QCon Londres 2018
Du 5 au 7 Mars, nous sommes allés en Angleterre pour assister à la célèbre QCon de Londres, rendez-vous annuel dédié aux développeurs, organisé par le site InfoQ. La conférence se déroule sur 3 jours durant lesquels nous avons eu le choix parmi 140 présentations, réparties sur 8 tracks en parallèle, chacune dédiée à une thématique. À cette occasion, plus de 1500 participants ont répondu à l’appel.
Les sujets abordés ont été très variés. L’ambition de cette conférence est de se positionner en avance de phase sur les nouvelles technologies pour livrer un état de l’art du monde de l’informatique. Le rédacteur en chef d’InfoQ, Charles Humble, a profité de la keynote d’ouverture du deuxième jour pour nous présenter sa représentation de la courbe d’adoption des nouvelles technologies :
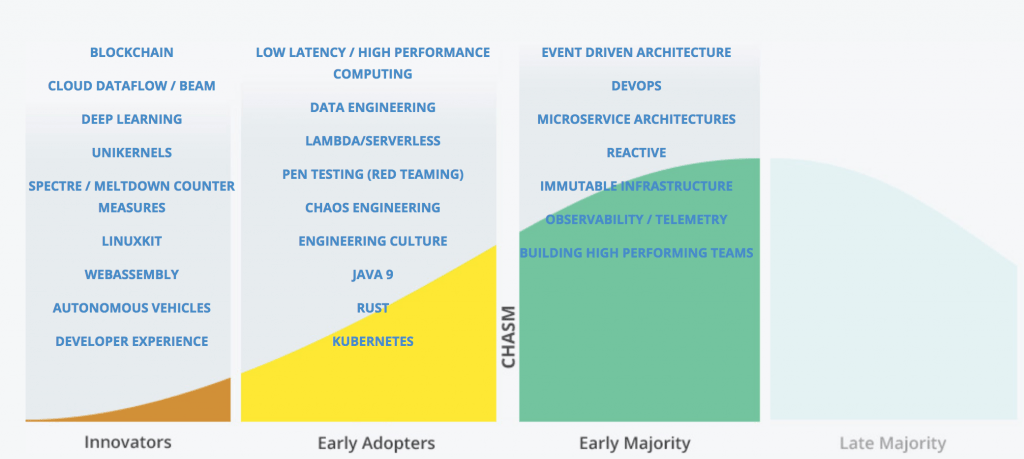
Vous l’aurez compris, la QCon est l’occasion de se mettre à la page et d’alimenter sa culture générale. Globalement les présentations sont de bonne qualité avec des speakers préparés et plutôt à l’aise avec l’exercice. Elles sont, pour la plupart, orientées technique sans pour autant perdre l’audience dans trop de détails inappropriés pour ce type d’exposé. Les enjeux techniques sont souvent bien présentés et les conférenciers fournissent les clés nécessaires pour approfondir les sujets de façon autonome.
Comme toujours pour ce type de conférence, on en sort la tête pleine de nouveaux concepts et de nouvelles idées qu’il faut prendre le temps d’approfondir. Nous vous proposons ici un retour non exhaustif des différents thèmes abordés au cours de ces trois jours.
A noter : la plupart des conférences seront accessibles en vidéo sur le site de la Qcon d’ici quelques jours.
Le Machine Learning pour tous
Comme on pouvait s’y attendre, le Machine Learning a occupé une place importante au cours de la QCon. Aujourd’hui, on le retrouve dans de nombreux use cases, et on peut trouver des frameworks pour à peu près tous ses algorithmes (Scikit-learn, TensorFlow, PyTorch, Keras…). Pour Rob Harrop, qui a ouvert la QCon avec la première Keynote, le Machine Learning est un nouvel outil qui doit faire partie du bagage technique du développeur. Il parle même de DevSecMLOps. Il s’agit non plus de faire des algorithmes qui répondent à un besoin, mais de créer des algorithmes qui trouvent le meilleur algorithme pour résoudre un problème. Sans forcément connaître les fondements mathématiques du Machine Learning, les développeurs de demain devront avoir une certaine culture des différents frameworks existants.
Les véritables problématiques actuelles autour du Machine Learning concernent en fait avant tout l’industrialisation de ses modèles, en témoigne la track The Practice and Frontiers of AI dédiée aux retours d’expérience sur le Machine Learning en production.
Nous avons relevé un certain nombre de conférences traitant ce sujet :
- Tools to Put Deep Learning Models in Production : Booking.com utilise le Deep Learning pour de nombreux use cases : extraction d’informations sur image, traduction, enchères… et a donc besoin de déployer de nouveaux modèles régulièrement. Pour cela, les développeurs utilisent Kubernetes pour faire l’apprentissage et HDFS pour stocker les modèles et les rendre disponibles via des API REST avec toujours Kubernetes.
- Models in Minutes not Months: AI as Microservices : Salesforce propose son outil, Einstein, pour facilement concevoir et déployer des modèles de Machine Learning. Son objectif est de trouver automatiquement un modèle de Machine Learning performant en fonction de features sélectionnées en entrée. Il s’intègre à de nombreuses sources, et se configure via une interface.
- Machine Learning at Google Scale : Présentation des produits de Machine Learning intégrés dans Google Platform. Simplicité et efficacité sont les maître mots de ces APIs : TensorFlow, Label Detection, Face Detection, Speech Detection, Video Properties Detection, DialogFlow.
- Neural Networks Across Space and Time : Introduction sur les fondements théoriques des différentes architectures de réseaux de neurone (Fully-Connected, CNN, RNN, LSTM) et présentation de DL4J : API écrite en Java pour le Deep Learning.
- Inside a Self-Driving Uber : La majorité des accidents de voiture sont provoqués par les conducteurs, tel est le constat mis en avant par les partisans de la révolution sans chauffeur. Basé dessus, Uber propose une voiture autonome “self-driving” équipée de plusieurs capteurs. De grands volumes de données en provenance de capteurs vont permettre de prédire la planification et le contrôle du véhicule. Pour éprouver la technologie, il suffit finalement à Uber de mettre en place une flotte de voitures de test dans une ville laboratoire pour simuler, à moindre coût, différents scénarios de trafic urbain. Suite au malheureux accident mortel impliquant une piétonne et un véhicule autonome Uber dans une ville américaine, un recul est actuellement amorcé de la part d’Uber qui a suspendu ses essais.
Pour quelques cycles CPU de plus
L’accroissement des quantités de données récoltées par les entreprises, la démocratisation du Machine Learning et, de façon plus générale, la volonté de chacun de valoriser au maximum ses données font aujourd’hui le succès des frameworks de calcul performants. En particulier, le streaming et les architectures évènementielles étaient largement représentés tout au long des trois jours. La track dédiée Stream Processing in the Modern Age était l’occasion d’avoir des retours sur des technologies encore peu exploitées comme Apache Flink ou Apache Beam. Le framework Scala/Java d’acteurs, Akka (de Lightbend), était également largement mis en avant pour sa capacité à fournir de bonnes performances avec peu de ressources matérielles. On notera par ailleurs la faible présence de certaines technologies comme Spark ou, plus largement, Hadoop, qui entrent aujourd’hui plutôt dans la catégorie “mainstream” :
- Next Steps in Stateful Streaming with Apache Flink : le CTO de Data Artisans et créateur de Flink nous présente les différentes fonctionnalités du framework, et nous livre une vision unificatrice du streaming et du batch. Pour lui, tout est une question de compromis entre complétude de la donnée et latence.
- The Dataflow Project. Réflexion autour de nos structures de données inscrites dans le temps de manière trop souvent bordée, ce document propose une vision unifiée du streaming et du batch avec un flux illimité de données en entrée. C’est notamment cette vision qui est mise en application dans Apache Beam. Ce projet écrit en Java permet également, à l’aide d’une API unique, d’abstraire le moteur de calcul (Spark, Flink, Dataflow...) aussi bien pour le batch que pour le streaming.
- Drivetribe: A Social Network on Streams : Aris Koliopoulos, CTO chez Drivetribe, nous propose une architecture construite uniquement sur des streams avec Flink, Akka HTTP et Kafka.
- Real-Time Data Analysis and ML for FraudPrevention : Paypal détecte les fraudes avec un pipeline de données associant streaming et batch pour faire tourner différents modèles de Machine Learning (Deep Learning, Régression…) reposant sur des sources de données avec des fenêtres de temps différentes.
- High Performance Actors : Akka est une implémentation Scala du concept d’acteurs. Kiki Carter est architecte chez Lightbend et fait le tour des optimisations mises en place dans Akka : compression, utilisation de ByteBuffer, intégration de Aeron pour la couche réseau. Trois surcouches du modèle d’acteurs sont proposées par Akka : Akka HTTP, Akka Stream et Akka Cluster.
Recherche base distribuée transactionnelle : bon relationnel attendu
Les bases relationnelles oeuvrent depuis longtemps au service de presque tous les systèmes d’information d’entreprise. Elles offrent une flexibilité de développement et des performances qui répondent à la plupart des cas d’usage. Cependant, passés certains caps de volumes de données associés à certaines exigences de temps de réponse, les traitements sont généralement déportés vers des bases de données distribuées. On passe alors d’un modèle relationnel avec des propriétés ACID à une base soumis au joug de l’impitoyable théorème CAP. Les modèles de données doivent alors évoluer, et toute l’architecture doit être repensée pour répondre aux nouvelles contraintes imposées par les bases NoSQL.
Quelques irréductibles développeurs ont cependant cherché à réconcilier les deux mondes et ont créé la mouvance NewSQL. Celle-ci fait aujourd’hui particulièrement parler d’elle notamment depuis l’annonce par Google de l’offre Spanner en 2017, avec la promesse d’une base distribuée mondialement respectant les propriétés ACID. Dans sa présentation, The Future of Distributed Databases Is Relational, Sumedh Pathak nous montre comment il a construit une base relationnelle distribuée en repartant du code source de Postgres.
De façon plus générale, un problème central des modèles distribués vient de la cohérence des données. Comment mettre tout le monde d’accord ? C’est la question à laquelle tente de répondre Heidi Howard dans son talk Consensus: Why Can't We All Just Agree?. Elle passe en revue les grands algorithmes de consensus existants (Paxos, Multi-Paxos, Fast-Paxos, Raft, State Machine Replication…) et nous fait prendre conscience de l’ampleur des efforts fournis par la communauté scientifique dans ce domaine encore peu maîtrisé. Selon elle, la recherche sur ces problématiques permettra bientôt d’avoir des algorithmes de consensus ayant de moins en moins d’impact sur les performances. C’est d’ailleurs ce que cherche à nous montrer Martin Thompson, auteur du blog Mechanical Sympathy, avec une implémentation performante de l’algorithme Raft, dans sa présentation Cluster Consensus: When Aeron Met Raft . Pour cela, il utilise Aeron, une librairie performante de messaging.
Enfin, Martin Kleppmann nous propose une approche différente dans CRDTs and the Quest for Distributed Consistency. La différence avec le consensus est la suivante : au lieu de chercher à mettre tout le monde d’accord à chaque requête, chaque acteur du système accepte toutes les modifications qui lui sont soumises, puis toutes ces modifications sont mises en commun pour être fusionnées (ou mergées pour faire le lien avec le terme anglais). On parle alors d’algorithme de convergence et non plus de consensus. C’est sur ce concept que reposent Google Doc et Git. Plusieurs approches existent, mais Martin Kleppmann nous présente plus en détail les CRDTs : une structure de donnée permettant de tenir compte de l’historique des modifications pour converger. Il nous fait également une démonstration d’Automerge : une implémentation JavaScript du concept de CRDT.

Martin Kleppmann comparant les deux principaux algorithmes de convergence : Operational Transformation et Conflict-Free Replicated Data Types
Observabilité
Entre le découpage des applications en microservices et l’émergence de plateformes de déploiement des applications, chacun des participants a convenu de la difficulté à maîtriser son parc applicatif. Comment gérer la performance de son application, avoir une vue sur l’ensemble des services et corriger des bugs avec une solution simple de monitoring et d’alerting ?
Si le monitoring nous permet de connaître l’état de notre système, l’observabilité, elle, nous permet de savoir pourquoi le système ne marche pas.
Avec toute une track dédiée sur l’observabilité, on retiendra les talks suivants :
- How to build observable distributed systems : Pierre Vincent nous explique très bien les promesses de l’observabilité et les limites du monitoring : celui-ci ne s’applique que sur des métriques connues. En cas d’incident sur des métriques non connues, l’observabilité doit permettre de comprendre plus rapidement les causes des incidents. On retiendra notamment les outils Prometheus et Grafana pour le monitoring, Honeycomb pour les logs, Opentracing et Zipking pour le tracing.
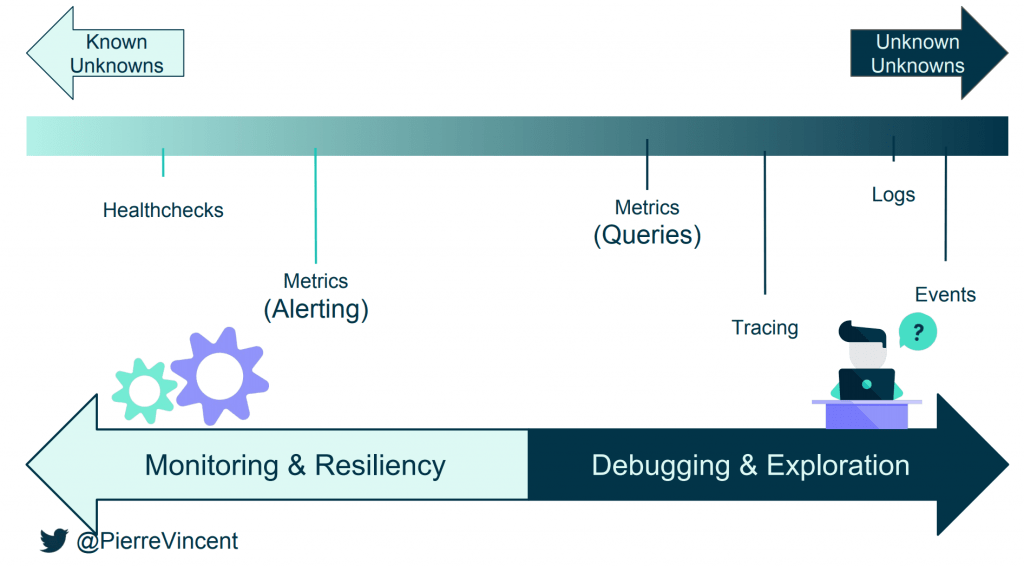
Vue d’ensemble des différents composants pour observer un système
- The present and future of serverless observability : Comme le rappelle Yan Cui, développeur à Space Ape Games, monitorer est important : “Amazon found 100ms latency cost them 1% in sale”. Il nous partage son retour d’expérience à propos du monitoring de Lambda sur AWS avec des Lambda, CloudWatch et une stack ELK. Pour finir, selon lui, le futur est de pouvoir visualiser en temps réel les interactions entre composants.
- Observability and Emerging Infrastructures : De façon volontairement extrême, Charity Majors, CEO HoneyComb, estime que le monitoring est mort. Les dashboards ne permettent pas d’interpréter facilement les incidents et les métriques ne répondent qu'à des problèmes connus, ce qui ne correspond plus aux besoins d’architectures complexes et évolutives. Le plus difficile est souvent d’identifier le composant à debugger ou à tracer. Comparés aux simples métriques, les évènements et les logs constituent un ensemble d’informations plus intéressant à traiter en cas de problème. Attention à ne pas tomber dans l’excès, à récupérer tous les logs pour tous les composants. Par ailleurs, l’agrégation de logs risque de détruire de précieux détails car notre façon de les récupérer est biaisée par notre expérience. L'observabilité est un ensemble de best practices qui, selon Charity Majors, est plus important que les tests (troll).


DevOps and Kubernetes
Kubernetes n’est plus une nouveauté, et les talks “Kubernetes: Crossing the Chasm” et “Tamming Distributed Statefull Pets With Kubernetes”, se concentrent maintenant sur des retours d’expérience ou des évolutions possibles de la plateforme. En complément, lors du talk “10k Deploys a Day - the Skyscanner Journey so Far”, on découvre comment l’équipe est parvenue à déployer des milliers de fois par mois sur ce type de plateforme. On voit également apparaître le concept de DevEx dans “Develop your development experience” :
- Develop your development experience : DevEx désigne le fait de passer rapidement d’une idée à une application en production en maximisant l’efficacité des développeurs, notamment au travers de l’automatisation. Jessica Kerr, développeuse à Atomist, nous présente l’outil Atomist qui permet, entre autres, de fédérer et d'automatiser les outils de source code, CI /CD et monitoring. Exemple : en définissant un template Spring, il est possible, au travers d’une commande Slack, de créer une branche, générer un squelette et de le déployer.
- Kubernetes: Crossing the Chasm : La question n’est pas de savoir si Kubernetes va être massivement adopté, selon Ian Crosby, mais plutôt quand. Avec une base solide (projet open source basé sur l’expérience de Google) et une communauté croissante, tous les atouts sont du côté de la plateforme. Attention cependant, Ian nous rappelle que Kubernetes n’est pas fait pour tout le monde et tous les cas d’usage. Il nous fait part de son retour d’expérience pour le cluster multi-zone (la fédération de controler manager est intéressante) et le déploiement dans des zones non connectées à internet (récupération des paquets et déploiement du cluster à la main). Les futurs challenges concernent le support sur Windows, l’intégration avec des legacy/vendor software ou encore avec le cloud hybride.
- 10k Deploys a Day - the Skyscanner Journey so Far : C’est avec humour et énergie que Stuart Davidson, de Skyscanner, nous fait part de son retour d’expérience pour arriver à plusieurs milliers de déploiements par mois. On en retient que :
- Il ne faut pas aider les équipes, mais les aider à savoir faire
- Il ne faut pas passer trop de temps à expérimenter un nouvel outil. Il faut commencer par le plus simple et le plus facile
- “Start small”
- Tamming Distributed Statefull Pets With Kubernetes : Au travers de ce talk, James Munnelly et Matthew Bates de Jetstack, nous présentent les différentes possibilités et les évolutions pour déployer des applications stateful au sein d’un cluster Kubernetes. Tous les systèmes distribués, tels que Zookeeper, MongoDB ou Elasticsearch, ne se valent pas. En déployant une application avec les ressources basiques Kubernetes, on note deux contraintes importantes : la nécessité d’un administrateur applicatif en cas d’échec, et l’impossibilité de voir rapidement l’état du système distribué au travers des différentes ressources. Le pattern Operator et les Custom Ressource Definition répondent à ce problème en offrant la possibilité d’étendre l’API Kubernetes pour y ajouter des “controlers” dédiés à des applications spécifiques. Pour différentes raisons, JetStack a récemment développé “Navigator”, une toute nouvelle extension basée sur le pattern Operator, qui évite une réécriture complète du “controler”. Après discussion informelle avec différents participants, voici quelques bonnes pratiques et informations sur Kubernetes :
- Pas de ressources Alpha en production (ressources possiblement vouées à disparaître comme les Initializers)
- NetworkPolicy vs Istio :
- NetworkPolicy : Intervient au niveau TCP
- Istio : Intervient à plusieurs niveaux dont HTTP, permet une granularité plus fine pour le contrôle et peut également remonter l’information. Il amène également une complexité supplémentaire au système.
- Séparer le code applicatif du code de déploiement car chacun a un cycle de vie différent
Une architecture orientée serverless suivrait les microservices
Du monolithique en passant par les services pour arriver sur des architectures microservices, la granularité des services appelés est de plus en plus fine. Avec l’utilisation des Lambdas, l’architecture web se décompose maintenant au niveau de la plus petite unité de calcul : la fonction. Poussé à l’extrême, on pourrait décomposer chacune des méthodes d’un programme en appels consécutifs de fonctions sur des architectures serverless. Chacune de ces fonctions pourraient même être écrites dans des langages de programmation différents. En contrepartie, ces architectures complexifient le suivi des applications.
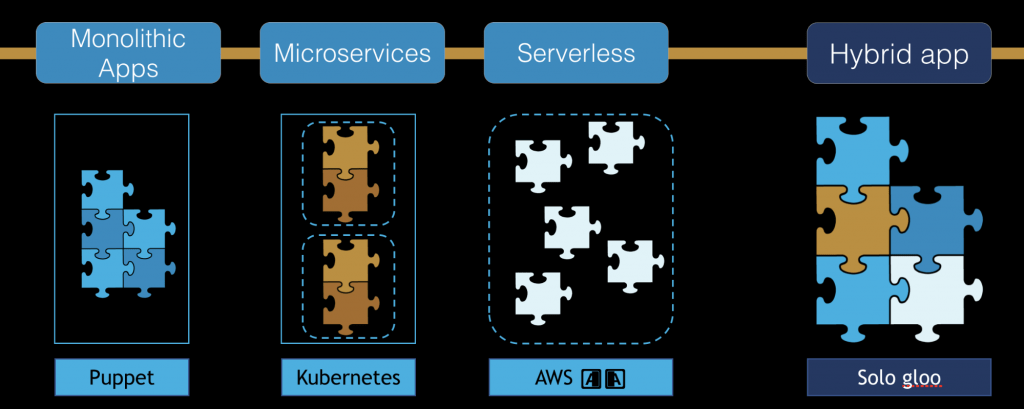
Du monolithique au Serverless
- Debugging Micro Services Applications : Le debugging est extrêmement compliqué sur des architectures microservices pour arriver à suivre les requêtes sur de multiples serveurs avec des technologies sous-jacentes différentes. Ivit nous vient en aide en nous présentant trois solutions : le suiveur de requêtes Opentracing, le debugger de containers micro-services Squash et le Service Mesh. Sa vision après l’architecture microservices est l’architecture « function-services » reposant sur du serverless, les fonctions étant la plus petite unité de calcul décomposable (projet en cours avec Gloo).
- Serverless Spring (Solution Track - Pivotal) : Le Serverless permet de réhausser la value line et de se concentrer sur les besoins métier. Présentation des différentes possibilités avec Spring Cloud : utilisable sur toutes les plateformes (AWS Lambda, Google function (java non disponible nativement pour le moment), Azure...). Riff combine Spring et Google Kubernetes : lancement d’une JVM à la requête avec la possibilité de conserver la même instance pour plusieurs requêtes consécutives.
Postures en entreprises
Après l’intégration avec les Ops pour former les DevOps, l’introduction des data scientists avec le DevOpsML, il reste un domaine absent dans les équipes de développement : la sécurité. Laura Bell insiste sur le fait qu’il s’agit d’un sujet primordial, surtout dans des architectures qui sont de plus en hétérogènes. Elle développe cette idée dans Guardians of the galaxy: architecting a culture of secure software. Le security manager porte parfois une trop lourde responsabilité. Elle le compare à Batman : agissant dans l’ombre comme protecteur des méchants de l’extérieur. Or, il est en fait isolé et vulnérable en plus d’être dans une position incertaine si jamais la sécurité de l’entreprise est défaillante. Laura Bell poursuit ensuite l’analogie : au lieu d’appeler la Justice League pour améliorer notre défense en ajoutant des super héros, on ferait mieux d’inclure la sécurité comme un rôle partagé dans l’équipe de développement : une équipe réunissant des non-experts aux compétences complémentaires avec pour objectif de concevoir un système sécurisé (comme les gardiens de la galaxie).
Avoir des compétences n’est pas suffisant, il faut aussi avoir l’envie d’en développer de nouvelles, nous rappelle Randy Shoup dans Attitude determines altitude - Engineering Yourself. “I Know I can improve”, avec cette volonté et un entraînement pour focaliser son attention, on gagne confiance en soi pour appréhender des nouvelles expertises. Les présupposés de la théorie Y sont mis en avant en rappelant que la théorie X, bien présente dans beaucoup d’entreprises, entraîne uniquement une démotivation des équipes. De même pour le Syndrome de l’imposteur : Randy voit au travers de ses expériences de nombreux experts douter de leur capacité et de leur légitimité. On retrouve ce phénomène avec l’effet Dunning-Kruger : lorsque nous débutons dans un domaine, notre confiance en nous croît très rapidement car nous ne sommes pas encore conscience de ce que nous ne savons pas. Nous commençons à douter avec l’expérience car nous découvrons des connaissances que nous ne maîtrisons pas.
Au plus proche du hardware
Les nouveaux frameworks de calcul proposent de nouvelles abstractions afin d’obtenir les meilleures performances avec le minimum de connaissance bas niveau. A l’inverse, Gil Tene, CTO de Azul Systems, nous propose de revenir sur les différents comportements de base du compilateur Java et sur les optimisations réalisées par le JIT dans Java at Speed. Il nous rappelle que la notion de rapidité s’inscrit dans un contexte et doit uniquement s’adapter à un besoin précis. Interprétation du bytecode, profilage et optimisations sont les différentes phases réalisées par le JIT, et nécessitent une connaissance approfondie avant de se lancer dans des optimisations inutiles. C’est aussi l’occasion pour lui de présenter la JVM d’Azul capable de répondre très rapidement au démarrage car elle se dispense de la phase d’échauffement grâce au chargement d’optimisations précalculées.
De son côté Howard Chu, dans Software Design for Persistent Memory Systems, nous présente les avantages des RAM persistantes avec tous les enjeux encore non résolus autour de la cohérence et de l’atomicité des écritures. Encore une fois, le message est clair : il vaut mieux attendre que des APIs un peu plus haut niveau émergent (des librairies C par exemple) avant d’exploiter vraiment ces nouveaux composants.
Enfin, Tim Ellison était présent pour nous parler d’ordinateur quantique et des avancées d’IBM sur le sujet : The Extraordinary World of Quantum Computing. Ces nouvelles infrastructures pourraient nous permettre de résoudre de nombreux problèmes où la combinatoire est importante et où on ne possède pas d’algorithme autre que d’essayer toutes les possibilités pour trouver une solution : typiquement les problèmes NP-complets, parmi lesquels on trouve de nombreux problèmes de calculs scientifiques. Aujourd’hui, les ordinateurs quantiques n’ont pas encore tout à fait atteint la puissance nécessaire pour concurrencer les ordinateurs classiques, même si Google semble s’en approcher à grands pas. On estime qu’il faudrait une machine d’au moins 50 qubits, capable de maintenir son état pendant suffisamment longtemps pour que l’ordinateur quantique présente un intérêt. Néanmoins, on peut d’ores et déjà commencer à appréhender le concept avec la solution de Cloud Quantum Computing proposée par IBM : IBM Q Experience. On dispose pour cela d’un ordinateur quantique de 5 qubits avec lequel on peut interagir en configurant des portes logiques quantiques au travers d’une interface graphique plutôt intuitive (à condition de savoir coder avec des portes logiques quantiques…). Une API Python, QISKit, permet également d'interagir avec une infrastructure quantique distante. Rappelons toutefois que l’ordinateur quantique n’a pas vocation, dans la connaissance actuelle des choses, à remplacer l’ordinateur classique pour lequel l’un des enjeux majeurs est le temps de réponse. Il permettrait, en revanche, de faire évoluer des domaines nécessitant de fortes puissances de calcul, comme le Machine Learning ou la cryptographie.

Tim Ellison présentant un cas d’application de l'ordinateur quantique à la chimie
Conclusion
La QCon est l’occasion de prendre le temps d’appréhender au plus tôt les évolutions technologiques de demain. La notion de futur est toutefois variable d’un domaine à l’autre : le Machine Learning et même le Deep Learning sont sortis des laboratoires de recherche depuis bien longtemps, et des technologies comme Akka ou Kubernetes ne sont plus réservées aux quelques entreprises à la pointe. A l’inverse, les ordinateurs quantiques ne sont pas encore exploités à large échelle. Le tout étant de savoir où notre entreprise se situe sur la courbe d’adoption.
Si vous êtes un adepte de futurologie, vous pouvez également lire notre article décrivant notre vision à 5-10 ans dans lequel nous nous sommes prêtés à un jeu difficile : extrapoler les signaux actuels pour tenter de prédire la courbe d’adoption de demain.