Pourquoi les entreprises ne vont pas toujours en production facilement ?
Dans nos missions chez OCTO, nous souhaitons mettre en production le plus tôt possible pour dérisquer la production, tester les modes opératoires mais aussi tester l’application dans des conditions réelles pour récolter des informations précieuses des utilisateurs finaux du système dans sa globalité qui permettront d’améliorer l’application.
Malgré l'avènement de la culture DevOps, les pratiques itératives et incrémentales, la volonté de vouloir livrer de nouvelles fonctionnalités, de nouveau produits dans un marché de plus en plus compétitifs, les entreprises éprouvent souvent une certaine réticence à déployer des changements ou des nouvelles solutions en production, principalement en raison de l'impact potentiel que cela pourrait avoir sur leurs opérations et leur réputation mais aussi pour des problématiques réglementaires. Dans cet article nous allons décrire les principales raisons pour lesquelles le déploiement en production suscite cette crainte. La liste ci-dessous ne se veut pas exhaustive.
Les 3 risques majeures
Risques de dysfonctionnements ou d'interruptions
Un des premiers sujets qui revient chez nos clients est la stabilité et la maîtrise du système. Introduire un changement, un nouveau produit c’est introduire un risque :
- Impact sur la disponibilité : Un déploiement en environnement de production peut entraîner des dysfonctionnements, voire des interruptions de service. Dans de nombreux secteurs d’activité, la disponibilité des systèmes d’information est un facteur critique : chaque période d’indisponibilité, même de courte durée, peut engendrer des pertes financières significatives et porter atteinte à l’image et à la crédibilité de l’entreprise auprès de ses clients et partenaires.
- Erreurs techniques : Malgré la mise en place de phases de tests approfondies, certaines anomalies logicielles ou techniques peuvent n’apparaître qu’en environnement de production, lorsque le système est confronté à des conditions d’utilisation réelles et à des volumes de charge représentatifs. Ces erreurs peuvent résulter de défauts de code, de configurations inadaptées ou d’interactions imprévues entre composants. La crainte que de telles anomalies ne soient pas identifiées en amont constitue un frein important aux mises en production et justifie la nécessité de processus de déploiement particulièrement rigoureux.
Le 18 novembre 2025, un changement de configuration a entraîné une panne partielle du réseau Cloudflare, affectant la capacité à router le trafic pour de nombreux sites et applications en ligne. Des erreurs HTTP 500 visibles par des millions d’utilisateurs et indisponibilité temporaire de services connectés. L’impact en production est majeur : arrêt ou dysfonctionnement de services web critiques (moteurs de recherche, plateformes en ligne, portails clients).
Risque de perturbation des utilisateurs
- Impact sur l'expérience utilisateur : Le déploiement continu, bien qu’il vise à accélérer la mise à disposition de nouvelles fonctionnalités, peut, dans certains contextes, affecter négativement l’expérience utilisateur. Des évolutions fréquentes des fonctionnalités ou des modifications répétées de l’interface utilisateur sont susceptibles de perturber les utilisateurs finaux, en particulier lorsqu’elles ne sont pas suffisamment accompagnées ou anticipées. Il apparaît donc essentiel que les processus de déploiement soient rigoureusement encadrés afin de prévenir les régressions fonctionnelles, les incohérences d’interface ou les interruptions de service susceptibles de nuire à l’usage et à la satisfaction des utilisateurs.
- Problèmes de rollback en cas de défaillance : La capacité à revenir rapidement à un état stable du système en cas d’incident constitue un élément clé de la fiabilité des déploiements en production. Toutefois, dans des environnements techniques complexes, caractérisés par des architectures distribuées ou fortement interconnectées, la mise en œuvre de mécanismes de rollback efficaces peut s’avérer particulièrement délicate. En cas d’échec du déploiement continu, l’organisation peut être contrainte d’engager des actions correctives en urgence afin de rétablir le service, avec un risque accru de perturbation pour les utilisateurs et de dégradation de la qualité de service.
L’image d’une entreprise et l’adoption par ses utilisateurs sont cruciales. Un des exemples est la nouvelle application de l’entreprise de hifi SONOS qui a été rejetée par une majorité des clients suites aux anomalies constatés et à la suppression de fonctionnalités majeures dans la nouvelle version. L’entreprise à dû en urgence réactiver son ancienne version et garder la nouvelle. Elle a par ailleurs dû reporter des nouveaux produits pour se concentrer sur la correction et l’amélioration de sa nouvelle application. Elle a mobilisé une partie des équipes de l’entreprise à corriger la nouvelle version afin d'apporter des améliorations significatives aux utilisateurs. Revenir à une situation stable à non seulement coûté des millions de dollars à la société, mais son image a totalement été dégradée et les utilisateurs ce sont pour une partie détournée de la marque.
Coût élevé des erreurs
- Conséquences financières : Une erreur survenant en environnement de production est susceptible d’engendrer des répercussions financières significatives pour l’entreprise. Celles-ci peuvent prendre la forme de remboursements aux clients, de pénalités contractuelles, de pertes de revenus ou encore d’une diminution de la base clientèle. Dans les secteurs particulièrement concurrentiels ou fortement régulés, l’échec d’un déploiement peut entraîner des impacts financiers d’autant plus sévères, compromettant non seulement la rentabilité à court terme, mais également la position concurrentielle et la pérennité de l’organisation.
Le scandale impliquant Volkswagen reposait en grande partie sur l’utilisation d’un logiciel non conforme aux réglementations environnementales. Les conséquences financières ont été majeures, incluant des amendes, des pénalités réglementaires et des compensations aux clients, pour un montant total dépassant plusieurs dizaines de milliards d’euros. Cet exemple illustre le risque financier accru lié aux défaillances logicielles dans les secteurs fortement réglementés.
Les autres risques à ne pas sous estimer
La législation
Conformité réglementaire et légale
- Régulations strictes : Certaines industries, comme la finance, la santé ou l'énergie, sont fortement régulées. Des erreurs en production peuvent entraîner des violations de régulations légales ou des amendes. Le respect des normes de sécurité, de confidentialité et de conformité doit être assuré à tout moment, ce qui ajoute un niveau supplémentaire de complexité et de prudence dans le déploiement.
- Audit et traçabilité : En fonction des secteurs d’activité, les entreprises doivent respecter des processus d'audit rigoureux et garantir la traçabilité des modifications. Cela peut entraîner des contrôles supplémentaires avant qu'un déploiement en production soit autorisé.
Google a été sanctionné en 2024 par une autorité européenne de protection des données pour défauts dans la gestion des consentements de cookies, en violation du RGPD. Une amende de 150 millions d’euros lui a été réclamée par l'Union Européenne. L’’entreprise a dû revoir profondément ses systèmes de gestion des cookies et ses flux en production pour respecter les obligations de consentement, avec des modifications techniques et des tests supplémentaires avant redéploiement.
Les tests
Manque de tests automatisés fiables
- Tests insuffisants ou mal conçus : Le déploiement continu repose en grande partie sur l’efficacité des dispositifs de tests automatisés, notamment les tests unitaires, d’intégration et de performance. Lorsque ces tests sont insuffisamment conçus, présentent une couverture limitée des cas d’usage ou ne reflètent pas fidèlement les conditions réelles d’exploitation, le risque d’introduction d’anomalies en environnement de production s’en trouve significativement accru. L’absence de tests automatisés fiables et représentatifs constitue ainsi un frein majeur à l’adoption du déploiement continu, dans la mesure où elle compromet la confiance des équipes dans la stabilité et la qualité des mises en production.
Un des exemples les plus marquants est celui de CrowdStrike, une grande entreprise de cybersécurité. En 2024, une mise à jour logicielle contenant un bug non détecté par les validations internes (dont la suite de tests) a été déployée dans des millions de systèmes Windows. Résultat : environ 8,5 millions de machines ont “crashé”, provoquant des interruptions massives de services pour des entreprises, infrastructures critiques et services publics. Ce bug a causé des pertes financières potentielles pour plusieurs grandes entreprises et déclenché des enquêtes réglementaires. L’entreprise à dû revoir les tests de validation complète des changements avant déploiement en production.
L’architecture, l’interdépendance des systèmes la multiplicité des environnements
Complexité des systèmes et des architectures
- Systèmes monolithiques et applications héritées : Dans les organisations reposant sur des architectures monolithiques ou des applications héritées (legacy systems), la mise en œuvre du déploiement continu s’avère particulièrement complexe. Ces systèmes, souvent caractérisés par un fort couplage entre leurs composants et une architecture peu flexible, limitent la capacité à déployer des évolutions de manière fréquente et isolée. La mise en place d’une livraison continue dans ce contexte nécessite généralement une refonte architecturale visant à accroître la modularité, le découplage et la maintenabilité des applications.
- Dépendances complexes : Les systèmes d’information interconnectés reposent sur un ensemble de dépendances internes et externes dont la gestion peut s’avérer délicate. Dans le cadre du déploiement continu, une maîtrise rigoureuse des versions, des interfaces et des dépendances est indispensable afin de prévenir les conflits, les incompatibilités et les régressions fonctionnelles. Une gestion inadéquate de ces dépendances peut compromettre la stabilité des systèmes après chaque mise à jour et constitue, de ce fait, un obstacle majeur à l’automatisation et à la fiabilité des mises en production.
La panne informatique mondiale liée à une mise à jour défectueuse du logiciel de sécurité CrowdStrike a provoqué l’instabilité ou le crash de millions de systèmes Windows utilisés par des entreprises du monde entier. Ce problème unique s’est propagé à des infrastructures dépendantes (systèmes de réservation, de gestion de bagages, etc.), conduisant à l’annulation de plus de 7 000 vols chez Delta Air Lines et à des perturbations dans de nombreux autres secteurs (hôpitaux, transports, services publics).
Multiplicité des environnements
- La gestion de plusieurs environnements : Elle accroît la complexité opérationnelle. Chaque environnement possède ses propres configurations, dépendances, jeux de données et contraintes techniques. Les écarts de configuration entre ces environnements peuvent entraîner des situations où une application fonctionne correctement en test ou en préproduction, mais présente des dysfonctionnements en production
Mehdi Houacime consultant OCTO explique dans son article à travers le vécu d’une mission en commun Environnements éphémères anté-production : arrêtez de faire du "pet" 🐈, faites du "cattle" 🐄que la multiplicité des environnements rendait complexe l’activité des équipes OPS pour maintenir ses environnements et fluidifier les mise en production. La fréquence de déploiement était de 100 jours. C’est à dire que presque 3 mois s’écoulaient en moyenne entre le moment où le Product Owner donnait le top départ pour réaliser une livraison logicielle et le moment où la nouvelle version du produit était utilisable en production.
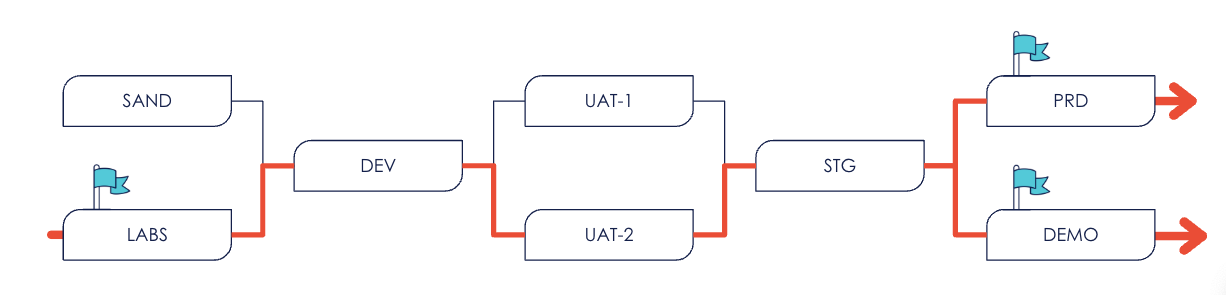
Parcours pour réaliser une release du produit 🏃
La sécurité
Problèmes de sécurité
- Risque de vulnérabilités introduites en production : Le déploiement continu repose sur un flux fréquent et automatisé de modifications en environnement de production. En l’absence de mécanismes de contrôle et de validation adéquats, cette dynamique peut favoriser l’introduction de vulnérabilités de sécurité au sein des systèmes opérationnels. Chaque modification logicielle ou configurationnelle doit ainsi faire l’objet d’une analyse rigoureuse afin de prévenir toute compromission de la sécurité des environnements de production. La survenue de failles de sécurité peut exposer des données sensibles ou critiques, porter atteinte à la réputation de l’organisation et entraîner des conséquences juridiques et réglementaires significatives.
En septembre 2025, le constructeur automobile Jaguar Land Rover (JLR) a subi une cyberattaque majeure qui a obligé l’entreprise à arrêter temporairement ses chaînes de montage dans plusieurs pays. La production a été interrompue pendant plusieurs semaines, avec des milliers d’employés mis au chômage technique et des pertes potentielles estimées à plus d’un milliard de livres pour le Royaume‑Uni et des effets en cascade sur les fournisseurs et partenaires du secteur.
La stratégie de déploiement
Problèmes de planification et de gestion des risques
- Absence de stratégie de déploiement : L’absence d’une stratégie de déploiement clairement définie, incluant un plan détaillé de gestion des risques et des mécanismes de repli en cas d’échec, peut engendrer des imprévus opérationnels et des retards significatifs lors des mises en production. Afin de limiter les risques associés aux changements, les organisations sont généralement amenées à planifier des déploiements progressifs ou réalisés par étapes, permettant une meilleure maîtrise de l’impact des évolutions sur les systèmes existants.
- Plan de secours insuffisant : À la suite d’un déploiement défaillant, la capacité à restaurer rapidement un état stable du système constitue un facteur déterminant pour la continuité de service. L’absence ou l’insuffisance de procédures de reprise et de remédiation peut conduire à des interruptions prolongées, voire à des défaillances critiques des systèmes. La mise en place de plans de secours robustes apparaît ainsi indispensable pour assurer la résilience des environnements de production et réduire les conséquences des incidents post-déploiement.
Le problème principal identifié par la société CrowdStrike après l’incident était le manque d’un déploiement progressif ou « canary » pour limiter l’impact potentiel de la mise à jour avant un déploiement sur l’intégralité des systèmes. À la suite de cet incident, CrowdStrike a indiqué vouloir adopter des stratégies de déploiement échelonné pour réduire le risque de défaillances globales lors de prochaines mises à jour.
L’organisation et l’humain
Résistance au changement et culture organisationnelle
- Culture devops : La mise en œuvre du déploiement continu repose sur une culture DevOps consolidée, favorisant la collaboration étroite entre les équipes de développement et d’exploitation. Dans les organisations où les silos fonctionnels persistent ou où les pratiques de travail sont rigides, cette approche peut être freinée par des résistances au changement. Par ailleurs, le déploiement en production mobilise des ressources humaines et techniques variées ; une insuffisance de personnel qualifié ou une pénurie de compétences spécifiques peut retarder les mises en production. L’engagement des parties prenantes à tous les niveaux de l’organisation est également déterminant : l’absence de soutien managériale, ainsi qu’une formation inadéquate des utilisateurs finaux, peuvent compromettre l’adoption effective des outils et des processus associés, et accroître le risque d’erreurs post-déploiement.
Problèmes de coordination entre équipes
- Problèmes de coordination et charge opérationnelle dans le déploiement continu : La mise en œuvre du déploiement continu requiert une coordination étroite entre les équipes de développement, de tests, d’intégration, de qualité et d’exploitation. Des processus de communication insuffisants ou un manque d’alignement organisationnel peuvent générer des problèmes de synchronisation et accroître le risque d’erreurs en production. L’intégration de tests utilisateurs, notamment dans le cadre de logiciels complexes, constitue un défi supplémentaire lorsqu’ils ne peuvent être entièrement automatisés, compliquant la fluidité des déploiements. Par ailleurs, le déploiement continu impose une charge opérationnelle accrue : la surveillance en temps réel des systèmes et la gestion rapide des incidents deviennent plus complexes du fait de la fréquence et de l’enchaînement des modifications. Ces contraintes organisationnelles et opérationnelles représentent des obstacles significatifs à l’efficacité et à la fiabilité des déploiements continus.
L’incertitude
La crainte de l’inconnu
- Incertitude et préparation face au déploiement de nouvelles technologies : Le déploiement de technologies ou de processus inédits introduit systématiquement un degré d’incertitude, auquel les équipes de développement, de production et de gestion peuvent réagir par une appréhension légitime. Cette crainte est renforcée lorsque la préparation est perçue comme insuffisante ou que les risques potentiels n’ont pas été pleinement anticipés, soulignant l’importance d’une planification rigoureuse et d’une gestion proactive du changement pour réduire l’impact des résistances organisationnelles.
Conclusion
La réticence aux mises en production régulières est souvent liée à une combinaison de facteurs : opérationnels, techniques, humains et financiers. Avec l'avènement de l’agile, du DevOps, des stratégies de déploiement progressif, les entreprises ont peu à peu pris conscience de l’importance de déployer de façon plus fréquente leurs applications. Toutes les entreprises n’ont pas vocation à le faire car elles sont soumises à des contraintes réglementaires et sécuritaires qui ne leur permettent pas de le réaliser.
Si l’on comprend mieux les thèmes qui freinent les entreprises à aller en production voici quelques exemples qui vous présente l’intérêt d’embrasser cette pratique :
- Positionner votre delivery à un haut niveau de performance pour que les livraisons soient une question d’opportunités business et non de risques techniques.
Chercher le plus court chemin vers la production pour dérisquer les hypothèses business
- Dédramatiser la mise en production pour pouvoir livrer quand on le souhaite et sans risque
- Mettre en place un collectif unique responsabilisé sur la conception, la réalisation et l’exploitation
- Privilégier la rapidité d’exécution pour agir en fonction des retours réels collectés en production
Références
Livres
Accelerate: The Science Behind Devops: Building and Scaling High Performing Technology Organizations par Nicole Forsgren, Jez Humble et Gene Kim - Ce livre présente des recherches sur les pratiques qui améliorent la performance des équipes de développement, incluant des éléments du "shift right".
Domain-Driven Design: Tackling Complexity in the Heart of Software par Eric Evans - Ce livre propose une approche systématique de la conception orientée domaine, en présentant un ensemble complet de meilleures pratiques de conception, de techniques basées sur l'expérience et de principes fondamentaux qui facilitent le développement de projets logiciels confrontés à des domaines complexes.
Team topologies : par Matthew Skelton et Manual Pais - Ce livre est un modèle pratique, adaptatif et progressif de conception organisationnelle et d'interaction d'équipe basé sur quatre types fondamentaux d'équipe et trois modèles d'interaction d'équipe.
Data Mesh: Delivering Data-Driven Value at Scale par Zhamak Dehghani - Ce livre traite les données comme un produit, considère les domaines comme une préoccupation principale, applique les principes de la plateforme pour créer une infrastructure de données en libre-service et introduit un modèle pour fédérer la gouvernance des données.
Introducing MLOps: How to Scale Machine Learning in the Enterprise par Mark Treveli et la Dataiku Team: Ce livre présente les concepts clés de MLOps afin d'aider les data scientists et les développeurs non seulement à mettre en oeuvre les modèles de ML pour conduire des changements réels dans l'entreprise, mais aussi à maintenir et à améliorer ces modèles au fil du temps.
The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win par Gene Kim, Kevin Behr, et George Spafford – Ce livre propose un roman pédagogique sur la mise en place de pratiques DevOps, mettant en lumière l’importance des boucles de feedback rapides pour la productivité et la qualité des projets.
Why Small Releases are Better Than Big Bang Deployments : (Martin Fowler, Continuous Delivery) décrit comment les déploiements fréquents réduisent les risques et permettent de tester plus rapidement les hypothèses dans un environnement de production