Quelle solution de persistance pour ma stratégie cross-canal ?
"67% des consommateurs utilisent à la fois leur ordinateur, leur tablette et leur smartphone pour faire un achat. Et 98% d’entre eux passent d’un support à un autre dans la même journée" (source : Skeelbox). Cette tendance souligne l'importance de s'adapter à ces usages en adoptant une stratégie cross-canal. Mais qu’est-ce qui se cache vraiment derrière ce terme? Quels sont les enjeux technologiques liés à cette stratégie? Comment la mettre en oeuvre chez moi, et avec quelles solutions pour stocker mes données. C’est ce que nous allons présenter dans cet article, premier d’une série concernant les différents use-cases liés aux nouvelles architectures de traitement et de persistance de la donnée.
Présentation du Use-Case
Le terme cross-canal regroupe les techniques de vente ayant pour but d’utiliser tous les canaux de distribution disponibles de façon transverse et sans couture, et de tirer parti du meilleur de chaque pour offrir un parcours optimal à l'utilisateur. Dans notre cas, nous nous intéresserons uniquement au canal web et non au canaux physiques. En effet, la problématique de récupération des données sur les canaux digitaux "hybrides" (magasin connecté, produit connecté, vitrine connectée...) mériterait en effet un article à part entière.
Le périphérique que nous utilisons est choisi à partir du contexte (lieu dans lequel nous nous trouvons, temps dont nous disposons, etc) et il convient donc d'exploiter les spécificités de chaque canal pour offrir la meilleur expérience client possible. Il est par exemple pratique de parcourir un catalogue produits sur son téléphone mais un paiement par carte bancaire ne sera pas forcément adapté si l'on se trouve dans la rue ou le métro, d'où la possibilité d'enregistrer ses achats dans des listes ou des paniers "longue durée".
L'infographie suivante illustre, pour chaque "device", le pourcentage d'achats qui y ont été initiés, et le parcours qu'a ensuite suivi l'utilisateur.
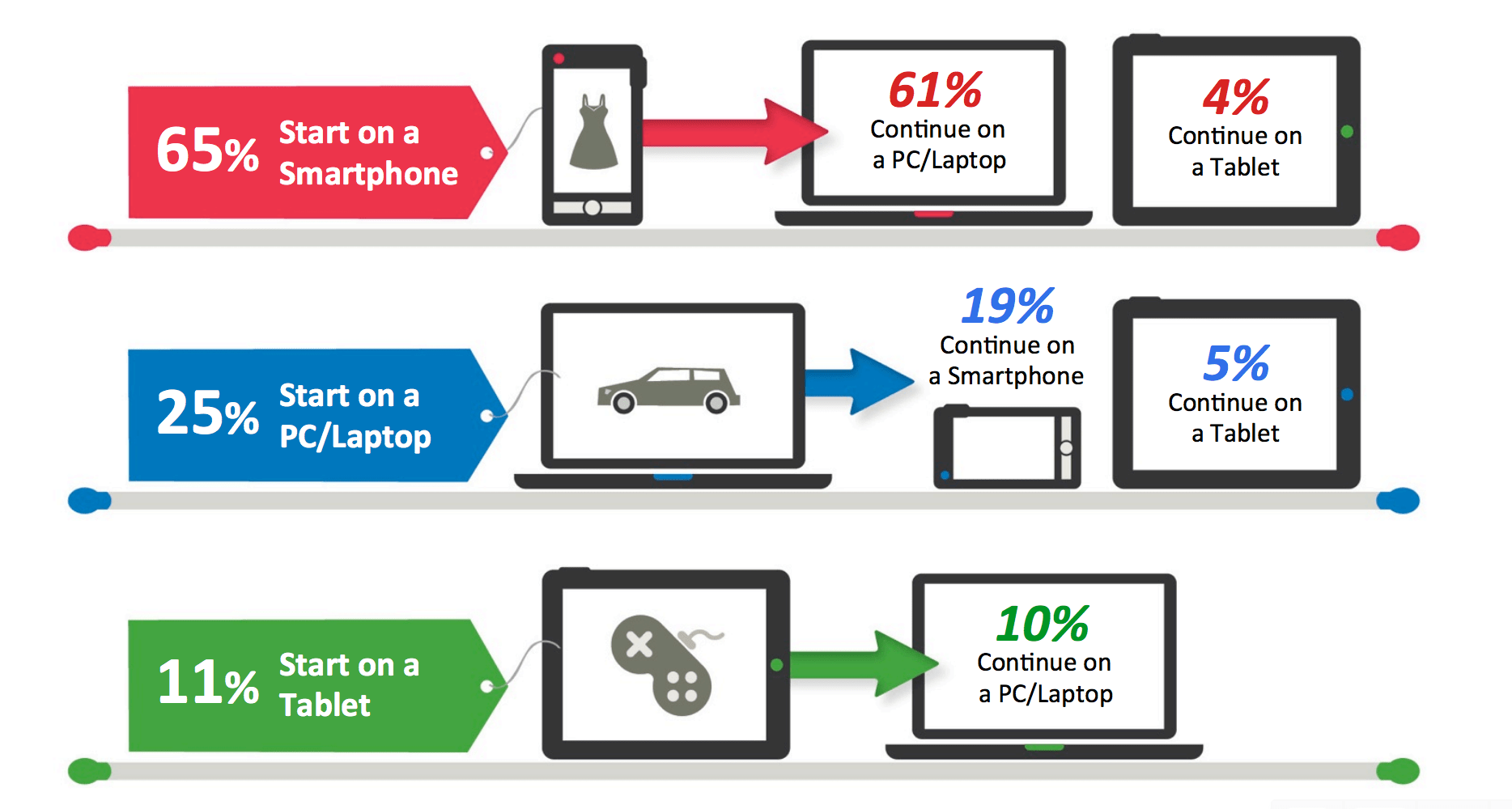
Afin de donner à notre utilisateur une impression de fluidité dans son parcours, il est donc indispensable de synchroniser les différentes informations d'un canal à l'autre.
Concrètement, cela peut se traduire par les cas suivants :
- j’ai repéré un produit qui m’intéresse en parcourant un catalogue sur ma tablette, je le mets dans mon panier, que je réglerai le soir sur mon PC, pour finalement aller le retirer en magasin une fois le produit disponible en montrant un QR code sur mon smartphone.
- j’achète mon billet d'avion sur mon ordinateur, je retrouve mon voyage sur mon téléphone sur lequel je peux choisir mon siège et visualiser ma carte d’embarquement.
- je commence à remplir mon dossier de sinistre d’assurance à mon domicile, je peux le continuer plus tard en uploadant une photo prise avec mon smartphone.
Ce type d’utilisation devient de plus en plus courante chez l’utilisateur, qui prend l’habitude de voir ses choix, effectués sur un canal donné, mémorisés et disponibles immédiatement sur les autres.
Enjeux techniques
Outre les problématiques d’identification unique de notre client, indispensable pour faire le lien entre nos canaux, et de récupération des données utiles (avantages fidélité du client, adresse préférée de livraison, historique...), ce cas d’utilisation pose de gros enjeux au niveau persistance de nos données. En effet, il nous faut maintenir une cohérence globale de notre contexte, le tout en garantissant des performances compatibles avec une bonne expérience utilisateur.
Face à ces besoins, la solution retenue devra donc répondre aux enjeux techniques suivants :
- très faible latence, indispensable pour de la gestion de session utilisateur et pour la fluidité de la navigation (cf. l'impact des temps de réponse sur le parcours client). Les IHM réactives modernes ne peuvent plus se permettre d’attendre la base de données. Certains cas pourront même nécessiter une réplication sur data centers distants pour mettre la donnée au plus proche de l’utilisateur.
- cohérence : on souhaite qu’une écriture réalisée à partir d’un canal soit synchronisée rapidement sur les autres canaux. Par « rapidement » nous entendons par là quelques secondes. Un client mettant à jour un panier d’achats sur son mobile n’a pas forcément besoin de le visualiser dans la milliseconde qui suit sur son desktop. En terme de théorème de CAP, nous cherchons donc un système de type AP (avec Eventual Consistency) plutôt que CP.
- haute disponibilité : on parle d’une solution de stockage qui sera potentiellement utilisée par de nombreux devices, et par plusieurs applications critiques (gestion de panier, des promotions, des commandes, de la facturation…). Pas question donc de devoir relancer notre cluster à chaque maintenance. Une perte de l’un des noeuds devra également être transparente pour l’utilisateur.
- elasticité : pour répondre à des pics d’activité saisonniers (soldes, Noël, Black Friday... pour un site d’eCommerce par exemple), notre solution devra être capable d’ajouter ou décomissionner des nouvelles machines facilement, et à chaud.
- volumétries : beaucoup d’écritures/lectures sur les applications à fort trafic. Le ratio lecture/écriture sera dans la plupart des cas équilibré.
- durabilité : il s’agit là de stocker des sessions métier (achat, gestion d’un dossier) longue durée, avec une durabilité qui s’éloigne de la session web de quelques minutes. On veut pouvoir stocker un dossier client, un panier, des préférences utilisateurs sur de nombreux jours. Dans le cas de données plus volatiles, une solution gérant un TTL (Time-To-Live, permettant de spécifier une durée de vie à nos données avant éviction) pourra également être intéressante.
- facilité de prise en main : la solution de persistance retenue sera potentiellement utilisée par de nombreuses applications, le succès d’une bonne intégration reposera donc sur la simplicité d’accès aux données (ex: clé-valeur, clé-document)
Technologies adaptées
Au vu des enjeux technologiques que représente ce cas d'utilisation, les bases de données relationnelles ne semblent pas répondre à toutes les exigences (ou du moins pas forcément à des coûts raisonnables). En effet, même si certains SGBDR peuvent fournir des latences très faibles, ces solutions n’offrent pas de scalabilité horizontale (du moins pas nativement) nécessaire pour pouvoir répondre à une montée en charge de l’application ou a des pics d’activité saisonniers. La modélisation relationnelle peut également s’avérer être un point bloquant lorsqu’il s’agit de réunir des données hétérogènes provenant de plusieurs applications différentes (tunnel de vente online, application en magasin...), là ou une base NoSQL permet de gérer des documents aux formats différents (panier non terminé, profil à moitié rempli...). La base de donnée retenue devra donc faire la différence sur les aspects haute disponibilité, élasticité et facilité de prise en main, les autres conditions pouvant être remplies par la plupart des SGBDR.
Nous vous proposons donc 3 solutions NoSQL, Aerospike, Cassandra et Couchbase, connues pour leurs performances élevées, notamment en ce qui concerne la latence en lecture. Cette liste ne se veut pas exhaustive, d'autres solutions pourraient être retenues dans certains cas particuliers, il s'agit là de bases sur lesquelles nous avons des retours d'expérience et pour lesquelles nous sommes convaincus qu'elles peuvent répondre au besoin.
Pourquoi ces technologies?
Ces 3 solutions sont en effet réputées pour leurs très bonnes performances en lecture/écriture. Elles disposent toutes d'un mécanisme de réplication de données pour assurer de la haute disponibilité, y compris une replication cross-datacenter permettant à la fois de se prémunir de pertes de données lors d'un sinistre mais également de s'assurer que les données seront localisées au plus près de l'utilisateur final. Enfin elles proposent toutes un mécanisme d'ajout / suppression de machines dans le cluster, à chaud, permettant aisément de dimensionner l'infrastructure en fonction de la charge.
Le plus de détails) est disponible pour les trois.
Du point du vue durabilité, Aerospike offre également le choix de persister les données uniquement en mémoire, et non sur disque, mais cette option ne concerne pas notre cas d'utilisation car nous cherchons bien à utiliser ces solutions en tant que primary datastore et non comme cache uniquement.
Ce qui les distingue entre elles
- Prise en main : Aerospike et Couchbase sont avant tout des bases K/V dont le requêtage se fait facilement via la clé primaire. Ils disposent également d'un langage de querying (AQL pour Aerospike, et N1QL qui arrive dans la version 4 de Couchbase prévue ce mois-ci) inspiré du SQL, tout comme l'est CQL (Cassandra Query Language)
- Cohérence : Cassandra permet de choisir la granularité entre une cohérence immédiate ou à terme via la Tunable Consistency, Couchbase et Aerospike sont de leur côté immédiatement cohérents (pour Couchbase, cela est vrai uniquement lors du requêtage par clé primaire, l'utilisation des vues ne garantit qu'une cohérence à terme car leur mise à jour est asynchrone)
- Gestion du mode déconnecté : Couchbase propose avec Couchbase Lite une base mobile embarquée permettant de gérer le mode déconnecté et de synchroniser les données avec Couchbase Server une fois revenu en ligne
- Les + :
- Aerospike : cette base a été conçue pour tirer pleinement parti du stockage SSD, et peut donc offrir de très bonnes performances si vous disposez de ce type de disque dans votre infrastructure.
- Cassandra : avec sa modélisation colonne, Cassandra permet de stocker beaucoup de données sur une seule ligne et de ne mettre à jour que certains informations là ou les autres solutions requièrent de réécrire tout le document à chaque mutation. Intéressant si l'on se trouve dans un contexte d'écritures massives donc.
- Couchbase : avec Couchbase Lite, nul besoin d'avoir à gérer du côté applicatif le mode déconnecté, la base le gérant elle même nativement.
Nous disposons donc de 3 bases répondant très bien à nos contraintes de performance et de haute disponibilité. Couchbase et Aerospike apparaissent comme les plus simples à utiliser et administrer, et l'aspect schema-less permet d'intégrer des formats de donnée hétérogènes facilement. L'association Couchbase Server - Couchbase Lite pourrait se révéler déterminante dans le choix de la solution au vu de notre cas d'utilisation. Le fonctionnement de Cassandra est peut être moins trivial à appréhender (on pense notamment à des concepts comme la Tunable Consistency) mais c'est une base qui peut s'avérer un bon choix dans des cas d'écritures massives et qui a fait ses preuves chez beaucoup de clients.
Et ensuite
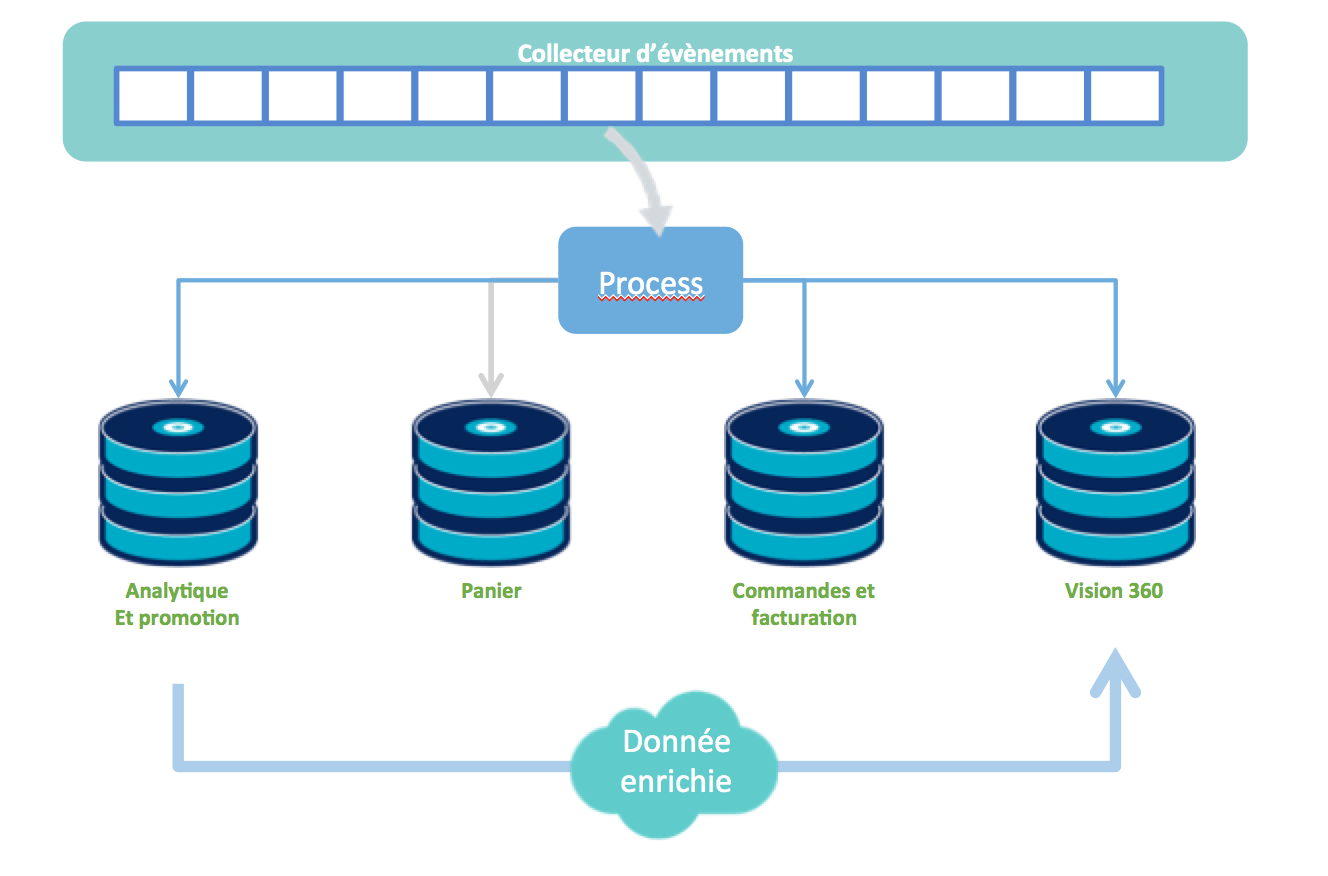
La stratégie cross-canal présentée ci-dessus est juste une première étape. Chez OCTO, nous sommes convaincus que derrière cette problématique de stockage/restitution de la donnée se cache un enjeu plus important : celui de l'architecture de nos données . En effet, stocker dans un endroit unique les transactions et paniers d’utilisateurs issus d'un site web, d’une tablette, d’un téléphone ou d'un magasin physique est déjà une étape importante mais le vrai objectif pour nous est de décloisonner le SI pour rendre ces données accessibles en temps réel aux autres briques métier. Et, pour que cela devienne vraiment pertinent, un des challenges est de collecter le maximum de données et d'essayer de les traiter au fil de l'eau, comme nous le présentions lors de notre petit déjeuner sur les Nouvelles Architectures de Données, en structurant notre SI autour d'évènements. Toute action de notre utilisateur, que ce soit une mise à jour panier, un clic, une modification de son profil… devient donc un évènement, accessible par nos différentes applications. Cette nouvelle manière d'aborder vos data pourront ainsi vous ouvrir de nouveaux cas d'utilisation comme par exemple la vision 360 d'un client qui est mise à jour dès qu'il déclare un sinistre, la détection d'abandon de panier dans le eCommerce.
Et en allant un peu plus loin, on peut aussi se dire que ces évènements ne devront pas être limités aux canaux digitaux mais permettront également d'intégrer les canaux physiques : consultation des stocks en temps réel du magasin physique depuis mon smartphone, achat depuis le magasin physique qui déclenche un bon de reduction pour un prochain achat que je pourrais aussi utiliser sur mon téléphone... Il faudra alors évaluer la capacité des solutions citées dans cet article à intégrer ces nouveaux besoins, quitte à utiliser une autre base pour stocker et traiter tous ces évènements, la persistance polyglotte étant de plus en plus courante dans les SI.
Sources :
https://ssl.gstatic.com/think/docs/the-new-multi-screen-world-study_research-studies.pdf
http://www.nngroup.com/articles/response-times-3-important-limits/
http://wiki.apache.org/cassandra/ArchitectureOverview#Consistency
http://www.odbms.org/wp-content/uploads/2013/11/NoSQL-Failover.pdf
http://martinfowler.com/bliki/PolyglotPersistence.html