POV: A streaming/communication platform for the data mesh
In 2021, a rich set of data is the soil that empowers the business of all the Internet Giants (GAFAM, NATU, …).
Meanwhile, traditional companies are striving to remain competitive. Therefore, the mandatory acceleration of their business goes through a massive digitalization of their operations and assets.
Amongst the most valuable digital assets are the data. Big data’s promises are attractive. However, the “data” organizational unit is commonly separated from the core business in the wild. Even if many of those departments provide much effort to bring value to the organization, the overall business plan usually looks like this:
- step 1: collect
- step2: ?
- step3: profit

In this article, I will present a way to address step 2 of the plan. I will borrow concepts from the data-mesh paradigm as a model.
At the end of the article, you will have an idea that the links between the federated computational governance, the platform’s role, and the data product are crucial to profit from the data-mesh paradigm.
I will eventually illustrate them with a trivial technological implementation (with some code) - learning by doing!
Disclaimer: the implementation described here is a skeleton acting as a proof-of-value. As usual, adapt is better than adopt, and the reader should adjust most of the concepts here depending on the business context and building constraints. Nevertheless, the code present in this article is working, and the code snippets you will find along the explanation are using tests that could be understandable to most developers.
Previously in the world of Data
As explained in the introduction, much effort has been put into technological solutions to address big data issues and extract their value.
If we apply the adage “during a gold rush, sell shovels” to our context, the shovel retailers lead to various technological implementations such as data-warehouse, data-lake, and lately data-factories. But, even if it may sound like the right thing to do, those solutions share a common problem: they can hardly scale.
To manage this rush by addressing the shovels ecosystem issues while focusing on the gold (the data), Zhamak Dehghani introduced a paradigm shift called data mesh. The data-mesh is a way to exploit the data in a distributed manner. In essence, the paradigm shift is:
- focusing on the distribution of ownership and technological architecture;
- placing the data at the center of each distributed component.
All the rest of the data mesh is about solving the problems that come with that.
The pillars of the data mesh in a glimpse
Four pillars are supporting a data mesh:
- A federated computational governance.
- A domain-driven data ownership architecture.
- Data as product thinking.
- A self-serve infrastructure platform.
Let’s now go through an extract of concepts that we want to illustrate with our proof-of-value.
Data as product
The first pillar we need to define is to treat the data as a product. To empower the business, the owners must think of the data as a product. To bring the maximum value to the company, the data-as-product must be:
- Discoverable: Declared on a catalog and a search engine
- Understandable: provide semantic (meaning), syntactic (topology), and usage description (behavior)
- Addressable: must participate in a global ecosystem with a unique address that helps its users to find and access it programmatically
- Secure: Be accessed securely with global policies (role-based-access, purpose-based-access-control, GDPR, Info security, data sovereignty …)
- Interoperable: Be able to reuse, correlate and stitch them together across namespaces for new use cases
- Trustworthy – Truthful: Provided data provenance and lineage and data quality from the owner
- Natively Accessible: Provided multimodal access like Web services, events of file interfaces
- Valuable on its own: Designed to higher insights when combined and correlated
- Committed to SLOs: Must respect expected service levels in terms of data availability and quality.
Federated computed governance
The original article describing the data mesh principles defines federated computational governance as
a model that embraces decentralization and domain self-sovereignty, interoperability through global standardization, a dynamic topology and most importantly automated execution of decisions by the platform.
In this article, we will insist on the automated execution of decisions by the platform. In essence, we will describe and implement a set of platform features, and we will point out why they are mandatory in such an organization.
Self-serve data infrastructure as a platform
Wikipedia defines a digital platform as the environment in which a piece of software is executed.
In the present context, the platform will act as a lever to the development and execution of the data products. On top of that, as explained in the last paragraph, it will also carry the role of a validator with regard to the decision made by the federated governance.
The platform is composed of different services and offers features that participate in the robustness of the mesh. Our implementation will focus on one of the features: the communication between the nodes and the eventing capability as a lever to data exploitation.
Data mesh representation
To oversimplify the idea of the mesh for the rest of the article, we will represent the network like this:
A set of autonomous products that provides values on their own (Profit) by collecting data and that are exposing their data to others to give a more significant value to the company:
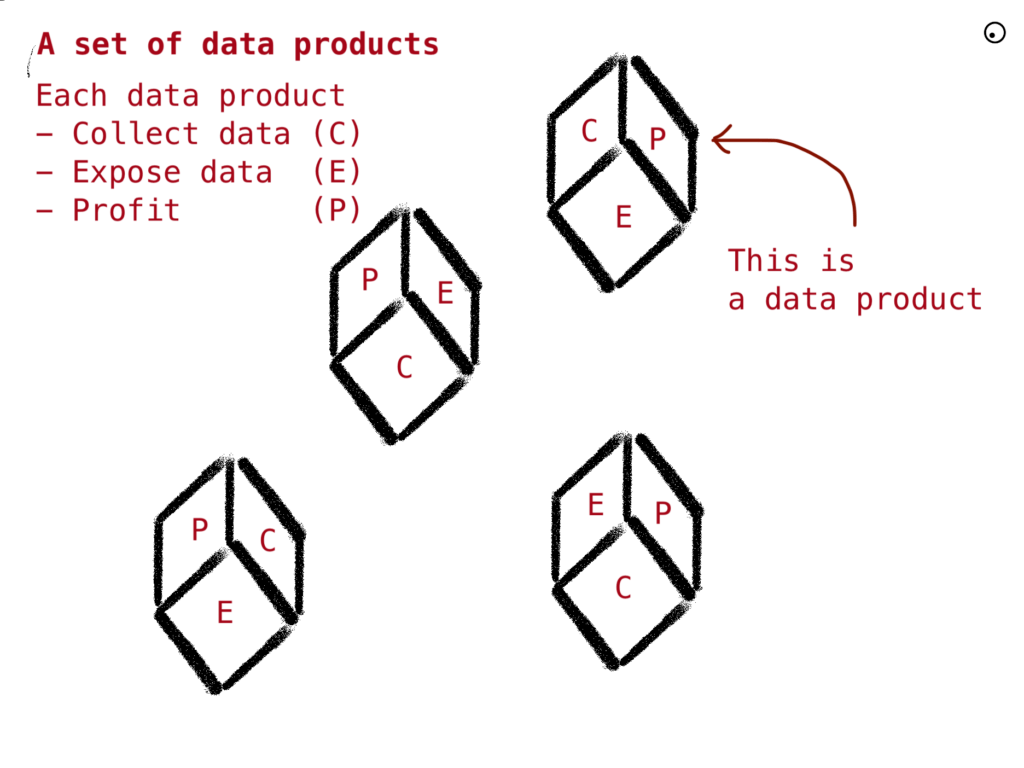
The fuel of each product is a set of data provided by grabbing data from the operational services and by other products via a set of communication channels. The sum is the mesh. The mesh will bring profit to the overall business.
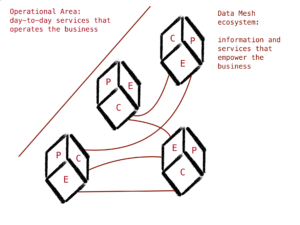
Mesh: a matter of communication
In the model we’ve exposed, communication is mandatory for the mesh to exist. Without communication, we end up with an independent set of nodes.
Managing communication is therefore essential to build products that are understandable, interoperable, and accessible. On top of that, a good communication network shall allow the discoverability of the products.
Let’s now see how to implement one of the many communication systems based on eventing that fulfills the prerequisites of the data mesh.
Modeling the communication
This section will introduce fundamental concepts that will help understand the technical implementation that will follow.
The basic model representing a communication system was defined in 1948 by Claude Shannon. Let’s borrow this representation and the explanation from the essay A mathematical theory of communication:
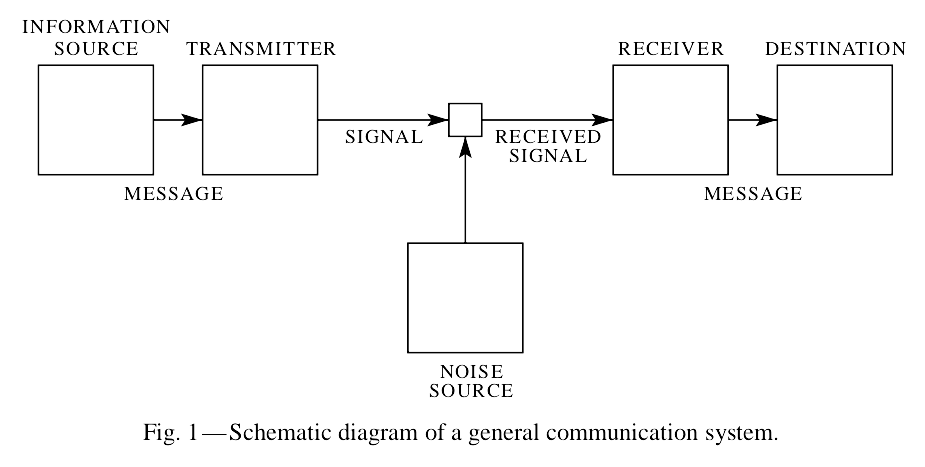
Let’s put aside the noise source and focus on the other elements:
Note: ignoring the noise source is equivalent to considering a noiseless channel, as described in part I of the original article. In our context, the model is applied to a set of components that operate on a layer that is barely sensitive to noise (applicative level).
- An information source that produces a message or sequence of messages to be communicated to the receiver terminal. In our case, the message is data to be transmitted to other nodes of the mesh.
- A transmitter that operates on the message in some way to produce a signal suitable for transmission over the channel.
- The channel is merely the medium used to transmit the signal from the transmitter to the receiver.
- The receiver ordinarily performs the inverse operation of that done by the transmitter, reconstructing the message from the signal.
- The destination is the thing for whom the message is intended.
Roughly, standardizing the communication network in the mesh will lead to this representation:
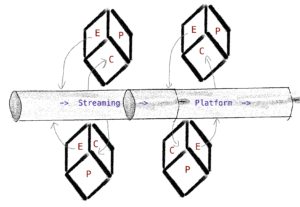
Application to our mesh
From a communication model to a processing data pipeline
Instantiating this communication model to the data world is roughly equivalent to describing a shallow data processing pipeline (more on this later, in the implementation). Let’s explain it step by step.
Making the message understandable: the semantic
The source and the destination must agree on the semantic of the message. In computer science, this goal is achieved by sharing a schema and definitions of the information. For example, in English, we can express a message like this:
The message contains the identity of a person. A person’s identity is composed of his first name starting with a capital letter, his last name beginning with a capital letter, and optionally his age, which is a number less than 130.
On top of that, the “federated governance” role is to impose a common language to express the messages and impose a shared syntax for Schema definitions. Actually, to be programmatically addressable, the product must expose its definitions and schemas in a computer-friendly language, e.g., JSON-Schema, Protobuf, or CUE. This is why the data mesh calls it a “federated computational governance.”
For example, here is the definition of the schema in CUE language:
<br><br> 1<br> 2<br> 3<br> 4<br> 5<br> 6<br> 7<br> 8<br> 9<br>10<br>11<br>12<br>13<br>14<br><br> | <br>text<br>message: #Identity & {<br> first: "John"<br> Last: "Doe"<br> Age: 40<br>}<br><br>#Identity: {<br> // first name of the person<br> first: =~ "[A-Z].*"<br> // Last name of the person<br> Last: =~ "[A-Z].*"<br> // Age of the person<br> Age?: number & < 130<br>}<br><br> |
Note: More on the choice of the CUE language will come later in this article.
CUE’s tooling makes it easy for a computer to understand the syntax and facilitate the data validation (e.g., calling <br>cue vet identity<br> will validate the data against their definition; you can play with the example directly in the Cue playground. If you don’t have the tooling locally) Changing the Last name from <br>Doe<br> to <br>doe<br> or setting an age above 130 would result in an error. The validation prevents sending noise or garbage over the channel:
The validation prevents sending noise or garbage over the channel:
As a résumé, the role of the message emitter is to expose its semantic in a language defined by the “federated governance” and to emit a message that is syntactically and functionally coherent with the definition (as validated by the “federated computational governance”).
Creating a signal: the transmitter
Once we have transformed the information into an understandable message (this operation is usually called a marshaling process), we pass it to the transmitter to encode it into a signal and emit the data.
The role of the signal is to ensure that the information propagates safely over the communication channel. On top of that, the signal format should allow multiplexing to avoid cooking a spaghetti of channels in our mesh. _ Encapsulating the message into an envelope is a way to address the problem.
The envelope allows creating a shared structure. This structure handles metadata such as the emitter of the message, its type, its source, and so on.
Once again, it is the role of the “federated computational governance” to define the envelope format and standards. Cloudevents is one of those. It standardizes the exchange of messages between the cloud services.
As a résumé, the role of the transmitter is to transmit the message over the channel by encapsulating it into an event (aka marshaling the event). The event envelope is standardized by the governance. The transmitter is a capacity offered by a “self-serve infrastructure” (the data products should be autonomous to transmit some event)
Broadcasting the signal: the channel
The role of the channel is to store and expose the events to the receivers. Furthermore, the channel’s role is to validate that the message, once accepted, is delivered to the authorized and intended receivers. This will guarantee the security and trust of the whole infrastructure. It is not the role of the channel to analyze the message in any way. It is, therefore, independent of the type of messages (think about the telephone, you can speak English or French on the phone).
Trivial implementation: a streaming platform
Now we have all the concepts, let’s implement the self-serve communication infrastructure that will facilitate the development of the product while ensuring the rules of the federated computational governance.
First, let’s summarize the pipeline using the Unix pipe (<br>|<br>) symbol:
<br><br><br>1<br>2<br>3<br>4<br>5<br><br><br> | ``` shell // Send: collect_data |
To facilitate the development and maintenance of the mesh, the self-serve communication infrastructure (let’s call it a streaming platform) will provide those capabilities:
- validate_message: as said before, it is a must to ensure the data quality
- channel management
- event filtering, and more precisely, event routing
On top of that, it must provide a repository of data schemas (data catalog) to make the information addressable.
What we are building in a glimpse
We will build a product, part of a global platform; its purpose is to interconnect the mesh nodes and provide a standard way to expose the information. We will refer to what we are building as the streaming platform for the rest of the document.
A configuration language for the semantic
As explained before, the system should be generic enough to be loosely coupled with the semantic of the data.
Precisely, it should be the role of the data-products owner to express the schema and the business validation rules; We can therefore consider the validation and data cataloging capabilities as the configuration of a generic instance of the streaming platform.
Note: The Site Reliability Engineering book defines a configuration as human-computer interface for modifying system behavior.
In our trivial implementation, we use the CUE language because it is accessible and concise in the definition.
Amongst its strengths, CUE:
- Allows data validation by design;
- data composition but no inheritance;
- holds a set of tooling to format, lint and validate the data and the schemas easily;
- Provides an API (in Go) to build a set of tools that we’ll use for the rest of this article.
Our streaming plateform is therefore a generic validation and message publishing interface configured with CUE.
Execution/Runtime
Once we have configured our streaming platform to handle and understand any kind of messages described in CUE, we need to provide an end-user interface that facilitates the ingestion, validation, and transmission of data.
CUE stands for Configure/Unify/Execute. This is a perfect resumé of what we are trying to achieve: we configure the platform to understand a definition of information; internally, the platform unifies the definition and the data and executes the validation.
This is what the command <br>cue vet<br> we’ve issued before does under the hood. But we may want to turn it into a service for ease of testing and robustness. This simple code snippet shows the power of the SDK: fewer than ten lines are required to validate data against a schema (including the functional constraints).
<br><br> 1<br> 2<br> 3<br> 4<br> 5<br> 6<br> 7<br> 8<br> 9<br>10<br>11<br>12<br>13<br>14<br>15<br><br> | <br>go<br>type DataProduct struct {<br> definition cue.Value<br> // ...<br>}<br><br>func (d *DataProduct) ExtractData(b []byte) (cue.Value, error) {<br> data := d.definition.Context().CompileBytes(b)<br> unified := d.definition.Unify(data)<br> opts := []cue.Option{<br> cue.Attributes(true),<br> cue.Definitions(true),<br> cue.Hidden(true),<br> }<br> return data, unified.Validate(opts...)<br>}<br><br> |
Note: It is beyond the scope of this article to detail the implementation of the services, but as a proof-of-concept, you can refer to this gist for a complete example with an HTTP handler; This gist also holds a functional test that shows different validation scenarios.
Eventing/Routing
So far, we’ve seen that it requires minimal effort to express a schema and validate the data at the entrance of the streaming platform.
Before submitting it to a communication channel (to be defined later), let’s ensure that we write a comprehensible envelope. We’ve expressed it already: interoperability is key to the success of the mesh. Using a standard envelope will guarantee that the message can move out of the platform’s ecosystem.
Cloudvents is a standard format of the Cloud-native Computing Foundation (CNCF) that addresses this need. The specification of Cloudevents standardizes the structure of the envelope by introducing concepts such as the source of the event, the type of the event, or its unique identifier (helpful in tracing and telemetry).
The Federated Governance role ensures that the declaration of the sources and the event types are registered correctly in a catalog and widely accessible to any data consumer. Our streaming data platform will encapsulate the data into a Cloudevent.
Example of event serialized in JSON:
<br><br>1<br>2<br>3<br>4<br>5<br>6<br>7<br>8<br><br> | <br>json<br>{<br> "specversion": "1.0",<br> "id": "1234-4567-8910-1234-5678",<br> "source": "MySource",<br> "type": "MySource:newPerson",<br> "datacontenttype": "application/json",<br> "data_base64": "MyMessageInJSONEncodedInBase64=="<br>}<br><br> |
Of course, the platform can handle the encoding of the event easily.
Once again, it is beyond the scope of this article to show how to do it, but this gist contains all the required information a reader may need to go deeper into the implementation.
The channel
Now we have a signal, it is time to propagate it over a communication channel.
The channel is a medium of communication. Therefore, in Shannon’s model, it can be anything that can act as a buffer between the emitter and the receiver. But in our context, we may add some required features:
- We should allow multiple receivers to get a message
- The communication can be asynchronous
- The channel must be tolerant and robust to avoid any loss of messages
For robustness and efficiency, a solution like Kafka is probably a safe choice, but to move fast, managed solutions such as Google PubSub could do the trick. As we address the validation of the data at the channel’s entry to avoid the garbage in/garbage out, there is no need for an intrinsic validation mechanism. Kafka is part of the infrastructure (in the definition of a hexagonal architecture); keeping the validation outside of Kafka ensures strong infrastructure segregation and its independence to the streaming platform product.
Note: We won’t dig into partitioning problems in this article, nor will we use the partitioning extension of the Cloudevents specification. To continue the coding journey, you can refer to this implementation of a Kafka connect that publishes a “Cloudevent” into a topic.
The catalog/openAPI
An essential part of our journey is the ability of the consumer to extract and understand the data from the signal.
A solution is to expose the schema definition in CUE; an alternative is to provide a standard OpenAPI definition of the schema. This last option has the significant advantage of being compatible with most development languages and frameworks. Therefore, coding a data-consumer will become straightforward, and the time-to-market will increase.
CUE’s toolkit and SDK make it easy to convert a set of definitions into an OpenAPI v3 specification. The command-line utility from the standard CUE toolkit can perform such a job:
<br><br> 1<br> 2<br> 3<br> 4<br> 5<br> 6<br> 7<br> 8<br> 9<br>10<br>11<br>12<br>13<br>14<br>15<br>16<br>17<br>18<br>19<br>20<br>21<br>22<br>23<br>24<br>25<br>26<br>27<br>28<br>29<br>30<br>31<br>32<br>33<br>34<br>35<br>36<br>37<br>38<br>39<br>40<br>41<br>42<br>43<br>44<br>45<br>46<br>47<br>48<br><br> | ``` json ❯ ( cat << EOF #Identity: { // first name of the person first: =~ "[A-Z].*" // Last name of the person Last: =~ "[A-Z].*" // Age of the person Age?: number & < 130 } EOF ) |
And for our POC, we will once again use the SDK as exposed in this gist.
Wrap-up / Gluing all together.
Gluing all the code we’ve walked through allows generating an elementary web server that:
- Reads and understands the data schema as expressed by the product owner;
- Exposes an open API version of the Schema
- Listen to an endpoint for data
- Validates the data
- Generate a Cloudevent format
- Sends it over the wire
All of this in 100 lines of code that you can find here.
You can feed the system with this definition:
<br><br>1<br>2<br>3<br>4<br>5<br>6<br>7<br>8<br><br> | <br>text<br>#Identity: {<br> // first name of the person<br> first: =~ "[A-Z].*"<br> // Last name of the person<br> Last: =~ "[A-Z].*"<br> // Age of the person<br> Age?: number & < 130<br>}<br><br> |
Then query the server for the OpenAPI:
<br><br> 1<br> 2<br> 3<br> 4<br> 5<br> 6<br> 7<br> 8<br> 9<br>10<br>11<br>12<br><br> | <br>shell<br>curl http://localhost:8181/openapi<br>{<br> "openapi": "3.0.0",<br> "info": {<br> "title": "Generated by cue.",<br> "version": "no version"<br> },<br> "paths": {},<br> "components": {<br> "schemas": {<br> ...<br>}<br><br> |
Or send good data …
<br><br>1<br>2<br><br> | <br>shell<br>❯ curl -XPOST -d'{"first": "John","Last": "Doe","Age": 40}' http://localhost:8181/<br>ok<br><br> |
… or bad data …
<br><br>1<br>2<br><br> | <br>shell<br>❯ curl -XPOST -d'{"first": "John","Last": "Doe","Age": 140}' http://localhost:8181/<br>#Identity.Age: invalid value 140 (out of bound <130)<br><br> |
… and, if you have a Kafka broker running on localhost:9092, it will send the message over the wire:
<br><br>1<br>2<br><br> | <br>shell<br>❯ curl -XPOST -d'{"first": "John","Last": "Doe","Age": 40}' http://localhost:8181/<br>sent to the channel ok<br><br> |
Last note about performances
The code we’ve generated is, obviously, not production-ready; nevertheless, the core is based on CUE, and we can legitimately wonder if it will scale. CUE is designed to be O(n), and this simple benchmark shows that the code can ingest, validate, encode and send thousands of events into a local Kafka topic in 2.5 seconds:
<br><br>1<br>2<br>3<br>4<br>5<br>6<br>7<br>8<br><br> | <br>shell<br>> go test -run=NONE -bench=. -benchmem<br>goos: darwin<br>goarch: amd64<br>pkg: owulveryck.github.io/test1<br>cpu: Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz<br>BenchmarkRun-12 1024 2135823 ns/op 55261 B/op 537 allocs/op<br>PASS<br>ok owulveryck.github.io/test1 2.503s<br><br> |
Conclusion
Through this article, we’ve built a complete communication and streaming mechanism to interconnect the nodes of a mesh.
This streaming mechanism is part of a global platform and will be operated by a platform team (as defined by the book team topologies from Matthew Skelton and Manuel Pais).
The users of this capability are different stream-aligned teams (in the context of team topologies, a stream-aligned team is organized around the flow of work and can deliver value directly to the customer or end user)
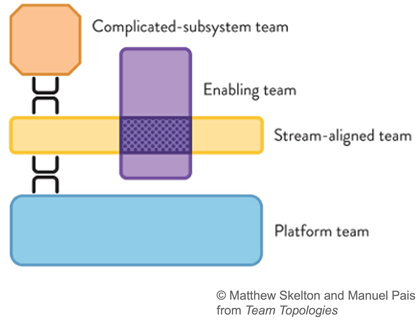
Within the stream-aligned team, the data-product-owner can use the CUE language to describe its data semantic and constraints; The developers will use the validation process to feed the stream with data.
The consumers of data will exploit the data cataloging capability and build other products thanks to the data they will find on the wire.
Meanwhile, the Cloudevents format ensures that the signal can be propagated through the infrastructure in an agnostic way. It also opens the possibility to build data-product on a pure serverless architecture, but let’s keep that warm for another article.
Final note: this article presents a single way to expose data through event streaming. To be complete, a “pull” mechanism should be defined as a standard to fetch the information via, for example, a set of REST APIs.