Jeu de données : constituer, annoter et gérer efficacement vos datasets
Un premier briefing
Avant de commencer le grand plongeon, des définitions s’imposent :
- Jeu de données (ou dataset) : collection de données de même type, de préférence de même format et souvent accompagnées d'annotation
- Annotation : description du contenu de chacune des données d’un dataset. L’annotation des données est le processus d’étiquetage du contenu reconnaissable par un ordinateur. En fonction de la nature du problème, on indiquera le type de l’objet dans l’image, on peut également indiquer ses coordonnées ou d’autres attributs.
- Modèle de Machine Learning (ou apprentissage automatique): le résultat d’un algorithme permettant de reconnaître des motifs dans les données. On forme un modèle à partir d’un jeu de données et en lui appliquant un algorithme qui permet d’apprendre à partir de ces données. Il existe plusieurs méthodes d’apprentissage, supervisé ou non-supervisé (https://le-datascientist.fr/apprentissage-supervise-vs-non-supervise).
Pour quelles raisons doit-on constituer un dataset ? Pour créer un modèle de Machine Learning, le premier prérequis est d'avoir un dataset annoté. Sans donnée, il est impossible de créer ou de mesurer les performances d’un modèle d’apprentissage. Un modèle se construit selon les données que constitue un dataset, celui-ci doit se rapprocher au maximum des données que le modèle va traiter en production.
Pour illustrer cet article, nous allons utiliser un cas d’usage de Vision par Ordinateur (Computer Vision): une association de sauvegarde de l’environnement veut identifier des espèces marines présentes en Méditerranée. Ceci pourra être effectué grâce aux photos acquises par les plongeurs et en soumettant à une application les photos pour les analyser et visualiser les statistiques de chaque espèce. Pour une première version, ce cas d’usage se limitera aux 50 espèces les plus représentées de la Mer Méditerranée et à une tâche de classification de l’espèce en premier plan.

Exemples de photos de plongées acquises en Mer Méditerranée et leur annotation
Ce cas d’usage est un exemple qui sert à illustrer les principes énoncés dans cet article. Ces principes peuvent être généralisés à tout type de donnée : série temporelle, texte, audio, vidéo.
Pour répondre à ce cas d’usage, une des étapes initiales est donc de constituer un dataset. Comment créer et gérer cette collection de données, quelles en sont les limites et comment l’améliorer ? Autant de questions auxquelles cet article va tâcher de répondre.
Constituer et gérer son dataset
Un dataset correct pour une application de Computer Vision exige :
- un nombre d’images suffisant de toutes les catégories à identifier. Ce nombre est compliqué à définir et dépend de la complexité de la problématique.
- une description pertinente des images, soit la classe, soit la boîte englobante ou le masque des objets contenus dans l’image (l’annotation),
- un ensemble de données présentant une variété suffisante de conditions environnementales.
On décrit dans la suite des solutions répondant à ces exigences.
Récupérer des données à l’état Naturel
Internet permet maintenant d’accéder à un nombre important de données avec des API assez simples. Pour les images, il est possible d’en télécharger à partir de Google images. Pour les autres types de données, d’autres sources de données existent, par exemple Wikipédia ou Twitter pour le texte.
Dans le cadre de notre cas d’usage, des outils simples permettent de télécharger des images avec l’API Google. Le tutoriel suivant propose de faire son propre script en python : https://www.pyimagesearch.com/2017/12/04/how-to-create-a-deep-learning-dataset-using-google-images/.
Il est possible de passer aussi par le package python google-images-download. Ce package permet de télécharger selon des mots clés et des filtres les images issues de Google Image, avec la limite de 100 images par requête. De cette manière, le dataset peut être créé en quelques minutes. Cependant, le choix des mots-clés est crucial.

Exemples d'utilisation du package google-images-download pour constituer un dataset d'images
L’avantage de cette méthode est une annotation immédiate pour une tâche de classification d’images. Néanmoins, en procédant de cette manière, certaines images ne correspondent pas à la recherche de photos prises par des plongeurs. Il faudrait exclure les photos provenant de pêcheurs ou les photos sans arrière-plan. Il existe aussi de nombreuses images dupliquées. Il est nécessaire d’affiner les mots clés et les filtres pour essayer d'obtenir un dataset assez proche du sujet initial. Les droits des photos et leur source sont à prendre en compte, l’accès aux photos de Google Images est libre mais pour certaines leur utilisation ne l’est pas.
Cette solution, pourtant facile à mettre en place pour une tâche de classification d’images, apparaît vite limitée en termes de diversité et nécessite un travail important de nettoyage.
Il est très rarement conseillé de mettre en place ce type de dataset à cause des limites citées précédemment. Dans de rares cas, par exemple en réponse à un appel d’offre où les données client ne sont pas accessibles, cette méthode peut apporter une solution.
Utiliser un dataset de référence
La Data Science s’est démocratisée ces dernières années grâce à l’ouverture de milliers de datasets annotés pour des compétitions de Data Science. Un moteur de recherche existe: https://datasetsearch.research.google.com/. Certains de ces datasets sont devenus des références comme le dataset MNIST ou Imagenet. En effectuant une recherche rapide sur un moteur de recherche, on peut accéder à des dizaines de datasets similaires aux données du cas d’usage.
Voici quelques exemples de datasets liés à des photos de poissons trouvés par cette méthode :
- La compétition Kaggle « The Nature Conservancy Fisheries Monitoring » (https://www.kaggle.com/c/the-nature-conservancy-fisheries-monitoring) qui consiste en la détection et la classification de huit espèces de poissons. Les photos ont été collectées par The Nature Conservancy :

Dans le cadre du cas d’usage, ces images ne correspondent pas aux conditions d’acquisition souhaitées. Les photos de pêche sont très différentes des photos de plongée. Les datasets issus de Kaggle sont intéressants pour participer aux compétitions mais ils ne sont pas forcément pertinents pour des besoins client ou utilisateur. Ils sont également très utiles et adaptés pour des formations de Data Science. De nombreux exemples de leur utilisation et des modèles créés à partir de ces données sont partagés sur la plateforme.
- Référentiel de datasets pour la classification de poissons : https://globalwetlandsproject.org/computer-vision-resources-fish-classification-datasets/. Ce lien liste plusieurs datasets qui semblent similaires à l’objectif du cas d’usage. En approfondissant les liens, la plupart des datasets référencés ne coïncident pas non plus au mode d’acquisition des plongeurs (mode contrôlé, in-situ, out-of-water) pour Fish Dataset par exemple.

- Un dataset se distingue : OzFish (https://github.com/AIMS/ozfish) est une collection de plus 80 000 images rognées et de 45 000 annotations issues de Baited Remote Underwater Video Stations. Ce dataset contient 70 familles, 200 genres et 507 espèces de poissons. Le mode d’acquisition est adapté à notre cas d’usage car ses images correspondent bien à des photos pouvant être prises par des plongeurs. En revanche, les classes contenues dans ce dataset sont éloignées de l’objectif du cas d’usage. En effet, les espèces représentées sont des espèces australiennes et non des espèces méditerranéennes.

Exemples d'images issues d'OzFish
Ces différents datasets sont pour la grande majorité créés par des laboratoires de recherche. Ces laboratoires ont une faible probabilité de rencontrer des problématiques similaires aux nôtres. Cette méthode paraît attirante pour commencer à créer son modèle mais elle va nous éloigner de l’objectif. Ces datasets donnent à la communauté scientifique un moyen simple de comparer les modèles issus de la recherche. Tout le monde utilise la même base, la comparaison des performances des modèles est facilitée. Il faut être vigilant à la licence associée à ces datasets, ces licences peuvent être sous condition et ainsi à la recherche ou payant pour un usage industriel .
Cette solution est à envisager dans un cadre de projet de recherche ou de POC (Proof of Concept/Preuve de Concept). Dans des projets de Deep Learning, ces datasets peuvent compléter l’existant et permettent de faire du Transfer Learning plus facilement (technique d’apprentissage permettant d’appliquer des connaissances et des compétences, apprises à partir de tâches antérieures, sur de nouvelles tâches ou domaines partageant des similitudes).
Récupérer des images des utilisateurs, le dataset réaliste
Cette partie va détailler une troisième solution pour avoir un dataset le plus proche possible du besoin du client ou des utilisateurs. Dans le cadre du cas d’usage de cet article, l’objectif est d’identifier des photos provenant des plongées et non de la pêche. Une des premières démarches est de demander au client la quantité de données qu’il a en sa possession. Dans le cadre où les données sont limitées, une des pistes est de lui proposer une démarche pour permettre de constituer un dataset proche de son objectif. Par exemple, il pourra se rapprocher d’associations de plongeurs ou de groupes de plongeurs dédiés pour leur demander une collecte de leurs images tirées de leurs archives.
Contacter en amont les futurs utilisateurs de l’application est une piste à considérer dès le début d’un projet. Des ateliers peuvent être fait pour travailler avec eux et organiser une collecte de leurs photos qu'ils ont pu faire lors de leurs plongées en Méditerranée. C'est une des étapes déterminantes d’un projet de Data Science où il est nécessaire de dépenser de l'énergie. Les données récoltées seront ainsi au plus proche de l’objectif de l’application finale.

Images provenant de plongeurs (comme les images de la 1ère partie)
Les données synthétiques
Une autre manière de constituer un dataset est de créer les données de façon synthétique par des logiciels 3D. Le projet Hypersym (https://github.com/apple/ml-hypersim) est un exemple de dataset pour des scènes intérieures constitué par Apple.
Cette approche est difficilement adaptable pour notre cas d’usage pour modéliser toutes les espèces de poissons. Cependant, cette article (https://www.researchgate.net/publication/331940717_Fish_species_identification_using_a_convolutional_neural_network_trained_on_synthetic_data) exploite une approche de données synthétiques en générant des images synthétiques à partir des données réelles.
Les données synthétiques sont, dans leur usage, assez proches des données obtenus par un dataset de référence (Transfer Learning, R&D). Cependant, leur construction est plus coûteuse et nécessite des ressources ayant des connaissance dans les logiciels de création 3D.
Résumé
Les méthodes de constitution d’un dataset d’images énoncé ci-dessus ont chacune leurs avantages et leurs limites qui sont résumés dans le tableau suivant :
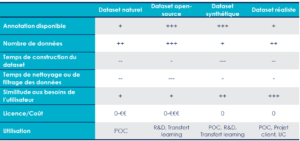
Les difficultés de la constitution d’un dataset
On favorise dans tous les projets industriels de travailler sur les données réalistes qui correspondent à l’objectif du projet et à la réalité terrain (ground truth).
L’annotation
Selon les méthodes de collecte des données, il peut être nécessaire de passer par une étape d’annotation réalisée éventuellement par une équipe d’experts. De nombreux outils existent maintenant pour l’annotation d’images tels que LabelBox (https://labelbox.com/) ou Remo (https://remo.ai/). Ce dernier permet d’organiser, d’annoter ou de visualiser des datasets d’images dans une application Web de façon privée.
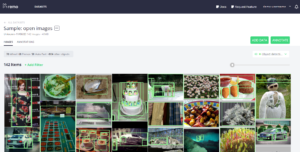
Démonstration de remo.ai
Cette étape qualifiée de manuelle ou de semi-automatique (si cela consiste seulement à vérifier les labels fournis par un premier modèle) est cruciale et est souvent négligée car elle est considérée coûteuse en temps et fastidieuse par le Data Scientist. Au contraire, l’annotation permet de constituer la matière première pour créer un modèle de Machine Learning. Pour en savoir plus sur l’importance de l’annotation, on peut se référer à l’article suivant : https://blog.octo.com/deep-learning-a-lechelle-mieux-annoter-pour-mieux-scaler/
Les cas limites
Lors de la constitution d’un dataset, les utilisateurs (ou les plongeurs) ont sûrement envoyé leurs plus belles photos mais aussi quelques photos non pertinentes avec le sujet: photo floue, ou de mauvaise qualité, trop sombre, espèce non identifiable, espèce non concernée par l’objectif, ou non triée.

Exemples de photos floues, peu contrastées, non pertinentes, ou avec des espèces non identifiables
Ces cas limites ne doivent pas être ignorés. En effet, le modèle doit aussi pouvoir traiter des cas similaires lors de l’utilisation de l’application. Il est nécessaire de définir une stratégie, des contraintes et des règles de rejet interprétables par l’utilisateur. Plusieurs stratégies peuvent être appliquées dans l’exemple de l’UC :
- Soit mettre en place des prétraitements qui correspondent à ces critères. Ces prétraitements permettent de rejeter les images avant qu’elles soient traitées par un modèle (détection du flou, sombre, manque de luminosité).
- Soit garder ces données « imparfaites » dans le dataset, et ajouter une classe "rejet" à notre modèle.
Le déséquilibre des classes
Un déséquilibre des classes peut apparaître dans tout dataset, car la réalité elle-même est déséquilibrée. Il est plus facile de photographier des mérous en Mer Méditerranée qu’un poisson-lune. Ce déséquilibre rend la modélisation du problème plus difficile. Le Data Scientist devra se méfier que le modèle ne sur-apprenne pas les classes majoritaires et ne sous-apprenne pas les classes minoritaires.
Des stratégies pour renforcer les classes sous-représentées peuvent être mises en place : acquisition dédiée pour une espèce ou Data Augmentation. La Data Augmentation consiste en la transformation des images initiales par des filtres et des transformations géométriques pour en créer des nouvelles. Il existe des packages Python dédiés à ce type de transformation tel que ImgAug (https://imgaug.readthedocs.io/en/latest/). Un article complet sur les données déséquilibrées est disponible sur le blog d’Octo: https://blog.octo.com/donnees-desequilibrees-que-faire/

Population déséquilibrée...
L'évolution naturelle des données
La réalité des données
Concrètement, un dataset est souvent géré comme un dossier d’images et un dossier avec les annotations. C’est un format couramment utilisé par les datasets de référence en open-source. On peut trouver également des datasets découpés en trois parties : train/validation/test qui permet de séparer les données d’apprentissage des données d’évaluation.
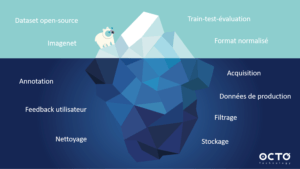
La face cachée des datasets dans des projets industriels
Cependant, un dataset évolue au cours du temps pour différentes raisons. On peut en citer quatre exemples qui peuvent se présenter dans le cadre du cas d’usage:
- Le client reçoit un mois plus tard de nouvelles images d'un plongeur après la campagne d'annotation v0. Cela ne représente que peu d'images mais néanmoins il veut les ajouter car elles représentent des images d’espèces sous-représentées. Cela donne une version v0.1 du dataset (modification corrective).
- Après la campagne d'annotation et avec les premiers résultats de modélisation, le Data Scientist se rend compte que certaines annotations sont fausses (l’annotateur peut se tromper). Cela entraîne la version v0.1.1 du dataset (modification mineure)
- Dans l’exemple de ce cas d’usage, le client a comme objectif d’identifier les 50 espèces les plus représentées en Méditerranée. Maintenant que le modèle est satisfaisant, il souhaite ajouter 50 espèces en plus qui n'étaient pas annotées. Une nouvelle phase d’annotation doit être effectuée, la version du dataset va évoluer en v1.0.0 (modification majeure). Il y a un changement complet des classes cibles et donc une mise à jour importante de l'annotation.
- Une fois l’application sur le marché, le client va pouvoir obtenir de nombreux retours des utilisateurs avec ses propres données. L’utilisateur aura la possibilité de remonter des erreurs, des faux positifs (l’espèce a été confondue avec une autre), ou des faux négatifs (l’espèce n’a pas été reconnue). Ces cas intéressants qui deviennent fréquents, vont permettre d’améliorer ou de corriger le modèle. Ces données seront à ajouter au dataset pour ré-entraîner un modèle. La version du dataset sera ainsi à la version v1.2.0 (modification mineure)
Comme pour un code informatique, un dataset doit pouvoir suivre les règles de Semantic Versionning : https://semver.org/lang/fr/
Les différents états d’un dataset
Il existe différentes manières dont un dataset peut évoluer. Elles sont souvent passées sous silence dans la mise en place des architectures de Machine Learning ou de Deep Learning. Un des enjeux de suivi des explorations ou de mise en production d'un modèle est tout d'abord le suivi de la matière première lors de la création d'un modèle c'est-à-dire les données et leur annotation. Ces données vivent, changent et sont modulaires comme le code. Il est nécessaire de prendre conscience qu'elles doivent pouvoir évoluer. Les données issues des feedbacks lors de la mise en application du produit sont à prendre en compte dans les datasets.
SI les données n’évoluent pas, cela peut expliquer une des raisons d’obtenir des modèles biaisés. Ces modèles peuvent devenir discriminatoires et non adaptés à la problématique. Par exemple, le client veut une application qui permet d’identifier maintenant des espèces présentes en Mer Rouge en se basant sur le travail effectué pour la Mer Méditerranée. Par simplicité ou par économie, on pourra réutiliser des données issues de la collecte précédente**.** Néanmoins, il est fort probable que le modèle reconnaisse très mal les nouvelles espèces car elles vont rester minoritaires dans le dataset initial. Les espèces sont souvent plus colorées ou complètement différentes selon le contexte, on va introduire un biais inconscient au modèle.

et un mérou Brun (Mer Méditerranée)
En ajoutant des cas acquis en Mer Rouge (donc en créant une nouvelle version du dataset), il est fort probable que la modélisation sera facilitée.
La capacité à faire évoluer les données va influencer les performances d’un modèle de Machine Learning.
En résumé, un dataset peut être vu de différentes manières :
- Dataset de référence: dataset constitué, figé souvent découpé en train/test/validation et qui va rester inchangé au cours du projet. C’est une référence,
- Dataset issus de la réalité terrain et évolutif : dataset avec plusieurs versions, plusieurs annotations, et qui permet de comparer les performances selon différentes versions.
- Dataset de recette : images + annotations non connues à l'avance, un dataset qui permet de savoir que le modèle n’a pas été sur-appris, il est souvent utilisé pour valider le modèle avant la mise en production.
- Dataset de production: pas ou peu d'annotation, données acquises en production suite à des feedbacks des utilisateurs.
Versionner son dataset
Les données lors de la création d’un modèle de Machine Learning font partie du triplet code/model/data triplet comme énoncé dans l'article de Martin Fowler : https://martinfowler.com/articles/cd4ml.html. Il est important de suivre l’évolution des données et de les suivre en version, comme si les données devenaient une dépendance du code informatique.
Versionner son dataset permet :
- de suivre les résultats des modélisations,
- d’avoir un pipeline de Data Science reproductible et partageable,
- de savoir exactement ce qui tourne en production,
- de faciliter le debug.

Triplet Data/Model/Code extrait de https://martinfowler.com/articles/cd4ml.html
Lorsqu'un Data Scientist commence à créer son premier modèle, la solution la plus simple consiste à mettre ces données dans un dossier, avec un dossier données brutes et un autre avec l’annotation. Il peut y avoir sur certain projet un dossier pour séparer le dataset en Train/Test/Validation. Si des données doivent être ajoutées, cette méthode de suivi des données apparaît très limitée.
Il existe d’autres techniques qui permettent d’avoir un suivi des versions. Toutes ces techniques se basent sur Git, qui est un outil qui a fait ses preuves pour suivre les versions de code:
- Créer des listes des chemins (avec des chemins Cloud ou local) vers les données, ajouter ces fichiers texte à un dépôt Git: technique assez simple qui permet de garder un suivi, de le versionner facilement, adaptable et modifiable. Il est ainsi facile de relancer un apprentissage avec une version du code, une version du dataset, et de pouvoir comparer les résultats avec une autre version.
- Une méthode plus évoluée consiste à stocker les informations de chemins des données (et pas forcément les données) et leur annotation dans une base de données (BDD). Cette méthode a l’avantage de pouvoir stocker des informations annexes à l’annotation : nom de l’annotateur, date d’ajout, date d’annotation, session, version … Le stockage en BDD permet de créer aussi facilement des filtres à partir de requêtes SQL. Ces requêtes SQL sont stockées au niveau du code et de la création du modèle, ce qui permet de relancer facilement un apprentissage dans les mêmes conditions.
- Des outils dédiés au suivi de version des données commencent à apparaître dans les outils du Data Scientist, tel que DVC (https://dvc.org/). DVC est conçu pour rendre les modèles ML partageables et reproductibles. Il est conçu pour traiter les fichiers volumineux, les jeux de données, les modèles d’apprentissage automatique, les mesures ainsi que le code. Un article complet est disponible sur le blog d'Octo : https://blog.octo.com/mise-en-application-de-dvc-sur-un-projet-de-machine-learning/
Le débriefing
À travers cet article, plusieurs aspects sur la constitution d’un dataset ont été détaillés et mis en valeur : la création, la gestion et le suivi. Un dataset est la matière première de tout projet de Data Science.
Plusieurs méthodes de constitution d’un dataset ont été expliquées avec chacune leurs avantages et leurs limites. Un premier objectif est de collecter un maximum de données au plus proche de la cible finale. Pour cela, des ateliers pour créer un dataset sont nécessaires en amont, avant même les réflexions liées au modèle à mettre en place. Nous avons également vu que l’annotation du dataset et la gestion des cas limites sont des étapes souvent inévitables.
Toutes ces approches ont comme enjeu de favoriser l’apprentissage du modèle. L’apprentissage d’un modèle, tout comme le niveau des performances obtenues, dépendent en effet de la qualité des données et des annotations.
Finalement, un dataset doit avoir la possibilité d’évoluer et de se transformer. La démarche que nous préconisons consiste à traiter un dataset comme du code informatique avec des versions et un suivi de version associé.
