste à écrire la section MPEG sur un dépôt de fichiers (AWS S3).
Constat et problèmes
Initialement, pour écrire sur s3, nous attendions d’avoir terminé la génération de la structure binaire encodant le carrousel d’une zone de diffusion. Or, attendre que tout le carrousel soit encodé pour l’écrire signifie garder en mémoire tous les messages encodés composant ce carrousel et il n’est pas inhabituel de compter des millions de messages par carrousel. Enfin, rappelons qu’un message a une taille maximale de 4096 bits soit 512 octets. Ainsi, un carrousel composé de 2 millions de messages aura une taille pouvant aller jusqu’à 1 Go.
<br>carrousel_section_mpeg = create_carrousel_section_mpeg_for_zone_diffusion(zone_diffusion, current_date)<br><br>store(output_filename, carrousel_section_mpeg)<br>
Solution
Pour améliorer l’usage de la mémoire, nous avons mis en place un mécanisme d’upload à la volée en s’appuyant sur les file-like object Python et la bibliothèque smart_open.
En Python, les différents types d’IO (entrée / sortie) sont gérés par le module io. Celui-ci permet de gérer l’écriture et la lecture de texte, de binaires et de raws. Le file-like object implémente une API orientée fichier avec les méthodes de lecture et d’écriture (read() et write()) s’interfaçant avec n’importe quel type d’IO (texte, binaire, raw).
La bibliothèque smart_open permet de lire / d’écrire en streaming de très gros fichiers de manière efficace depuis / vers des systèmes de stockage (S3, GCS, Azure Blob Storage) en implémentant l’API orientée fichier des file-like objects. Pour gérer l’écriture en streaming sur S3, smart_open s'appuie sur le multi-part upload de S3. Dans les coulisses, smart_open crée un buffer dans lequel on écrit réellement à chaque appel de la méthode write() et dès que la taille du buffer atteint une taille de 50 MB, celui-ci (correspond à une Part au sens du multi-part upload de S3) est uploadé sur S3 avec le mécanisme de multi-part upload.
Ainsi, nous avons refactoré notre implémentation de cette manière :
- Ouverture d’un flux en écriture sur S3 avec smart_open
- Itération sur tous nos messages à encoder dans la structure de données binaire
- Écriture de chaque structure de données binaire sur ce flux
Voici notre classe permettant d’ouvrir un flux en écriture sur S3 avec smart_open :
<br>from smart_open import open<br><br><br><br>class SectionMpegAwsS3StorageAdapter:<br><br> def upload(self, filename: str) -> IO:<br> url = "s3:///"<br> transport_params = {"session": boto3.Session(),<br> "multipart_upload": True,<br> "resource_kwargs": {"endpoint_url": ...}}<br> return open(url, "wb", transport_params=transport_params)<br>
Voici le code orchestrant l’ouverture du flux, l’itération sur les messages et l’écriture dans le flux :
<br>with section_mpeg_aws_s3_storage_adapter.upload(output_filename) as f:<br> for campagne, message in get_all_messages_for_valid_campagnes(...):<br> f.write(MessageSectionMpeg(campagne, message).to_bytearray())<br>
Grâce à ce mécanisme, nous utilisons moins de 200 Mo de mémoire, et ce quelque soit le nombre de messages en entrée. Ainsi, aucun risque d’atteindre la limite mémoire de la machine.
Take away
- L’écriture à la volée est une manière élégante de maîtriser la consommation mémoire
- Attention toutefois aux IO, ce sont les opérations les plus lentes en temps d’exécution : il y a un compromis à trouver entre temps d’exécution et usage de la mémoire (taille limite d’un buffer avant écriture réelle)
Récupération des données par chunk (server-side cursors)
Constat et problèmes
La récupération des données peut impacter considérablement la mémoire. En effet, si notre requête retourne 1 million d’enregistrements, notre ORM va construire 1 million d’objets Python correspondant en mémoire. De plus, l’ORM a un mécanisme de cache qui permet d’éviter de requêter à nouveau la BDD. Ceci permet d’exécuter plusieurs fois la même requête en ne l’exécutant qu’une fois côté BDD. Cependant, ce mécanisme de cache a un coût en mémoire qui ne permet pas une exécution limitée à notre contrainte de départ de 200 MB de mémoire.
Solution
Pour pallier ce problème, nous avons utilisé les server-side cursors de psycopg2 (9)(10).
Par défaut, lorsque psycopg2 exécute une requête, tous les résultats sont récupérés et renvoyés au client par le backend. Cela peut amener notre application à utiliser beaucoup de mémoire lors de requêtes volumineuses.
En utilisant les "curseurs côté serveur”, les résultats sont renvoyés progressivement, par chunk (par défaut par 2000 enregistrements). Ceci permet de soulager grandement la mémoire du côté client (notre application) qui récupère ces enregistrements.
Nous avons dû refactorer notre code requêtant la base de données pour ne requêter la base qu’une seule fois. Pour rappel, cela se fait en deux étapes :
- Une requête pour récupérer les campagnes
- Pour chaque campagne retournée, une requête pour récupérer les messages associés
<br>valid_campagne_entities = CampagneEntity.select().where(<br> (CampagneEntity.valid_start <= current_date) & ...)<br><br>for campagne_entity in valid_campagne_entities:<br> campagne = campagne_entity.to_model()<br> for message_entity in MessageEntity.select().where(MessageEntity.campagne == campagne_id):<br> message = message_entity.to_model()<br> DO_SOME_STUFF(campagne, message)<br>
Or, pour simplifier l’utilisation du server-side cursor, nous avons fusionné les requêtes en une, en exécutant la jointure côtés BDD :
<br>all_valid_messages = MessageEntity.select(...)<br> .join(CampagneEntity)<br> .where((CampagneEntity.valid_start <= current_date) & …)<br><br>for (...) in all_valid_messages:<br> campagne = Campagne(...)<br> message = Message(...)<br> DO_SOME_STUFF(campagne, message)<br>
Ainsi, la base de données effectue la jointure plutôt que de la faire applicativement. Ceci est plus performant en termes de :
- Exécution : la base de données pourra éventuellement faire des optimisations sur la requête en déplaçant des contraintes
- Trafic réseau : une seule requête à la base de donnée, donc un seul aller-retour vers la base de données
Enfin, il ne reste plus qu’à instancier l’objet approprié pour utiliser un server-side cursor :
<br>query = MessageEntity.select(...)<br><br>return ServerSide(query, array_size=self.SERVER_SIDE_CURSOR_CHUNK_SIZE))<br>
Take away
- Ne pas hésiter à déporter un maximum de logique de requêtage sur la base de données (les SGBD sont faits pour exécuter du SQL, pas le Python)
- Les ORMs sont des outils puissants, souvent bien optimisés, mais à manier avec précaution. Bien prendre le temps de s’approprier la documentation de son ORM pour en connaître les bonnes pratiques et les limites
- Les servers-side cursors sont très utiles lorsque le client qui requête la BDD a des contraintes de mémoire.
Conclusion
Lorsque l’on a des contraintes de performances, il est important de maîtriser les impacts de chacune de ses lignes de code. Pour comprendre ces impacts (instructions chronophages et / ou gourmandes en mémoire), les profilers de temps d’exécution et de mémoire sont très utiles.
Il est important d’adopter une démarche stratégique, telle que détaillée en début de cet article, pour s’attaquer aux plus gros problèmes de performance en premier et mesurer systématiquement l’évolution résultant de l’optimisation. On évitera ainsi de perdre de l’énergie sur une optimisation qui apparaîtra complètement dérisoire au début alors qu’elle sera potentiellement réellement bénéfique plus tard.
Dans cette quête d’optimisation, on retrouve des “suspects habituels” que sont le requêtage à la base de donnée (ORM & N+1 requests, index) pour le temps d’exécution et les multiples instanciations d’objets pour l'utilisation de la mémoire.
Par ailleurs, rendre son code plus performant implique souvent de faire des concessions sur sa simplicité voire sur l’architecture elle-même du code (nous avons opté pour une architecture hexagonale). Il y a toujours un compromis à faire entre performance et simplicité ; c’est ce qu’on évoquait dans les considérations générales vis-à-vis du multiprocessing ou multithreading.
Enfin, pour aller plus loin, nous aurions pu imaginer des implémentations plus complexes à base de multithreading pour paralléliser les IO (requêtage à la BD et écriture sur le S3). Cependant, les performances atteintes après la mise en place de ces optimisations étaient satisfaisantes pour nous et nous ne voulions pas complexifier plus notre base de code pour un gain minime.
(1) PyCharm n'est qu'une interface au profiler cProfile
(2) Attention, cette fonctionnalité n'est disponible que sous PyCharm dans sa version Professional
(3) Les couleurs sont réutilisées plus bas pour illustrer le propos.
(4)
<br>EXPLAIN (ANALYZE on, TIMING on) SELECT *<br>FROM "campagnes" AS "t1", "messages" AS "t2"<br>WHERE ("t1"."id" = "t2"."campagne_id_fk") AND ((("t1"."zone_diffusion" = 'AFRIQUE') AND (date_trunc('day', "t1"."valid_start") <= '2021-02-04')) AND (date_trunc('day', "t1"."valid_end") >= '2021-02-04'));<br>
(5) construit avec le PostgreSQL execution plan visualizer conçu par Dalibo
(6) Pour rappel, la génération d’un carrousel se fait par zone géographique.
(7) Le temps d’exécution ne baisse pas significativement car celui-ci est borné par le reste de la génération (sérialisation binaire) qui devient plus chronophage.
(8) 
(9) psycopg2 est un adaptateur de base de données PostgreSQL très populaire en Python.
(10) peewee fait appel à psycopg2 lorsque la base de données utilisée est une base PostgreSQL.