Quelle architecture Google Cloud pour de l'ingestion de données ?
Introduction
Il vous est déjà arrivé de vouloir initier un projet d’ingestion de données sur le cloud, de lire la documentation et de vous rendre compte qu’il y avait des dizaines de composants pouvant répondre à votre problématique ? Avoir autant de composants peut être un avantage pour un utilisateur rodé à ceux-ci, cela devient en revanche un véritable casse-tête pour quelqu’un n’ayant pas la vision totale de son projet ou débutant sur Google Cloud. Cette réflexion du choix d’une architecture plutôt qu’une autre est en plus de cela capitale lorsque l’on sait la complexité pour une équipe de changer d’architecture en cours de projet. Afin d’éviter ce scénario, nous allons vous présenter dans cet article plusieurs architectures GCP permettant l’ingestion de données. Pour chacune de ces architectures, nous vous détaillerons leurs forces et leurs faiblesses. Nous vous exposerons aussi le résultat d’une batterie de tests comparant les performances des architectures.
Pour quel usage ?
Notre objectif est de créer des architectures pouvant répondre à un grand nombre de problématiques observées en missions par les consultants d’Octo.
Les architectures que présente cet article ont été réalisées dans le but de faire de l’ingestion de données provenant de différents fichiers CSV. Nous insistons sur la diversité des fichiers car il est rare que lors d’un projet, une architecture ne soit montée que pour l’ingestion d’un unique fichier ayant toujours la même structure.
Nous souhaitons aussi que lors de l’ingestion, un pre-processing soit réalisé sur les fichiers ingérés. Les fichiers nettoyés seront ensuite écrits dans des tables Big Query.
Une fois cette étape réalisée, nos architectures devront être en mesure de réaliser un nouveau calcul, permettant de stocker les résultats dans une nouvelle table, qui permettra de faire une analyse statistique au cours du temps et sera par exemple exploitable par des Data Analysts immédiatement.
En plus de cela, nos architectures doivent être capables de faire preuve de scalabilité : si la charge de travail ou l’import de données augmente, elles sont censées absorber cette augmentation sans interruption de service.
Enfin, nous voulions proposer des architectures déclinables en mode batch et streaming afin de pouvoir voir leurs forces et leurs faiblesses dans ces deux situations.
En schéma, voici comment ça se représenterait :
Déclinaison en streaming :
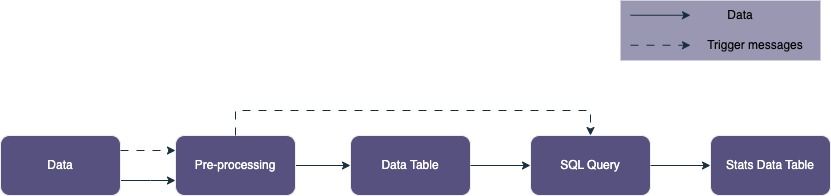
Déclinaison en batch :
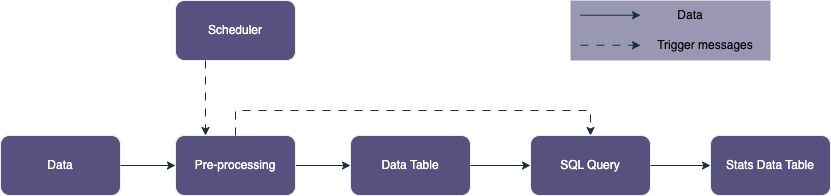
En bonus, toutes ces architectures ont été réalisées à l’aide de Terraform sur le modèle de l’infrastructure as code (IaC), donc sont réalisables de la même façon par vous même. C’est une pratique que nous vous recommandons grandement de mettre en place car elle apporte plusieurs avantages :
Reproductibilité de l’expérience. Si demain votre architecture rencontre un bug majeur ou si vous désirez reproduire la même architecture à l’identique sur un autre projet Google Cloud, cela est possible en une seule ligne de commande depuis votre terminal.
Versionning de votre architecture. Grâce à votre code que vous poussez régulièrement sur Git mais aussi grâce à Terraform qui propose des fichiers appelés “.tfstate”, vous pouvez connaître l’état de votre architecture à n’importe quel moment, comme un historique finalement.
Avoir une trace de toutes les ressources qui constituent votre architecture et qui sont actuellement déployées. Cela est beaucoup plus difficile d’avoir cette information sans cela.
Pour résumer, voici le cahier des charges de nos architectures :
Capable de traiter plusieurs fichiers CSV différents
Effectuer un pre-processing de ces fichiers
Effectuer une requête d’analyse statistique sur nos données nettoyées
Faire preuve de scalabilité
Déclinaison en mode batch et streaming
Réalisable en Infra as Code
Architectures
Nous allons donc vous présenter trois architectures qui permettent de remplir chacune des caractéristiques énoncées précédemment.
Avant d’avancer, nous pensons qu’il est pertinent de vous présenter de façon brève les principaux composants Google Cloud que nous allons utiliser dans cette étude.
Voici une liste et description de ces-derniers, de la façon dont nous les avons utilisés dans notre étude :
Cloud Storage : il s’agit de la solution de data lake de Google Cloud. On peut venir y déposer n’importe quel type de fichiers, sous n'importe quel format. On peut aussi ranger le contenu par dossiers, de la même façon que votre stockage local sur votre ordinateur.
BigQuery : c’est la solution de data warehouse de Google Cloud. Elle est constituée de datasets, eux-mêmes constitués de tables relationnelles. On peut aussi y retrouver des vues de ces tables. La force de cet outil réside dans sa force à manipuler une quantité importante de données à l’aide de SQL.
Cloud Logging : il s’agit de l’interface utilisateur permettant de visualiser les logs de toutes les ressources faisant partie de notre projet.
Cloud Monitoring : c’est une autre interface utilisateur que nous avons utilisée afin de visualiser les logs sous forme de graphiques. Cela permet à l’utilisateur d’avoir une vue d’ensemble de son projet en un instant.
Cloud Pub/Sub : c’est un service de messagerie asynchrone qui permet à deux composants de communiquer entre eux. Ce service est capable de conserver les messages tant que le receveur n’a pas pris connaissance du message. Durant ce laps de temps, Pub/Sub renverra le message à intervalle régulier. Ce composant agit de la même manière qu’une boîte mail où plusieurs utilisateurs peuvent y envoyer des messages et plusieurs utilisateurs peuvent prendre connaissance de ces messages. Ici, les utilisateurs sont des composants GCP.
Cloud Scheduler : c’est un planificateur de tâches Cron qui permet, à intervalle de temps régulier et personnalisable, d’effectuer diverses tâches. Parmi celles-ci on retrouve le déclenchement de Cloud Function ou encore l’envoi de messages Pub/Sub.
Cloud Function : c’est un outil serverless qui peut être déclenché sur plusieurs types d’évènements, qui exécute du code et qui est entièrement managé par Google. Ce composant déclenche autant d'instances qu’il reçoit de requêtes. L’utilisateur peut ajuster la mémoire maximale et le nombre de CPU maximum que va utiliser chaque instance de sa Cloud Function. Il peut aussi choisir le nombre maximum d’instances autorisées en simultané s’il veut limiter les coûts. Grâce à son caractère serverless, l’utilisateur n’est facturé qu’à l’utilisation de ce composant, en fonction du temps où des instances restent allumées.
Cloud Run : c’est un outil serverless qui présente de nombreuses similarités avec Cloud Function. Sa principale différence réside dans le fait qu’il n’embarque non pas un code mais une image Docker. Les limites maximales de CPU, de mémoire et d’instances sont plus importantes que celles de Cloud Function. Pour cette raison, son coût est un peu plus élevé.
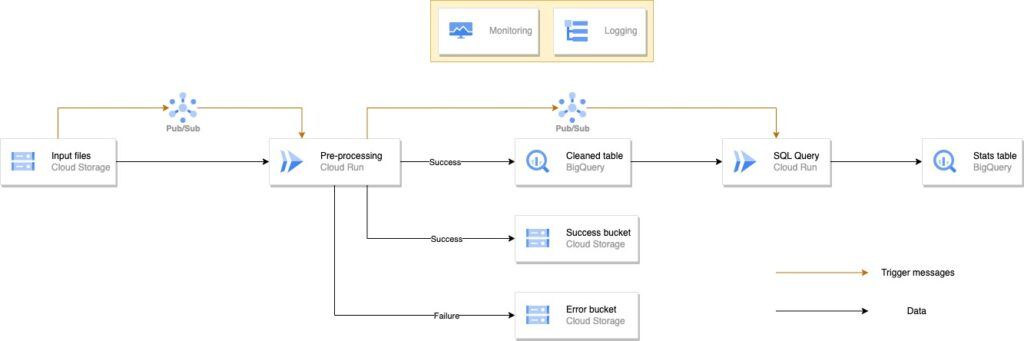
Architecture Cloud Function
Nous avons commencé par la création d’une architecture centrée principalement autour de Cloud Function (de première génération). Notre choix de commencer par cette architecture plutôt qu’une autre s’explique par le fait que Cloud Function est décrit comme l’un des composants de GCP les plus faciles facile à prendre en main, et après utilisation, nous sommes assez d’accord avec cette idée.
Cloud Function - Batch
Voici le schéma de l’architecture Cloud Function au format batch, qui se lit de la gauche vers la droite :
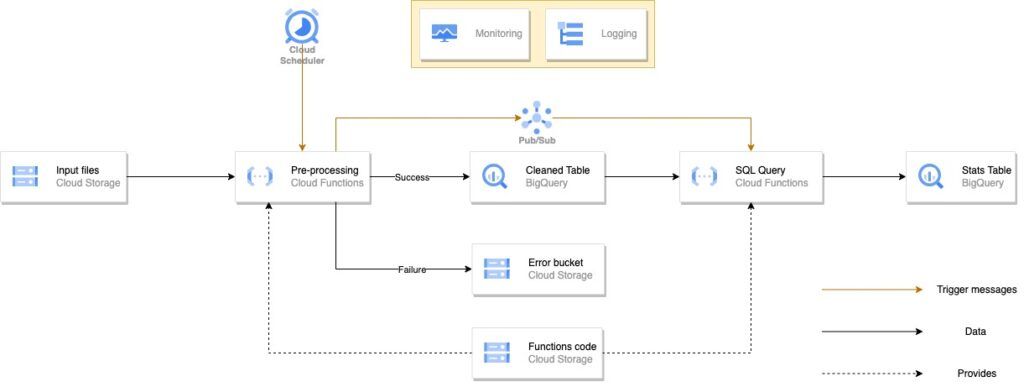
Afin de mieux comprendre ce que fait cette architecture, nous allons la séparer en différents blocs afin de vous expliquer les différentes étapes qu’elle réalise.
Bloc d’ingestion
Dans un premier temps nous avons l’ingestion de fichiers et leur pre-processing.
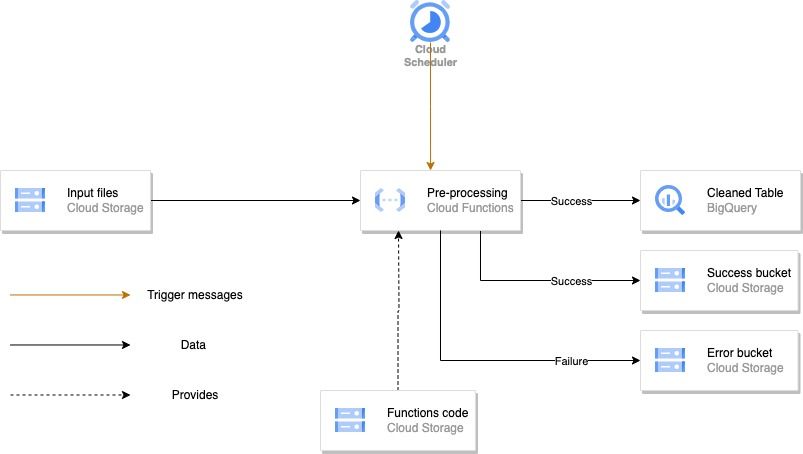
Ici, les fichiers sont déposés par l’utilisateur dans un bucket Google Cloud Storage. La principale particularité de cette architecture est que les fichiers vont être traités par batch à un certain intervalle de temps, imposé par le Cloud Scheduler. Celui-ci va, à intervalle de temps régulier, allumer la Cloud Function qui va à son tour réaliser les tâches que contient son code. Dans notre cas, le code de notre Cloud Function récupère tous les fichiers présents dans le bucket “Input files”, il réalise un traitement dessus afin de faire un peu de data engineering, puis écrit ces dataframes modifiées dans des tables BigQuery. Un paramètre sur lequel vous pouvez jouer est la façon dont vous écrivez vos fichiers : vous pouvez décider d’écraser la version précédente de la table, ou bien ajouter les nouvelles lignes à la suite des précédentes (ce que nous faisons dans notre cas).
Notre code réalise aussi d’autres opérations que nous avons jugées importantes dans une architecture data. Lorsqu’un fichier est ingéré avec succès, il est ensuite copié dans le bucket “Success bucket” et supprimé du bucket initial. Avec cette façon de faire, l’utilisateur peut désormais mettre en place une opération de suppression des fichiers de “Success bucket” lorsqu’ils sont dans ce bucket depuis un certain temps. Ainsi, l’utilisateur évite de conserver des fichiers inutiles qui lui feront dépenser de l’argent. Un autre aiguillage est réalisé, cette-fois ci pour les fichiers ayant généré une erreur lors de leur ingestion. Ceux-ci sont redirigés vers le bucket “Error bucket” et supprimés du bucket initial aussi. De cette façon, il sera rapide pour la personne chargée de maintenir l’architecture de détecter la source du problème.
Sur le schéma précédent, on peut aussi remarquer la présence d’un bucket “Functions Code”. Celui-ci contient le code qui est exécuté dans les Cloud Functions.
Bloc de requêtes
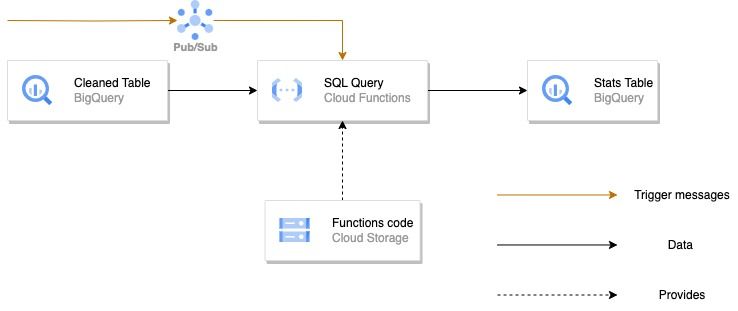
Nous décrivons ici l’étape qui survient après le block d’ingestion dans notre architecture.
Une fois la première Cloud Function passée et la dataframe modifiée écrite dans une table BigQuery, une seconde Cloud Function, appelée “SQL Query” est déclenchée. Cette suite d'événements est rendue possible grâce à Pub/Sub. En effet, lors de la création de notre architecture, nous avons créé un topic Pub/Sub, auquel nous avons souscrit la Cloud Function “SQL Query”. De ce fait, dès qu’un message sera envoyé au topic, la Cloud Function sera déclenchée. Maintenant que nous savons à quoi servent les messages qui parviennent au topic, il nous reste à comprendre comment ces messages lui sont parvenus. Dans notre cas, nous avons inclus à la fin de notre code python de la première Cloud Function une fonction qui envoie un message au topic Pub/Sub en cas de succès.
La Cloud Function “SQL Query” contient un code Python qui effectue une requête SQL sur la table “Cleaned table” afin de réaliser une analyse (dans notre cas une moyenne sur une colonne). Le résultat de cette requête est écrit dans une nouvelle table BigQuery appelée “Stats table”. L’utilité de cette table est de voir l’évolution de l’analyse, puisque le contenu qui est analysé change à chaque fois que de nouveaux fichiers sont ajoutés à la table.
Ainsi, si nous devions résumer en quelques lignes tout ce que nous venons de voir, voilà ce que ça donnerait : des fichiers sont déposés dans un bucket, ils sont ensuite traités tous ensemble par une Cloud Function à un instant donné indiqué par le Cloud Scheduler. Le résultat de ce traitement est écrit dans une table BigQuery. Dès que cette opération est finie, une requête chargée de faire une analyse est effectuée et son résultat est écrit dans une nouvelle table.
Bloc de monitoring
Le dernier bloc mis en place, mais certainement pas le moins important, est celui qui permet le monitoring de notre projet. Il est représenté de la façon suivante sur notre schéma d’architecture :

Ce bloc permet de visualiser certains logs sous forme de graphiques. Afin de n’afficher que les logs qui vous intéressent, il vous faut créer des filtres personnalisés appelés “Logging metrics”. Le résultat obtenu est visible dans l’onglet “Monitoring” de l’interface de Google Cloud. Voici un exemple ci-dessous :
Dans cet exemple, le filtre créé permet de compter le nombre de logs d’erreurs provenant de nos deux Cloud Functions.
Mettre en place un bloc de monitoring est une pratique que nous recommandons vivement, et ce dès le début de votre projet. En effet, lorsque votre architecture va grossir et que le nombre de composants va augmenter, il vous sera difficile d’identifier la source d’un problème.
Cloud Function - Streaming
La seconde architecture que nous avons mise en place est elle aussi tournée aussi vers Cloud Function, mais avec désormais un mode d’ingestion des fichiers en streaming. Voici son schéma ci-dessous :
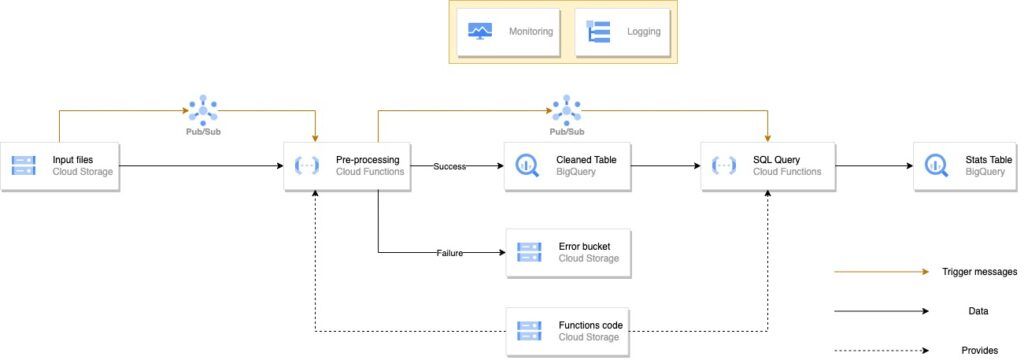
On peut remarquer que ce schéma présente de nombreuses similarités avec le précédent. De ce fait, afin de ne pas nous répéter, nous allons uniquement vous présenter les différences. Celles-ci se trouvent uniquement dans le bloc d’ingestion, que nous détaillons ci-dessous :
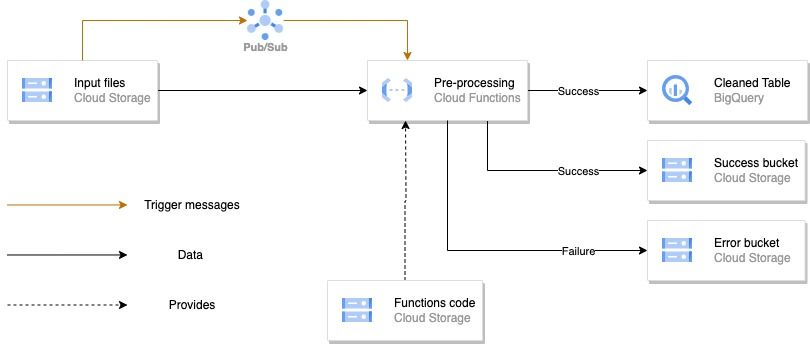
Dans cette architecture, la Cloud Function ne va plus être déclenchée à intervalle de temps réguliers à l’aide d’un Cloud Scheduler, comme c’était le cas auparavant. Maintenant, lorsqu’un fichier est déposé dans le bucket “Input files”, cela va envoyer une notification instantanément, contenant le nom du fichier ajouté, à un topic Pub/Sub auquel a souscrit notre Cloud Function. Dès que celle-ci a pris connaissance du message, elle active une instance et s’occupe d’exécuter le code d’ingestion. Avec cette façon de faire, nous aurons autant d’instances que de messages Pub/Sub seront envoyés. Ainsi, si nous déposons 4 fichiers d’un coup, alors 4 instances de Cloud Function vont s’activer et traiter chacune un fichier. On remarque que cette façon de faire nécessite forcément un code différent de celui présent dans la Cloud Function de la première architecture.
Retour d’expérience
Les principales forces de l’architecture Cloud Function sont :
Des coûts financiers et une consommation énergétique faibles, dûs à son côté serverless qui fait que Cloud Function ne consomme rien lorsqu’elle n’est pas utilisée.
Une architecture facilement modulable. Dans notre cas, nous nous sommes servis de cette architecture pour effectuer des traitements d’une certaine façon sur un certain type de fichiers. Cependant, si demain nous souhaitons changer les fichiers que traitent cette architecture et modifier le traitement opérer, il nous suffit seulement de transformer le code exécuté par la Cloud Function.
La facilité avec laquelle Cloud Function peut être pris en main. Il n’y a pas besoin d’avoir de compétences techniques très pointues. Il vous suffit seulement de fournir à la Cloud Function un fichier zip contenant tous vos fichiers Python et un fichier appelé “requirements.txt” qui précise les dépendances à installer.
Les faiblesses de cette architecture que nous avons pu noter sont :
La faible diversité des langages disponibles (seulement 7). Si jamais vous avez besoin d'effectuer une tâche dans un langage très précis, il se peut que cela soit impossible avec Cloud Function.
Le roll-back est difficile. En effet, le déploiement d’une nouvelle version du code d’une Cloud Function viendra écraser la version précédente définitivement.
Architecture Cloud Run
Suite à la première architecture, nous avons souhaité en créer une deuxième assez similaire, mais dont le principal composant change. Ainsi, nous avons remplacé les Cloud Functions par des Cloud Run. Nous ne présenterons pas en détail cette architecture car elle est similaire à la précédente. Cependant, nous avons souhaité vous montrer les schémas des architectures afin que vous puissiez voir ce qui peut être fait avec des Cloud Run, mais aussi afin que cela soit plus clair pour vous lorsque nous présenterons les résultats des tests.
Cloud Run - Batch
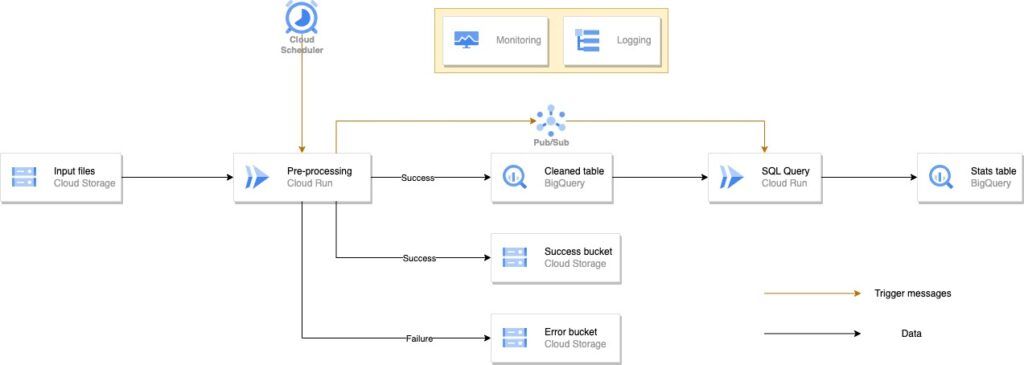
Cloud Run - Streaming
Retour d’expérience
Les principales forces de l’architecture Cloud Run sont :
Des coûts financiers et une consommation énergétique faibles, de la même façon que l’architecture Cloud Function. Cela est dû à la même raison qui est la caractéristique serverless.
La possibilité d’écrire du code dans n’importe quel langage. De façon plus générale, sachant que Cloud Run exécute une image Docker, il vous suffit juste d’avoir un code capable de fonctionner avec Docker.
La portabilité. Si demain vous souhaitez exécuter exactement le même traitement mais en local ou sur un autre cloud provider, il vous suffit d’y déployer l’image Docker que vous avez déjà en main. Cela est plus difficile avec Cloud Function car vous n’avez que le code en main, mais pas l’enveloppe qui permet de l’exécuter.
Les faiblesses de cette architecture que nous avons pu noter sont :
Une plus grande difficulté de prise en main que pour l’architecture précédente. En effet, pour cette architecture, il vous faudra désormais avoir des connaissances à propos de Docker.
Les coûts financiers de cette architecture sont plus importants que pour la précédente. Cela s’explique par la différence de limites au niveau des ressources utilisables.
Architecture DataFlow
La dernière architecture que nous avons voulu étudier est construite autour du composant DataFlow.
Qu’est-ce-que DataFlow ?
Ce composant se base sur Apache Beam qui est un modèle de programmation qui permet de faire de l’ETL (Extract-Transform-Load), que ce soit en batch ou en streaming. La suite d’opérations qu’exécute DataFlow est représentée sous la forme d’un DAG (Directed Acyclic Graph) appelé pipeline. Chaque exécution de ce pipeline est appelée un job. Lors de la création d’un job, on peut spécifier comme paramètre le template de job DataFlow que l'on souhaite effectuer. Un template est tout simplement le format sous lequel vous avez sauvegardé le code de votre pipeline. Google Cloud propose des templates déjà en place qui permettent de réaliser des actions simples. Cependant, si vous voulez faire des étapes de processing sur des fichiers particuliers, vous allez devoir créer votre propre pipeline avec vos propres variables d’environnement. Afin de lancer l’exécution d’un pipeline, Dataflow met en place des clusters de machines virtuelles entièrement managés par Google.
Particularité de Dataflow
Avec tout ce que nous avons expliqué jusqu'à présent à propos de Dataflow, il est légitime de se demander en quoi ce composant est différent de Cloud Run et Cloud Function, mis à part la complexité de son déploiement. La principale particularité de Dataflow est qu’il est capable de paralléliser le calcul. Avec les deux premières architectures, chaque nouveau fichier déposé est traité par une instance différente (dans le cas du streaming), ce qui représente déjà une répartition de la charge de travail. Cependant, pour le fichier entier, une seule instance va s’en occuper. C’est là que Dataflow se différencie. Ce-dernier est capable de paralléliser le calcul d’une seule et même opération au sein de plusieurs machines virtuelles. Par exemple, si votre fichier contient deux millions de lignes, Dataflow va être capable de découper le fichier en 4 blocs de 500 000 lignes, où chaque bloc sera donné à 4 machines virtuelles différentes afin qu’elles réalisent les calculs nécessaires. La donnée sera ensuite rassemblée de façon automatique et intelligente pour ne former à nouveau qu’un fichier. De plus, Dataflow évalue la charge de travail au début de l’exécution du pipeline, allumant ainsi le nombre de machines virtuelles nécessaires.
Schéma d’architecture
Voici donc l’architecture que nous avons mis en place pour de l’ingestion de données avec Dataflow comme composant principal :

Retour d’expérience
Les principales forces de l’architecture Dataflow sont :
La grosse puissance de calcul disponible provenant des machines virtuelles.
La répartition de la charge de travail qui s’effectue lors de la parallélisation.
L’ajustement automatique du nombre de machines virtuelles utilisées en fonction de l’importance du calcul à réaliser.
L’absence de limites de temps d’exécution
Les faiblesses de cette architecture que nous avons pu noter sont :
La difficulté de prise en main de la façon de créer un pipeline pour Apache Beam. C’est une façon de coder que nous n’avions pas l’habitude de voir, même si cela peut se faire en Python. Cela se fait aussi à l’aide de bibliothèques que nous n'utilisons généralement pas, à moins de réaliser des pipelines Dataflow depuis longtemps.
Les coûts peuvent rapidement s'avérer importants si aucune surveillance n’est appliquée sur l’architecture. En effet, cela n’est pas à prendre à la légère car Dataflow ne dispose pas de limites de temps. Ainsi, si vous lancez un traitement qui doit prendre plusieurs jours, Dataflow le fera et ne s’arrêtera qu’une fois le job réalisé.
Tests
Une fois toutes ces architectures mises en place, nous avons voulu les évaluer avec plusieurs tests de performance afin de comprendre leurs comportements dans différentes situations. Nous savons qu’il existe des évaluations de performances réalisées par Google ou d’autres organisations, cependant, ces évaluations sont théoriques et ne concernent qu’un composant à la fois, tandis que nous désirons connaître le comportement plus global, en prenant en compte l'interaction entre certains composants. Pour faire cela nous avons évalué les performances du bloc d’ingestion des architectures en streaming en relevant l’instant où le dépôt du fichier est effectué et l’instant où la dernière écriture dans la table BigQuery a eu lieu. Suite à cela, nous calculons le délai entre ces deux instants. Nous avons aussi mis en place un protocole expérimental rigoureux afin de pouvoir être sûr de la pertinence des résultats.
Tout d’abord, nous avons souhaité garantir une similarité précise entre les tests. Ainsi, les architectures réalisent exactement le même preprocessing avec les mêmes bibliothèques. Les fichiers traités sont eux-aussi évidemment identiques d’un test à l’autre. Enfin, la manière de déposer les fichiers est à chaque fois la même, réalisée de façon automatique à l’aide d’un script Python.
Ensuite, nous avons souhaité augmenter la difficulté des tests en augmentant la taille des fichiers traités. Pour cela, nous avons pris un fichier de 1 million de lignes et nous en avons multiplié ses lignes. Avec cette façon de faire, nous sommes sûrs que les dernières lignes du fichier présentent les mêmes caractéristiques que les premières et ne seront donc pas plus dures que les premières à traiter.
Enfin, afin d’éviter les cas extrêmes qui ne représentent pas une situation générale, nous avons effectué chaque opération plusieurs fois (5 fois pour être précis) et nous avons fait la moyenne de ces résultats. Cela permet une meilleure généralisation des résultats.
Nous avons réalisé des tests uniquement sur les architectures de Cloud Function et de Cloud Run car Dataflow présentait un code radicalement différent des deux premières architectures. Cela n’aurait donc pas été pertinent de les comparer ensemble.
Temps
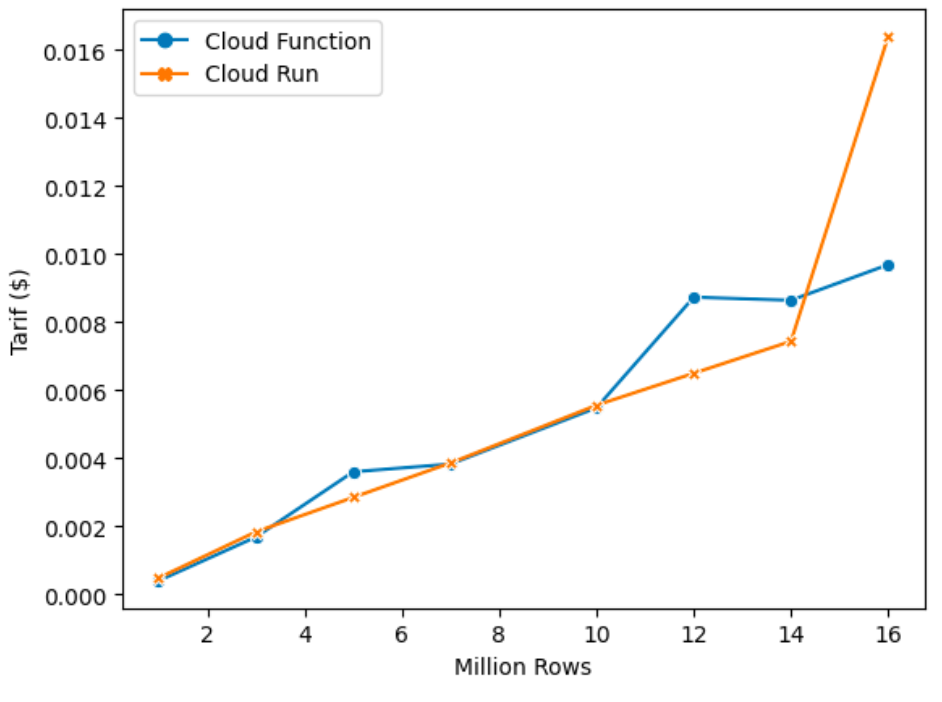
Comme énoncé précédemment, nous avons donc effectué des mesures de temps sur les architectures en mode streaming. Voici les résultats sous forme de graphique :
On retrouve en abscisses la taille du fichier ingéré (en million de lignes), et en ordonnées le temps qu’il a fallu pour ingérer ledit fichier. Ici, nous nous arrêtons à 16 millions de lignes car c’est la taille maximale de fichier qu’a pu traiter notre Cloud Function avant d’atteindre la limite de mémoire autorisée.
La première remarque qu’on peut faire en voyant ce graphique est la stabilité de Cloud Run qui est plus forte que celle de Cloud Function. En effet, certaines opérations prenaient plus de temps lorsque nous lancions une Cloud Function, c’est notamment le délai entre la dépose du fichier et le déclenchement d’une instance qui pouvait s’avérer plus long, comme si Cloud Function mettait plus de temps à prendre connaissance des messages de Pub/Sub.
La seconde remarque qu’on peut faire est la meilleure performance des Cloud Functions sur les fichiers de petites tailles, la performance égale entre les deux services pour les fichiers de tailles moyennes et passer un certain seuil (ici à 10 millions de lignes), la meilleure performance de Cloud Run. Ces résultats confirment ce que nos recherches théoriques avaient donné.
Coûts financiers
Pour cette section, nous avons simplement récupéré les résultats des performances de temps, ajouté les composants que nous avons utilisés (CPU et mémoire limites) et appliqué les règles de calcul annoncées par Google dans leur documentation. A noter que le coût varie d’une région à l’autre pour certains composants sur Google Cloud. Il est donc important de se renseigner au préalable. Dans notre cas, nous avons appliqué les prix de la zone “europe-west6”. Voici les résultats que nous vous présentons, de la même façon que précédemment :
Ici, nous remarquons l’importante corrélation entre le coût financier et le temps de calcul vu juste avant. Cela est dû au fait que pour des services serverless, vous êtes facturés à l’utilisation, donc en fonction du temps où au moins une instance est active.
Ici, nous remarquons l’importante stabilité des coûts pour Cloud Run, ce qui est moins le cas pour Cloud Function.
Le point qui peut nous interroger est le pic de prix qu’on observe pour Cloud Run lorsqu’il traite le fichier de 16 millions de lignes. Cela s’explique par le fait que nous avons dû augmenter la mémoire maximale de notre Cloud Run d’un cran afin que l’opération puisse s’effectuer, sinon nous obtenions une erreur car la limite était atteinte. Ce changement a pour conséquence l’augmentation du coût.
Afin de mieux nous rendre compte des coûts financiers que représentent l’utilisation de ces architectures, nous avons établi plusieurs scénarios et nous avons évalué combien coûteraient les différentes architectures pour chacun d’eux. Nous avons effectué cela à l’aide des valeurs que nous avons collectées lors de nos tests. Il ne s’agit donc pas d’une prévision théorique, mais plutôt d’une estimation qui se base sur une analyse pratique réalisée par nos soins.
Voici les trois scénarios que nous avons étudiés :
Dans le premier, nous partons du principe que notre client est un grand acteur du monde de la finance. Il a besoin d’une architecture capable de traiter un fichier de 16 millions de lignes, et ce 1 fois par minute, donc 1440 fois par jour. Chaque fichier contient l’historique de toutes les transactions sur le marché des actions réalisées dans la minute écoulée.
Dans ce second scénario, notre client possède un site de e-commerce. Il souhaite avoir une architecture qui pourrait traiter 5 fichiers d’un million de lignes, et ce 1 fois par heure, donc 24 fois par jour. Il souhaite déposer 5 fichiers car il dispose de 5 pages internet différentes et chacun d’entre eux contient tous les logs de connexions et d’actions réalisées dans l’heure écoulée.
Notre troisième et dernier scénario concerne notre client qui est un acteur majeur dans le secteur des télécommunications. Il souhaite déposer 10 fichiers de 14 millions de lignes d’un coup, 1 fois par jour. Chacun de ces fichiers décrit le trafic pour un service (MMS, SMS, Appels, Wi-Fi etc) sur la journée écoulée.
Voici les estimations mensuelles que nous faisons concernant l’utilisation de nos architectures dans le cas de ces scénarios-là :

La dernière colonne représente le coût de stockage sur Google Cloud Storage de nos fichiers déposés au cours du mois, si aucune action de suppression n’est entreprise.
Ce tableau révèle l'existence d’une différence au niveau du tarif entre Cloud Run et Cloud Function mais que cette différence reste, dans la majorité des cas, infime. Enfin la présence de la dernière colonne n’est pas anodine : nous avons voulu la mettre afin de souligner les faibles coûts financiers que représentent les services Cloud Run et Cloud Function, puisque rien que le stockage des fichiers dans un datalake coûte plus cher.
Petite précision concernant les prix que vous voyez affichés dans le tableau : il ne s’agit que de l’estimation du prix du bloc d’ingestion, c’est-à-dire la première étape de notre architecture. Il s’agit de la partie la plus coûteuse en termes de temps et donc en termes de budget. Nous n’avons pas non plus pris en compte les remises que met en place Google pour les premières utilisations de ses services.
Limites
Enfin, nous avons mené une analyse pour évaluer la différence entre les limites des différents services.
Nous avons voulu voir quelle taille maximale de fichier pouvait traiter Cloud Function et le mettre en opposition avec la même valeur que nous avions relevé pour Cloud Run. Pour réaliser cette mesure, nous avons fixé les CPU et mémoires limites au maximum autorisé par Google. Voici le résultat :
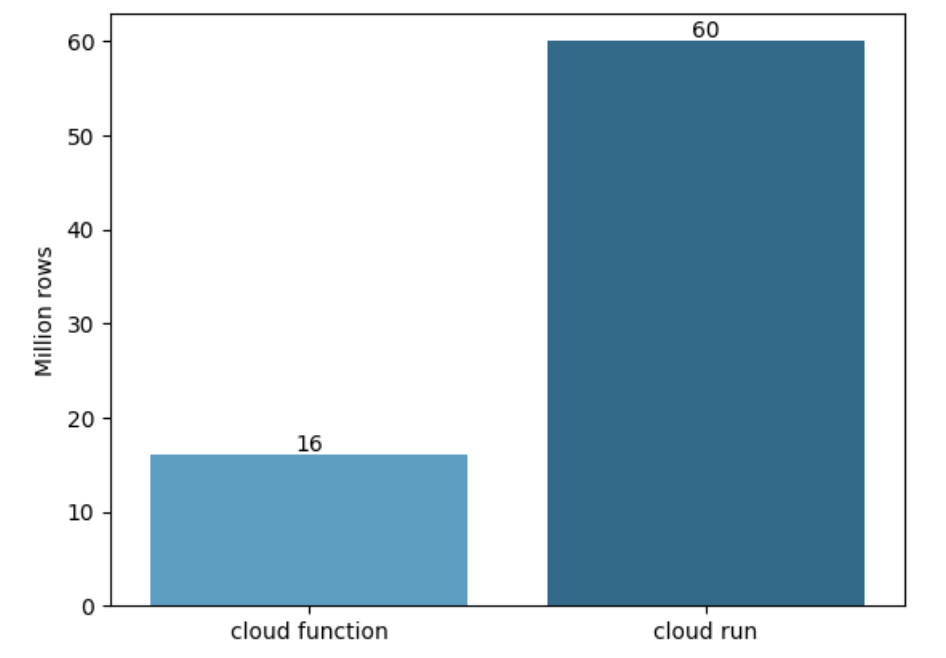
On observe que pour Cloud Function nous avons pu traiter au maximum un fichier de 16 millions de lignes tandis que ce nombre s’élevait à 60 millions de lignes concernant Cloud Run, ce qui représente une multiplication par 3,75 des capacités, en termes de mémoire, entre les deux services.
Il est aussi important de préciser que la limite de mémoire pour Cloud Function est atteinte avec le fichier de 16 millions de lignes dans notre cas, mais ce chiffre peut énormément varier en fonction du preprocessing que nous effectuons. En effet, si notre code déclare beaucoup de variables qui utilisent beaucoup la mémoire, la limite sera atteinte plus vite.
Conclusion
Tout au long de cet article, nous avons essayé de vous présenter plusieurs architectures GCP pour faire de l’ingestion de données afin que vous puissiez voir ce qui est réalisable ou pas. Nous avons aussi tenté de vous transmettre ce que nous estimons être des bonnes pratiques. Enfin, nous vous avons donné nos avis sur différents composants.
Essayons maintenant de donner une réponse en quelques lignes à la complexe question “Quelle architecture Cloud choisir pour faire de l’ingestion de données ?”.
Premièrement, la réponse à cette question dépend beaucoup du profil de la personne posant cette question. Si vous êtes quelqu’un ayant des connaissances en Python mais que vous commencez tout juste à monter en compétences sur GCP et les architectures cloud de façon générale, il sera plus simple pour vous de démarrer avec l’architecture Cloud Function qui permet de faire un grand nombre d’opérations. Si vous avez plus de temps devant vous pour monter en compétences, ou que vous connaissez déjà Docker, il peut-être préférable pour vous de passer directement sur Cloud Run. Vous bénéficierez d’une plus grande marge de manœuvre au regard des limites de ressources mais aussi vous aurez la main sur plus de paramètres qui vous permettront d’adapter au mieux votre service en fonction de vos besoins. Finalement, nous recommandons Dataflow si vous avez des bonnes compétences en pipeline de traitements de données ainsi qu’en programmation.
Le deuxième critère à prendre en compte est le volume de données que vous souhaitez traiter. Si ce volume n’est pas trop important et que vous savez qu’il ne risque pas de trop augmenter dans le futur, alors Cloud Function est largement suffisant. Si en revanche ce volume a des chances d’augmenter dans le futur, il peut être préférable de vous tourner vers Cloud Run. Dataflow est à utiliser pour des cas d’usage où le volume de données est très important ou risque de croître avec le temps. En revanche, nous le déconseillons pour des situations ne nécessitant pas une telle puissance de calcul et dont les volumes sont acceptables par Cloud Run et Cloud Function. Utiliser Dataflow dans de tels cas ne ferait qu’engendrer des temps de calcul et des coûts financiers plus importants.
Enfin le dernier critère à prendre en compte est le coût financier de votre architecture. Nous pouvons essayer de vous aider à prendre cette décision et nous espérons que la section “Coûts financiers” vous a été utile.
Annexe
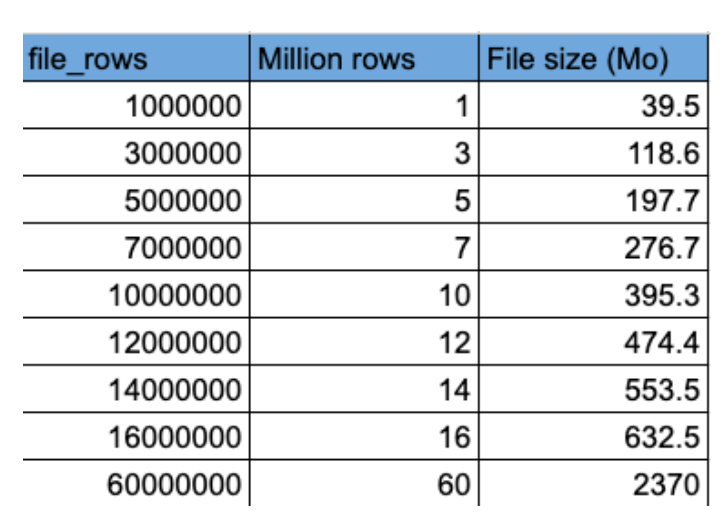
Voici le tableau qui pour chaque taille de fichier (en million de lignes) utilisé dans cette étude, indique la quantité de mémoire que ce fichier occupe :
Autres articles qui présentent des projets réalisés sur Google Cloud :