Qu'est-ce que l'Edge Computing ?
Avez-vous entendu parler du robot « Curiosity » ? Lancé par la NASA le 26 novembre 2011, ce rover explore la planète Mars, à la recherche d’éventuelles preuves de l’existence passée d’un environnement favorable à l’apparition de la vie. L’un des atouts majeurs de ce concentré de technologie est sa capacité à « évoluer » en quasi-totale autonomie. Par « évoluer », j’entends :
- La capacité à percevoir son environnement ;
- La capacité à prendre des décisions sur les actions à mener ;
- La capacité à interagir avec son environnement.
Autrement dit, Curiosity n’attend pas les ordres d’un « système central » pour accomplir sa tâche. Il est doté d’une « intelligence », implémentée directement à bord.
Bien sûr, il n’est pas nécessaire d’aller sur Mars pour voir des objets se comporter de la sorte. Prenez l’exemple des voitures autonomes. Celles-ci obéissent aux mêmes principes que les rovers : elles analysent l’environnement qui les entoure, prennent des décisions sur la marche à suivre, et agissent en conséquence… en temps réel ! Dans ce cas, il est impensable de devoir attendre, ne serait-ce que quelques précieuses millisecondes, les ordres d’un système distant pour agir. Ainsi, comme pour les rovers, une partie de l’ « intelligence » (si ce n’est toute) est implémentée « en périphérie », sur la voiture elle-même.
En fait, avec la démocratisation des objets connectés, il y a une véritable tendance à déporter le traitement des données directement sur ces derniers. Montres connectées capables d’appeler un numéro d’urgence à partir de l’analyse des indicateurs de santé, caméras de sécurité capables d’effectuer de la reconnaissance faciale, lampes connectées qui adaptent leur intensité à la luminosité ambiante, etc.
Ces usages sont rendus possibles par le développement de l’« Edge computing », qui regroupe l’ensemble des méthodes et technologies visant à traiter les données au plus proche de leur source. Dans cet article, je me propose donc de définir plus précisément l’Edge computing ainsi que les principes qu’il met en jeu.
Après la lecture de cet article, vous saurez :
- Définir ce qu’est l’Edge computing ;
- Saisir l’ensemble des problématiques qui doivent être adressées lorsque l’on fait le choix de l’Edge computing ;
- Présenter les éléments que doit contenir une architecture fonctionnelle « type » qui s’appuie sur l’Edge computing.
Quels sont les bénéfices de l’Edge computing ?
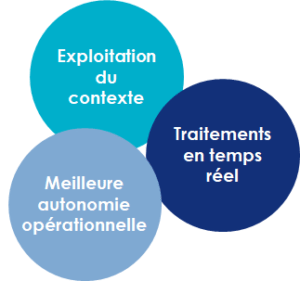
La mise en place d’une architecture basée sur l’Edge computing permet de bénéficier des atouts suivants :
- Capacité à exploiter le contexte : en déportant le traitement des données sur des équipements capables de percevoir leur environnement, on se donne la possibilité de prendre des décisions et d’agir en fonction d’opportunités, de contraintes et/ou d’aléas qui se présentent par rapport à la situation du système ;
- Capacité à agir en temps réel : déporter les traitements « en périphérie », sans attendre les ordres d’un « système central/distant », c’est offrir un potentiel d’action en temps réel lorsque cela est utile voire indispensable ;
- Meilleure autonomie opérationnelle : les fonctions implémentées sur les objets leur confère la capacité à gérer les situations et à évoluer dans des environnements « hostiles » (inhospitaliers pour l’être humain, comportant des risques sanitaires, théâtre d’actes de guerre, etc.) sans intervention humaine et indépendamment du « système central ».
Quelles sont les problématiques à prendre en compte ?
Choisir une architecture en s’appuyant sur l’Edge computing, c’est s’ouvrir à un monde de possibilités que n’offrent pas les systèmes qui centralisent données et traitements. Cependant, pour pouvoir « en profiter », cela nécessite de gérer les problématiques associées « classiquement » aux systèmes embarqués.
Pour mieux saisir la nature de ces problématiques, voyons un exemple concret. Considérons une entreprise qui vend des caméras de surveillance connectées aux particuliers, baptisée “Alarmcorp”. Ces caméras :
- Permettent à leurs utilisateurs d’observer en temps réel ce qui se passe dans un périmètre de 10 mètres autour du point où la caméra est positionnée ;
- Sont capables d’envoyer une notification si un visage inconnu se présente devant la caméra et de transmettre un enregistrement vidéo de ce qu’elles captent pendant une période de temps donnée aux serveurs d’Alarmcorp afin d’être consultées par leurs clients ou par les autorités judiciaires ;
- Peuvent fournir un historique de tous les évènements qui ont eu lieu sur une période de temps donnée (allumage, extinction, présence détectée, notification envoyée, etc.).
De par la nature des services qu’elle propose, Alarmcorp se trouve confrontée aux problématiques suivantes :
- Connectivité de qualité disparate
Alarmcorp propose ses services dans toutes les régions. Or, la couverture Internet est inégale sur l’ensemble du territoire, avec des débits de transmission hétérogènes, plus ou moins élevés en fonction de la situation géographique. Ainsi, il faut que la transmission des enregistrements vidéo vers les serveurs d’Alarmcorp soit optimisée.
⇒ Pour permettre l’optimisation de ces transferts vers les serveurs d’Alarmcorp, la caméra compresse et filtre les données avant de les envoyer, ce qui limite le volume d’informations à transférer.
- Ressources hardware limitées
Les caméras étant de petite taille, elles présentent des ressources matérielles limitées (processeur, mémoire, carte graphique, etc.).
⇒ Les solutions logicielles implémentées dans ces caméras doivent optimiser leur utilisation des ressources matérielles qui existent nativement sur les caméras.
- Diversité des objets connectés
Alarmcorp propose deux modèles de caméras issus de deux constructeurs différents. Ainsi, les systèmes d’exploitation sont différents pour chacun des modèles. De plus, elles doivent être capables d’interagir avec la serrure de la porte d'entrée qui envoie des données au format Z-Wave.
⇒ Les solutions logicielles implémentées au sein des caméras doivent mettre en œuvre une couche de standardisation (API, …). Cette standardisation permettrait non seulement de gérer plusieurs familles ou générations de matériel, mais également de dialoguer avec d’autres objets connectés qui “discutent” dans un format différent de celui qui est nativement implémenté sur les caméras.
- Grand volume de données à traiter
Il est possible de configurer les caméras d’Alarmcorp de telle façon qu’elles n’envoient une notification à leurs propriétaires uniquement si les visages des individus qui se présentent devant elles sont inconnus. Pour ce faire, elles procèdent à une reconnaissance faciale en temps réel, à partir des images reçues via les capteurs vidéos et qui constituent donc d’importants volumes de données à traiter.
⇒ Les traitements qui permettent de procéder à la reconnaissance faciale doivent avoir lieu directement au sein des caméras, sans que des transferts d’information avec les serveurs d’Alarmcorp ne soient nécessaires.
- Parc d’objets à gérer et à superviser
Alarmcorp a déployé pas moins de 5000 caméras auprès de ses clients. L’entreprise doit absolument savoir à tout instant dans quel état ces caméras se trouvent et si des actions doivent être menées à distance sur ces dernières (mise à jour, dépannage, etc.).
⇒ Afin de permettre à Alarmcorp d’avoir de la “visibilité” sur l’état de ses caméras, la société doit mettre en place une infrastructure et des fonctionnalités de gestion du parc (déploiement et supervision).
- Potentielles failles de sécurité
Les caméras connectées étant reliées à Internet via la box du domicile familial, elles constituent une porte d’entrée vers les serveurs d’Alarmcorp et doivent donc absolument être sécurisées.
⇒ Pour limiter les risques de piratage (vol de données clients, dénis de service, …), une couche de sécurité (authentification, intégrité et chiffrement) doit être mise en œuvre au sein des caméras.
Quel positionnement de l’ « Edge computing » dans une plateforme IoT ?
« Tant de problématiques que cela à gérer ?! » me direz-vous ? Eh bien fort heureusement, des architectures ont été étudiées et des composants imaginés pour prendre en charge toutes ces problématiques : ce sont les principes généraux de ces architectures et de ces composants que je vais m’attacher à vous décrire dans la suite de cet article.
Comme évoqué en introduction, le concept d’ « Edge computing » a surtout émergé avec l’essor des objets connectés et des objets intelligents. Ces derniers ne fonctionnent pas seuls mais en synergie avec une plateforme centralisée (désignée par le “cloud”, par opposition à l’“Edge” qui désigne les éléments situés en “périphérie”). Je me propose donc de vous présenter les principes de l’Edge computing en m’appuyant sur une plateforme IoT, qui est la plateforme “classique” sur laquelle les objets connectés et intelligents s’appuient :
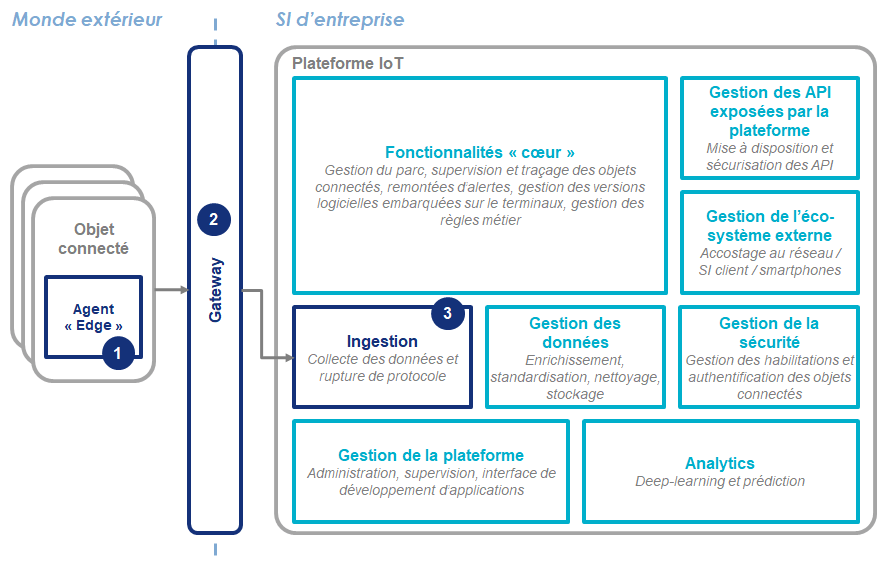
Trois éléments sont à considérer plus particulièrement dans le cadre de l’Edge computing :
- L’ « agent Edge » appelé aussi « agent-IoT » dans le cadre d’une solution IoT ;
- La gateway ;
- La fonction d’ingestion.
L’agent Edge est le composant logiciel installé sur les objets connectés qui permet à la fois leur fonctionnement en autonomie ainsi que la collecte des données et leur transmission vers la gateway. Comme nous allons le voir par la suite, cet agent est capable de prendre en charge l’ensemble des problématiques évoquées plus haut.
La gateway est l’élément d’infrastructure permettant l’agrégation des données issues des différents objets connectés et leur transmission vers la plateforme IoT. Ce qui peut être intéressant de noter ici, c’est qu’un agent Edge peut également y être installé : cela va être le cas lorsque l’objet connecté n’est pas en capacité de supporter la complexité de l’agent.
Enfin, lorsque les objets connectés ou la gateway ne sont pas capables de prendre en charge la rupture de protocole, c’est la plateforme IoT qui s’en charge via la fonction d’ingestion. Celle-ci permet alors le traitement des données collectées malgré la diversité de leurs formats d’origine puisqu’elle permet à la plateforme de comprendre les protocoles implémentés nativement sur les objets connectés (MQTT, Zigbee, etc.) en les traduisant dans un standard qui va être compréhensible pour celle-ci.
Quelles sont les fonctionnalités d’un agent Edge ?
Faisons maintenant un zoom sur l’agent Edge qui est principalement responsable de l’ensemble des problématiques à adresser lorsque l’on souhaite rapprocher les traitements de la source de collecte des données.
Je précise que ce que je vais décrire ici s’appuie sur les éléments implémentés par un projet open-source baptisé EdgeXFoundry qui supporte l’ensemble des fonctions que l’on attend d’un agent Edge.
L’ensemble des fonctionnalités offertes par un agent edge peut être représenté par un modèle en couches (similaire au modèle OSI dans le domaine des Réseaux et Télécommunications pour les connaisseurs) dont la clé de lecture est la suivante : plus on monte dans les couches, plus on s’éloigne du matériel pour se rapprocher des services à valeur ajoutée.

Il y a 4 couches de fonctions, complétées par deux couches “transverses” que sont la “Sécurité” et la “Gestion”. Voyons plus précisément quelles fonctions sont offertes et quelles problématiques sont adressées par chacune de ces couches.
- Couche “Matériel”
Cette couche assure la communication avec les objets connectés, transmet les ordres émis par la plateforme IoT aux objets connectés et traduit les informations générées par ces derniers dans un format compréhensible par la plateforme.
Cette couche permet à l’ « agent Edge » de gérer la diversité des types et modèles d’objets connectés grâce à la prise en charge de nombreux protocoles natifs (MQTT, Zigbee, …).
- Couche “Coeur”
Cette couche dispose de la connaissance de l’objet sur lequel l’agent est installé, permet le stockage des données qu’il génère et gère les ordres d’actualisation émis par la plateforme.
Les capacités de stockage des données que fournit cette couche permet leur persistance et ouvre donc des possibilités de traitement en mode déconnecté.
- Couche “Intelligence”
Cette couche est celle qui permet l’ « intelligence » de l’agent Edge : gestion des règles métier, alertes et notifications, mais également analyse des données et prise de décisions.
Cette couche exploite les capacités de l’objet connecté pour réaliser les traitements en temps réel et permettre la mise en œuvre de fonctions relatives aux domaines de l’AI et de l’Analytics.
- Couche “Export”
Cette couche fait le lien entre l’objet connecté et le « monde extérieur » puisqu’elle formate les données et permet leur transfert vers la plateforme IoT dans un format qui pourra être exploité par celle-ci voire adapté à des SI externes.
Cette couche prend en charge les aspects de compression et/ou de filtrage afin de garantir un transfert optimisé des données vers le cloud.
- Couche “Sécurité”
Cette couche assure l’authentification des objets connectés à la plateforme ainsi que l’intégrité et le chiffrement des données qu’ils lui envoient.
L’implémentation de cette couche permet un premier niveau de protection des données au plus près de la source, sur des équipements moins protégés nativement.
- Couche “Gestion du système”
Cette couche fournit toutes les fonctionnalités qui permettent à l’agent de fonctionner : déploiement, démarrage/arrêt, supervision. Il peut également gérer les fonctionnalités d’enrôlement de l’objet connecté.
Cette couche met à disposition les fonctionnalités de gestion du parc des objets connectés pour avoir une vue d’ensemble de leur fonctionnement et de leur état de « santé ».
Quelle synergie entre l’Edge et le Cloud ?
Vous l’aurez compris, l’agent Edge rassemble l’ensemble des fonctions qui permettent à l’objet connecté ou intelligent de collecter toute information utile, issue de sa perception de l’environnement, et d’agir en conséquence. Néanmoins, une question subsiste : quelles règles suit-il lorsqu’il agit ?
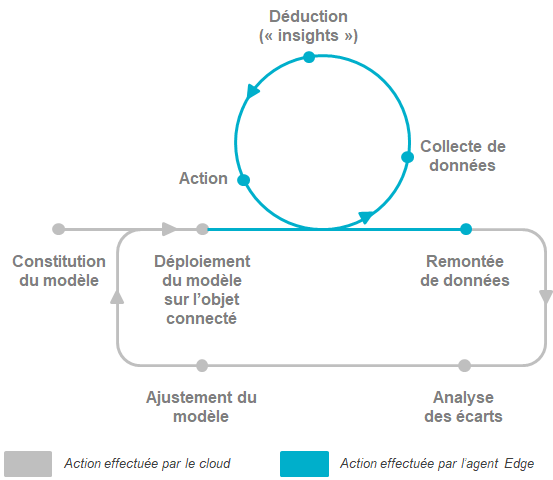
En fait, son comportement est régi par des modèles (“si tu perçois X, alors déduis-en que tu es dans la situation Y, et déclenche l’action Z”) qui ont été élaborés au sein du “cloud”.
Plus précisément, il y a une véritable répartition des rôles entre le cloud et l’Edge qui contribue à une “amélioration continue” du système global en tirant profit des capacités de chacun :
- Le modèle est constitué sur le cloud et déployé sur l’Edge (objet ou gateway) ;
- En temps réel, l’Edge exploite ce modèle pour prendre les décisions adéquates ;
- A intervalles réguliers, le cloud évalue la pertinence du modèle à partir de données qui sont envoyées par l’edge (“dans telle situation, l’objet aurait dû déduire A, mais il a déduit B...”) ;
- Le cas échéant, le modèle est corrigé sur le cloud et redéployé sur l’Edge.
Si je reprends l’exemple des caméras d’Alarmcorp, cela donne :
- Le modèle de reconnaissance faciale est constitué sur le cloud et déployé sur l’Edge (objet ou gateway) ;
- En temps réel, l’Edge exploite ce modèle pour prendre les décisions adéquates (transmission de l’ordre de déverrouillage de la porte, envoi d’une notification, …) ;
- A intervalles réguliers, le cloud évalue la pertinence du modèle de reconnaissance faciale à partir de données qui sont envoyées par la caméra ;
- Le cas échéant, le modèle est corrigé sur le cloud et redéployé sur l’ensemble des caméras à l’occasion d’une mise à jour.
Ce qu’il faut bien comprendre, c’est que si ce couple peut bien fonctionner, c’est notamment en raison des capacités offertes par l’agent Edge. En effet, lorsqu’il est correctement implémenté, celui-ci :
- Perçoit correctement son environnement (via les capteurs des objets connectés ou intelligents) ;
- Exécute de façon efficace les modèles de “machine-learning” ;
- Gère de façon optimisée les bases de données locales déployées sur l’Edge qui peuvent être volumineuses.
Conclusion
Si un collègue et/ou ami vous demande de lui définir ce qu’est l’Edge computing en quelques phrases, dites-lui ceci :
- L’Edge computing désigne l’ensemble des techniques et des technologies qui permettent de traiter les données au plus proche de leur source ;
- Il permet de concevoir des systèmes autonomes, capables d’agir en temps réel sans attendre les “ordres” d’un système central (“cloud”), à partir de la perception de l’environnement dans lequel ils évoluent ;
- Néanmoins, cela nécessite de gérer tout un tas de problématiques que l’on associe classiquement aux systèmes embarqués, ce qui est généralement le rôle d’un composant logiciel baptisé “agent Edge” ;
- Enfin, si les systèmes s’appuyant sur l’Edge computing n’ont pas besoin d’un système centralisé (“cloud”) pour agir au jour le jour, l’exploitation du couple “Cloud / Edge” permet néanmoins d’améliorer continuellement le système global puisque les règles de gestion et modèles de prédiction sont élaborés sur le Cloud, déployés au sein des objets connectés ou intelligents (Edge), peuvent être corrigés par “retour d’expérience” des objets connectés ou intelligents.