Prévenir ou guérir ?
Although the crew was aware of ice in the vicinity, they did not reduce the ship's speed, and continued to steam at 22 knots (41 km/h; 25 mph), only 2 knots (3.7 km/h; 2.3 mph) short of her maximum speed of 24 knots (44 km/h; 28 mph).[22][e] Titanic's high speed in waters where ice had been reported was later criticized as reckless, but it reflected standard maritime practice at the time. According to Fifth Officer Harold Lowe, the custom was "to go ahead and depend upon the lookouts in the crow's nest and the watch on the bridge to pick up the ice in time to avoid hitting it".[25] https://en.wikipedia.org/wiki/Sinking_of_the_RMS_Titanic
The Titanic Effect: The thought that disaster is impossible often leads to an unthinkable disaster. Jerry Weinberg
Scene: Inside Penny’s car. Sheldon: Thank you for driving me to work. Penny: You know this is my day off, Sheldon. Sheldon: Oh, good. I’m not keeping you from anything. Your check engine light is on. Penny: Mm-hmm. Sheldon: Typically that’s an indicator. To, you know, check your engine. Penny: It’s fine, it’s been on for, like, a month. Sheldon: Well, actually, that would be all the more reason to, you know, check your engine. Penny: Sheldon, it’s fine. Sheldon: If it were fine, the light wouldn’t be on. That’s why the manufacturer installed that light, to let you know it’s not fine. Penny: Uh, maybe the light’s broken. Sheldon: Is there a “check the check engine light light”? Chuck Lorre - The big bang theory
Indicateurs avancés, indicateurs retardés
En économie on distingue les indicateurs avancés des indicateurs retardés. Un indicateur avancé permet d'anticiper, encore qu’avec imprécision et incertitude, une réalité économique future. Un indicateur retardé permet de mesurer une réalité économique en cours avec précision, mais ne permet pratiquement aucune prévision. Pour prendre une analogie, cette sorte de différence entre indicateurs avancés et retardés existe également dans nos sens :
Les sens "prédictifs" : vue, ouïe, odorat, permettent d’anticiper une situation possible, mais manquent d'exactitude : on ne perçoit pas concrètement et avec certitude la situation, on peut seulement se la représenter comme possible. En revanche, on dispose de nombreuses options pour répondre à ce que nos sens semblent nous indiquer. (Si vous voyez une forme bouger au loin, et entendez un bruit inhabituel, il est encore possible de prendre la fuite, ou de vous préparer à une mauvaise surprise, ou encore de chercher à obtenir plus d’information).
Les sens "réactifs" : toucher, goût, manifestent directement, au présent et avec une certaine exactitude une réalité concrète observable. On dispose par contre de beaucoup moins d’options pour réagir à la situation donnée. (Vous êtes au contact avec un agresseur, il n’y a aucun doute, et les options sont en très petit nombre).
Voici une autre analogie : supposons que je souhaite améliorer ma forme physique. Dans ce contexte, mon poids en kg est un indicateur retardé : je peux le mesurer facilement, avec précision, et aussi souvent que je le souhaite. Mais cette mesure ne me permet pas vraiment de prédire quoi que ce soit. Je "découvre" que j'ai pris trois kilos, et il n'y a rien que je puisse faire pour changer cette réalité dans l'immédiat. D'un autre côté, le nombre de calories ingérées par jour, ainsi que la quantité d'exercice physique réalisé, sont des mesures un peu plus compliquées à mettre en place, mais elles permettent, quoiqu’avec une importante marge d’erreur, de faire certaines prédictions concernant ma forme physique à venir.
Pour une équipe de développement logiciel, y a t’il des exemples intéressants d’indicateurs avancés et retardés ?
Dans la catégorie des indicateurs "avancés" on pourrait ranger :
- la couverture des tests unitaires : cet indicateur permet de prédire — avec une précision et une certitude faibles — quelles parties du code contiendront plus d‘erreurs de programmation ou de conception que les autres parties. Un taux de couverture très faible pourrait signifier de nombreux incidents à venir. Un taux très élevé pourrait indiquer que le code est bien protégé contre les erreurs et les régressions.
- le nombre de points relevés en revue de code (ou de spécification) : cet indicateur permet également d'anticiper des problèmes futurs — sans savoir précisément lesquels — dans le logiciel, que ce soit dans son comportement, ou bien dans son adéquation aux besoins des utilisateurs. Un nombre de points relevés très faible pourrait signifier que le produit n’a été que sommairement revu et réserve encore de nombreuses surprises en production (ou bien que le niveau de qualité du code revu est d’emblée excellent ?). Un nombre élevé pourrait signifier que ce code et cette conception ont été soigneusement revus (mais ont-ils été corrigés ?).
Bien qu'ils soient difficiles à obtenir (et les obstacles à les obtenir sont surtout humains), et parfois même à interpréter (car ils peuvent aisément être faussés) ces indicateurs sont très utile parce qu’ils autorisent une certaine marge de manœuvre : par exemple si votre code ne comporte aucun test unitaire, et n'a fait l'objet d'aucune revue, il est encore possible de remettre sa livraison en production à plus tard, le temps de mettre en place un minimum de processus et de pratiques en vue d'améliorer sa qualité. Ou bien de renoncer tout bonnement au projet.
Dans la catégorie des indicateurs "retardés", on pourrait ranger :
- le nombre d'incidents rencontrés en production : cet indicateur ne "ment" pas, il témoigne clairement d’un problème de qualité dans le processus de développement. Il serait certes possible de savoir précisément et en détail ce qui est à l'origine de chaque incident (au prix d’efforts d’analyse et de facilitation non-négligeables), mais tel qu'il est délivré, cet indicateur n'autorise pratiquement aucune marge de manœuvre. Il ne peut donc pas conduire à une amélioration de la qualité de vos process et pratiques de développement.
- les retours qualitatifs effectués par des utilisateurs référents : là encore, l'indicateur ne ment pas (voulez-vous réellement croire et affirmer que vos utilisateurs vous mentent ?), mais là encore, la marge de manœuvre pour améliorer la qualité a posteriori est extrêmement limitée.
En résumé, les indicateurs avancés vous offrent plus d’options, une meilleure anticipation, mais le prix à payer peut être considérable et le résultat incertain :
- il faut établir et collecter les informations : en l’occurence, réaliser ces tests unitaires et ces revues, ce qui requiert un process, des pratiques, une certaine discipline, donc également une grande cohésion dans l’équipe, ainsi qu’avec le management.
- les informations recueillies ne produisent pas de modèle prédictif très fiable : d’une part il y a trop peu d’information recueillies (même pour un projet de grande taille), d’autre part les acteurs du système, qui sont au cœur des décisions, manquent d’objectivité dans leurs observations comme dans leur interprétations.
- les données, le modèle, les prédictions sont toujours sujettes à des discussions possibles en fonction du contexte, qui est bien souvent spécifique à chaque projet.
Les indicateurs retardés vous offrent une mesure précise et imparable de la qualité de votre logiciel, mais vos options se limitent à contrôler les dégâts :
- le recueil des informations demande peu d’effort à mettre en place. (Un simple outil de ticketing, voire une ligne téléphonique, ou un réseau social suffisent).
- les informations recueillies sont pratiquement indubitables : même dans le cas où l’on pourrait discuter des causes et des responsabilités derrière ces problèmes (ce qui ne manque jamais d’arriver), il reste que les problèmes sont bel et bien présents.
- il est pratiquement impossible de prédire quoi que ce soit sur la qualité de votre produit à l’aide de ces indicateurs seuls.
- les options se limitent à la correction des symptômes et à la gestion de la crise.
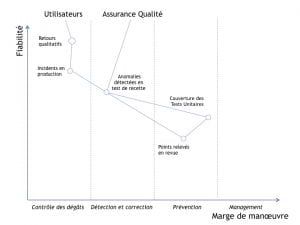
_Fiabilité relative des indicateurs de qualité, et les marges de manœuvre qu'ils autorisent_
La double fatalité des raccourcis sur la qualité
Selon qu’une équipe de développement mesure la qualité de ses résultats grâce à des indicateurs avancés ou retardés, sa capacité à produire du logiciel fiable, maintenable et répondant aux besoins de ses clients, sera plus ou moins grande. Favoriser la mise en place d’indicateurs retardés revient à fonder une démarche de qualité sur la correction des défauts. C’est une approche que l’on retrouve par exemple dans la culture des start-ups, notamment lorsqu’elles prennent le dicton « move fast and break things » un peu trop à la lettre. Mais de nombreuses entreprises plus structurées et disposant de bien plus de moyens voient pourtant leur processus de développement se dégrader au fil du temps jusqu’à devenir un simple « suivi des incidents ».
Favoriser la mise en place d’indicateurs avancés revient à fonder une démarche de qualité sur la prévention des défauts. C’est l’approche généralement adoptée par les géants du logiciel, et qui implique non seulement les développeurs, les tech leads, les testeurs, les pilotes fonctionnels, le management, mais également la gestion des ressources humaines.
Dans une entreprise qui n’utilise que des indicateurs retardés, c'est seulement lorsque les incidents apparaissent en recette ou en production que des décisions sont prises en vue d'améliorer les choses. Bien souvent, ces décisions se limitent à :
- gérer la relation avec le client ;
- apporter au plus vite des corrections, en vue de relivrer au plus tôt (après tout, c’était peut être le dernier “bug”) ;
- faire beaucoup plus d’heures supplémentaires ;
- se mettre personnellement à l’abri du blâme et des chasses aux coupables.
De telles décisions visent à améliorer la situation présente, mais elles n’améliorent en rien le processus de développement. Au contraire, elles le détériorent un peu plus :
- le code relivré est sujet aux régressions (insertion ou réinsertion de défauts lors des actions de “bugfix” en urgence) ;
- toute activité autre que corriger des bugs ou finir des tâches de programmation est repoussée à plus tard, voire interdite ;
On assiste alors à une boucle de renforcement positif (qui n'a de positif que sa structure, car en réalité, les mauvaises nouvelles s'enchaînent de plus en plus vite).
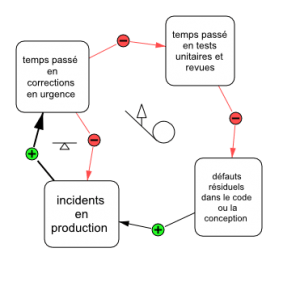
Pour changer de stratégie, en l’occurrence pour commencer à effectuer des revues ou des tests unitaires, il faut améliorer le processus, et former les personnes qui sont en charge du développement. Mais comme ces personnes sont aussi en charge de diagnostiquer et corriger les défauts ayant causé des incidents, elles manquent continuellement de temps, de crédibilité et de confiance pour pouvoir se former ou améliorer leur processus :
- Les prévisions de stabilisation erronées (ou l’aveu d’incertitude complète) placent l’équipe en porte-à-faux avec le client, et la relation avec ce dernier devient plus difficile.
- La crédibilité de l’équipe diminue, alors qu’un sursaut de confiance et de sécurité serait nécessaire afin de commencer à apprendre (c’est à dire à tirer parti de ses erreurs).
- Une atmosphère de chasse aux coupables domine le cadre de travail, et il devient alors impossible de s’améliorer (sans même parler d’acquérir une nouvelle pratique), car les stratégies personnelles de défense, et le drame qu’elles provoquent, mobilisent toute l’énergie et l’attention.
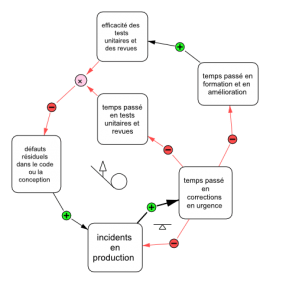
( ⊗ : effets composés renforçant une diminution ou une augmentation)
Dans un contexte de maintenance d'un logiciel de plusieurs centaines de milliers de lignes de code, ne disposant d'aucun test unitaire, et n'ayant fait l'objet d'aucune revue depuis plusieurs années, il n'est pas rare de constater que l'équipe en charge s’est créé certaines habitudes afin de s'adapter comme elle le peut à cette double fatalité des raccourcis sur la qualité :
- tolérance aux problèmes de qualité (les "bugs" font partie de la vie de l'équipe);
- découragement des initiatives visant à améliorer la qualité du code ou du produit;
- empilement de "solutions" nouvelles sur le produit sans effort pour fiabiliser, simplifier et pérenniser le code existant;
- pertes ou obfuscation des métriques et autres sources d'informations à propos de la qualité;
- postures incongruentes de protection : par exemple, blâmer les utilisateurs, les "mauvais" développeurs, les chefs "inconséquents dans leurs décisions", les clients "qui ne savent pas ce qu'ils veulent" etc.
- turn-over ;
Passer du correctif au préventif : la transformation invisible
La fatalité des habitudes de travail, l’impossibilité de se donner ne serait-ce que quelques jours pour tenter d’améliorer l’approche de développement, la pression des délais exercée sur un projet de plus en plus en retard, constituent un cercle vicieux bien souvent inexorable. Mais qui dit « cercle vicieux » dit aussi possibilité d’un cercle vertueux. Une équipe disposant du temps et de la confiance nécessaire pour se former pourra commencer à appliquer un process et des pratiques permettant d’anticiper les problèmes de qualité au lieu de les subir. À moyen terme, cette équipe se retrouvera moins souvent dans des situations d’urgence, ce qui lui permettra en retour de prendre à nouveau plus de temps pour se former et améliorer encore sa façon de travailler.
Pour commencer à "renverser" la situation, pour transformer le cercle vicieux en cercle vertueux, il faut se mettre simplement à observer les indicateurs avancés, et leur donner un sens, c'est à dire établir une corrélation entre l'état de la base de code, le niveau des pratiques de qualité, et le nombre de défauts ayant provoqué des incidents en production. Pour ce faire il faut mener des rétro-analyses pertinentes sur les incidents, identifier leur origine dans le code ou la conception, puis trouver des contre-mesures adaptées concernant le processus et les pratiques à mettre en œuvre. À moyen terme, il devient possible de faire de meilleurs prédictions basées sur la couverture de tests unitaires ou le nombre de points relevés en revue, et ainsi d’améliorer progressivement la qualité du produit.
Entreprendre une telle amélioration est particulièrement difficile. Cela demande de la ténacité et du courage. A l’heure où toutes les sociétés parlent de leur transformation, bien souvent le changement qui consiste à progressivement substituer des indicateurs avancés là où sont en place uniquement des indicateurs retardés, — changement qui repose sur une action cohérente des équipes, de leur tech leads et du management — relève de la mission impossible. Une telle transition vers une meilleure qualité représente un projet à moyen, voire long terme. Or c’est le court terme qui domine bien souvent les décisions, en particulier celles qui touchent un logiciel de mauvaise qualité maintenu tant bien que mal durant des années :
- j’ai besoin que le logiciel soit opérationnel demain, je ne peux pas attendre que les développeurs soient formés ;
- ce logiciel coûte cher à maintenir, et un surcroît de dépenses en formation est malvenu ;
- pourquoi est-ce que je formerais des personnes qui pourraient ne pas rester sur le projet ?
- à long terme, il y a toujours une échappatoire possible : refonte, mutation, outsourcing.
Que faire ?
Votre application présente de nombreux problèmes de qualité, l’équipe est démoralisée, le bugdet de maintenance en conditions opérationnelles est de plus en plus lourd, chaque nouvelle version entraîne avec elle une série toujours plus longues d’incidents en production. Que pouvez-vous faire ?
Faites une pause afin d’observer.
Si pour vous gérer la qualité consiste uniquement à corriger les défauts constatés, votre projet de développement se dirige lentement mais sûrement vers une situation d'échec irrécupérable : le travail de correction va mobiliser l'essentiel de l'énergie de l'équipe, les dépassements vont s'accumuler, et avec eux les sacrifices supplémentaires sur la qualité du code ou de la conception. Les activités de prévention, pour lesquelles l'équipe n'est pas formée, et qu'elle ne saura pas défendre face à l'urgence de la crise, passeront au second rang, quand elles ne seront pas tout bonnement rejetées. Pour éviter cette catastrophe, il ne suffit pas de la pressentir, il faut aussi en rendre les signes précurseurs visibles par tous. Prenez le temps d’observer les symptômes, de sélectionner des incidents significatifs et d’identifier, au delà des excuses et des raisons apparentes, leurs causes. Vous trouverez très certainement des incidents dont la cause est liée à la conception fonctionnelle, c'est à dire, dans un projet Agile, à la qualité et à la fréquence des conversations avec le Product Owner. Vous trouverez également des incidents dont la cause est liée à la façon dont le code a été produit, et bien souvent dans ce cas, vous trouverez du code qui n’a pas été testé unitairement, et qui n’a pas été relu par l’équipe.
Rétablissez les indicateurs avancés.
Les indicateurs avancés de qualité sont ceux qui permettent de faire des prédictions — même approximatives — sur le nombre de défauts que l'on pourra trouver dans votre produit logiciel. Très souvent, ces indicateurs avancés sont indisponibles, ou bien déréglés. Parfois ils sont truqués de façon à atteindre des « objectifs ». Lorsque ces indicateurs sont présents mais indiquent des valeurs trop basses, on cherche à en établir d’autres, qui produiraient une meilleure impression. Par exemple, on mesure, en vue de l’optimiser, la “couverture” des tests fonctionnels en recette. Or cet indicateur est tronqué, car les tests de recette automatisés omettent un grand nombre de chemins possibles dans l’exécution du code. De plus c’est un indicateur retardé et non avancé : il ne permet pas de faire des prédictions fiables concernant la qualité du travail réalisé en amont de la recette, uniquement des constats. Renforcer la “couverture de tests” en recette ne contribue pas à améliorer les pratiques de développpement.
Faites preuve de lucidité.
Si la couverture de tests unitaires de votre projet est proche de 0%, cela signifie que les développeurs ne vérifient pas systématiquement le code qu’ils produisent et maintiennent. S’ils ne font aucune revue, cela signifie que le code part en production sans avoir été relu par une autre personne que son auteur. C’est là votre situation de départ. Les causes en sont simples à comprendre et n’ont rien à voir avec le niveau d’engagement, le caractère des personnes en charge du développement ou bien l’heure à laquelle elles font leur daily meeting. Ces indicateurs avancés proches de zéro signifient simplement que les activités qu’ils reflètent n’ont pas cours dans votre environnement de développement. Le remède consiste alors à créer les conditions pour que ces activités deviennent courantes.
Mettez en place une stratégie de formation et d’amélioration.
Une stratégie réaliste d’amélioration de la qualité s’appuie en premier lieu sur une phase de formation aux pratiques de préventions des erreurs. Durant cette phase, l’équipe immobilise une partie de son temps en formation, en expérimentation et en amélioration de son processus de développement. Contrairement à ce que l'on constate pour l’acquisition de connaissances technologiques, l’acquisition de pratiques de prévention des erreurs s'appuie rarement sur des initiatives individuelles isolées. Faire de TDD et de la revue de code en collectif les nouvelles pratiques standard de l’équipe, cela ne se produit pas en lisant un tutoriel pendant la pause repas : cela requiert de l'entr'aide, de la cohésion d’équipe, et le support du management. En somme, cela implique une volonté commune de surmonter les obstacles que la situation présente — la double fatalité des raccourcis sur la qualité — pose à l’acquisition des pratiques.
Gagnez l’adhésion de tous les acteurs.
Votre stratégie de transition du correctif vers le préventif doit faire l’objet d’une communication et d’un engagement auprès de tous les acteurs concernés par votre activité de développement, et non pas seulement les développeurs : architectes, responsables applicatifs, responsables métier, financiers, ainsi que des R.H. Si vous êtes isolés (par exemple si vous estimez que le changement devra être transparent pour votre direction métier), la transition vers une meilleure qualité n’aura pas lieu.
Donnez des marges de manœuvres; demandez des améliorations.
La double boucle de renforcement des raccourcis sur la qualité signifie qu’à moins que lui soit donné un répit de temps pour se former et améliorer son niveau de pratique, il est impossible à une équipe prise dans cette boucle d’améliorer la qualité de son code. Or le budget de temps dont elle dispose est l’affaire des managers. Par conséquent en tant que manager, votre premier levier de changement consiste à établir et défendre un budget de temps qui permette à l’équipe de sortir du cercle vicieux. Cela signifie que les estimations d’effort faites en début d’exercice ou bien lors du cadrage du projet ne sont pas correctes et doivent être revues. En l’occurrence ces estimations sont déjà en cours de révision, puisqu’un projet qui rencontre des problèmes de qualité se retrouve inéluctablement en dépassement de budgets et de délais. Il ne s’agit pas tant d’autoriser les dépassements que d’affecter ces dépassements à la bonne cause, c’est à dire mieux prévenir les défauts du logiciel. 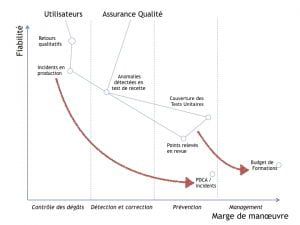
_Nouveau indicateurs, après un déplacement de la gestion de la qualité du correctif vers le préventif_
Maintenez la maintenabilité de vos applications.
Le code que l’équipe produit aujourd’hui, dans les conditions où elle le produit, impacte son travail futur, non pas dans deux ans ni dans six mois, mais dans deux semaines, lorsque les défauts apparaîtront suite à la première livraison en production. Face à cette situation, l’équipe pourra prétendre qu’elle “s’endette techniquement” afin de tenir un délai intermédiaire (la prochaine démonstration, ou autre échéance impossible à repousser). L’excitation associée au démarrage du projet, l’absence de consensus à propos des standards de qualité, ainsi que le manque de savoir-faire en matière d’amélioration continue, vont engager l’équipe dans une “course aux users stories” : en surface, l’équipe produit une application dont les fonctionnalités s’ajoutent les unes aux autres à une vitesse exceptionnelle. En réalité, elle bâtit sur le sable. Elle possède un niveau de pratique adapté sans doute à la construction d’un proof of concept, mais une fois impliquée dans la réalisation d’une application complexe, cette démarche ne tiendra pas la distance. Le moment du projet où la complexité fonctionnelle est la plus faible, où la pression sur la qualité et les délais ne se fait pas encore sentir, où l’équipe dispose encore de la crédibilité et de la confiance nécessaire pour s’améliorer, est le moment précis où cette équipe devrait faire le point sur sa démarche, et la compléter avec les pratiques de prévention des défauts. Au lieu de se demander comment aller vite, elle doit d’abord se demander comment aller loin.