Prevendo o futuro com filtros colaborativos
É possível prever o futuro? Muitos acreditam que um homem chamado Michel de Nostradamus foi capaz. Suas previsões têm intrigado estudiosos por mais de quatrocentos anos.
Prever o futuro sempre foi um dos maiores desejos do ser humano, isso pode ser visto em quadrinhos, filmes de Hollywood, e até mesmo na cigana que te aborda na rua para ler a sua mão. A ciência afirma que prever o futuro pode ser uma capacidade humana: uma pesquisa empírica sugere que o cérebro possui uma certa capacidade de perceber o que está por vir...
Mas, falando em tecnologia, como os aplicativos atuais conseguem oferecer produtos e serviços como se tivessem “adivinhando” a necessidade do usuário? O Neo diria que eles usam os poderes do Oráculo, mas acredite, não é bem assim...
Casos
No final de 2009 a Netflix lançou um concurso para aprimorar o mecanismo de recomendação de sua plataforma, onde o objetivo era encontrar uma forma de melhorar em 10% o que o seu código atual já realizava: Recomendações de conteúdo aos seus usuários baseando-se no histórico de cada um. O premio seria nada menos que 1 milhão de dólares.
Para recomendar um amigo de forma mais assertiva, o Facebook se baseia nos usuários que visitam sua pagina, as conexões entre vocês e até os lugares por ondem passaram. O Google Lê os seus e-mails para sugerir produtos baseados no conteúdo de cada e-mail.
Hoje em dia, antes mesmo de o usuário usar um serviço, ele já contou metade da sua vida para o banco de dados, e cada vez mais esses dados são usados para melhorar a experiência dos usuários na aplicação, oferecendo a recomendação de algum produto ou serviço de acordo com o perfil/histórico de cada um, dessa forma sendo muito mais assertivos em recomendar coisas que eles realmente gostariam de ter.
Tipos de abordagens
Tecnicamente falando, existem três principais tipos de mecanismos de recomendação baseados em aprendizagem de máquina (machine learn):
- Model-based (recomendação por características do item)
- Memory-based (recomendação por similaridade do perfil do usuário)
- Hybrid solution (união dos dois anteriores)
As duas primeiras técnicas possuem seus pontos fortes e fracos:
Baseado em Modelo
- Vantagens:
- Gera modelos que representam a matriz de avaliações;
- Permite o sistema reconhecer padrões complexos;
- Utiliza protipagem e redução de dimensionalidade;
- Lida melhor com dispersão dos dados e escalabilidade;
- Melhora performance de previsão;
- Dá uma justificativa intuitiva para as recomendações;
- Desvantagens:
- Construção do modelo pode ser custosa;
- Percas em técnicas de redução de dimensionalidade;
- Vantagens:
Baseado em memória
- Vantagens:
- Fácil implementação;
- Novos dados podem ser adicionados facilmente;
- Não precisa se preocupar com o conteúdo dos itens recomendados;
- Bem escalável para itens co-avaliados;
- Desvantagens:
- Dependente das avaliações dos usuários;
- Perde performance com a dispersão dos dados;
- Não consegue recomendar com poucos itens/usuários;
- Tem escalabilidade limitada;
- Vantagens:
E obviamente a Hybrid solution tenta sanar as limitações oferecendo as vantagens de ambas abordagens.
Ao se desenvolver um sistema de recomendação de filmes, por exemplo, utilizando a técnica Model-based (tipo 1), temos que olhar para as características dos filmes que o usuário viu, por exemplo, se o usuário “Pedro” gostou dos filmes: “Conan” , “Predador” e “Exterminador do futuro”, então o sistema deve entender que esse usuário gosta dos filmes com o Arnold schwarzenegger, e portanto oferecer por exemplo “Mercenários” como recomendação.
Por outro lado, se o sistema de recomendação for do tipo 2 (collaborative filtering), é analisado o perfil do usuário, de acordo com seus “vizinhos”, por exemplo o usuário “Pedro” gostou dos filmes: “Rock” , “Duro de Matar”, “Exterminador do futuro” e , o usuário “José” gostou dos filmes: “Rock” , “Duro de Matar”, então o sistema deve entender que esses são usuários similares (vizinhos), e assim recomendar ao usuário “José” o filme “Exterminador do futuro”.
Matematicamente falando
O problema de um sistema de recomendação consiste basicamente em analisar o conjunto de todos os usuários (C) de um determinado sistema, sobre o conjunto de todos os possíveis itens que podem ser recomendados (S'). Sendo u a função utilidade que mede o quão útil é um determinado item s para um determinado usuário c, i.e., u:C x S → R, onde R é um conjunto totalmente ordenado. Então, para cada usuário c ∈ C, procura-se um item s' ∈ S que maximiza a utilidade do usuário. Isto pode ser expressado pela equação abaixo:

Sendo mais especifico o desafio reside no fato da utilidade u geralmente não ser definida em todo o espaço C x S, mas apenas em um subconjunto deste. Isto significa que u precisa ser extrapolado para todo o espaço C x S.
Geralmente em sistemas de recomendação, a utilidade é definida através de avaliações, e estas são definidas apenas nos itens previamente avaliados pelos usuários. Deste modo, o algoritmo de recomendação deve ser capaz de estimar (predizer) as avaliações não realizadas para os pares usuário-item e de fazer recomendações apropriadas baseadas nestas predições.
Uma solução baseada no modelo de filtro colaborativo (colaborative filtering) poderia ser descrita pela formula:
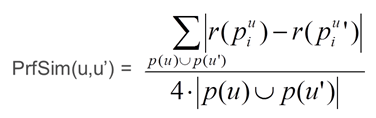
Olhando sob a forma de pseudocódigo poderíamos entender da seguinte maneira:

Prevendo o Futuro
Tá! Muito legal esse monte de números nessas fórmulas malucas, mas afinal de contas como meu sistema de recomendação vai identificar a similaridade entre os usuários e recomendar os filmes corretos?
Vamos a um exemplo mais visual: Considere a matriz abaixo como sendo de filmes e usuários, contendo notas de 1 a 5:
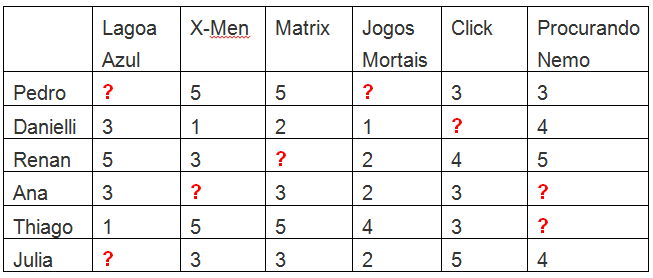
Agora que a premonição acontece, pois o algoritmo deve atribuir uma nota aos filmes não pontuados pelo usuário, se baseando na similaridade dos mesmos, ou seja, separar os usuários por grupos, onde nesse caso podemos nitidamente ver as semelhanças nas notas entre Pedro/Thiago, Danielli/Ana e Renan/Julia, por exemplo.
Executando o algoritmo nessa situação teríamos:
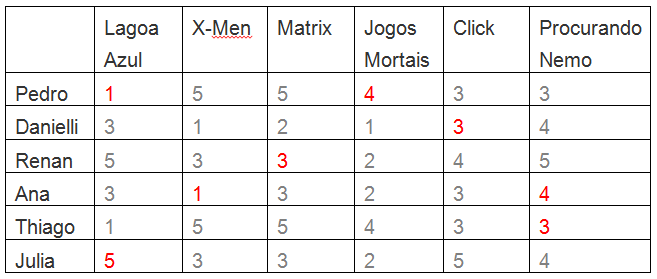
Dessa maneira, mais do que dizer que Pedro iria gostar de “Jogos Mortais” e a Julia iria adorar “A Lagoa Azul”, saberíamos que a Ana detestaria “X-men”.
Por onde começar?
Uma vez que se tenha o case definido, é hora de pensar em qual tecnologia utilizar para construir o seu sistema de recomendação. Obviamente a escolha irá ser tendenciosa para a linguagem/plataforma em que se tem mais afinidade.
No entanto é importante atentar para algumas funcionalidades de cada framework, como por exemplo, o quanto escalável pode ser o algoritmo, afinal, sistemas de recomendação são geralmente executados sobre grandes massas de dados e naturalmente levam muito tempo para serem processados.
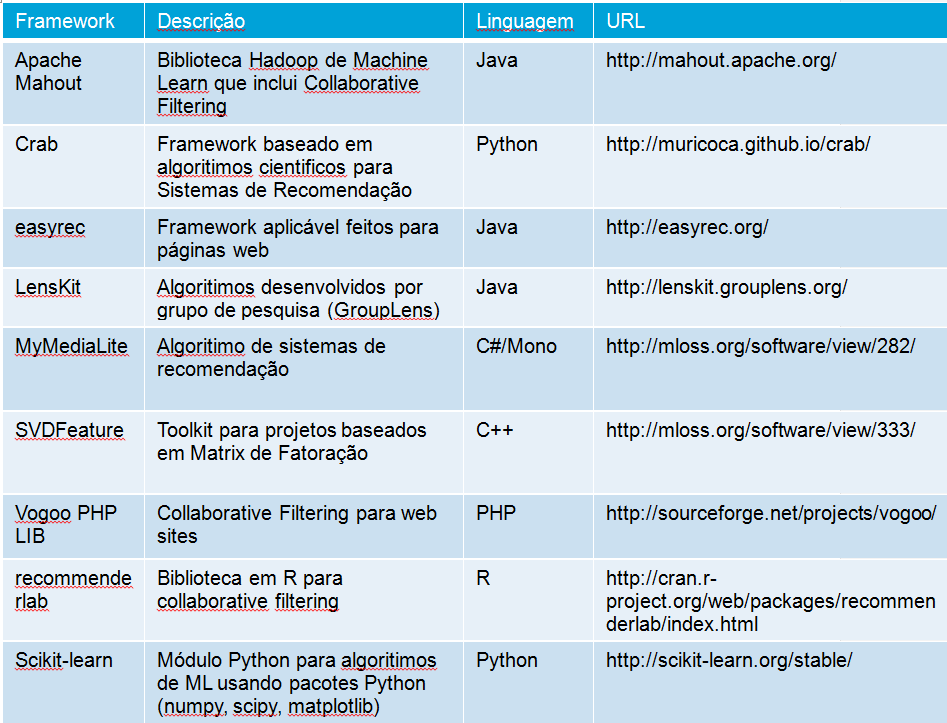
Na tabela abaixo temos uma lista com alguns frameworks de sistemas de recomendação:
Mãos na massa!
Fizemos uma POC que envolve um front-end usando mongoDB e SCALA realizando chamadas Restful ao elasticSearch (o próximo artigo será sobre como esse front-end foi construído).
A base de dados em elasticSearch é previamente populada por um processo batch que executa a engine de recomendação em Python com o framework de recomendação CRAB.
A figura abaixo exibe um draft da arquitetura:

O que é o CRAB?
CRAB é projeto OpenSource feito em python que utiliza pacotes científicos (Scipy, Numpy e Matplotlib) com a finalidade de ser uma alternativa de framework para desenvolvimento de sistemas de recomendações colaborativos.
Por que escolhemos o CRAB?
O ponto forte do framework claramente é a facilidade de implementação do sistema que os algoritmos científicos que realizam todo o trabalho “pesado” de criação dos modelos, e predições baseada me matriz de recomendação. Além disso, vale destacas a abordagem escalável que o projeto possui, tornando-o uma boa opção para a realização da POC. No entanto nem tudo é perfeito, infelizmente o projeto encontra-se sem atualizações em seu repositório web, dessa forma exige do programador a expertise de adaptar as atualizações das bibliotecas cientificas manualmente.
Você pode baixar o projeto (aqui) e executá-lo em uma IDE Python (usei o PyCharm). Com o projeto montado, deve-se estudar a estrutura e organização do framework para localizar o diretório que contem os datasets utilizados (scikits\crab\datasets\data), após analisar/alterar a fonte de dados, crie seu “.py” principal que será responsável por executar as chamadas da Biblioteca CRAB. Um exemplo do arquivo pode ser visto abaixo:
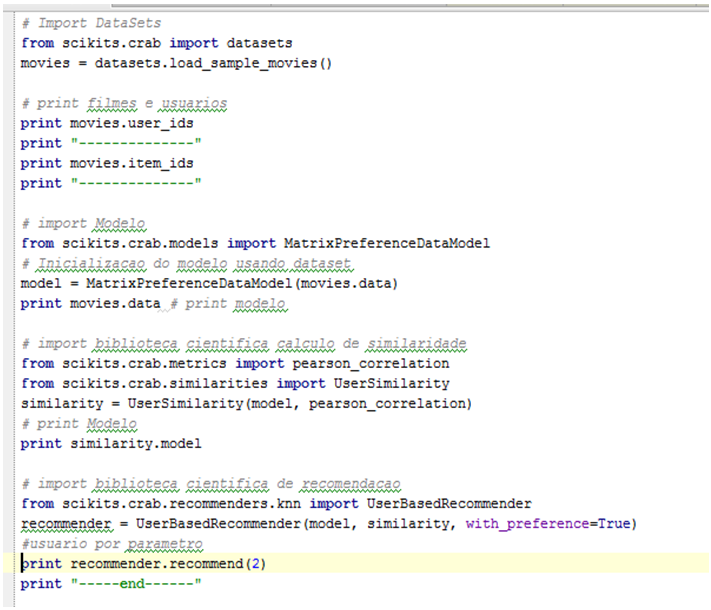
Esse simples código é capaz de executar a chamada dos métodos que fazem todo o trabalho científico de recomendação, e então teríamos o resultado:
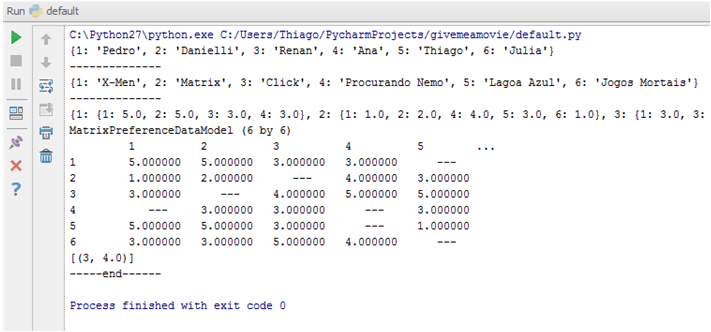
A partir desse momento, podemos criar um serviço batch que realiza a chamada do nosso código, passando por parâmetro os usuários que devem ser analisados, e recebendo como output as recomendações para os mesmos.
Conclusão
Nos últimos anos, os sistemas de recomendações personalizadas têm se tornado uma ferramenta bastante útil para as lojas virtuais que necessitam de auxílio inteligente na busca por itens relevantes em meio ao enorme volume de informações disponíveis. O principal intuito ao se recomendar um produto é garantir o sucesso na recomendação aos seus clientes, e por consequência aumentar o volume de vendas.
Porém, antes de poder gerar recomendações de boa qualidade, o sistema precisa identificar as necessidades específicas de cada usuário, e se deparar com desafios como:
- Itens com nomes diferentes, porém significados iguais ou similares, levando a recomendar itens já adquiridos
- Ou o problema da “ovelha negra” onde o usuário não se encaixa em nenhum grupo, e só é possível fazer recomendações baseadas em conteúdo.
O método de Filtragem Colaborativa se destaca por seus resultados, e nesse meio, uma boa prática sempre é pensar na escalabilidade, afinal imagine uma base com 10 milhões de recomendações, por 1 milhão de usuários e 1 milhão de itens, acredite você terá tempo pra ver muitos filmes quanto acontece o processamento [single-node] dessa massa de informação, Além disso outro ponto importante é a facilidade de implementação, por isso a utilização de Python e bibliotecas cientificas podem ser uma ótima opção para a criação de sistemas de recomendação de forma precisa, escalável e inteligente.
Referências
http://en.wikipedia.org/wiki/ Collaborative_filtering
http://en.wikipedia.org/wiki/ Slope_One
http://en.wikipedia.org/wiki/ Cluster_Analysis
http :/ / en.wikipedia.org / wiki / Music_Genome_Project
http :/ / en.wikipedia.org / wiki / Recommender_system
http :/ / files.grouplens.org / papers / www10_sarwar.pdf
http :/ / www.cs.carleton.edu/cs_comps/0607/recommend/recommender/ itembased.html
http://www.dataiku.com/blog/2012/09/10/a-simple-recommendation-engine-implemented-in-different- languages.html
http :/ / www.nexttovisit.com /
http://bhagyas.github.io/spring-mahout-demo /
http://1.bp.blogspot.com/-ME24ePzpzIM/UQLWTwurfXI/AAAAAAAAANw/W3EETIroA80/s1600/ drop_shadows_background.png
{kind=link}