Optimisation du problème du voyageur de commerce par du Machine Learning :
Longtemps considéré comme la discipline reine alliant mathématiques appliquées et informatique dans l'industrie, l'optimisation combinatoire s'éclipse aujourd'hui dans l'ombre de son cousin le Machine Learning.
Au lieu de considérer les deux sujets indépendamment, nous vous proposons par le biais de cet article, un exemple de contribution du Machine Learning dans la résolution de l’un des problèmes les plus utilisés de l’optimisation combinatoire.
Les problèmes d’optimisation combinatoire constituent une classe de problèmes qui cherche à trouver la solution optimale parmi un ensemble fini de choix. Or, pour la plupart des problèmes de cette classe, la taille de l'espace de recherche croît de manière exponentielle avec la taille du problème en entrée, et la recherche d'une solution optimale exacte est généralement infaisable sur le plan informatique.
En raison de l'impossibilité de trouver des solutions exactes, dans la pratique, nous nous contentons d'utiliser des algorithmes heuristiques donnant des solutions proches de l'optimalité.
Ces heuristiques sont relativement rapides par rapport à une recherche exhaustive mais ne présentent aucune garantie théorique d'optimalité. Dans son papier “Machine Learning for Combinatorial Optimization: a Methodological Tour d’Horizon”, Bengio et al. pensent qu'il y a beaucoup à gagner en intégrant de plus en plus d'heuristiques issues du Machine Learning qui soient autant performantes dans le but de résoudre des problématiques de CO.
Ainsi, le but de mes recherches est de concevoir un algorithme innovant intégrant des techniques issues des deux domaines, optimisation combinatoire et Machine Learning, pour résoudre un problème à grande échelle.
Définitions et notations :
Le problème du voyageur de commerce (TSP) : Le problème du voyageur de commerce, en anglais Traveling Salesman Problem, est l'un des des problèmes d'optimisation combinatoire les plus connus.
Énoncé : Étant donné n points (des « villes ») et les distances séparant chaque point, trouver un
chemin de longueur totale minimale qui passe exactement une fois par chaque point et revient au point de départ.
Approche traditionnelle : Ce que j’appelle "approche traditionnelle" dans la suite du rapport représente une résolution classique d'un problème d'optimisation combinatoire sans inclure une éventuelle contribution d'un algorithme de machine learning.
Pour l'implémentation de cette approche, j'ai utilisé l'outil OR-Tools qui est un logiciel open source créé par Google entre 2010 - 2011 dans la volonté de se rapprocher du milieu universitaire. Ce logiciel est dédié à la résolution des problèmes d'optimisation combinatoire d'une manière traditionnelle/classique.
Hybridation ML et CO pour le problème du voyageur de commerce :
J’ai choisi d’orienter mon travail de recherche sur l’optimisation du problème du voyageur de commerce pour quatre raisons principales :
Les diverses applications dans l'industrie et le monde scientifique. En effet, le problème du TSP a plusieurs applications dans le marché, à titre d'exemple nous pouvons citer :
La logistique et la livraison en minimisant les trajets des véhicules.
La biologie dans le séquençage du génome.
Les communications en minimisant le temps de transmission des signaux.
L'essor de l'e-commerce et des livraisons Suite à la pandémie du Covid-19, la France a connu un essor du e-commerce. Entre 2019 et fin 2020, la part du e-commerce dans le commerce de détail est passée de 9.8% à 13% avec 40 millions d'acheteurs. Marc Lolivier, directeur général de la Fédération du e-commerce et de la vente à distance a imagé la progression du nombre de sites marchands par "Un nouveau site marchand toutes les demi-heures en 2020”. En effet, en 2020 le nombre de sites est passé de 165K à 182,5K.
L’impact écologique et sociétal : Dans la logistique, bien optimiser le trajet des conducteurs revient à leur offrir plus de confort et de réduire leurs horaires de travail. De plus, ceci entraînera la réduction des émissions CO2 des véhicules dans l'atmosphère.
L’impact environnemental du numérique : En plus de son utilisation fréquente dans l'industrie, le problème du TSP est un problème très challengeant. En effet, nous montrons dans la section suivante que la résolution de ce problème est très coûteuse en termes de calcul pour les grandes instances. Ceci signifie qu'il est très polluant numériquement. Ainsi, s'attaquer au problème du TSP et alléger les calculs réduit les émissions carbone émises.
Limites de l’approche traditionnelle avec OR-Tools :
Le problème du TSP n'est pas seulement un problème difficile à résoudre d'un point de vue théorique (NP-difficile), mais aussi d'un point de vue pratique. Les techniques de résolution du TSP s'avèrent être très coûteuses en termes de calculs.
Avec OR-Tools, la résolution se fait souvent en un temps exponentiel en fonction de la taille du problème en entrée. Le graphe de la figure 1 appuie la présente déclaration entre une taille d'instance de 100 localisations -à visiter- à 1500 localisations.
-Note : Dans la figure 1, je mesure le temps de résolution de plusieurs instances de TSP. Entre chaque deux mesures successives, nous gardons la même instance et nous lui rajoutons 100 positions à visiter. Comme la composition par le logarithme nous permet d’inverser la fonction exponentielle, le comportement linéaire du tracé du temps de résolution en échelle logarithmique nous permet de conclure qu’il a un comportement exponentiel.-
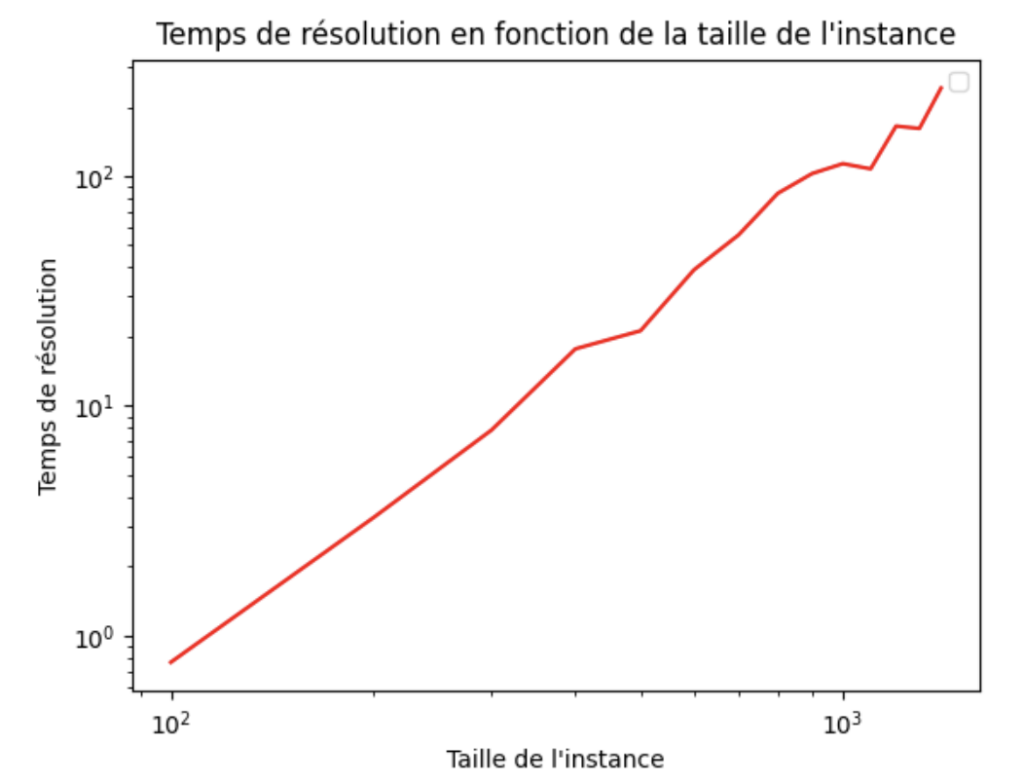
Figure 1 : Temps de résolution du TSP avec OR-Tools en fonction de la taille de l'instance en échelle logarithmique.
Ce qui rend le problème du TSP très challengeant pour un nombre de villes N relativement grand, c'est que la taille de l'espace de recherche est en N!. L'approximation de Stirling montre que la croissance de cet espace est exponentielle en fonction de N (N ~∞). La plupart du temps, l'utilisation d'heuristiques réduit le temps de calcul. Mais celui-ci garde son comportement exponentiel face à la taille de l'instance.
Methode Proposée :
L’intuition générale de la méthode proposée s’appuie sur la politique du diviser pour mieux régner. Supposons une instance avec 100 positions à visiter, ceci revient à chercher la solution dans un espace de cardinal 100! . Si nous divisons cette instance en 5 sous-instances différentes de même cardinal, nous obtenons pour chacune une solution dans un nouvel espace de cardinal 20!.
Obtenir ces 5 solutions en séquentiel revient à effectuer des opérations dans un espace de cardinal 5.20! . De ce fait, nous sommes passés d'un espace de cardinal 100! à un espace de cardinal 5.20!. Soit une réduction de 100!/ (5.20!).
Généralisons cet exemple, transformer un problème de taille N en k sous-problèmes, de taille approximative E(N/k) revient à chercher k solutions dans des espaces de taille E(N/k)! . De ce fait, on réduit la taille de l'espace de recherche de N.(N-1) ... (E(N/k)+1) car :
N! = N.(N-1) . . . (E(N/k)+1).E(N/k)!
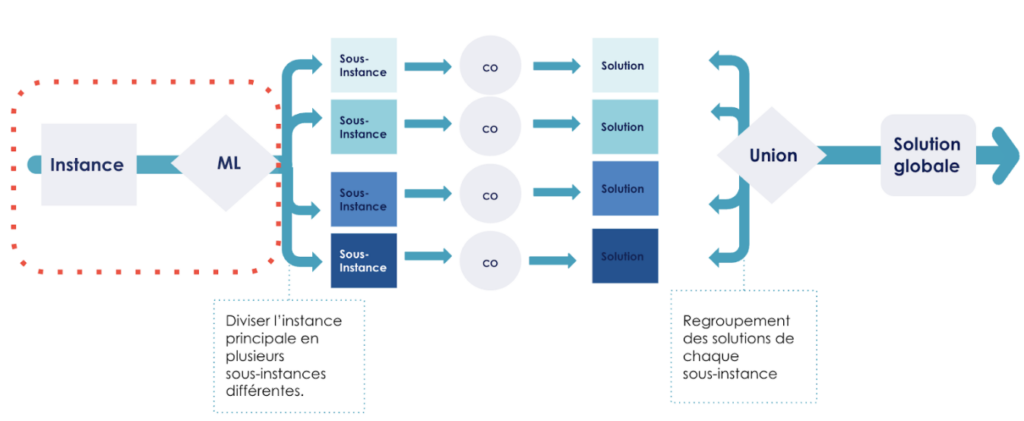
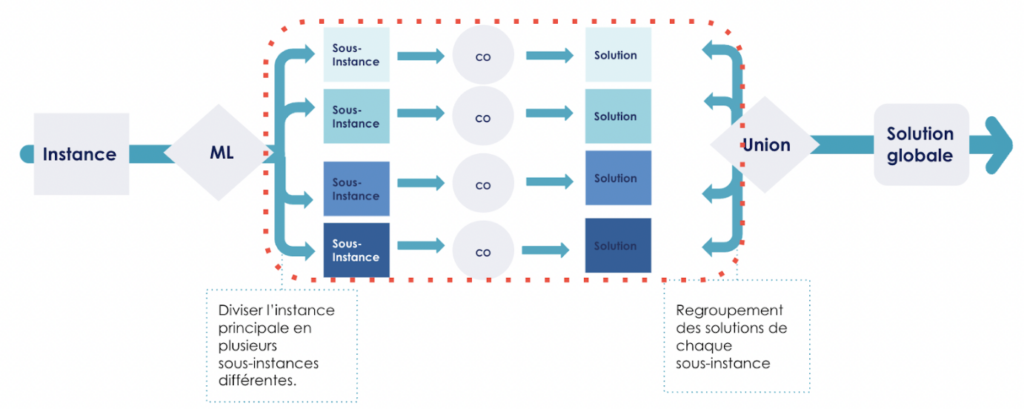
Ainsi la méthode que je propose se déroule en trois étapes : premièrement, la conversion de l'instance principale en plusieurs sous-instances différentes en faisant appel un algorithme de clustering ML . Deuxièmement, l’optimisation du problème du TSP sur K instances. Enfin troisièmement, le regroupement des solutions pour avoir le chemin à parcourir de l'instance principale.
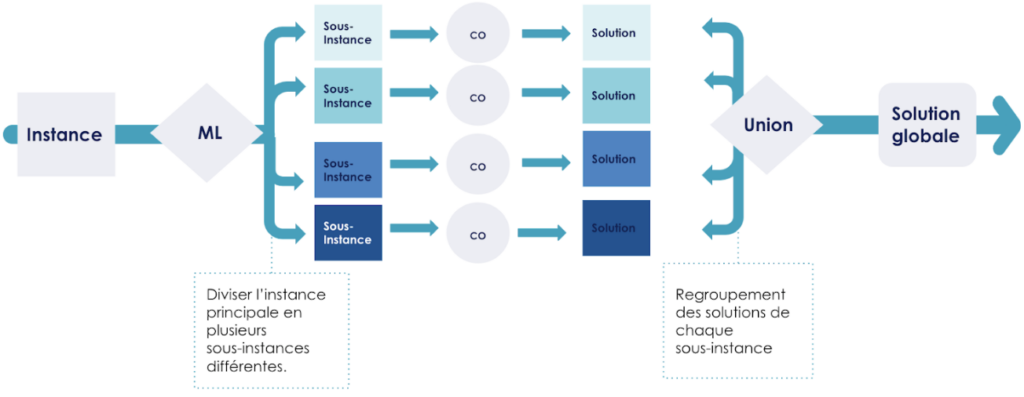
Figure 2 : Schéma visualisant l'approche avec Machine Learning.
Étape 1 : Clustering par la méthode des K-means
Le but de cette première étape est de diviser l'instance principale en plusieurs sous-instances.
Le problème du K-means est NP-difficile mais il existe des algorithmes d'approximation rapide tels que celui Lloyd ou Elkan que j'ai utilisé durant mon travail. L'implémentation de ces algorithmes est disponible dans la librairie sk-learn avec une complexité moyenne en O(k.n.T) avec :
k Nombre de clusters.
n Taille du jeu de donnée en entrée.
T Nombre d'itérations.
Il faut noter que la méthode du k-means n'a pas une tendance à égaliser les cardinaux des clusters. Toutefois, il existe des variantes de ce problème qui égalisent les tailles des clusters engendrés, et que je n'ai pas traités dans cet article.
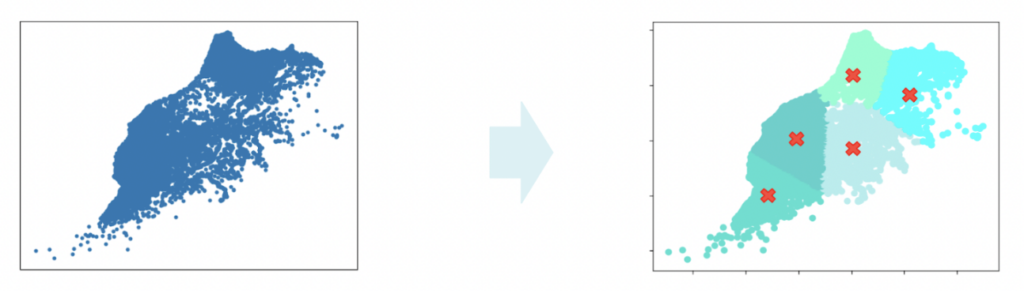
Figure 3 : Visualisation de la classification proposée par l'algorithme du k-means pour 5 clusters.
Étape 2 : Optimisation du TSP sur chaque cluster
En anticipant la prochaine étape, celle du regroupement, nous commençons par optimiser le problème du TSP sur les centroïdes de chaque cluster par l'approche traditionnelle. Le chemin que nous renvoie cette optimisation sera considéré comme un ordre de parcours des clusters.
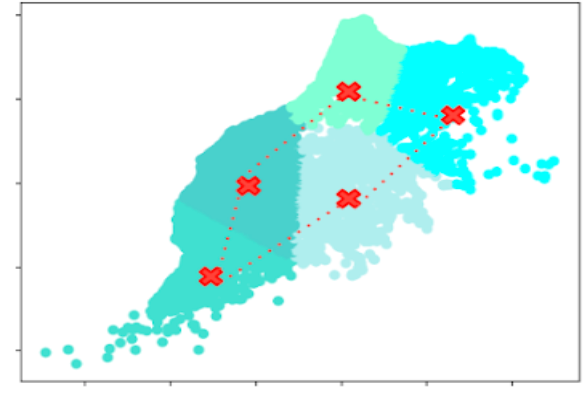
_Figure 4 : Visualisation de la résolution du problème du TSP sur les centroïdes de 5 clusters.
_
Une fois l'ordre de parcours mis en place, nous cherchons à trouver pour chaque paire de clusters successifs Sk et Sk+1 pour k = 1 … K-1, les couples de points (xk* , xk+1*) les plus proches avec xk∈ S~k ~ et xk+1∈ Sk+1. C'est à dire :
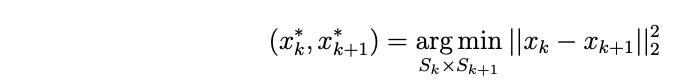
Finalement nous procédons à la résolution du problème du TSP sur chaque cluster par les méthodes traditionnelles. Cette résolution se fait sous deux contraintes additionnelles :
Le point de départ du parcours doit être le point le plus proche du cluster précédant.
Le point d'arrivée du parcours doit être le point le plus proche du cluster suivant.
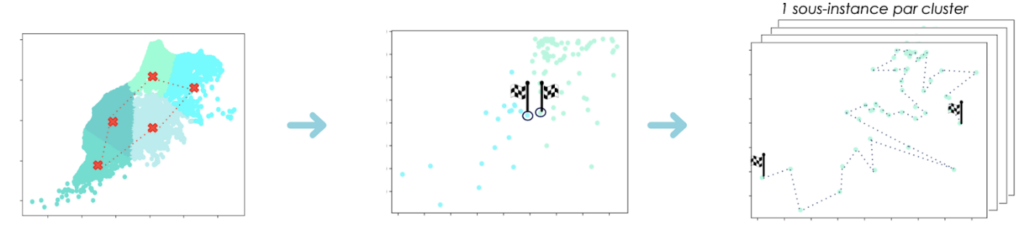
Figure 5 : Schéma illustrant les phases de l'étape de l'optimisation.
Étape 3 : Regroupement de la solution
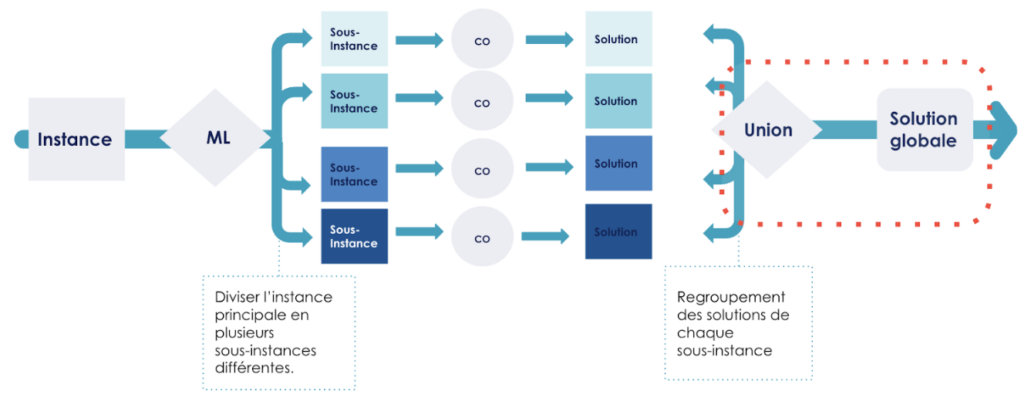
À ce point, nous avons un parcours optimisé à suivre pour chaque cluster, un ordre de parcours, ainsi qu'un point de départ et un point d'arrivée. Naturellement, nous relions ces parcours en ajoutant pour chaque cluster, une route entre son point d'arrivée et le point de départ du cluster qui le suit.
Bien qu'on ait considérablement réduit la taille de l'espace de recherche, nous n'avons aucune garantie sur l'optimalité de la solution que nous intégrons.
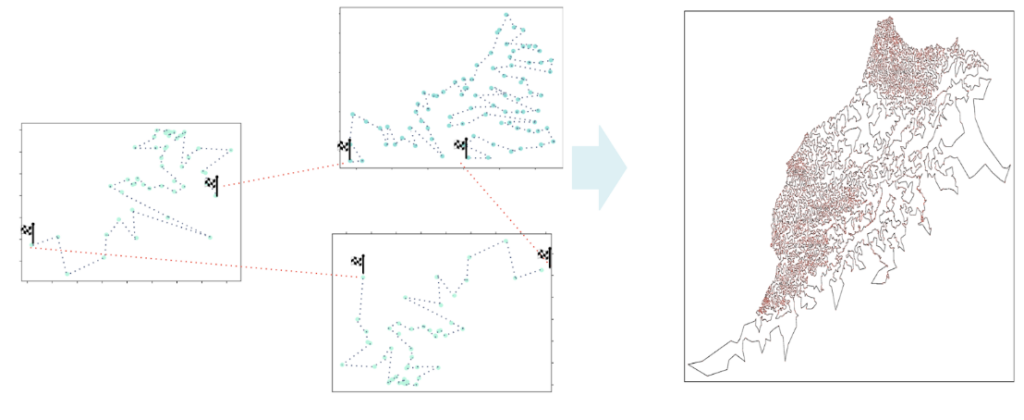
Figure 6 : Schéma illustrant l'étape du regroupement.
Applications et discussion des résultats :
Puisque nous approchons le problème du voyageur de commerce dans le but de réduire son temps de résolution, notre approche aura plus de sens sur des jeux de données de grande taille ; des tailles à partir desquelles la résolution avec des heuristiques traditionnelles prendrait plusieurs heures. Ainsi, nous pouvons remarquer sur la figure 1, que le temps de résolution du problème du TSP avec OR-Tools sur les datasets de grande taille devient assez vite grand. En effet, les tailles d'instances supérieures à 1200 positions à visiter nécessitent plus d'une heure de temps de résolution.
Nous utilisons des données issues d'un défi proposé par l'Université de Waterloo : 25 instances de TSP, où chaque instance représente un pays, composé d’entre 29 à 71 009 villes. Ces données ont été extraites de la base de données de l'agence nationale de l'intelligence géospatiale ( département de la Défense des États-Unis). Il s'agit donc de données réelles.
Nous appliquons notre démarche sur deux jeu de données :
| Instance | Taille | |
| Instance de taille moyenne | Maroc | 14k position à visiter |
| Instance de grande taille | Chine | 71k positions à visiter |
Dans cette section, nous comparons l'approche traditionnelle et l'approche avec ML sur les deux data sets présentés dans la section précédente.
Nous comparons ces deux approches sur la base de deux métriques :
La distance totale du parcours proposé. Elle se traduit par la valeur finale de la fonction objectif.
Le temps total de calculs pour obtenir une solution : Il comporte le temps de modélisation, de résolution et d'intégration pour l'approche traditionnelle. Pour l'approche avec ML, nous calculerons le temps du clustering, de la modélisation, de la résolution et de l'intégration de chaque cluster, en plus du temps de regroupement de la solution. Nous lisons ce temps à l'horloge grâce au module python timeit.
Les calculs ont été effectués en local sur une machine de 4 cœurs (2.3GHz). Les résultats présentés par la suite sont issus de 5 simulation indépendantes. Chaque simulation est une seed différente de l'algorithme du K-means.
Résultats obtenus sur le jeu de données de taille moyenne - Maroc :
Dans cette section, nous regardons de plus près les résultats obtenus sur l'instance du Maroc.
Dans le graphe de la figure 7, nous pouvons lire la moyenne des fonctions objectif avec un intervalle de confiance à 95% en fonction du nombre de clusters des 5 simulations. Aussi, la valeur de la fonction objectif de l'approche traditionnelle y est représentée comme une ligne horizontale constante car indépendante du nombre de clusters.
Nous pouvons constater que l'approche traditionnelle reste nettement plus performante que l'approche avec Machine Learning. Néanmoins, pour un petit nombre de clusters (<10), la perte en performance ne dépasse pas 5%. Plus intéressant encore, pour 5 clusters, la perte en performance avec l'approche ML est de 1%.
Cependant, quand le nombre de clusters devient grand (>50), la perte en performance dépasse les 10% en moyenne et la variance de la fonction objectif devient très grande.
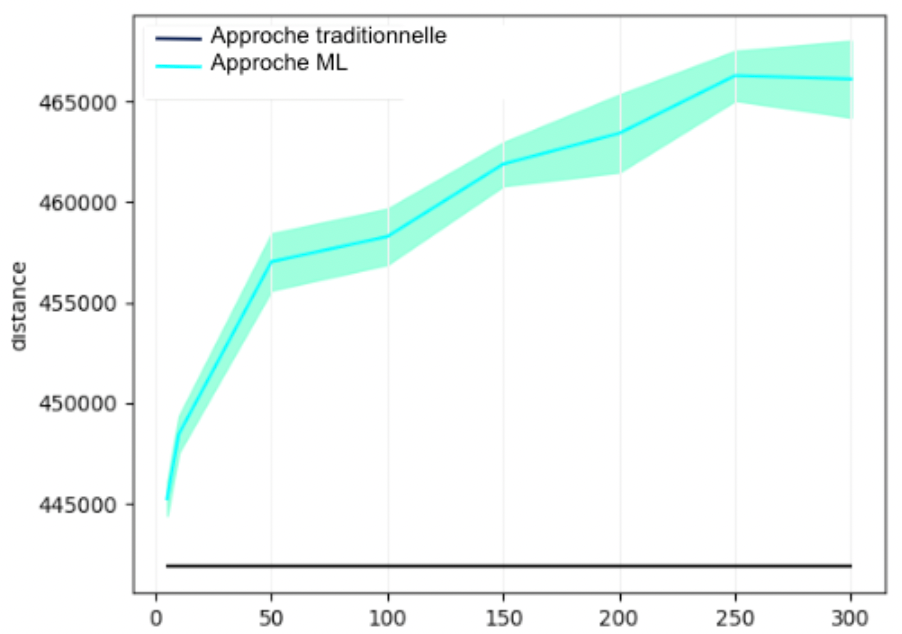
Figure 7 : Comparaison des distances moyennes des parcours proposés par les deux approches avec un intervalle de confiance à 95% sur l'instance : Maroc.
D'un autre côté, la figure 8 montre la différence entre le temps moyen de calcul des deux approches en échelle logarithmique. Il faut noter que le temps de calcul avec l'approche traditionnelle est de 11 heures, alors qu'avec l'approche avec machine learning, ce temps ne dépasse pas 1h40min en moyenne pour 5 clusters et descend à une quarantaine de minutes pour 10 clusters.
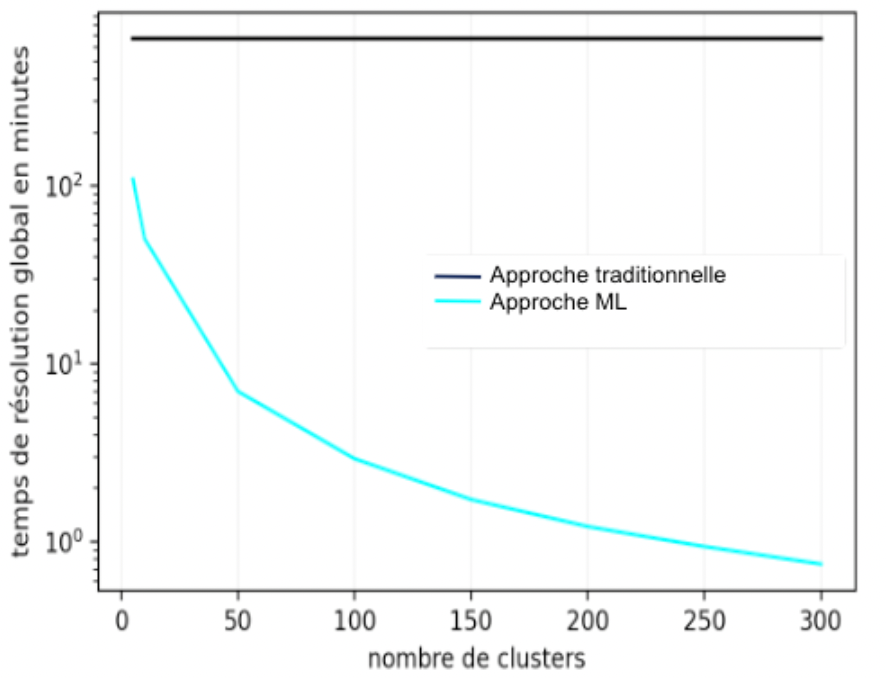
Figure 8 : Comparaison des temps moyens de calculs pour les deux approches avec intervalle de confiance à 95% en échelle logarithmique sur l'instance de Maroc.
La figure 9 montre le comportement du temps de calcul de l'approche machine learning sur une échelle linéaire. Nous pouvons constater qu'en plus de la perte significative en performances quand nous augmentons le nombre de clusters, le gain en temps de calcul devient très petit, voir insignifiant. Nous ne gagnons pas plus de 7 minutes en moyenne en passant de 50 à 300 clusters et moins d'une minute en passant de 150 à 300 clusters.
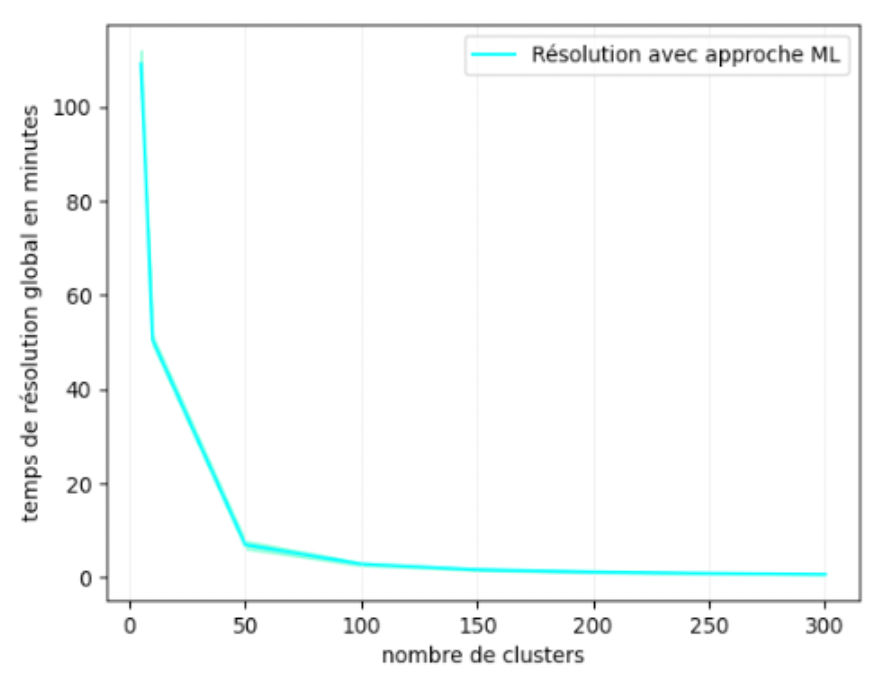
Figure 9 : Temps moyen de résolution avec intervalle de confiance à 95% pour l'approche ML sur l'instance de Maroc.
Résultats obtenus sur le jeu de données de grande taille - Chine
Concernant l'instance Chine, l'approche traditionnelle ne fournit pas de solution dans des temps raisonnables. En effet, même après 15h de calculs, le solver d'OR-Tools ne fournit pas de solution à l'instance.
Face à ce problème, j'ai essayé de comparer les deux approches sous un autre angle : limiter le temps de recherche en profondeur à une heure et de baser ma comparaison sur la solution intermédiaire qui sera fournie par l'approche traditionnelle. Après 8h de calcul, l'exécution du programme s'achève sans fournir aucune solution intermédiaire. De plus, le temps de modélisation avec l'approche traditionnelle à lui seul s'élève à 69 minutes. Ce temps dépasse le temps de résolution total avec l'approche ML sur 200 clusters qui se situe autour de 61 minutes en moyenne.
La figure 10 et la figure 11 représentent respectivement la distance moyenne du parcours proposé par la solution et le temps moyen de calcul de l'approche avec machine learning sur les 5 simulations, et ce en fonction du nombre de clusters. Pour cette instance, nous faisons varier le nombre de clusters entre 200 et 700.
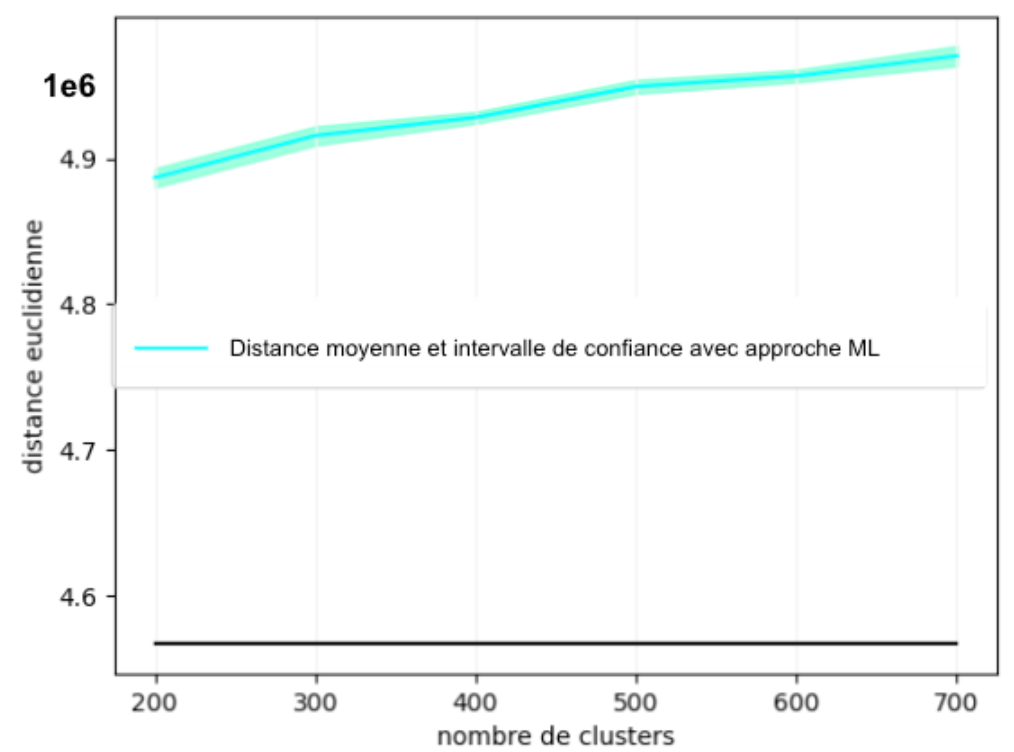
Figure 10 : Distance moyenne des parcours proposés par l'approche ML avec un intervalle de confiance à 95% sur l'instance : Chine.
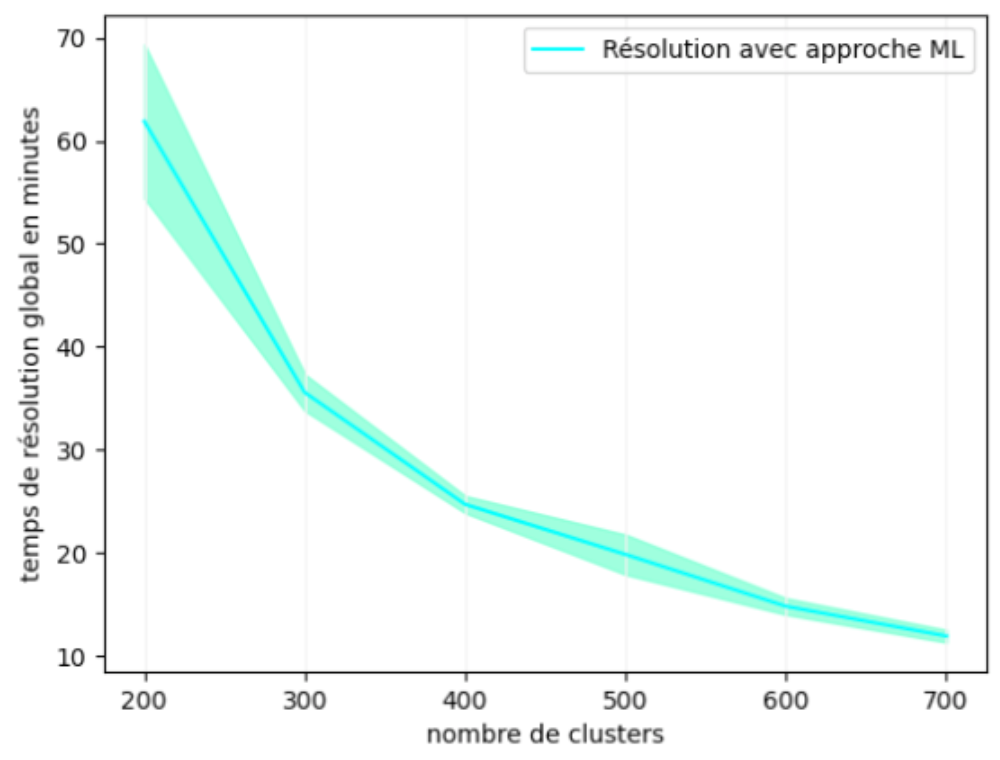
Figure 11 : Temps de résolution moyen avec un intervalle de confiance à 95% pour l'approche ML sur l'instance : Chine.
Nous remarquons sur ces graphes, qu'à l'encontre de l'instance de taille moyenne, le gain en temps de calcul reste significativement grand en augmentant le nombre de clusters. En effet, on arrive à réduire de 6 fois le temps de calcul entre 200 et 700 clusters. La perte en performance quant-à-elle, reste inférieure à 10%.
Conclusion :
Pour conclure, s'attaquer à des problèmes d'optimisation combinatoire s'avère souvent difficile. Dans ce contexte, les méthodes traditionnelles ne garantissent pas toujours l'optimalité, et le temps de calcul peut parfois s'étaler longuement. C'est pourquoi, en inventant des heuristiques avec des approches de machine learning, on arrive à gérer ces problèmes. Ainsi, on parvient à réduire considérablement le temps de résolution sans toutefois perdre beaucoup en performances. De ce fait, nous avons rendu compte de l'utilité et de la robustesse de ces méthodes dans des applications industrielles à travers deux exemples : un premier jeu de données de taille intermédiaire pour lequel l'heuristique combinant ML et CO fournit des résultats plus que satisfaisants et un deuxième jeu de données de taille très grande pour lequel on arrive à trouver une solution là où l'approche traditionnelle peine à arriver au bout du calcul dans un temps raisonnable. Enfin, il est important de noter que l'hybridation ML et CO repose sur un compromis entre performances légèrement réduites et temps de calcul nettement amélioré. Et que cela, advient en jouant sur le choix de la méthode du clustering ainsi que sur le nombre de clusters.
Sources et liens utiles :
Jeux de données du TSP utilisés : National Traveling Salesman Problems (uwaterloo.ca)
Doc OR-Tools : OR-Tools | Google Developers
Remerciements : Paul-Émile Morgades, Mohamed-Taha Abdelmoula et Ayoub Samaki pour leur relecture et nombreux commentaires.