React Paris 2026 – CR – Killing Micro Frontends
PayFit a supprimé ses micro-frontends. Leur CI est passé de 45 à 7 minutes, leurs déploiements de 2-5 jours à 20 minutes et leur vélocité multipliée par 17. Voici un retour d'expérience sur une migration qui a pris 2 ans, avec 2,5 ingénieurs, sur une base de code utilisée par ~100 développeurs et 22 équipes.
Cet article est un compte rendu du Talk Killing Micro Frontends How Radical Simplification 10x'd Our Frontend Velocity - Nicolas Beaussart à la conférence de React Paris 2026.
Le problème : le pire des deux mondes
PayFit avait 4 implémentations différentes de micro-frontends à travers 15+ repos.
Le contexte :
- ~100 ingénieurs
- Beaucoup de surface frontend
- Beaucoup de couplage cross-domain
- L'hypercroissance cachait la complexité, la décélération l'a exposée
La réalité :
- CI de 45 minutes (quand ça marchait)
- Des tests flaky
- Livrer une feature prenait 2-5 jours
- Déploiement en production : 2 fois par semaine (par peur)
- 32 repos pour construire une seule app frontend
- 6 bundlers différents
- NPM publish entre repos
"On avait le pire des deux mondes : le couplage d'un monolithe, le coût de coordination des micro-frontends. Un distributed big ball of mud."
Pourquoi leur premier monorepo a échoué
Ils avaient déjà essayé le monorepo mais ça n’avait pas fonctionné. Les raisons :
- Mandaté d'en haut (pas de buy-in)
- Équipes non formées et non supportées
- DX pourrie
- Ownership devenu flou
- Les équipes l'ont donc abandonné
Le problème n'était pas l'outillage mais le manque de confiance et de platformisation.
La stratégie : autant de trust que de tech
Leur plan :
- Supprimer la variation
- Consolider dans un monorepo
- Unifier l'outillage
- Automatiser le delivery
- Prouver la valeur par l'exécution, pas par le mandat
La partie difficile n'était pas technique mais de faire embarquer les gens.
Nettoyer la maison avant d'inviter les invités
Unifier les bundlers : 6 → 1
Avant : TS App, TS Build, Webpack, TypeScript (tsc), Vite, Rollup. Tous avec des configs uniques par lib.
Après : Vite partout. Configuration uniforme, quelques options et c'est tout.
Unifier les versions de third parties
Problème : plusieurs versions de React dans la même application. Plusieurs versions majeures de la même librairie. Plus de 100 librairies sont concernées. Par exemple, ils étaient bloqués sur React 16 à cause de ça.
Solution : unification incrémentale + tooling qui vérfie qu'on ne régresse pas.
Résultat : Le hot reload fonctionne à nouveau dans tout le monorepo. Avant, changer une librairie nécessitait de rebuild toutes les librairies et redémarrer le serveur de développement. Parfois le hot reload Webpack ne marchait pas.
Maintenant : un changement n’importe où dans le code et le hot reload se fait correctement.
Traiter la santé de la plateforme comme du travail produit
Documentation packagée dans Starlight (par Astro) avec une recherche qui marche. Nx leur a donné :
- Task inference (projets qui marchent out of the box)
- Dependency graph (pour enfin voir le bordel)
- Nx conformance (pour vérifier que les standards sont respectés)
- Nx generators (pour créer de nouvelles librairies facilement et à la norme)
CI : première preuve tangible
Ils ont utilisé Nx Cloud pour :
- Du distributed caching
- De la parallélisation
Les chiffres en 2025 (sur l'année) : 5 ans de CI time économisés, soit 2001 jours (48 024 heures).
Pour profiter de ça, il fallait être sur le monorepo. Ça a créé l'incitation.
- Nx agents : task distribution automatique. Plus de runners = plus rapide.
- Flaky tests : Nx Cloud identifie les tests flaky grâce à de l’auto-retry et fournit des statistiques. On peux aller voir les équipes : "Ce test fail 40% du temps, ça nous a coûté 2h de CI."
- Monitoring CI : Datadog pour tracker l'évolution. Alertes si la CI pend plus de 10 minutes. Résultat : CI passé de 45 minutes à 7. Le P95 sur tous le monorepo est de 20 minutes (894 tâches).
Construire la confiance : traiter le monorepo comme un produit
Le monorepo n'est pas juste une destination technique. Ça doit devenir un produit que les équipes veulent adopter.
Build in public
- Visible à tout l'engineering
- Les décisions, trade-offs, blockers et progrès sont partagés tôt et souvent
- Les équipes voyaient le momentum, pas juste des promesses
- Le travail effectué n'était plus mystérieux
- La confiance a grandi parce que la platforme est devenue lisible
Public demo : trust engine
Rituel mensuel pendant 2 ans :
- Montrer les dernières améliorations et migrations
- Montrer ce qui est devenu plus facile
- Montrer ce qui fait encore mal (transparence)
- Collecter le feedback en live
- Transformer ce feedback en prochaines améliorations
Demo + discovery + support + preuve sociale en un seul rituel.
Public roadmap
- Ce qui a ship
- Ce qui est en cours
- Ce qui est bloqué
- Ce qui vient après
- Où les équipes peuvent influencer les priorités
La plateforme est devenue quelque chose que les équipes pouvaient façonner, pas juste consommer.
NDLR : Voir la plateforme comme un produit, c’est exactement ce qu’on recommande chez OCTO avec les APIs, à retrouver dans Culture API.
Early adopters = design partners
- Choisir quelques équipes prêtes à bouger en premier (early adopters)
- Les over-supporter
- Transformer leur feedback en améliorations
- Transformer leurs victoires en preuve visible pour les autres
L'adoption est devenue organique parce que la valeur est devenue évidente.
Mapper le système
Avant de migrer, il faut comprendre ce qu'on a.
Le graph qu'ils ont construit :
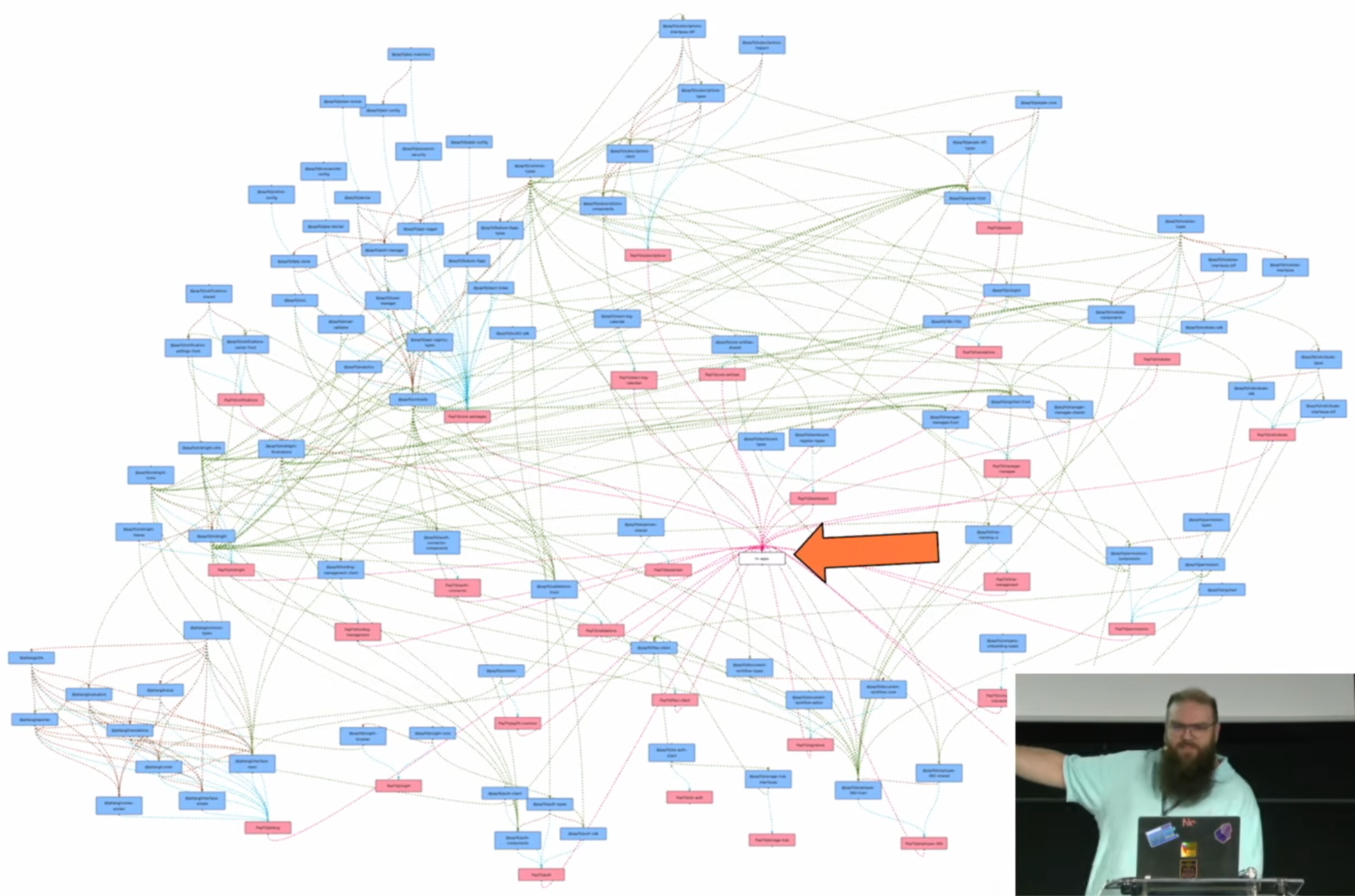
- Chaque boîte bleue : une librairie publiée sur NPM
- Chaque boîte rouge : un monorepo
- Au milieu : le monorepo frontend principal
Certaines librairies existaient sur NPM, mais le code source n’était plus accessible. Code minifié, utilisé en prod, critique, mais personne ne savait ce qu’il contenait ni ne pouvait le modifier.
Le graph leur a appris :
- Les repo boundaries ne matchaient pas les change boundaries
- Quelques hubs tiraient trop de librairies
- Certains packages semblaient indépendants mais évoluaient toujours ensemble
- L'unité de migration n'était ni le repo ni la librairie : c'était le cluster
- Circular dependencies possibles entre monorepos via NPM (grâce aux peer versions)
Ils ont identifié :
- Les Shared platform clusters
- Les Domain clusters
- Les heavy hubs et chokepoints
- Les cas qui forçaient des releases cross-repo
- Les repos que personne ne voulait toucher où qui étaient “mort”
Le principe : migrer le code qui change ensemble, pas le code qui semble juste partagé.
La boucle de migration
- Stabiliser le repo, nettoyer
- Mapper le système
- Migrer un cluster de librairies
- Utiliser la migration comme apprentissage pour améliorer le repo et la prochaine migration
- Partager le feedback publiquement
Du coup, plus d'équipes veulent migrer.
La trust loop:
- Public demos créent la confiance
- Confiance amène early adopters
- Early adopters donnent du feedback
- Feedback améliore la plateforme
Une meilleure plateforme rend la prochaine migration plus facile
Les deux boucles se renforcent.
Automatiser le delivery : mesurer le cargo cult
Consolider le code ne suffit pas. Shipper prenait toujours 2-5 jours à cause de la coordination manuelle.
Le tunnel de PayFit : l’humain comme infrastructure
Le système de merge était absurde. Pour pouvoir remonter en production il fallait :
- S’ajouter dans une liste d’attente sur un Google Doc.
- Attendre son tour.
- Mais quand le tour arrive, la PR n’est plus à jour. Il faut donc l’update, attendre que la CI tourne. Ensuite merger, puis attendre l’approval manuel pour remonter sur les différents environnements.
- Et enfin notifier la personne suivante dans la liste d’attente du Google Doc.
Au mieux : 55 minutes. En moyenne : 3 heures. Et on évitait de merger la PR suivante par peur de bloquer. Ce qu'ils appelaient "safety" était surtout du coordination debt.
Cargo cult engineering
“Copier ce que les équipes qui réussissent font sans comprendre pourquoi.”
Par exemple : "Google et Facebook font du micro-frontend donc nous devons faire du micro-frontend" (avec 10 ingénieurs). Mauvaise idée.
Leur approche :
- Remplacer le Google Doc par Mergify (merge queue SaaS)
- Mesurer ce que les contrôles rattrapent réellement
- Tracker rollbacks et surcharges
- Garder le signal, supprimer la cérémonie Si un contrôle ne peut pas se justifier avec des preuves, c'est de la process debt.
Le nouveau flow
Lorsque la PR est prête, il suffit d’ajouter un label sur GitHub. Ensuite Mergify prend la main :
- Récupère la PR
- L’update automatiquement
- Merge et déploie vers dev et staging en parallèle
- Lance les tests sur staging pour les chemins critiques
- Deploie en production
On passe de 3h à 20-25 minutes. L’expérience développeur n’est plus la même : on ajoute un label, Mergify met à la queue avec estimation ("tu seras mergé dans 10 min"), puis auto-merge.
Résultat : même avec 10+ personnes dans la queue, au pire ça prend 20min. Les humains ne sont plus des “queue managers”.
La code review : un autre cargo cult
Lorsqu’un fichier était modifié, toutes les équipes qui avaient l’ownership sur ce fichier devaient approuver la Pull Request.
Conséquence :
- Review fatigue
- Des reviews qui deviennent juste “on approuve” (rubber-stamp reviews)
- Ralentit les refactorings
- Pousse à faire des PRs plus grosses (parce que lent à review) qui poussent au “LGTM” (Looks good to me) sans réelle review.
- 1 PR sur 4 nécessitait au moins 2 équipes
Nouveau modèle :
- Par défaut : tous les propriétaires du code sont notifiés, mais pas forcés d'approuver
- Une seule approbation est nécessaire (par n'importe quel ingénieur)
- Peut demander optionnellement à deux personnes
- Pour les zones critiques : on force l’approval par l'équipe propriétaire
- En incident : label "urgent" bypass tout
Le but n'est pas moins de reviews. C'est moins de rubber-stamp reviews, plus de signal sur ce qui compte vraiment.
Simplifier l'app : migration du routing
Une fois le monorepo stable et le delivery automatisé, ils pouvaient enfin s'attaquer à l'application elle-même.
L'état initial
- 286 routes
- Routers nested partout dans les components
- Custom modal components utilisant des private React Router APIs
- Usage non-safe de location.state
- In-memory routers pour modals et side panels
- 5 ans de routing drift
- React Router v5 (vieille version de 2019)
Cleanup avant migration
- Bouger tous les sous-routers dans un seul fichier
- Supprimer les routeurs des sous-composants
- Arrêter l’utilisation de location.state (banni via un patching des types typescript)
- Supprimer les routeurs spécifiques aux modales
- Déplacer le behavior dans des URL search params explicites
Résultat : un routeur, une seule source de vérité.
Migration vers TanStack Router : strangler fig pattern
Le but est d’éviter une migration en big-bang (qui ne fonctionne jamais), de rewrite branch ou de freeze sur le code. Et surtout pas de "on se voit dans 6 mois".
Le strangler fig pattern (souvent utilisé côté backend). Sur une application legacy :
- On ajoute une façade par-dessus qui redirige d'abord vers le legacy
- Progressivement on redirige vers le nouveau système en parallèle
- Finalement il ne reste que le nouveau système
On réalise la migration des pages top-level une par une :
- /login, /dashboard → TanStack Router
- Le reste → ancienne application avec ancien router
Les nouvelles routes TanStack pouvaient vivre dans les pages legacy. Les équipes pouvaient continuer de travailler. Jamais de giant cut-over day.
La migration est devenue une loop, pas un événement.
Les bugs découverts
La migration a également permise de trouver beaucoup de bugs :
- 20+ query param bugs (code qui écrit un paramètre mais en lit un autre)
- Liens morts vers des routes qui n'existent plus
- Des conflits de search params (ex: "state" pour auth global ET state pour un tableau)
- Des race conditions cachées dans les URLs. TanStack Router étant plus strict : "tu ne peux pas faire une navigation au milieu d'une navigation vers une route différente, quelque chose ne va pas."
C'était pas juste un refactor mais une bug-finding machine.
Ownership
Dans une multi-team app, "qui possède cette route ?" compte au runtime. Ils ont attaché l’ownership des équipes directement dans le code des routes : explicite, local et type-safe. Toute cette migration router à pris 4 mois. Sur toute la codebase. Avec beaucoup de coordination d'équipes. Incluant le cleanup.
Les résultats
Sur 2 ans :
- Déploiements : 225/an → 4040/an
- CI : 45min → 7min
- Feature delivery : 2-5 jours → 20-25 minutes
- Vélocité frontend : 17x
- Bundle size : -92 MB de JS
- Load time : -5 secondes avec 2,5 ingénieurs.
Le contexte aujourd'hui :
- 22 équipes
- 95 contributeurs actifs mensuels
- 1 app de production
- 126 librairies
Les leçons
Leçon 1 : Ne jamais mandater, prouver
La première tentative de monorepo a échoué parce que imposée. La seconde a fonctionné parce que les équipes ont vu la valeur avant de migrer.
Leçon 2 : Réparer la maison avant d'inviter les invités
- Meilleur tooling avant de lancer les migrations
- Meilleures docs avant le marketing de la plateforme
- Meilleure CI avant l’adoption de la plateforme
Si la destination est douloureuse, la migration est juste une relocalisation de la douleur.
Leçon 3 : Mesurer le cargo cult
Certains process existent pour une raison. Ça ne veut pas dire qu'ils valent encore leur coût. Mesurer les rollbacks, overrides, failures, temps d’attente. Garder le signal, supprimer la cérémonie.
Leçon 4 : Migrer les clusters, pas les boîtes sur un org chart
Les repos ne sont pas les “change boundaries”. Les librairies ne sont pas les “migration units”. Le graph dit ce qui évolue vraiment ensemble.
L'architecture devient plus simple quand on suit la réalité.
Ce qu'ils ont tué
- Variation inutile
- Cérémonie de release
- Fausse isolation avec couplage réel
- Complexité accidentelle
Ce que ça m'inspire
Le micro-frontend n'est pas intrinsèquement mauvais. C'est juste qu'on le copie parce que Google/Facebook le font, sans comprendre pourquoi ils le font, ni si on a les mêmes contraintes.
C'est la même chose d'ailleurs avec les micros-services. Dans Culture API on recommande d'ailleurs le Modular Monolith par défaut.
PayFit avait ~100 ingénieurs. Pas 10 000. Ils n'avaient pas besoin d'isolation au niveau deployment. Ils avaient besoin de vélocité.
Ce qui m'intéresse le plus :
La partie trust. La première tentative monorepo a échoué. Pas parce que techniquement mauvais mais parce que mandaté d'en haut, sans buy-in, sans support, sans prouver la valeur. La seconde tentative a fonctionné parce qu'ils ont traité la plateforme comme un produit. Docs, demos, roadmap public, early adopters over-supportés, feedback transformé en améliorations visibles.
Build in public, même en interne. Ça crée de la confiance. Les équipes voient le momentum, pas juste des promesses. Le travail n'est plus mystérieux. On peut fortement s’inspirer de l’open source.
Mesurer le cargo cult. Le Google Doc pour merger et les approbations de toutes les équipes pour chaque PR étaient accepté comme "safety". En réalité c’était de la coordination debt. Ils ont mesuré pour supprimer la cérémonie.
Si une gate ne peut pas se justifier avec des preuves, c'est de la process debt.
Strangler fig en frontend. On ne voit pas souvent ce pattern utilisé en frontend. Pourtant c'est puissant. Leur façade router était brillante. Coexistence ancien/nouveau, migration incrémentale, jamais de freeze sur la codebase, jamais de rewrite branch. Et surtout pas de big bang.
Les loops. Migration loop. Trust loop. Ils se renforcent mutuellement.
Public demos → trust → early adopters → feedback → meilleure platforme → migration plus facile → plus de demos.
C'est ça qui a permis de tenir 2 ans sans abandonner.
Il n'y as pas besoin de 20 personnes pour simplifier un système mais de focus, patience, et preuves.
Cette présentation est un cas d'école de pragmatisme appliqué à grande échelle. Distinguer ce qui pourrit silencieusement (fake isolation avec real coupling, process debt non mesuré, cargo cult) de ce qui peut être corrigé visiblement (CI lent, coordination manuelle).
Prioriser la confiance autant que la technique. Prouver par l'exécution, pas par le mandat.
On parle aussi de micro-frontend sur le blog Octo :
- Duck Conf 2025 - Le micro-frontend décomplexé : les dessous d’une migration incrémentale et itérative
- 5 questions à se poser pour bien comprendre les micro frontends
- Micro-frontend : un exemple d'implémentation
Liens utiles :