Paris Chaos-engineering-meetup-9-perseverance-notes
On February 10th, 2022, I attended the Paris Chaos Engineering Meetup #9 hosted by WeScale, I wanted to share my notes about this meetup !
Disclaimer : The recordings of each presentation aren’t published as I’m writing this report. Nevertheless, they should appear on the YouTube channel of the “Paris Chaos Engineering Meetup”
TALK 1 - Game Days at ManoMano
Speaker : Clément Hussenot, Platform Engineering Manager at ManoMano
ManoMano is in a hyper-growth cycle, and recently became a Unicorn 🦄
It’s a marketplace with 50 million visitors every month and a base of 10 million products referenced, warehouse between France, Spain … It’s a big deal
During the talk, Clément summarized 2 years of work that he and his teams have put in place. They are responsible for governance on topics such as observability, system and web application performance, Incident Management and Chaos Engineering.
The “Why” behind the introduction to Chaos Engineering at ManoMano?
Clément takes the example of the history of the Concorde. The engineers who worked on Concorde design and construction made a lot of modifications to ensure its reliability. Unfortunately, we know the story of the tragic crash. However, the teams were aware that there was a problem with the wheels, but it was not corrected before the crash happened.
To draw a parallel with Chaos Engineering, it is precisely the objective to highlight the weaknesses of a system before they become a critical problem.
It is then necessary to Fail Fast (failure can produce success, learning from failures and realize greater output), we must provoke rational failures to learn from them and accelerate their resolution, as well as for those to come.
Let’s take a time to note two definitions from the Gremlin glossary
Chaos Engineering
“The science of performing intentional experimentation on a system by injecting precise and measured amounts of stress to observe how the system responds for the purpose of understanding and improving the system’s resilience.” — https://www.gremlin.com/docs/quick-starts/gremlin-glossary/#chaos-engineering
Resilience
“The ability to recover quickly from adversity, change, or other problems in socio-technical systems.
In Gremlin usage, this is how well a system recovers from degraded conditions or failures.
* Using Chaos Engineering to test your Incident Response is an example of resiliency.
* Note: resilience and reliability are not interchangeable. Reliability is the outcome, and resilience is the way you achieve that outcome. Making systems more resilient to failure results in them being more reliable” — https://www.gremlin.com/docs/quick-starts/gremlin-glossary/#resilience
Two main levers of change : Culture and Readiness
Culture
Train people, teach them to be better at analysis. Everyone at their own level, participates to the smooth running of this complex system that is the organization, by introducing people to Chaos Engineering we are going to be able to make them aware that they all have a role to play, one way or another in order to achieve a better resiliency and therefore a better reliability of what the organization produces.
Convince the Top Management : there is obviously no interest in breaking your production without learning from it. It’s necessary to give metrics (that speak to all): Conversion rate, time spent on the site …
Through the implementation of Chaos Engineering we can reduce major outages occurrences and their resolution (we make sure that it does not happen again) and we will improve the metrics, SLO will be high; example : 99.99%
In terms of culture, we need a strong entity that can unite people.
At ManoMano this entity represents 40 people (communication, technical team, site reliability engineering team …)
The objective will be to observe if the hypotheses we have made are the ones we expect, if not, we will improve and learn.
Local branding (internally at ManoMano) is necessary in order to extend the scope and not only reach the tech part of the organization, otherwise there is no point, it is really necessary to extend to all the sociotechnical system
> Yes ! Chaos Engineering addresses the entire sociotechnical system
Readiness
Teams must be trained to respond to incidents always in the socio-technical scope, responding to incidents also means sharing knowledge and resolution processes.
Firefighter
ManoMano put in place a tool called FireFighter, which is a slack bot that automates a lot of things to manage incidents. It is also used to train the people.
It is a kind of state machine whose workflow is as follows :
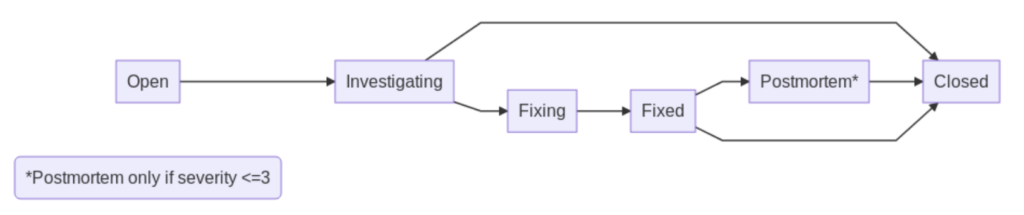
(source: this article from the ManoMano tech blog)
This allows for traceability of incidents (status, severity, people involved …) with the ease of reporting the unexpected event through this bot slack, via slack commands, while providing statistics to managers. The most important thing to remember is that it allows to have quality post mortem that are hosted in their Confluence
For more information about this Incident Management tool within ManoMano you should read their article (which goes way more into details), and to check their tech blog
Let’s talk about Game Days!
How do you introduce people to Game Days ?
How to raise awareness among people about Game days ?
In short, how to inspire people about Game Days ?
What is a Game Day at ManoMano ?
A Game Day brings together people from all across the organization to collaboratively break, observe, and restore a system to a functional state.
It is designed to test, train, and prepare systems, software, and people for a disaster by deliberately injecting failures into critical systems.
Two Game Day styles
Informed In Advance :__- Where the heroes are told before the Game Day about the type of incident they are walking into
Dungeons & Dragons :__- None of the heroes are aware of the conditions they are walking into
Game Day 1 - December 2020 - Informed In Advance
For the very first Game Day, the invitation is open to all ManoMano, only 100 people responded to the invitation.
A team of 20 people is formed to set up the Game Day. A series of workshops followed to :
1st workshop : Define themes for experiments
2nd workshop : Refine the list of experiments with clearly identified targets and objectives
3rd workshop : For the observability we use DataDog, we make a point on the open discussion experiments. We have the list of 8 experiments, we will choose only one for the day of the Game Day

(source : this article from the ManoMano tech blog)
The roles:

(source: this article from the ManoMano tech blog)
After the different workshops everything is ready, it’s time to launch the game day.
The subject that was retained amongst the list is synchronization, strange behavior is occurring on the site, sometimes the price displayed on the page of a product and on the page that lists the same product are not the same.
Target: Search, Product Page, Product Listing Page
Duration : 20 minutes
Environment : Production
The event was a good experience. People learned things. In the time following this first Game Day, an improvement in the quality of the incident reports was observed, allowing a better understanding of the people who are not in the technical part and it allowed to improve the communication during the incidents with the services/people who are in relation with the customers.
Game Day 2 - May 2021 - Organized with AWS
It’s the remake of the Game Day of 2015 with a little difference, to add more fun they imagined the following story : “Kyle , a visionary at the head of the company is gone, everyone else is gone, the new team comes in and has to figure everything out.“
Teams of 3 or 4 people that are fairly multidisciplinary.
This Game Day was more oriented towards people who were new to AWS infrastructures.
You can find the report of one of the participants to this Game Day, here.
Game Day 3 - December 2021 - Fire Drill Game Day
Mix of the first 2 Game Days.
Organization process like the 1st Game Day, but without the communication, without any particular explanation. It's a Dungeons & Dragons style Game Day
Target : Multiple incidents are open, they have to be resolved
Duration : 2 / 3 hours
The participants of this Game Day had two different roles: the villains (manage the set up of the incidents) and the heroes (they have to solve the incidents set up by the villains).
Left to their own devices, those responsible for resolving incidents had to make assumptions and investigate on their own. They were evaluated on their response to the incidents.
During this Game Day there was a real-time scoreboard that was accessible to see who was winning.
Takeaways from this talk :
Setting up a Game Day is quite tedious but the learning you get from it will put you on a path of continuous improvement towards better resilience and therefore greater reliability, it's a virtuous circle.
Two main levers of change : culture and readiness
“the incident is a catalyst to understanding where you need to improve your socio technical system“
We have to work on the post mortem to make sure that people talk about them and that they are of good quality (understable in the main lines by everyone). ManoMano studied their own post mortem, from this study they discovered 4 failure classes.
Chaos Engineering can highlight Conway's Law
TALK 2 - REX : Setting up Chaos Engineering: Everything to break or everything to build
Speakers : Rémi Ziolkowski and Robin Segura both Devops/Chaos Engineers at Klanik, working for their customer Pôle Emploi
Context: 1000/1500 people in the Tech Department, 55 000 employees at Pôle Emploi
Several kind of infrastructure one legacy and 2 other platforms based on Kubernetes and CloudFoundry
The “Why” of Rémi and Robin's presence at Pôle Emploi ?
Verify and improve Information System resilience and responsiveness.
A chaos day already took place in April 2018, before Robin and Remi arrived. They are in a context where chaos engineering is not unknown. They are working in a team of 5 people.
The objective of their presence is to challenge teams, verify that they can respond to incidents, and help them evaluate the maturity of the observability in place.
It's also about implementing Chaos Engineering in a more granular way and more regularly, not just on a dedicated chaos day.
In a context where there was a first contact with Chaos Engineering, a method already exist, they will rely on it (each point represent a workshop) :
Prioritization and eligibility
How the service work
Expected objective
Test definition
Preparing for observability
Launch of the exercise
Action plan and capitalization
The teams were more or less accompanied according to the different phases :
Chaos is not breaking everything, we work together to see what is relevant to do, so that you know your service better, we place ourselves as "servant" of chaos.
Teams do exercises in an accompanied wayValidated maturity level
The team is autonomous to run the exercise
Fully autonomous teams
They were able to set up several exercises for the different types of infrastructures that are present at Pôle Emploi
What does an exercise look like?
Exercise 1:
Two dependent services, Zookeeper instances on which Solr instances are based.
Target : to progressively shut down the instances of each service
How do they organize themselves for the exercise?
They formulate a hypothesis concerning the course of the exercise :
- Execution of the first test
- Impact and alerts
- Analysis and consideration
- Resolution
- Rollback to initial state and debriefing
Often it doesn't go as planned and they learn from it, especially on how to achieve resilience and therefore reliability of services
Exercice 2 : Use of LitmusChaos for the automation
The tool they used to automate exercises set up is LitmusChaos, unfortunately the demonstration was not successful during the talk.
Nevertheless it is necessary to remember that LitmusChaos offers a catalog of experiments provided by default at this address: https://hub.litmuschaos.io/
It is possible to have your own hub, that's what Rémi and Robin did at Pôle Emploi. They created a Chaos Hub to centralize their own experiences. This allows them to have an in-house hub where the experiences are already preconfigured. Furthermore, we can define a resilience score for each experiment according to its importance. Experiments can be scheduled via Argo Workflow to run at a specific time (every hour, every day ...), they can be launched automatically.
The objective is to have a catalog that allows us to have resilience tests adapted to the different types of infrastructures on which Pôle Emploi relies.
LitmusChaos has recently been upgraded to the next level of maturity by the CNCF. Indeed, it has been moved from Sandbox to Incubating level :
(this screenshot comes from https://www.cncf.io/projects/)
Takeaways from this talk:
Having done a day of chaos is not enough to be resilient, it is necessary on the contrary to perpetuate the practices related to Chaos Engineering in order to enter a virtuous circle toward continuous improvements that will result in a better resiliency and thus a better reliability
We need to accompany the teams until they are mature and are completely autonomous on the subject
LitmusChaos is a good tool to centralize and automate the ability to launch experiments as needed