Paris Chaos-engineering-meetup-9-perseverance-compte-rendu
Le 10 février 2022, j’ai assisté au Paris Chaos Engineering Meetup #9 hébergé chez WeScale, je voulais partager ce que j’ai pu retenir au travers d’un compte rendu.
Petite précision : au moment où j’écris ces lignes, les enregistrements de chaque présentation n’ont pas encore été publiés. Néanmoins, ils devraient apparaître sur la chaîne youtube du meetup “Paris Chaos Engineering Meetup”
TALK 1 - Des Game Days chez ManoMano
Intervenant : Clément Hussenot, Platform Engineering Manager chez ManoMano
ManoMano est dans un cycle d’hyper-croissance, elle est devenue une Licorne 🦄 récemment.
C’est une place de marché avec 50 millions de visiteurs tous les mois et une base de 10 millions de produits référencés, warehouse entre la France, l’Espagne … Bref ça pèse.
Durant le talk, Clément nous a résumé 2 ans de travail qu’il a mis en place avec ses équipes. Ils sont responsables de la gouvernance sur les sujets d'observabilité, de performances systèmes et applications web, d’Incident Management et de Chaos Engineering.
Le “Why” de l’introduction au Chaos Engineering chez ManoMano ?
Clément prend l’exemple de l’histoire du Concorde. Les ingénieurs qui ont travaillé à sa conception et à sa réalisation ont fait énormément de modifications pour assurer sa fiabilité. Malheureusement, on connaît l’histoire tragique du crash. Pourtant, les équipes étaient au courant qu’il y avait un souci au niveau des roues, mais ça n’a pas été corrigé avant l’accident.
Pour faire le parallèle avec le Chaos Engineering, c’est justement l’objectif : mettre en évidence les faiblesses d’un système avant qu’elles ne deviennent un problème critique.
Il faut alors Fail Fast (failure can produce success, learning from failures and realize greater output). Dans le sens où il faut provoquer des pannes réfléchies pour apprendre de ces dernières et accélérer leurs résolutions, ainsi que pour celles à venir.
Prenons le temps de noter deux définitions issues du glossaire Gremlin
Chaos Engineering
“The science of performing intentional experimentation on a system by injecting precise and measured amounts of stress to observe how the system responds for the purpose of understanding and improving the system’s resilience.” - https://www.gremlin.com/docs/quick-starts/gremlin-glossary/#chaos-engineering
Resilience
“The ability to recover quickly from adversity, change, or other problems in socio-technical systems. In Gremlin usage, this is how well a system recovers from degraded conditions or failures.
* Using Chaos Engineering to test your Incident Response is an example of resiliency.
* Note: resilience and reliability are not interchangeable. Reliability is the outcome, and resilience is the way you achieve that outcome. Making systems more resilient to failure results in them being more reliable” - https://www.gremlin.com/docs/quick-starts/gremlin-glossary/#resilience
Deux leviers principaux de changement : La culture et La readiness
La Culture
Entraîner les personnes, leur apprendre à être meilleur en analyse. Chacun à son échelle, participe au bon fonctionnement de ce système complexe qu’est l’organisation, en les sensibilisant, en leur faisant découvrir le Chaos Engineering on va pouvoir leur faire prendre conscience qu’ils ont tous un rôle à jouer de près ou de loin pour atteindre une meilleure résilience et donc une meilleure fiabilité de ce que l'organisation produit.
Convaincre le Top Management : il n’y a bien évidemment pas d’intérêt de casser la production sans en tirer des apprentissages. Il faut donner des métriques (qui parlent à tous): Taux de conversion, le temps passé sur le site …
Au travers de la mise en place du Chaos Engineering on peut réduire les occurrences d’incidents majeurs, ainsi que leur résolution (on fait en sorte que ça ne se reproduise pas) et on va améliorer les métriques et le SLO sera haut ; exemple : 99.99%
En terme de culture, il faut une entité forte qui va pouvoir fédérer les personnes.
Chez ManoMano cette entité représente 40 personnes (communication, équipe technique, site reliability engineering team …)
L’objectif va être d’observer si les hypothèses qu’on a fait sont bien celles auxquelles on s’attend, sinon on s’améliore et on apprend.
Le branding en local (en interne chez ManoMano) est nécessaire afin d’étendre le scope et de ne pas toucher uniquement la partie tech de l’organisation sinon ça n’a pas d’intérêt, il faut vraiment élargir à tout le système sociotechnique.
> Et oui ! Le Chaos Engineering s’adresse à tout le système sociotechnique
La Readiness
Il faut entraîner les équipes à répondre aux incidents toujours dans le scope sociotechnique, répondre aux incidents c’est aussi partager la connaissance, les processus de résolution.
Firefighter
Chez ManoMano a été mis en place un outil appelé FireFighter, c’est un bot slack qui permet d’automatiser pleins de choses pour gérer les incidents. Il sert aussi à entraîner toutes les personnes.
C’est une sorte de machine à état dont voici le workflow :
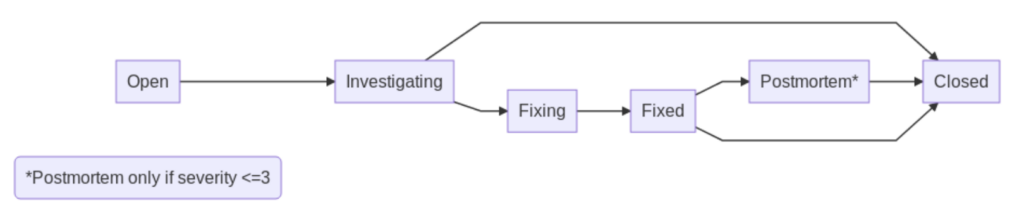
(source: cet article du blog tech de ManoMano)
Cela permet d’avoir une traçabilité des incidents (statut, sévérité, personnes impliquées …) en ayant la facilité de déclarer l’événement imprévu au travers de ce bot slack, via des commandes slack, tout en fournissant des statistiques aux managers. Ce qu’il faut retenir c’est que cela permet surtout d’avoir des post mortem de qualité qui sont hébergés sur leur Confluence.
Pour plus d’informations sur cet outil d’Incident Management au sein de ManoMano, il faut lire leur article (qui rentre plus dans le détail) et aussi regarder leur blog tech.
Abordons le sujet des Game Day !
Comment faire découvrir le principe des Game Day aux personnes ?
Comment sensibiliser les personnes aux Game Day ?
Bref, comment les inspirer au sujet des Game Day !
C’est quoi un Game Day chez ManoMano ?
Un Game Day rassemble les personnes de toute l’organisation pour casser, observer et remettre un système dans un état fonctionnel de manière collaborative.
Il est conçu pour tester, former et préparer les systèmes, les logiciels et les personnes à une catastrophe en injectant délibérément des défaillances dans les systèmes critiques.
Deux styles pour les Game Day
Informed In Advance :__- Les héros sont informés avant le Game Day du type d'incident auquel ils sont confrontés.
Dungeons & Dragons :__- Aucun des héros n'est conscient des conditions dans lesquelles il s'engage.
Game Day 1 - Décembre 2020 - Informed In Advance
Pour le tout premier Game Day, l’invitation s’adresse à tout ManoMano, seulement 100 personnes répondent pour y participer.
Une équipe de 20 personnes se forme pour mettre en place le Game Day. S’ensuit une série de plusieurs workshops pour :
1e workshop : Définir des thèmes d’expériences
2e workshop : Affiner la liste des expériences avec des cibles et des objectifs clairements identifiés
3e workshop : Pour l’observabilité on fait appel à DataDog, on fait un point sur les expériences discussion ouvertes. On a la liste 8 expériences, on en choisira une seule pour le jour du Game Day

(source : cet article du blog tech de ManoMano)
Les rôles:

(source : cet article du blog tech de ManoMano)
Après les différents workshops tout est prêt, il ne reste plus qu’à lancer le game day.
Le sujet qui a été retenu parmi la liste c’est celui de la synchronisation, un comportement étrange sur le site est en cours, parfois le prix affiché sur la page d’un produit et sur la page qui liste le même produit ne sont pas les mêmes.
Cible : Recherche, Page du produit, page qui liste les produits
Durée : 20 minutes
Environnement : Production
L’événement a été vécu comme une bonne expérience. Les personnes ont appris des choses. Dans les temps qui ont suivi ce premier Game Day, une amélioration de la qualité des rapports d’incidents a été observé, permettant une meilleur compréhension des personnes qui ne sont pas dans la partie technique et ça a permis d’améliorer la communication durant les incidents auprès des services/personnes qui sont en relations avec les clients.
Game Day 2 - Mai 2021 - Organisé avec AWS
Ils ont refait le Game Day de 2015 avec la différence qu’ils ont apporté un aspect plus fun, en ajoutant une histoire : “Kyle le visionnaire de la boîte est parti, tout le monde est parti, la nouvelle équipe arrive et doit tout découvrir.”
Des équipes de 3 ou 4 personnes assez pluridisciplinaires.
Ce Game Day était plus orienté pour les personnes qui découvraient les infrastructures AWS.
Le rapport d’un des participants à ce Game Day.
Game Day 3 - Décembre 2021 - Fire Drill Game Day
C’est une combinaison des 2 premiers Game Day.
Processus d’organisation comme le 1er Game Day, mais sans la communication, sans explications particulières. C’est un Game Day du style Dungeons & Dragons
Cible : Des incidents multiples sont ouverts il faut les résoudre.
Durée : 2 / 3 heures
Les participants à ce Game Day avaient deux rôles différents: les vilains (ils gèrent la mise en place des incidents) et les héros (ils doivent résoudre les incidents mis en place par les vilains).
En étant laissés à eux-mêmes, ceux qui étaient chargés de la résolution des incidents, ont dû faire des hypothèses et investiguer par leurs propres moyens. Ils ont été évalués sur la réponse qu’ils ont apportée aux incidents.
Lors de ce Game Day il y avait un tableau des scores en temps réel qui était accessible pour voir qui était en train de gagner.
Ce qu’il faut retenir de ce talk :
La mise en place d'un Game Day est assez fastidieuse mais l'apprentissage que vous en tirerez vous mettra sur une voie d'amélioration continue vers une meilleure résilience et donc une plus grande fiabilité, c’est un cercle vertueux.
Deux leviers de changement : la culture et la readiness
“l'incident est un catalyseur pour comprendre où vous devez améliorer votre système sociotechnique“
Il faut travailler sur les post mortem faire en sorte que les gens en parlent et qu’ils soient de bonne qualité (facilement compréhensible). ManoMano a réalisé une étude sur ses propres post mortem, cette étude leur a permis de mettre en lumière 4 classes de pannes.
Le Chaos Engineering peut mettre en exergue La loi de Conway
TALK 2 - REX : Mise en place du Chaos Engineering: Tout à casser ou tout à construire
Intervenants : Rémi Ziolkowski et Robin Segura tout deux Devops/Chaos Engineer chez Klanik en mission chez Pôle Emploi
Contexte : 1000/1500 personnes à la DSI, 55 000 employés à Pôle emploi
Plusieurs types d’infrastructures à la fois du legacy et 2 autres plateformes reposants sur Kubernetes et CloudFoundry
Le “Why” de la présence de Rémi et Robin ?
Vérifier et améliorer la résilience et réactivité du SI.
Il y a déjà eu un days of chaos en avril 2018, avant l’arrivée de Rémi et Robin. Ils arrivent donc dans un contexte où le chaos engineering n’est pas inconnu. Ils travaillent dans une équipe constituée de 5 personnes.
L’objectif de leur présence est de challenger les équipes, vérifier qu’elles peuvent répondre aux incidents, les aider à évaluer la maturité quant à l’observabilité en place.
C’est aussi mettre en place le Chaos Engineering de manière plus granulaire et plus régulièrement pas seulement lors d’un jour de chaos dédié.
Dans un contexte où il y’a déjà eu un premier contact avec le Chaos Engineering une méthode existe déjà, ils vont se reposer dessus (chaque point représente un atelier) :
Priorisation et éligibilité
Fonctionnement du service
Objectif attendus
Définitions des tests
Préparer l’observabilité
Lancement de l’exercice
Plan d’actions et capitalisation
Les équipes ont été plus ou moins accompagnées selon les différentes phases :
Le chaos c’est n’est pas tout casser, on travaille ensemble pour voir ce qu’il est pertinent de faire, afin que vous connaissiez mieux votre service, on se place en tant que “serviteur” de chaos.
Les équipes font des exercices de manière accompagnéeNiveau de maturité validé
Exercices en autonomie
Équipe complément autonome
Ils ont pu mettre en place plusieurs exercices dans les différents types d’infrastructures qui sont présentes chez Pôle Emploi.
Comment se présente un exercice ?
Exercice 1 :
2 services dépendants des instances Zookeeper sur lesquels se basent des instances de Solr
Objectif : couper progressivement les instances de chaque service
Comment ils s’organisent pour l’exercice ?
Ils formulent une hypothèse concernant le déroulé de l’exercice :
- Lancement du premier test
- Impact et alertes
- Analyse et prise en compte
- Résolution
- Retour à l’état initial et compte rendu
Souvent ça ne passe pas comme prévu et ils en tirent des apprentissages notamment sur la manière d’atteindre la résilience et donc la fiabilité des services
Exercice 2 : Utilisation de LitmusChaos pour l’aspect automatisation
L’outil qu’ils ont utilisé pour automatiser la mise en place des exercices c’est LitmusChaos, malheureusement la démonstration n’a pas abouti durant le talk.
Il faut néanmoins retenir que LitmusChaos propose un catalogue d'expériences fournit par défaut à cette adresse : https://hub.litmuschaos.io/
Il est possible d’avoir son propre hub, c'est ce que Rémi et Robin ont fait chez Pôle Emploi. Ils ont créé un Chaos Hub afin d’y centraliser leur propre expériences. Cela leur permet d’avoir un hub maison où les expériences sont déjà préconfigurées. De plus, on peut définir un score de résilience pour chaque expérience en fonction de son importance. Les expériences peuvent être programmées via Argo Workflow pour s'exécuter à un moment précis (toutes les heures, tous les jours …), elles peuvent être lancées de manière automatique.
L’objectif est d’avoir un catalogue qui permet d’avoir des tests de résilience adaptés pour les différents types d’infrastructures sur lesquelles Pôle Emploi repose.
LitmusChaos est récemment passé au niveau supérieur de maturité attribué par la CNCF. En effet, il est passé du niveau Sandbox au niveau Incubating :
(cette capture provient du site https://www.cncf.io/projects/)
Ce qu’il faut retenir de ce talk :
Avoir fait un days of chaos ne suffit pas être résilient, il faut au contraire pérenniser les pratiques liées au Chaos Engineering afin de rentrer dans un cercle vertueux qui menera vers une amélioration continue qui aura pour résultat une meilleure résilience et finalement une meilleure fiabilité
Il faut un accompagnement des équipes jusqu’à qu’elles soient matures et complètement autonomes sur le sujet
LitmusChaos est un bon outil pour centraliser et automatiser le fait de pouvoir lancer des expériences selon le besoin