Quand votre CPU parle trop : la faille Meltdown et ses conséquences
À moins d'être encore en train de récupérer du nouvel an (belle performance, bravo !), nul n'aura raté les premières failles de sécurité de 2018 : Meltdown et Spectre.
Des chercheurs d'universités et de Google ont trouvé des failles majeures dans tous les CPUs modernes qui contournent les mécanismes de sécurité des OS. Ces failles sont tellement structurelles et répandues que toutes les catégories d'ordinateurs sont touchées : les téléphones, les serveurs, presque tous les desktops... Seuls votre Raspberry PI et votre machine à laver semblent épargnés !
L'importance de ces failles de sécurité n'est pas à minimiser. L'industrie ne s'y trompe pas, et une énorme énergie est mise en place de tous les côtés pour les corriger et en traiter les conséquences. Malheureusement, comme nous allons le voir, celles-ci risquent de perdurer de longues années et de revenir dans nos patches de sécurité pour longtemps.
Dans cet article, nous vous proposons une explication la plus simple possible de l'attaque Meltdown, des raisons pour lesquelles elle est si répandue, et des impacts à prévoir pour nos systèmes d'information.
Optimiser pour mieux régner (sur le marché)
Au coeur des attaques se trouvent les optimisations mises en place dans nos CPUs depuis 30 ans. Les constructeurs se heurtent en effet depuis longtemps aux limites de la physique, et doivent en permanence gérer deux problèmes majeurs :
- Les processus de fabrication ne permettent pas d'augmenter les fréquences à l'infini, et les cycles de R&D sur ce sujet sont trop longs pour rester compétitif,
- Si les CPUs ont énormément accéléré, la vitesse de la RAM n'a pas suivi. Sans astuce, les CPUs modernes passeraient la majorité de leur temps à attendre la RAM, annulant tous les gains de performance développés.
Afin de nous livrer toujours plus de puissance chaque année, les constructeurs développent donc de nombreuses techniques pour améliorer les performances en attendant que leurs chercheurs avancent sur les problèmes fondamentaux. Si une description détaillée remplirait des livres entiers, nous allons ici explorer deux mécanismes importants pour notre cas : le cache CPU et l'exécution out-of-order.
Le cache CPU
La première direction que les constructeurs ont pris est de mettre du cache dans leurs processeurs : de la mémoire beaucoup plus rapide que la RAM, en petite quantité (elle est très coûteuse), qui permet au CPU d'accéder très rapidement aux données utilisées récemment.
En pratique, quand le CPU a besoin d'une valeur en mémoire, il la demande au cache, qui la demande à la RAM.
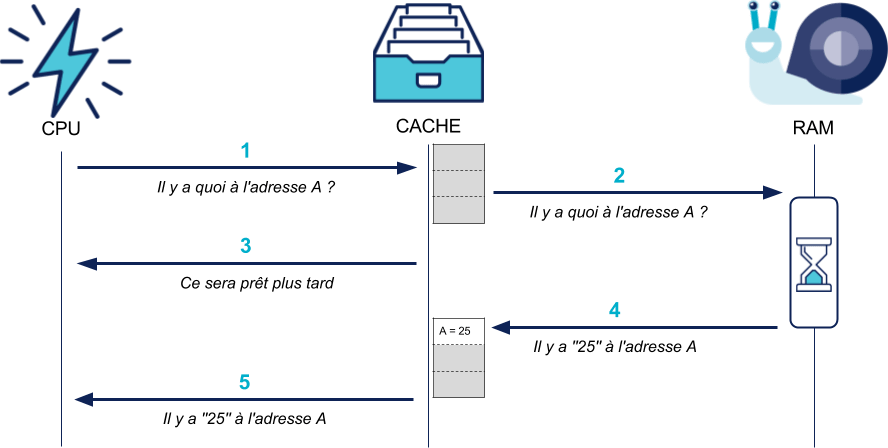
Le cache stocke la valeur récupérée et est capable de la renvoyer plus rapidement au CPU (jusqu'à 200 fois plus rapidement que la RAM) s'il la demande à nouveau :
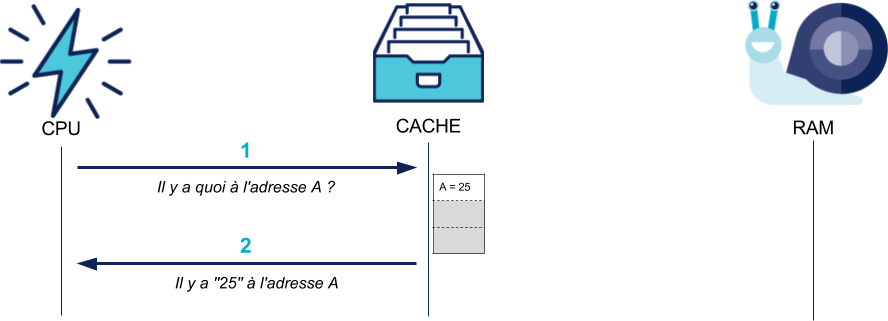
La présence de ce cache est transparente pour le programmeur : il voit seulement que certains accès mémoire sont plus rapides que d'autres, et que son programme s'exécute plus vite dans ce cas.
L'exécution out-of-order
Une fois le cache en place pour accélérer l'accès à la RAM, reste le problème de la fréquence du CPU. Comment exécuter plus d'instructions par seconde sans augmenter cette fréquence ? La réponse des constructeurs est d'en exécuter plusieurs en même temps^<a id="ref1" href="#note1">1</a>^. Les processeurs modernes vont donc lire dans le programme plusieurs instructions à la fois pour les jouer toutes d'un coup. Un exemple avec ce bout de programme :
1 resultat1 = 32 / diviseur 2 resultat2 = 10 + 13
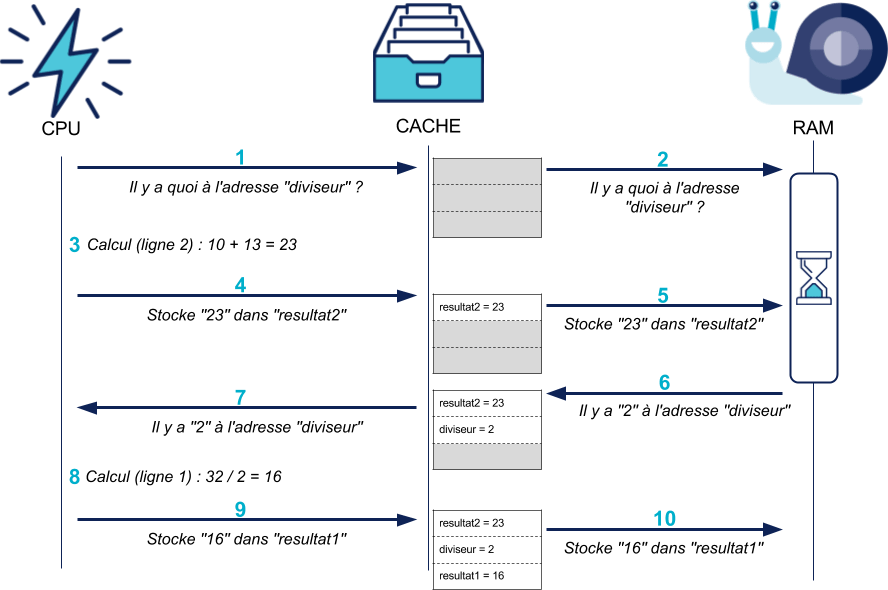
Tout comme le cache, cette optimisation est transparente pour le développeur : le CPU s'arrange toujours pour que le programme "voie" les instructions exécutées dans le bon ordre. Si une instruction génère au final une erreur, le processeur va annuler toutes celles qu'il avait déjà exécutées en avance.
Dans notre exemple, si le diviseur vaut 0, la division va créer une erreur :
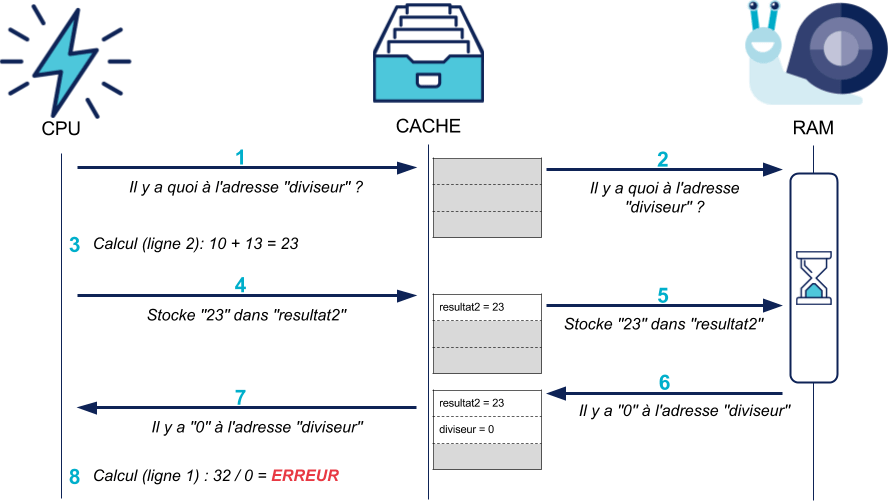
Et le CPU va annuler toutes les modifications effectuées par les instructions suivantes :
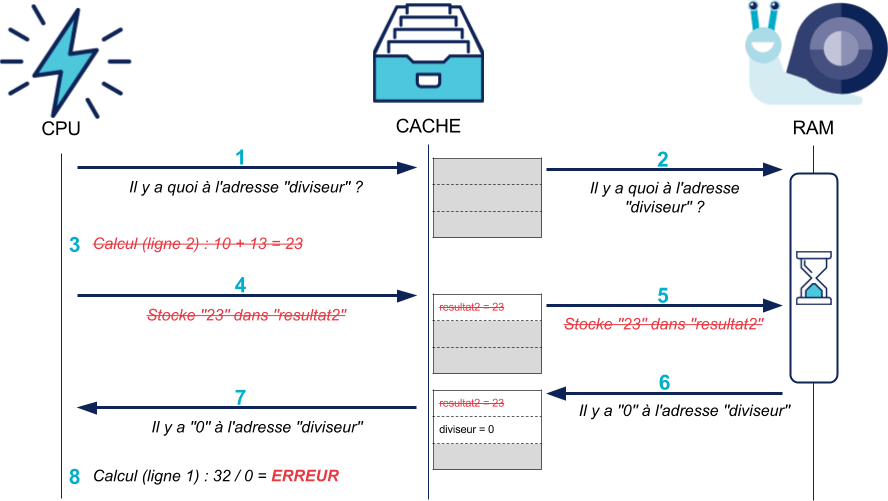
Au-delà de notre exemple simple, le processeur va plus généralement analyser le flux d'instructions (notamment pour détecter des dépendances entre les instructions) et les réordonner pour en exécuter un maximum en un minimum de temps. D'où le nom de ce système : exécution out-of-order.
L'anatomie d'une faille : au coeur de Meltdown
Vous vous en doutez, Meltdown exploite les deux systèmes décrits ci-dessus. Pour autant, leur utilisation dans une attaque n'est pas évidente. Le cache en lui-même n'est pas directement lisible par un programme : le CPU l'utilise pour accélérer les accès mémoire, mais le programme doit toujours demander l'accès à la RAM en elle-même, et le CPU valide chaque accès, cache rempli ou pas. De même, en cas d'exécution out-of-order, le mécanisme d'annulation des instructions va masquer au programme tous les accès à de la mémoire protégée qui ont été effectués.
L'approche directe
Prenons un exemple simple. Supposons qu'un attaquant veuille lire le contenu d'un secret (qui peut valoir 0 ou 1) dans la mémoire du noyau, qui est protégée, pour l'utiliser :
1 secret = memoire_noyau[adresse_dun_secret] # Mémoire protégée, illisible pour l'attaquant : ERREUR ! 2 memoire_accessible = secret
Dans cet exemple, notre attaquant a naïvement essayé de lire un secret du noyau et de le stocker dans une case mémoire qui lui est accessible.
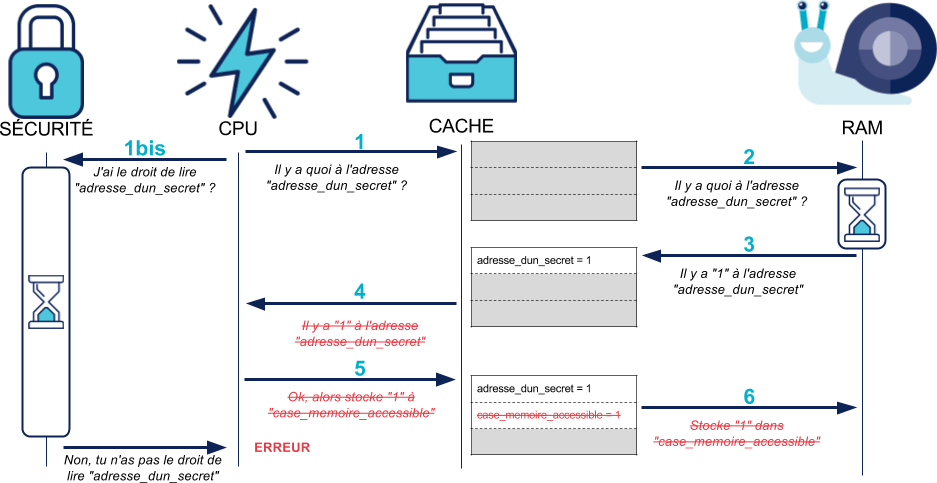
Le résultat est le même que pour notre division par zéro ci-dessus : dès que le CPU se rend compte que l'accès à adresse_dun_secret est interdit, il lève une erreur et annule les modifications des instructions suivantes.
A ce stade, les valeurs lues depuis la RAM restent chargées en cache. Est-ce là que Meltdown attaque ? Non, ça ne pose pas de problème de sécurité à priori, puisque les vérifications de sécurité sont toujours exécutées :
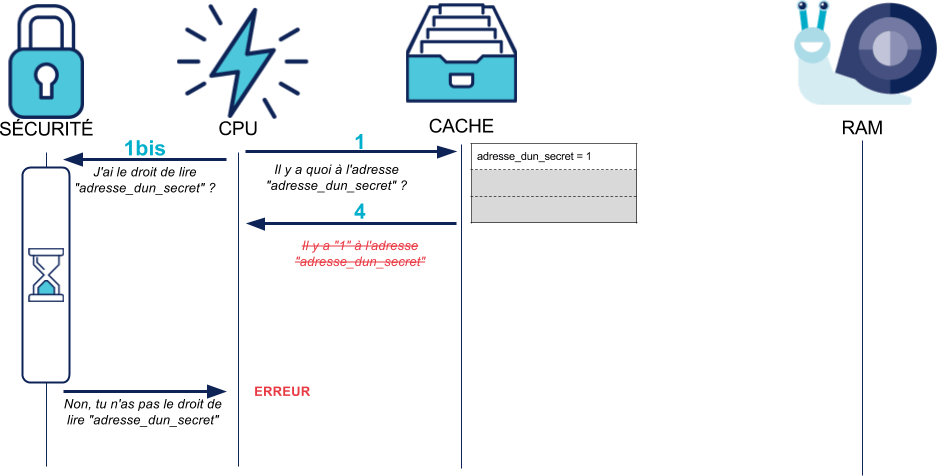
Les mécanismes de sécurité du CPU ont donc l'air bien implémentés. Comment Meltdown fait-il donc pour les contourner ?
L'approche subtile
Une variation de notre programme ci-dessus va rapidement nous donner la réponse :
1 secret = memoire_noyau[adresse_dun_secret] # ERREUR !
2 si secret est_egal_à 1 3 secret_indirect = memoire_accessible_1 4 sinon 5 secret_indirect = memoire_accessible_0
À première vue, ce programme ne nous avance pas plus :
- Certes, l'exécution out-of-order peut exécuter les lignes 2 à 5 en avance.
- Certes, la case mémoire lue va dépendre de la valeur du secret.
- Pour autant le mécanisme d'annulation va entrer en jeu, et l'écriture dans
secret_indirectsera supprimée.
À ce stade vous avez probablement l'impression que l'on vous fait tourner en rond. Pourtant, quelque chose a bien changé dans ce nouveau programme : selon la valeur de secret, la case mémoire chargée en cache (memoire_accessible_1 ou memoire_accessible_0) n'est pas la même :
[caption id="attachment_71590" align="aligncenter" width="937"] 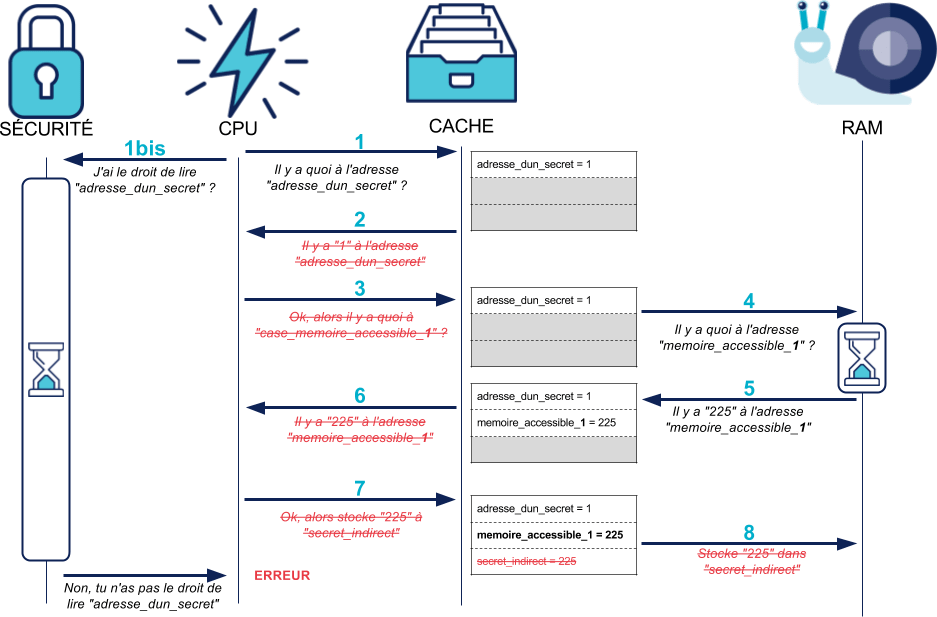
Si secret est égal à 1 : memoire_accessible_1 reste en cache
[/caption]
[caption id="attachment_71591" align="aligncenter" width="937"] 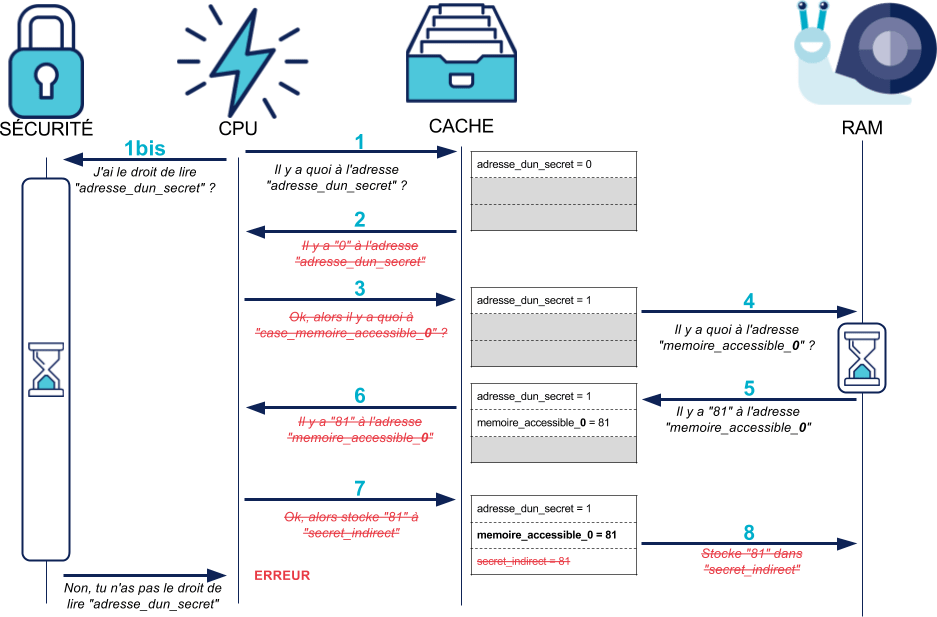
Si secret est égal à 0 : memoire_accessible_0 reste en cache
[/caption]
Et donc ? Eh bien, la vitesse d'accès aux cases mémoire 1 ou 0 a potentiellement été modifiée ! Complétons notre programme :
1 sortir_du_cache(memoire_accessible_1) 2 sortir_du_cache(memoire_accessible_0)
3 secret = memoire_noyau[adresse_dun_secret] # ERREUR !
4 si secret est_egal_à 1 5 secret_indirect = memoire_accessible_1 6 sinon 7 secret_indirect = memoire_accessible_0
Au démarrage, on s'arrange pour que memoire_accessible_1 et memoire_accessible_0 ne soient plus dans le cache : l'accès aux deux sera lent. En revanche, une fois le reste du code passé, seule l'une des deux cases aura été chargée en cache : son accès sera plus rapide.
Et on y est : il suffit de vérifier la vitesse d'accès à la mémoire en question. Voyez donc :
1 sortir_du_cache(memoire_accessible_1) 2 sortir_du_cache(memoire_accessible_0)
3 secret = memoire_noyau[adresse_dun_secret] # ERREUR !
4 si secret est_egal_à 1 5 secret_indirect = memoire_accessible_1 6 sinon 7 secret_indirect = memoire_accessible_0
8 si vitesse(memoire_accessible_1) est rapide 9 ** afficher("le secret vaut 1")** 10 si vitesse(memoire_accessible_0) est rapide 11 ** afficher("le secret vaut 0")** 12 sinon 13 afficher("l'attaque a échoué")^<a id="ref2" href="#note2">2</a>^
Le résultat est là : sans avoir directement lu la valeur de secret, l'attaquant a pu deviner son contenu à travers l'analyse du cache.
Cette technique peut facilement être étendue pour lire des octets complets : l'attaquant doit simplement préparer 256 cases mémoire judicieusement placées en RAM, et s'arranger pour que chaque valeur possible du secret charge une case différente en cache.
Préparez-vous à l'impact : les conséquences de Meltdown
L'attaque présentée ci-dessus permet en pratique de lire l'ensemble du contenu du noyau du système d'exploitation, que ce soit Linux ou Windows. Les chercheurs qui l'ont découverte ont réussi à atteindre 500 Ko/s en vitesse de lecture, ce qui est suffisant pour lire de grandes parties du noyau en quelques minutes. Le noyau en lui-même contient de nombreux secrets^<a id="ref3" href="#note3">3</a>^, et est donc une cible de choix pour un attaquant.
Pire encore, le noyau inclut une bonne partie de la mémoire des autres processus de la machine^<a id="ref4" href="#note4">4</a>^ : un attaquant peut se servir de l'attaque pour lire la mémoire des autres programmes de la machine. Ainsi, tout secret chargé en mémoire (clé privée associée au certificat SSL d'un service web, mot de passe, etc.) devient vulnérable.
Les conséquences de Meltdown sont donc désastreuses pour la sécurité informatique. Tous les OS se sont basés sur les mêmes mécanismes de protection mémoire pour se protéger d'un attaquant, et Meltdown fait complètement fondre ces mécanismes. L'ampleur de la faille est également grande : toutes les générations de CPUs Intel depuis 2010 sont concernées, et certains ARM aussi^<a id="ref5" href="#note5">5</a>^, rendant vulnérables ordinateurs de bureau, serveurs et téléphones.
Un facteur limite légérement l'impact : l'attaquant doit pouvoir exécuter du code très spécifique sur la machine cible pour exploiter la faille, et doit donc avoir au préalable un point d'entrée sur sa victime. Ce n'est malheureusement pas très rassurant pour les desktops et téléphones : une attaque peut aisément se cacher dans une application Android ou iPhone discrète, voire dans le Javascript d'une page web... Si les serveurs sont également vulnérables, ils exécutent généralement du code vérifié, et un attaquant devra déjà trouver une autre faille avant de pouvoir bénéficier de Meltdown.
Une rupture difficile, mais nécessaire
Les protections contre Meltdown passent dans leur ensemble par des mises à jour des systèmes d'exploitation. Tous les grands fournisseurs d'OS ont déjà publié des patches, vous trouverez de nombreux pointeurs sur le site de Meltdown.
La nature de la mise à jour se résume à séparer le noyau dans son propre processus, totalement isolé des autres. chaque processus a en effet une vue totalement différente de la mémoire : le CPU est limité à cette vue de la mémoire pour toutes ses opérations. Pour accéder au noyau, il faut désormais changer entièrement de vue mémoire, ce qui n'est pas possible depuis un programme, même via l'exécution out-of-order.
La séparation du noyau dans son propre processus permet de totalement bloquer Meltdown, mais avec un coût majeur : l'accès au noyau est fortement ralenti. Le changement de processus est en effet coûteux, beaucoup plus qu'un simple accès à la mémoire protégée. Or, les programmes ont besoin du noyau pour de nombreuses opérations, comme l'accès au réseau et au disque dur : les impacts de performance sont donc très variables en fonction du type de programme.
En pratique, les résultats des benchmarks sont pour l'instant très variables : certains voient déjà des ralentissements clairs de 50%, mais l'impact va fortement varier d'une situation à l'autre.
Au-delà de Meltdown, Spectre rôde
Nous vous avons présenté ici Meltdown sans parler de Spectre. Si cette seconde attaque repose sur les mêmes bases, elle est néanmoins beaucoup plus complexe, et mériterait une série d'articles à elle toute seule.
Parlons rapidement de ses effets : elle permet à un attaquant d'obtenir les mêmes informations que Meltdown mais en poussant un autre programme à exécuter l'attaque sur sa propre vue mémoire. Dit autrement, si dans Meltdown le programme de l'attaquant lit dans le noyau pour voler les secrets d'autres programmes dans Spectre il pousse les autres programmes à se lire eux-même pour lui donner leurs secrets. Tout comme Meltdown, cette faille est indépendante de l'OS, et se base uniquement sur des fonctionnalités du CPU : dans Spectre, l'attaquant "entraîne" l'unité out-of-order du CPU et celui-ci, biaisé, va prendre de mauvaises décisions quand il exécute le programme victime. En préparant bien cet entraînement, l'attaquant peut pousser la victime à charger en cache des données sensibles, qu'il peut détecter de la même manière que pour Meltdown.
Comme on l'entrevoit, Spectre est une attaque beaucoup plus difficile à exécuter par un attaquant, et nécessite beaucoup de préparation de sa part. Malheureusement, elle est aussi beaucoup plus compliquée à neutraliser ! La séparation du noyau dans sa propre vue mémoire n'est pas suffisante. Les réponses sont encore en cours de conception, et vont devoir impliquer OS, compilateurs et éditeurs de logiciels. Pour éliminer totalement la faille, un redesign des CPUs sera peut-être nécessaire, ce qui pourrait prendre des années...
La sécurité est un processus, pas un état
Meltdown et Spectre ont pris l'ensemble de l'industrie par surprise de par leur nature : les mécanismes utilisés sont présents depuis des dizaines d'années dans les CPUs sans que personne ne se soit aperçu de leur possible détournement. Par leur ampleur également : quasiment tous les ordinateurs (dans une définition large) sont impactés.
Leur correction complète va d'ailleurs s'avérer très longue : Spectre est tellement subtile et complexe que ses ramifications vont générer de nombreux patches dans les prochains mois ou années. C'est une nouvelle catégorie d'attaques que les chercheurs en sécurité commencent seulement à explorer^<a id="ref6" href="#note6">6</a>^.
Greg Kroah Hartmann, l'un des développeurs centraux de Linux le dit de manière éloquente :
Mettez à jour vos noyaux, n'attendez pas, et ne vous arrêtez pas. Les mises à jour pour résoudre ces problèmes vont continuer à apparaître pendant très longtemps.^<a id="ref7" href="#note7">7</a>^
Nous proposons même d'aller plus loin :
Soyez toujours prêts à mettre à jour vos systèmes : immédiatement, en masse, et du jour au lendemain.
En effet, Meltdown et Spectre ne sont que les dernières failles d'une longue série : Poodle, Heartbleed, Dirty COW... Toutes ces failles ont en commun d'avoir nécessité des mises à jour en masse et en urgence.
L'état des lieux de la sécurité nous oblige donc à être toujours plus réactifs, toujours plus… agiles. Alors que nos systèmes d'information se complexifient à vue d'œil, les procédures manuelles nous semblent complètement dépassées pour répondre aux enjeux de sécurité. La standardisation, l'automatisation des tests et des déploiements nous semblent donc une fois de plus incontournables.
Bonnes mises à jour !
Bibliographie
- Le l'article initial décrivant la faille, ainsi que les pointeurs vers les réponses des grands éditeurs et de nombreux autres détails.
- Des POCs d'exploitation de Meltdown existent déjà :
- Une version limitée montrant l'implémentation minimale de Meltdown.
- La version des chercheurs ayant trouvé la faille, très complète et avec des exemples montrant l'impact de sécurité de la faille.
Notes
^<a id="note1" href="#ref1">1</a>^: On parle de plusieurs instructions par coeur CPU : dans un CPU multi-coeur moderne, chaque coeur peut traiter 6 instructions à la fois. ^<a id="note2" href="#ref2">2</a>^: L'attaque ne réussit pas toujours à 100% même sur un CPU vulnérable : l'ordre réel des opérations effectuées par le CPU varie, et le contrôle de sécurité peut revenir avant que les instructions suivantes soient exécutées. Un échec est en revanche facilement identifiable par l'attaquant, et il peut facilement réessayer. ^<a id="note3" href="#ref3">3</a>^: Par exemple, l'attaquant pourrait récupérer l'état du générateur de nombres aléatoires du noyau (qui alimente /dev/random, OpenSSL et autres programmes de sécurité), lui permettant ainsi de prédire les futurs nombres renvoyés par ce générateur. ^<a id="note4" href="#ref4">4</a>^: Pour une raison totalement légitime : les programmes passent par le noyau pour toute opération de lecture/écriture sur le disque ou le réseau, et le noyau doit donc accéder aux pages des programmes pour les remplir. ^<a id="note5" href="#ref5">5</a>^: La liste n'est pas définitive : la faille est théoriquement possible sur quasiment toutes les gammes de CPUs depuis des années, même si les chercheurs n'ont pas réussi à les exploiter ailleurs… Pour l'instant. ^<a id="note6" href="#ref6">6</a>^: Les chercheurs s'intéressent depuis longtemps aux bugs des CPUs, comme le résume bien cette vidéo. Ces bugs vont certainement être analysés à nouveau dans les prochains temps à la lumière de Meltdown et Spectre... ^<a id="note7" href="#ref7">7</a>^: Traduction par nos soins de "Again, update your kernels, don’t delay, and don’t stop. The updates to resolve these problems will be continuing to come for a long period of time."