Ouvrir la boîte noire et comprendre les décisions des algorithmes
L’usage des algorithmes de traitement de données – de la simple requête SQL aux puissants algorithmes de recommandation et de personnalisation des géants de la Tech – s’est popularisé ces dernières années, notamment pour des utilisateurs traditionnellement hors du domaine IT. Cet usage se retrouve dans tous les secteurs (industrie, éducation, santé, sécurité, etc.) et tend à déléguer de plus en plus de décisions à des systèmes automatisés.
Cette appropriation par le plus grand nombre rend les naufrages encore plus probables, et l’exemple de Cambridge Analytica, en particulier, montre la nécessité d’une responsabilisation de tous les acteurs de la chaîne algorithmique. Deux principes sont nécessaires pour permettre une utilisation optimale et en accord avec les patrons de conception de ces traitements algorithmiques : Loyauté et Vigilance.
S’assurer de la loyauté d’un algorithme, que les décisions qu’il prend sont en accord avec ce qu’on attend de lui, implique que l’on puisse expliquer ses décisions, les comprendre, les challenger, et le cas échéant y apporter les correctifs nécessaires.
La vigilance, quant à elle, est une réponse au caractère parfois imprévisible de la méthode d’apprentissage des algorithmes. Elle vise à organiser, par des procédures concrètes, un questionnement régulier sur ces objets techniques complexes, de la part de tous les acteurs de la chaîne : de la conception à l’utilisation, de la définition de leurs objectifs à leur mise en œuvre.
Comment faire en sorte de respecter ces deux principes ? Quels impacts peuvent-ils avoir sur le développement ? Est-il possible de construire des systèmes algorithmiques responsables by design ?
Ce livret vous propose des pistes d’exploration pour définir des procédures responsables, en étudiant en premier lieu des techniques permettant d’expliquer les décisions d’un algorithme et de les partager en transparence. La deuxième partie est consacrée à différents biais statistiques pouvant s’insérer dans la conception et l’utilisation de ces traitements. Ce questionnement vous permettra de définir une stratégie de vigilance qui fera LA différence.
Interprétabilité et explicabilité
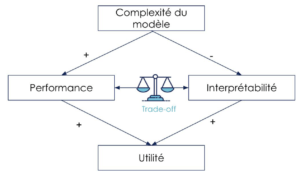
L’intelligence artificielle a toujours eu pour but, avoué ou non, de se rapprocher des capacités de l’intelligence humaine (voire un jour, de les dépasser). Dès le début, on a cherché à améliorer les performances des algorithmes, créant des modèles de plus en plus en complexes, jusqu’à obtenir des systèmes opaques, des ‘boîtes noires’. Or des modèles simples, qu’on peut interpréter facilement, donnent souvent des performances tout à fait respectables, mais on va souvent chercher malgré tout à les améliorer au détriment de l’interprétation (le trade-off interprétabilité/performance).
Il est important de réaliser qu’il n’existe pas de modèle parfait, parce que les modèles restent des simplifications/caractérisations de la réalité. Ainsi, à moins d’être dans une situation triviale, l’algorithme commettra toujours des erreurs, tout comme l’être humain d’ailleurs. Tout l’enjeu est de pouvoir gérer ces erreurs. Mais comment les gérer si on ne sait pas sur quelle base, selon quels critères, l’algorithme a pris sa décision ? Plus généralement, comment faire confiance aux modèles si on ne comprend pas comment ils fonctionnent (interprétabilité) et qu’on ne peut pas expliquer leurs décisions (explicabilité).
Souvent précurseur sur les sujets des algorithmes, le secteur des banques et des assurances a dû gérer ces questions depuis longtemps. En effet, si un prêt est refusé, la banque doit pouvoir donner les raisons de ce choix, que la décision ait été prise par un humain ou par une machine.
Avec l’adoption de l’IA, ces problématiques s’étendent. D’abord aux sujets sensibles qui touchent aux droits des personnes (recrutement, justice, droits sociaux…). On voit aussi ces questions apparaître quasi systématiquement lorsqu’on met un produit “intelligent” entre les mains des utilisateurs. Pourquoi Google Maps me fait passer par là ? Pourquoi Netflix me recommande-t-il ce film ? Pourquoi l’algorithme de maintenance prédictive me dit de changer le joint maintenant ? Ce besoin de comprendre “pourquoi” est devenu aujourd’hui l’objectif premier dans de très nombreux cas, déraillant la course à la performance. Il arrive également que la peur de ne pas être en mesure d’expliquer les décisions prises conduise à un refus d’adopter entièrement ces nouvelles technologies, au risque de passer à côté de tous les avantages concurrentiels qu’elles peuvent apporter.
Rassurez-vous, il existe des solutions !
Comment interpréter les algorithmes :
Il existe plusieurs solutions pour interpréter les algorithmes, et de nouvelles apparaissent fréquemment.
Avant tout, dans la mesure du possible, il est préférable de limiter la complexité. Cette complexité peut provenir de différentes sources, notamment le modèle mathématique utilisé. En effet, certains algorithmes comme les arbres de décisions ou les régressions sont beaucoup plus interprétables que des réseaux de neurones artificiels multicouches. Et comme on l’a vu plus haut, dans de nombreux cas, le gain de performance n’est pas toujours évident.

Dans certains cas, vous pouvez être obligés d’utiliser des modèles complexes. Par exemple, si vous analysez des images ou du son, vous aurez probablement à utiliser des réseaux de neurones artificiels (de type CNN ou LSTM). Des solutions commencent à être implémentées. Elles permettent d’avoir des informations plus ou moins complètes, sur les facteurs ayant influencés la décision de l’algorithme. Nous n’allons pas rentrer ici dans les détails techniques, mais sachez que c’est un pan très actif de la recherche actuelle et que nous disposons de plus en plus d’outils.
La complexité peut aussi émerger de transformations compliquées appliquées à la donnée. En effet, si un de vos facteurs est le cosinus de la température au carré, savoir qu’il est à l’origine de l’alerte de maintenance ne va pas directement vous expliquer pourquoi vous risquez la panne. On en arrive au problème d’explicabilité.
Comment expliquer les décisions des algorithmes :
Expliciter la décision :
Une fois qu’on a accès à l’information qui a influencé la décision du modèle, on peut alors l’exprimer à l’utilisateur afin de le rendre explicable. Savoir que Netflix nous recommande de regarder Spiderman parce que nous avons regardé les Avengers ou que Waze a changé l’itinéraire à cause d’un ralentissement à 10 km, nous aide à valider la décision prise ou à prendre une décision différente. Nous retrouvons un sentiment de contrôle et ces informations renforcent la confiance qu’on donne au système.
La façon dont on présente cette information est également importante. On observe souvent que le frein à l’adoption d’un système intelligent en entreprise vient des réticences des employés. Créer une interface intuitive et user-friendly, en utilisant des visualisations pertinentes et en verbalisant les décisions prises, peut avoir une influence trop souvent négligée sur l’adoption du système par les utilisateurs.
Exprimer l’indécision :
Trop souvent, la décision de l’algorithme est donnée de façon catégorielle : OUI ou NON, CHIEN ou CHAT, alors qu’il y a un degré de certitude/incertitude sous-jacent qui n’est pas exprimé. Dans la plupart des cas, la sortie de l’algorithme est une probabilité que ce soit un CHAT. On fixe ensuite un critère, souvent à 50 %, qui détermine une décision CHIEN si on est sous le critère et CHAT si on est au-dessus.
Accepter cette différence, c’est comprendre les failles possibles. En effet, il y a toute une zone d’incertitude, qui correspond à des situations ambiguës, où les erreurs peuvent apparaître. Cette zone d’incertitude est trop souvent ignorée, alors qu’on pourrait automatiser les décisions certaines et laisser aux utilisateurs le soin de prendre une décision lorsque l’algorithme n’est pas sûr.
On pourrait ainsi potentiellement éviter des erreurs et renforcer la confiance des utilisateurs. Si on prend l’exemple d’un algorithme de diagnostic médical, on pourrait (et devrait) proposer le diagnostic lorsque l’algorithme est certain et ne pas se prononcer pour les cas ambigus.
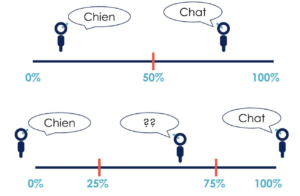
Ainsi, l’humain reste dans la boucle de décision, mais uniquement pour les cas incertains, lui libérant du temps pour se concentrer sur ces cas souvent délicats. On optimise les processus, tout en diminuant la possibilité de commettre des erreurs.
Biais statistiques et contrôle des décisions
Les algorithmes donnent l’illusion de neutralité et semblent donc prendre des décisions plus juste que les êtres humains, qui sont eux biaisés par nature. Or l’un des principaux dangers de l’IA est la perpétuation de ces biais. En effet, si l'algorithme apprend à partir de données reflétant des biais existants, l’usage de cet algorithme va renforcer les discriminations en automatisant une prise de décisions biaisées.
Par exemple, si les RH chez OCTO veulent mettre en place un algorithme qui pré-sélectionne les CV pour des postes de développeurs. Sachant que la majorité des profils disponibles, et du coup embauchés, à l’heure actuelle sont des hommes blancs qui sortent d’écoles d’ingénieurs, l’algorithme qui va apprendre sur la base de cette distribution biaisée ne sélectionnera dans le futur que des profils similaires. Un biais discriminatoire par rapport aux minorités va alors apparaître.
L’introduction de ces biais peut apparaître à différents niveaux : conception, collecte et transformation des données, implémentation, etc. Ils se reflètent par une prise de décision qui peut :
- Ne pas refléter la volonté du concepteur.
- Renforcer des discriminations existantes.
Ces biais peuvent être particulièrement difficiles à discerner, notamment à cause de la difficulté d’interpréter des résultats obtenus. Les techniques permettant de les étudier vont de pair avec celles sur l’interprétabilité. Les points d’attention suivants, à destination des développeurs et data scientists, visent à mettre en lumière ces biais afin d’éviter de les renforcer, mais doivent être accompagnés et nuancés par une réflexion globale sur l’impact de l’algorithme et de sa criticité.
Quel choix de métrique à optimiser par l’algorithme ?
- Quel comportement cherche-t-on à modéliser ?
- Si l’objectif est de maximiser une variable, quel impact auront les décisions prises par l’algorithme sur ce comportement ?
Quelles données pour alimenter l’algorithme ?
- La distribution des données sur laquelle l’algorithme d’apprentissage est entraîné reflète-t-elle celle de la population sur laquelle l’algorithme va prendre des décisions lors de son utilisation?
Dans l’exemple suivant, on observe une différence entre la distribution des données sur lequel l’algorithme a appris un comportement, comparé à la distribution des données sur lesquelles il va être utilisé : les décisions qu’il prendra ne seront pas conformes à celles obtenus par son concepteur, car le comportement modélisé à l’apprentissage n’existe pas dans la réalité.
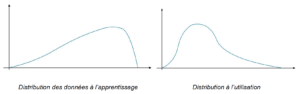
- Comment éviter qu’un exemple jamais observé durant l’apprentissage ne tombe dans une catégorie qui ne lui corresponde pas ?
Quelles sont les transformations à effectuer sur les données ?
- Les données transformées pour l’entraînement de l’algorithme reflètent-elles le comportement que je souhaite modéliser ?
- Si j’utilise des variables indirectes, pour mesurer des comportements non-observables directement, suis-je capable de déterminer dans quel cas l’information n’est pas présente dans la variable que j’observe ?
Quel est l’impact de l’implémentation choisie sur le comportement que je souhaite modéliser ?
- Quels sont les choix techniques effectués qui peuvent avoir un impact sur la prise de décision ?
- Si j’utilise une implémentation développée par une source tierce, suis-je en mesure de répondre à ces questions ?
Aussi les applications prédictives ont parfois des effets de bord moins immédiats.
Par exemple, des systèmes de recommandation qui permettent de prédire le contenu souhaité par les utilisateurs. Le danger de ce type d’algorithmes est d'enfermer l'utilisateur dans une bulle, où prolifèrent parfois des informations erronées voir dangereuses, ainsi que de créer une polarisation entre les individus, au fur et à mesure que ces boucles de rétroaction s’auto-renforcent.
Comment éviter de tomber dans ce piège ? Comment construire des cercles vertueux ?
Une étude des risques et des conséquences imprévues est nécessaire au préalable du développement de ce type d'algorithmes.
Comment assurer que l’algorithme ne produise pas de décision à l’encontre de mon intérêt ?
Un algorithme de maintenance prédictive prédisant une panne toutes les heures, sur chaque équipement d’une usine, va détecter 100 % des incidents. Pour autant, s’il prend la décision d’arrêter la production à chaque prédiction de panne, l’utiliser devient un désavantage. Pour garantir que les critères de l’algorithme ne rentrent pas en opposition avec les intérêts du concepteur ou du chef de produit, il peut être intéressant de produire un cadre de contrôle des décisions produites, qui peut s’implémenter à plusieurs niveaux :
- Lors de la conception, une étude de l’impact et de la criticité peut déterminer le degré d’attention nécessaire au suivi de l’algorithme. La participation à cette étude d’un panel large (chef de produit portant la vision à long terme, UX, data scientist, etc.) permet d’augmenter la taille de la matrice de risque pouvant en découler.
- Toujours lors de la conception, en étudiant et documentant les limites de l’algorithme (comment sont gérés les cas de faux positifs, sur quelles populations l’algorithme est le plus performant, quelles sont les populations à surveiller, …).
- La mise en place d’une boucle de feedback, en s’inspirant des méthodologies de software craftsmanship, permet d’accentuer le contrôle et d’affiner la stratégie de vigilance. Cette boucle se décline en pratique en un ensemble de métriques à collecter, analyser et raisonner sur l’utilisation de l’algorithme.
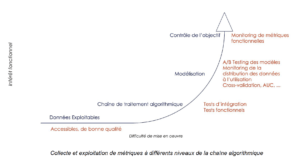
Enfin, pour garantir un fonctionnement cohérent en mode dégradé, il peut être intéressant de prévoir des actions lorsque les décisions prises ne sont plus conformes au cadre fonctionnel.
- Les données fournies pour l’apprentissage sont-elles encore cohérentes avec la population ciblée par l’algorithme ?
- Quelle solution puis-je mettre en place pour remplacer le service rendu par l’algorithme en attendant qu’il retrouve des performances convenables ?
En conclusion, l’intégration d’un système de traitement de données au sein de votre entreprise n’est pas une mince affaire et il y a de nombreuses questions à se poser pour éviter les pièges et faciliter son adoption.
L’équipe de RespAI se tient à votre disposition pour vous accompagner dans votre démarche responsable, dans sa définition comme dans sa mise en œuvre.