Rendre représentatif ce qu’on observe : l’exemple des données Twitter pour l’élection présidentielle 2022
Cet article fait partie de la série “Analyse de tendances des réseaux sociaux” traitant des méthodologies pour la construction de ces solutions.
Lorsque l’on souhaite créer un outil d’analyse de tendance à partir des réseaux sociaux, il est très important de définir le périmètre de ce que l’on souhaite analyser. La plus grande erreur est de partir directement sur l'extraction d'informations sans avoir parlé de représentation et pondération. En effet, comme nous le montrerons dans cet article, nous pouvons faire émerger des messages très différents à partir de mêmes données observées. L’objectif sera donc de vous donner les bases méthodologiques à la construction d'un outil d'analyse de tendances cohérent à partir de ces données observées. Nous prendrons ensuite l'exemple du projet laVoixDesElections.fr pour apprécier l'importance de cette méthodologie dans l'analyse des données des réseaux sociaux.
I. Les bases méthodologique de l'interprétation d'une analyse de tendances
Définir la population de référence
Lorsqu’on parle d’analyse de tendances, c’est qu’on se retrouve avec du contenu observé sur lequel nous souhaitons conjecturer des résultats. Il est alors important de définir la problématique, le sujet, la population que nous voulons étudier. Nous désignerons comme population de référence l'ensemble de tous les éléments concernés par la problématique ou l'étude (figure 1).

Figure 1 : représentation de la population de référence
Par exemple, si nous souhaitons étudier le comportement des français, la population de référence va être composée de 67 millions d'éléments, où chaque élément est une personne française.
Construire un résultat représentatif
Souvent le contenu observé ne concerne qu’un échantillon de ces éléments qui composent la population de référence (figure 2).

figure 2 : Contenu observé
Si nous voulons déduire des résultats sur notre population de référence nous allons donc devoir extrapoler l’information (figure 3). Cette fonction d’extrapolation va généralement consister à pondérer les éléments observés pour être représentatif de la population de référence. Toutes ces méthodologies sont très fortement utilisées lors de sondages ou d’études quantitatives et permettent à moindre coût d’avoir des résultats beaucoup plus représentatifs du phénomène étudié (= population de référence).

Figure 3 : Fonction d’extrapolation
Encadré : Comprendre la différence entre Sondage et Recensement
Aujourd’hui, le sondage a une définition légale : “enquête statistique visant à donner une indication quantitative, à une date déterminée, des opinions, souhaits, attitudes ou comportements d'une population par l'interrogation d'un échantillon”.
Le sondage analyse donc partiellement la population en vue d’une extrapolation à l’ensemble de la population (=population de référence). À l’opposé, on parle de recensement lorsqu’on analyse exhaustivement la population de référence.
Bon à savoir : Depuis 2004, le “recensement” français n’est plus une enquête exhaustive de la population française, mais fait intervenir des méthodes de sondage
Les sondages politiques sont principalement réalisés selon la méthode des quotas (vs méthode aléatoire) :
Concrètement, l’objectif est d’interroger un échantillon de personnes (1000-10000) qui ont des caractéristiques socio-démographiques (âge, CSP, région, sexe) très proches de la population de référence. On applique ensuite une fonction d’extrapolation (ou pondération) à chaque enquêté pour redresser les résultats bruts et obtenir exactement les proportions socio-démographiques de la population de référence (facilement disponible grâce aux résultats du recensement français).
La difficulté à définir la population de référence et les éléments qui la composent
Il n’est pas toujours simple de construire cette fonction d’extrapolation, car on ne peut pas obtenir aisément les paramètres qui permettent de pondérer et/ou parfois nous ne sommes pas au clair sur ce qu’est réellement notre population de référence. Pour la population française, il était assez aisé de dire qu’un élément représente une personne et que la population de référence est composée d’un peu plus de 67 millions d’éléments ayant chacun le même poids.
Cela devient plus compliqué lorsque nous souhaitons réaliser une enquête pour mesurer l’activité des entreprises françaises. En effet, nous approximons souvent la notion d’entreprise en France par l’unité légale (le SIREN). Nous nous retrouvons donc avec plus de 4 millions d'éléments. Nous pourrions alors extrapoler simplement les résultats d’une enquête réalisée sur 1000 unités légales pour représenter l’ensemble des entreprises françaises. Seulement, nous faisons le postulat que chaque unité légale dans notre population de référence a la même importance. Ce qui revient à dire que l’unité légale “TotalEnergies” a le même poids que l’unité légale du restaurant indépendant de votre quartier. Il apparaît clair que nous avons mal calibré la composition de notre population de référence. Nous pouvons par exemple pondérer les résultats par le chiffre d’affaires tout en ayant en tête que d’autres problèmes apparaîtront : non prise en compte de la notion de groupe et des comptes consolidés, plus fort poids des secteurs à fort chiffre d’affaires (exemple Commerce), etc.
Bien définir la population de référence, les éléments qui la composent et la fonction d’extrapolation constituent les bases pour assurer une bonne représentativité des résultats. Tout outil d’analyse de réseaux sociaux pour étudier un phénomène ne peut faire l’impasse de ce travail.
Cas particulier de l’analyse de tendance
Nous avons défini la problématique à observer et nous savons comment obtenir des résultats représentatifs. Il nous reste à étudier la spécificité que représente l’analyse des tendances : il faut rajouter un axe temporel pour suivre dans le temps les caractéristiques de notre population de référence (figure 4).

Figure 4 : Ajouter un axe temporel
Nous identifions deux principales méthodologies pour retirer de la valeur permettant de définir des tendances dans le contenu observé :
Baromètres :
On peut créer des baromètres, pour donner la photographie d’un phénomène à des instants différents. L’objectif est de mesurer une même information (par exemple dans le contexte d’enquêtes, on envoie le même questionnaire) à des instants “t” différents (t+1, t+2,etc.). Nous travaillons toujours avec un contenu observé qui peut ne représenter qu’un sous échantillon de la population de référence à l’instant t de l’observation. L’échantillon observé peut ainsi être totalement différent entre t et t+1. Nous devons donc encore extrapoler le contenu pour rendre comparable les valeurs des baromètres à chaque instant (figure 5). L’évolution d’un baromètre est un moyen très efficace pour détecter des tendances globales : Passer d’un sujet qui représente 32% à 45% de la population de référence est sans doute signe d’une importance grandissante.
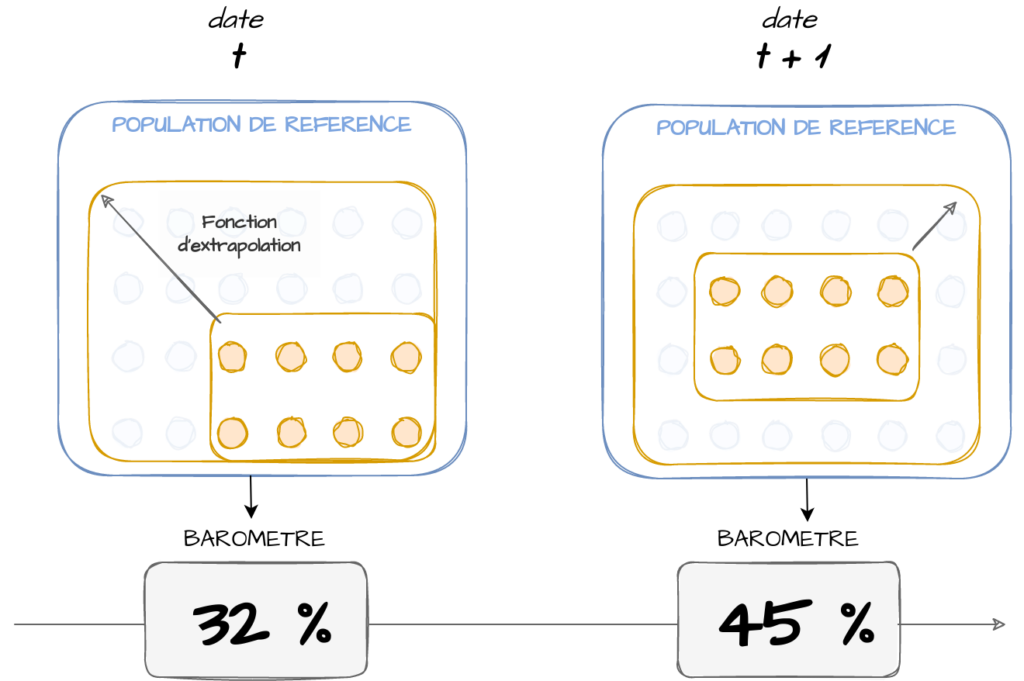
Figure 5 :suivre un baromètre
Panels :
On peut sinon s’intéresser à des évolutions au sein de mêmes éléments. On va regarder l’évolution dans le temps d’individus sélectionnés censés être représentatifs de la population de référence. La différence avec le baromètre consiste à suivre ces mêmes individus dans le temps. Cela donne la possibilité d’analyser plus finement les évolutions et permet de quantifier des changements de comportements : ceux qui préféraient le produit A ont tendance à préférer le produit B aujourd’hui (figure 6).
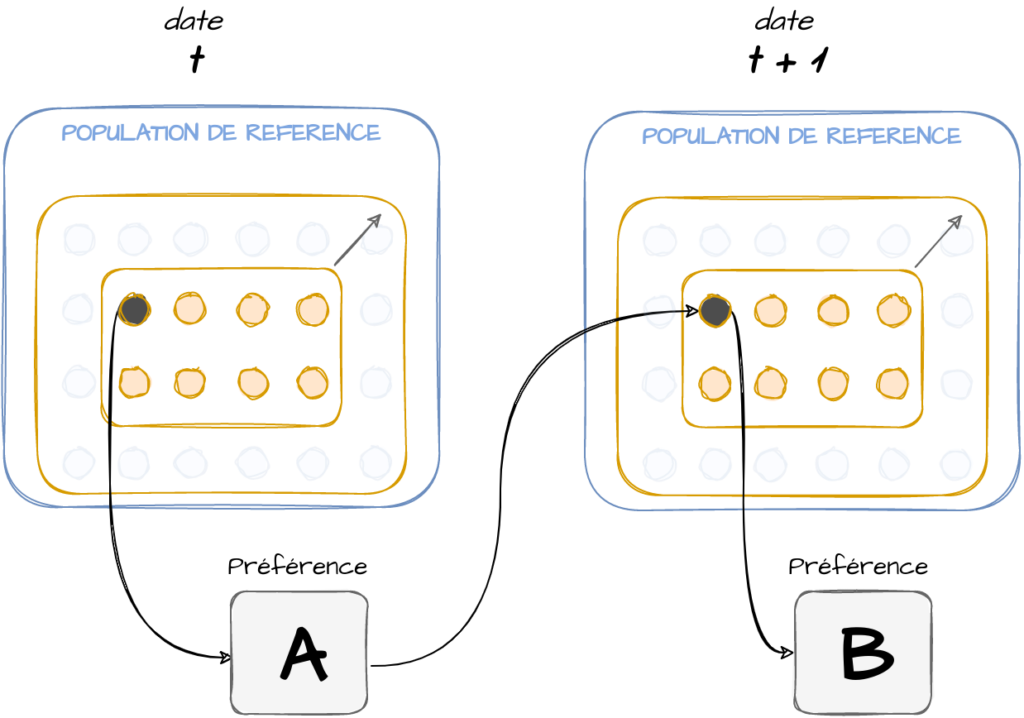
Figure 6: suivre des panels
II. L’exemple "la voix des élections" : Analyser les tendances politiques à partir des tweets
Maintenant que nous sommes au clair sur tous les sujets de représentativité de résultats, essayons de nous poser ces questions sur un exemple concret. Je vous propose d’étudier en particulier un projet personnel “www.LaVoixDesElections.fr” qui permet de suivre en temps réel les thématiques les plus abordées sur la scène politique des élections 2022 sur Twitter.
Définir notre population de référence
En utilisant l’API Twitter vous pouvez simplement être en écoute sur des tweets qui contiennent un certain contenu ou qui ont été postés par des utilisateurs sélectionnés. Pour ce projet j’ai fait le choix de capturer le contenu des principaux candidats à l’élection 2022 : Le contenu observé contient donc tous les tweets contenant une liste de hashtags précis et/ou postés par des comptes utilisateurs identifiés comme probable candidat. Les résultats que nous pouvons déduire de ce contenu dépendront de notre capacité à les rendre représentatifs de quelque chose de concret. Il est clair que déduire des résultats sur la population française à partir de la simple activité sur Twitter est très compliqué, car l’activité sur le réseau social ne représente qu’un sous-échantillon assez faible de la population française.
La fonction d’extrapolation est ainsi très difficile à construire. Une méthode classique consiste à réaliser des enquêtes quantitatives (exemple ici des sondages politiques) pour estimer la fonction d’extrapolation qui permet à partir du contenu Twitter d’être représentatif de l’activité politique française. On pourrait essayer de construire une fonction d’extrapolation pour lier les résultats de chaque candidat avec les intentions de vote mesurées par les très nombreux sondages disponibles. Pour information, les instituts de sondage réalisent ce travail par exemple après chaque résultat d'élections pour adapter leur fonction d’extrapolation.
Si la fonction d’extrapolation est compliquée nous pouvons essayer d’expliquer un périmètre plus restreint (figure 7). À partir de la source de données décrite précédemment, notre contenu observé permettra très efficacement de décrire l’activité politique sur Twitter des principaux candidats.

figure 7 : Simplifier la population de référence pour simplifier la fonction d’extrapolation.
Définir la méthode d’extrapolation
Maintenant que nous avons commencé à définir des populations de références possiblement explicables par notre contenu observé, nous devons définir clairement ce qui constitue un élément de notre analyse. Si nous travaillons seulement sur les tweets, nous nous retrouvons directement avec le problème de représentativité évoqué en partie 1. En effet, est-il adéquat de considérer comme aussi important un tweet avec plus de 10000 retweets et un simple tweet sans retweet ? Nous pouvons définir autant de représentations que nous le souhaitons. Chacune ont leurs avantages et leurs inconvénients. Quelques exemples de représentations possibles :
Version SIMPLE :
- 1elt = un Tweet (ou Un retweet avec un commentaire)
- fonction d’extrapolation = identité
C’est la représentation la plus simple. On se contente d’analyser seulement les tweets ou retweets contenant du texte et on n’applique aucune fonction d’extrapolation.
Version RETWEET - basique
- 1elt = 1 Tweet :
- fonction extrapolation = nombre de retweets
Une version classique de représentation de l’activité sur Twitter consiste à considérer chaque tweet comme un élément, et de pondérer par le nombre de retweets.
Version RETWEET2 - améliorée
- 1elt = 1 tweet ou 1 retweet :
- fonction extrapolation = identité
Afin de mieux observer l’activité liée à des tweets, il est également intéressant de considérer une variante de la précédente, où on définit comme un élément tout Tweet ou Retweet. Ainsi si un tweet parle d'Éducation et est fortement retweeté pendant 3 jours, nous pouvons alors mesurer dans notre baromètre que la thématique Éducation est restée durant 3 jours un sujet important. Ça n'aurait pas été possible avec la version précédente, c’est pourquoi nous préférons cette représentation de l’activité.
Version INTENTIONS
- 1elt = 1 tweet ou 1 retweet
- fonction extrapolation = poids des intentions de votes du candidat cité
Afin de représenter l’activité des élections françaises à partir des tweets. Nous pouvons utiliser les intentions de votes de chaque candidat pour construire la fonction d’extrapolation.
Concrètement si à un instant t les éléments (=1 tweet ou 1 retweet) provenant d’un candidat A représentent 10% des éléments observés alors que les derniers sondages font état de 30% d’intentions de votes pour ce candidat, nous pouvons appliquer un poids de 3 à tous les éléments de ce candidat.
Une grande analyse implique une grande représentativité
Il faut avoir conscience que les différentes représentations décrites dans la partie précédente amèneront à des résultats qui peuvent être assez différents. Prenons un exemple simple pour apprécier ces conséquences sur les résultats. Essayons de déduire le poids des thématiques “Éducation” “Immigration” “Climat” dans l’ensemble des tweets et retweets entre le 1er octobre et le 27 décembre (on travaille quand on peut :) ) des sept candidats aux intentions de vote les plus élevées à la date du 27 décembre.
Sept candidats sélectionnés :'Marine Le Pen', 'Emmanuel Macron','Valérie Pécresse', 'Anne Hidalgo', 'Jean-Luc Mélenchon', 'Yannick Jadot', 'Eric Zemmour'
Les trois versions de représentation nous amènent à travailler sur le contenu suivant :
- Version SIMPLE : Soit un total de 7420 tweets ou retweets (avec commentaire) envoyés par les candidats
- Version RETWEET2 : Soit un total de 2153750 tweets et retweets réagissant à cette activité des candidats.
- Version INTENTIONS : Nous pondérons le poids des tweets en utilisant l’excellente source NspPolls qui recense les sondages politiques des élections (https://github.com/nsppolls/nsppolls). Nous pouvons ainsi calculer à un instant t les intentions de vote pour chaque candidat et construire une pondération permettant de respecter le poids de chaque candidat dans les intentions de vote.
Si on observe le poids de chaque thématique (tableau 1), le message global n’est pas tout à fait le même entre les versions.
- Dans la version RETWEET2, la thématique la plus présente est l’immigration représentant 4.1% de l’activité politique.
- Dans la version INTENTION, la thématique la plus présente est le CLIMAT représentant 5.2% de l’activité politique.

Tableau 1 : poids et rang des thématiques en fonction de la représentation choisie.
En plus du poids global, les tendances dans le temps peuvent être légèrement différentes selon la version choisie (figure 8) : certains pics peuvent être plus ou moins marqués (exemple en novembre sur le sujet immigration).
Figure 8: Poids des thématiques en fonction de la représentation choisie
Note de lecture : Le climat représente 5.54% des messages si on utilise la représentation version “SIMPLE” contre 3.01% avec la version “retweet2” et 5.16% avec la version “Intentions”.
En conclusion, si l’on pondère en fonction des intentions de votes pour être plus représentatif de l’ensemble de la population française (du moins celle qui vote) la thématique du Climat est la principale thématique (5.2% de l’activité politique) ; alors que si on se contente d’être représentatif de l’activité sur Twitter (Retweet2) la thématique “Immigration” devient la principale thématique. Le choix d’une pondération n’est donc pas anodin lorsque nous construisons des baromètres ou tout outil d’analyse de tendances.
Décrire la méthodologie appliquée est sans doute la meilleure façon pour rendre compréhensible ses résultats, car pour paraphraser George Box, toutes les fonctions d’extrapolation sont fausses, mais certaines sont utiles !
Remarque : une représentation qui réduirait le poids des candidats et followers qui ont une tendance à retweeter de nombreuses fois est également en cours d’étude. Cette représentation permettrait de réduire le poids de certains candidats qui maîtrisent parfaitement Twitter en inondant de plusieurs petits tweets.
Construire un contenu pour l’analyse de tendances
Comme vu précédemment il y a deux principales façons d’analyser des évolutions ou tendances.
Créer des baromètres et étudier l’évolution de notre contenu observé
En faisant l’hypothèse que notre périmètre reste constant nous pouvons étudier l’évolution de ce baromètre dans le temps. Ainsi nous pouvons étudier les thématiques qui semblent être de plus en plus présentes au sein du contenu observé, et en déduire sans trop d'erreur qu’il se passe quelque chose sur cette thématique, par exemple (figure 9) : “le mois d’octobre, 25 % de l’activité sur Twitter des candidats concernaient l’éducation contre 2% un mois auparavant”.
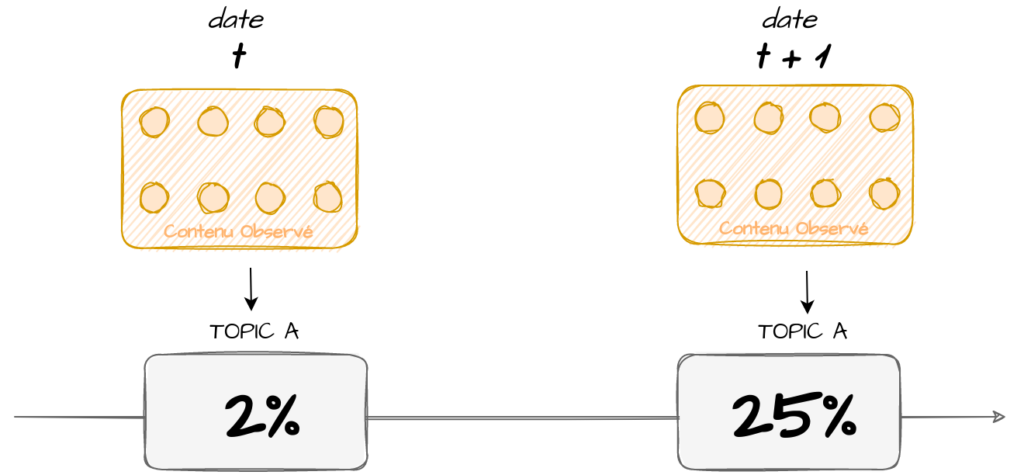
figure 9 : Suivre une thématique dans le temps
Nous devons cependant nous assurer que le périmètre reste constant et corriger toutes évolutions de celui-ci, par exemple :
- L’ajout d’un nouveau candidat dans l’écoute des tweets
- Ou si Twitter modifie des paramètres qui impacteront le contenu collecté, par exemple augmenter la longueur max d’un tweet.
- Etc.
Suivre des panels en étudiant l’évolution d’un ensemble d’utilisateurs
La deuxième manière de récupérer de la valeur est de s’intéresser à des évolutions de comportement parmi un ensemble d’utilisateurs. Cela permet d’afficher des résultats de la forme : X pourcent de tous ceux qui ont retweeté positivement un candidat A le mois dernier, ont retweeté positivement un candidat B. L’analyse de ces évolutions de comportement peut bien évidemment donner des informations intéressantes notamment entre deux tours.
Le défaut des panels est qu’ils ne permettent pas de mesurer les nouveaux entrants. Pour évaluer ce problème, il est intéressant d’essayer de mesurer le poids des nouveaux entrants.
Conclusion
Voilà ! Je vous ai donné une vision très rapide des bases méthodologiques pour s’assurer une bonne représentativité de ce que l’on observe : Travail nécessaire à toute valorisation de données de réseaux sociaux.
Réfléchissez donc au phénomène que vous voulez décrire : définissez votre population de référence et les éléments qui la composent ; puis décrivez la méthodologie pour extrapoler des résultats à partir du contenu observé. Grâce à cette rigueur vous serez confiants dans les informations que vous construirez (baromètre ou suivi de panels).
Vous êtes maintenant prêts à extraire de l’information du contenu observé ! Vous ferez appel aux méthodologies de Natural Language Processing (NLP) si vous travaillez avec des données texte ou voix ; ou à des méthodologies de Computer Vision si vous analysez des données images ou vidéos. Vous retrouverez ces contenus dans notre série d’articles sur la création d’un outil d’analyse de tendances de réseaux sociaux.