Qualité des données RH : Leçons d'un projet de reporting groupe
Albert Einstein aurait dit un jour “si j’avais une heure pour résoudre un problème, je passerais 55 minutes à réfléchir au problème et 5 minutes à réfléchir aux solutions”.
J’ai envie de prolonger cette citation par, “une fois le problème défini, je passerais 80% du temps à mettre en qualité la donnée avant de pouvoir l’exploiter et prendre des décisions”.
Cette fameuse qualité de données est au centre des projets data que nous menons au quotidien et qui nous permet, in fine, d’avoir confiance dans les données et par extension dans les prises de décisions que nous prenons.
Cet article de blog est pensé pour les delivery managers, les responsables data RH et les data engineers. Il vise à mettre en lumière les points de vigilance essentiels pour toute équipe data et à illustrer comment, collectivement, nous avons dépassé des challenges sur la qualité de données.
Je vous partagerai un retour d’expérience sur la mise en place d’un reporting RH au sein d'un groupe international. Nous aborderons les défis réels de la qualité des données auxquels l’équipe a été confrontée.
Au-delà de la théorie : À quoi ressemble une donnée de "qualité" ?
Avant de détailler notre cas pratique, faisons un rappel sur ce qu’est la qualité de données. L’association DAMA France “considère qu’une donnée est de bonne qualité lorsqu’elle répond aux attentes et aux besoins de ses consommateurs. Elle est considérée de mauvaise qualité lorsqu’elle n’est pas adéquate aux usages qu’on veut en faire. La qualité des données est donc dépendante du contexte et des besoins des consommateurs de ces données” (DAMA-DMBOK - Définition issue du Groupe de Travail sur la qualité des données de DAMA (DAta Management Association).
Une fois cette définition posée, la littérature scientifique propose différents modèles permettant de mesurer la qualité de données. Les travaux de Wang et Strong (1996) proposent un modèle conceptuel basé sur 15 dimensions de la qualité de données (figure 1).
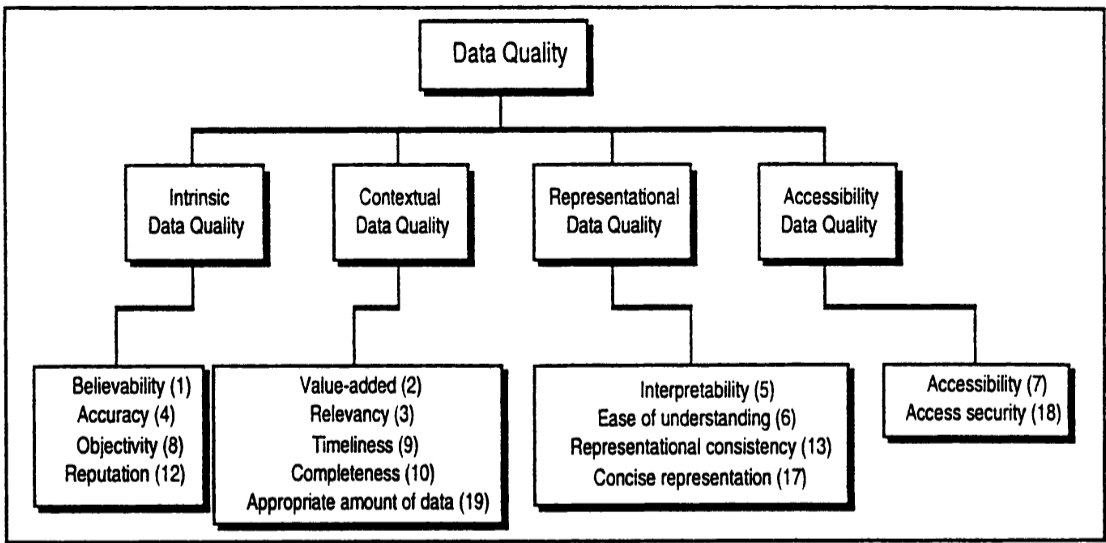
(figure 1)
D’autres modèles, notamment selon DAMA UK, proposent 6 dimensions pour l’évaluer. Ces dimensions peuvent être résumées via ce schéma (figure 2) réalisé par l’équipe Data Gouvernance d’OCTO.
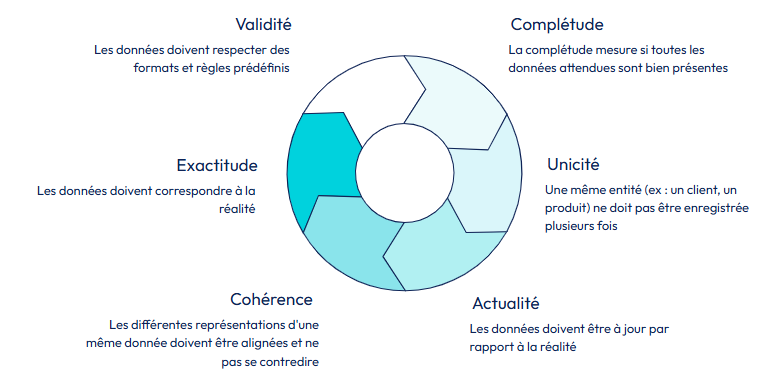
(figure 2)
L’objectif de cet article n’est pas d’explorer ces dimensions, quelque soit le modèle choisi, mais plutôt de vous embarquer dans un projet concret dans lequel nous avons dû travailler la qualité des données.
Retour d'expérience : un reporting RH au niveau groupe
Le contexte et ses défis
Notre mission s'est déroulée au sein d'un groupe international, dont la croissance s'est faite par fusions-acquisitions successives. La direction souhaitait obtenir une vision consolidée et fiable de ses effectifs mondiaux. Une question en apparence simple — "qui travaille pour nous et où ?" — mais qui cachait une grande complexité. L'objectif était de fournir aux DRH et aux contrôleurs de gestion sociale un reporting Power BI pour analyser les effectifs selon des axes multiples comme le type de contrat, le genre, la division ou la zone géographique.
Le principal défi provenait de la fragmentation du paysage data. L'héritage des acquisitions successives était un patchwork de systèmes d'information. Certaines filiales s'appuyaient sur des SIRH comme SAP SuccessFactors ou ADP, tandis que d'autres, plus petites, géraient leurs équipes avec de simples fichiers Excel. Cette hétérogénéité des sources se doublait d'une absence de référentiels communs. Chaque entité avait sa propre définition d'un "type de contrat" ou d'une "fonction", rendant toute consolidation directe impossible et erronée.
L'approche technique
Pour maîtriser cette complexité, nous avons mis en place une plateforme data sur Azure. Databricks a été choisi comme moteur de transformation, en s'appuyant sur l’architecture médaillon pour raffiner progressivement la donnée. Les données brutes atterrissent dans la couche Bronze, sont nettoyées et structurées dans la couche Silver, puis agrégées pour les besoins métier dans la couche Gold. Les données finales sont ensuite exposées dans une base PostgreSQL modélisée en étoile, un schéma optimisé pour les requêtes analytiques de Power BI.
Un principe d'architecture fort était de bannir toute logique métier des notebooks d'orchestration. Ces derniers devaient rester simples, se contentant d'appeler des pipelines de données robustes et testables.
Ce que ce projet nous a vraiment appris
Au-delà de l'architecture, ce projet a été riche en enseignements sur la gestion de la qualité des données en environnement complexe.
1. De la contrainte technique à la priorité métier
Pour nous, professionnels de la data, la nécessité d’une donnée de qualité est une évidence. Nous connaissons tous l'adage "garbage in, garbage out" et nous savons que la technique peut corriger ou pallier certains défauts jusqu’à un certain point. Mais la technique ne peut pas tout. Elle ne peut, surtout, pas repousser indéfiniment le besoin de travailler avec les experts métier pour poser un cadre de gouvernance clair et répondre aux questions de fond sur le redressement des données. Et c'est là que réside la leçon principale de ce projet : ce travail collaboratif ne démarre véritablement que lorsque le client lui-même prend conscience que la qualité des données est devenue une priorité pour lui. Cette prise de conscience s'est matérialisée lorsque la direction, souhaitant une vision consolidée de ses effectifs, a compris que l'hétérogénéité des sources et l'absence de référentiels communs rendaient sa simple question — "qui travaille pour nous et où ?" — impossible à répondre. À cet instant, la qualité des données a cessé d'être une ligne dans un plan projet pour devenir le véritable enjeu métier à surmonter.
2. L'identifiant unique : le mythe du numéro de sécurité sociale
Le premier réflexe pour identifier un salarié de manière unique est souvent de se tourner vers un identifiant national. En France, on pense immédiatement au numéro de sécurité sociale. C'était une fausse bonne idée. Au contact des experts métier RH, nous avons appris que ce numéro n'est pas immuable. Une personne née à l'étranger, par exemple, se voit attribuer un numéro temporaire qui changera si elle obtient la nationalité française. De même, une personne changeant de genre verra son numéro de sécurité sociale modifié. L'utiliser comme clé primaire aurait créé des ruptures dans l'historique des collaborateurs.
La leçon est claire : il est impératif de créer un identifiant technique interne, stable dans le temps, et de maintenir une table de correspondance pour le réconcilier avec les divers identifiants administratifs. Nous pouvons faire référence à l’unicité de la donnée, une des dimensions de la qualité de données.
2. La gestion des référentiels : le cœur du réacteur
Comment comparer des effectifs si la notion de "cadre" n'a pas la même signification à Paris, Los Angeles et Tokyo ?
L'harmonisation des référentiels, ou Master Data Management, est devenue la tâche la plus critique et la plus complexe du projet. Note particulière pour les chefs de projet, ce travail d’harmonisation peut considérablement impacter la timeline de prise en production du Minimum Viable Product.
L'apprentissage majeur ici est que la gouvernance des données est un sport d'équipe. Il faut lancer un projet à part entière, impliquant les experts métiers de chaque entité, pour définir et maintenir un référentiel d'entreprise unique (le "golden record"). Sans cet effort d'alignement, tout dashboard, aussi beau soit-il, reposera sur des sables mouvants.
3. Pseudonymisation et chiffrement : la donnée au service de l'analyse, pas du risque
Traiter des données RH impose une confidentialité absolue. Il était inenvisageable que les développeurs ou les analystes puissent accéder aux noms ou aux salaires en clair. La solution a été de pseudonymiser les données personnelles identifiantes dès leur ingestion.
Nous avons appliqué un chiffrement déterministe. Contrairement à un chiffrement classique, cette méthode garantit que la même information (par exemple, l’employé "Hubert Bonnisseur") produira toujours le même résultat chiffré. Cette propriété est fondamentale car elle permet de préserver la capacité d'analyse : on peut toujours compter le nombre d'occurrences d'une valeur ou effectuer des jointures entre différentes tables sur la base de cet identifiant chiffré, tout en protégeant l'information sous-jacente.
Cette méthode de chiffrement permet donc de conserver la cohérence des données “réelles” (même répartition par genre, type de contrat, salaires…).
4. La conformité RGPD : un cadre, pas une contrainte
Le RGPD est souvent perçu comme un frein. Nous l'avons vécu comme un guide méthodologique. L'intégrer dès la conception du projet (Privacy by Design) nous a obligé à nous poser les bonnes questions. L'étude de la nécessité d'une Analyse d'Impact sur la Protection des Données (AIPD) nous a poussé à identifier et maîtriser les risques en amont. La création d'un registre de traitement a clarifié la finalité du projet pour toutes les parties prenantes. Enfin, la définition d'une durée de conservation a permis d'instaurer des règles de cycle de vie saines pour la donnée.
La leçon finale est que la conformité n'est pas l'ennemie de la data. Au contraire, elle est un puissant levier pour construire des solutions plus robustes, éthiques et, en fin de compte, de meilleure qualité.
Conclusion
Au cours de ce projet RH, l’élément central fut assez vite identifié : comment identifier un ETP (équivalent temps plein) ?
Répondre à cette question nous a conduit à travailler les référentiels, la réglementation au travers du RGPD et la sécurité pour garantir un chiffrement des données (non accessibles en clair aux personnes non autorisées).
En conclusion, je souhaite reprendre une phrase de l’étude de Wang & Strong (1996) : “pour améliorer la qualité de données, nous devons comprendre ce que la qualité de donnée signifie pour les consommateurs (ceux qui utilisent les données)”.
Vous avez des modèles, des dimensions, des mesures à votre disposition mais au final, discutez avec les consommateurs : identifiez leurs besoins et déterminez l’élément central dans la qualité des données qui vous permettra de réaliser votre produit data dans lequel ils auront confiance.
Bibliographie
ISACA-AFAI & DAMA France — Groupe de Travail / Qualité des données (2021). Cahier pratique n°1 : Approches tactiques et stratégiques. 1ère édition.
Wang, R. Y. and Strong, D. M. Beyond accuracy: What data quality means to data consumers. J. Manage. Info. Syst. 12, 4 (1996), pp. 5–34