OpenShift 3 : le PaaS privé avec Docker
![]()
La genèse de la version 3
Depuis juillet 2014, OpenShift s’est lancé dans un vaste et ambitieux projet de refonte de son architecture en vue d’intégrer en son sein - les désormais incontournables - Docker et Kubernetes.
Pour OpenShift, lancer ce projet il y a 1 an était particulièrement audacieux, et constituait une stratégie risquée. Alors que la course avec Cloud Foundry battait son plein, OpenShift a choisit de se lancer dans un long chantier de refonte technique au détriment de l’enrichissement fonctionnel de son produit et de la compatibilité avec la précédente version. Nous pensons, aujourd’hui qu’ils ont fait le bon pari.
A date, le projet Origin regroupe 74 contributeurs sur Github dont les 10 plus actifs travaillent tous chez Red Hat. Cette communauté plutôt active, a réalisé 15 itérations en 11 mois et vient de rendre disponible sa version bêta 3 qui est déjà très prometteuse. Une première release candidate est attendue pour fin juin 2015 pour OpenShift Enterprise.
Bien que la solution soit principalement portée par Red Hat, elle repose fortement sur Kubernetes (de Google). Ceci pose la question de la gouvernance qui n'est pas forcément triviale et qui dépend de la bonne entente et de l'alignement des visions des deux entreprises. Qu'adviendra-t-il des nouvelles fonctionnalités poussées par Google : viendront-elles enrichir Kubernetes au détriment d'OpenShift? Visiblement, la question n'est pas encore tranchée.
Toutefois, si le soutien de Google se confirme, une gouvernance bicéphale de ces géants ne pourra être que bénéfique à OpenShift. Il permettra de confirmer l'avance prise sur la concurrence de Docker Enterprise (Machine, Compose et Swarm).
Construire et déployer automatiquement ses applications : le fonctionnement
OpenShift v3 offre nativement 3 modes de construction automatisée d’une application :
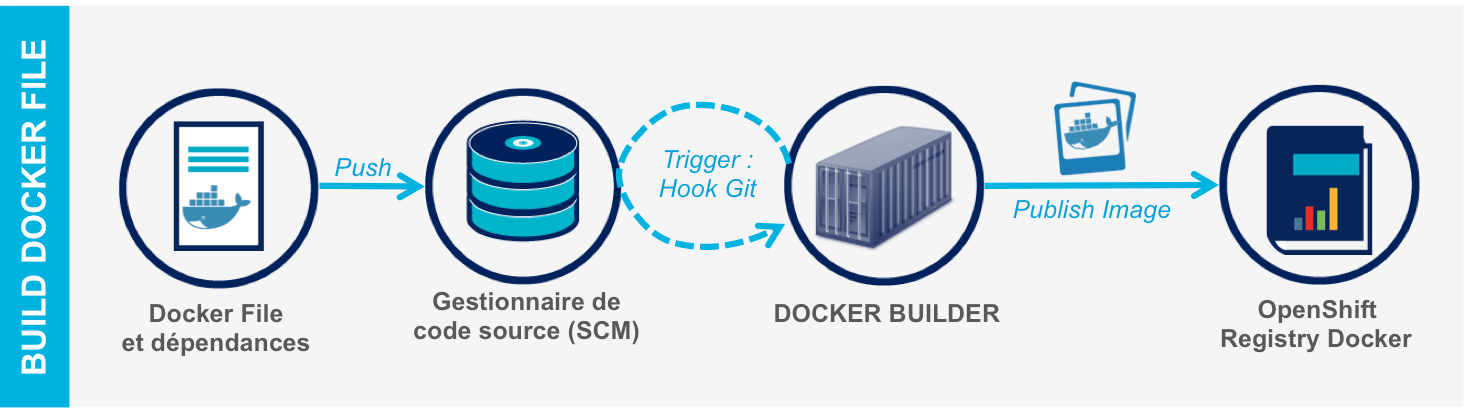
- Le mode Docker-File : permet de construire automatiquement un container Docker en fournissant à OpenShift l’adresse d’un gestionnaire de code source pointant sur un Docker-File et ses dépendances.
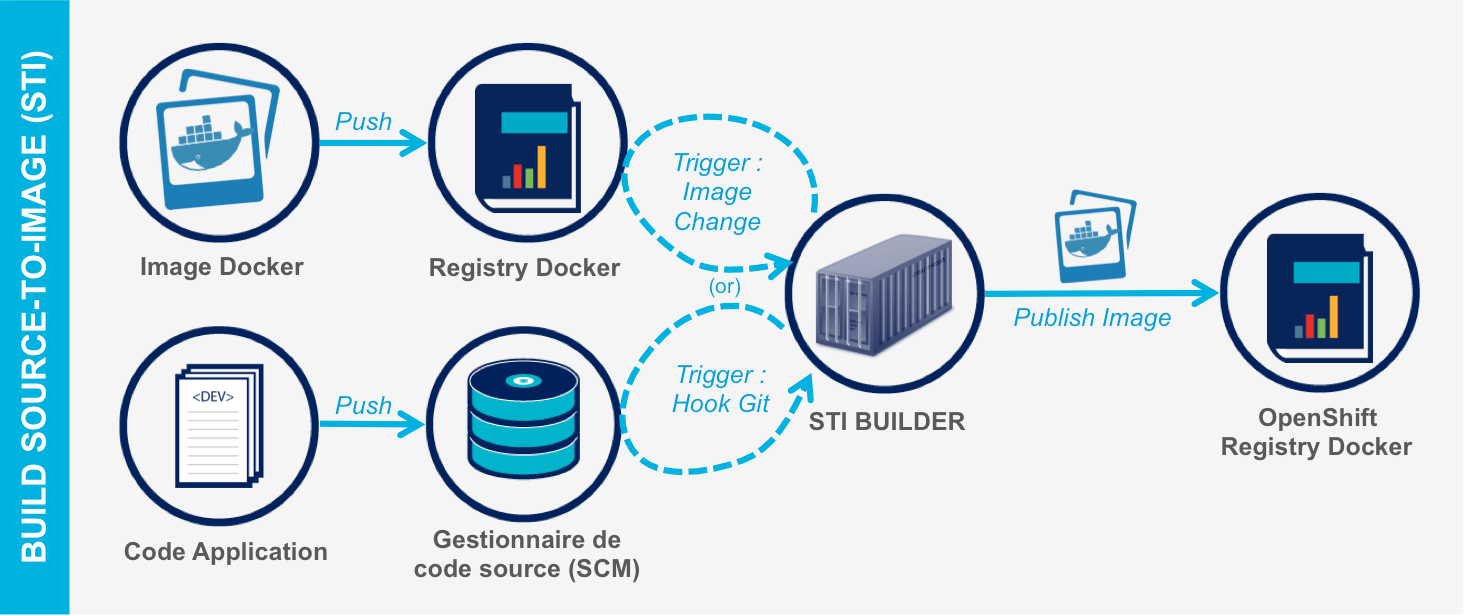
- Le mode Source-To-Image (STI) : permet de construire automatiquement une application en poussant le code source applicatif dans OpenShift (à l'instar des buildpacks dans Heroku).
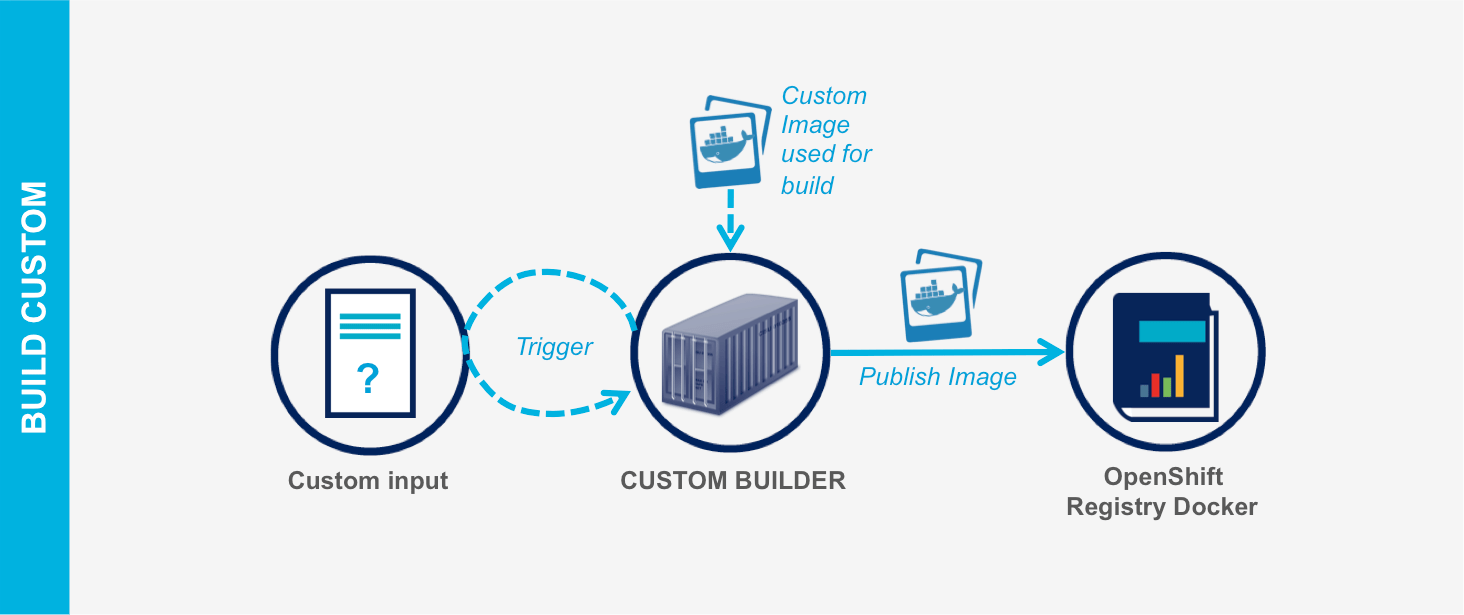
- Le mode Custom Build : permet de fournir sa propre logique de build d'une application en fournissant à OpenShift une image Docker conçue à cet effet.
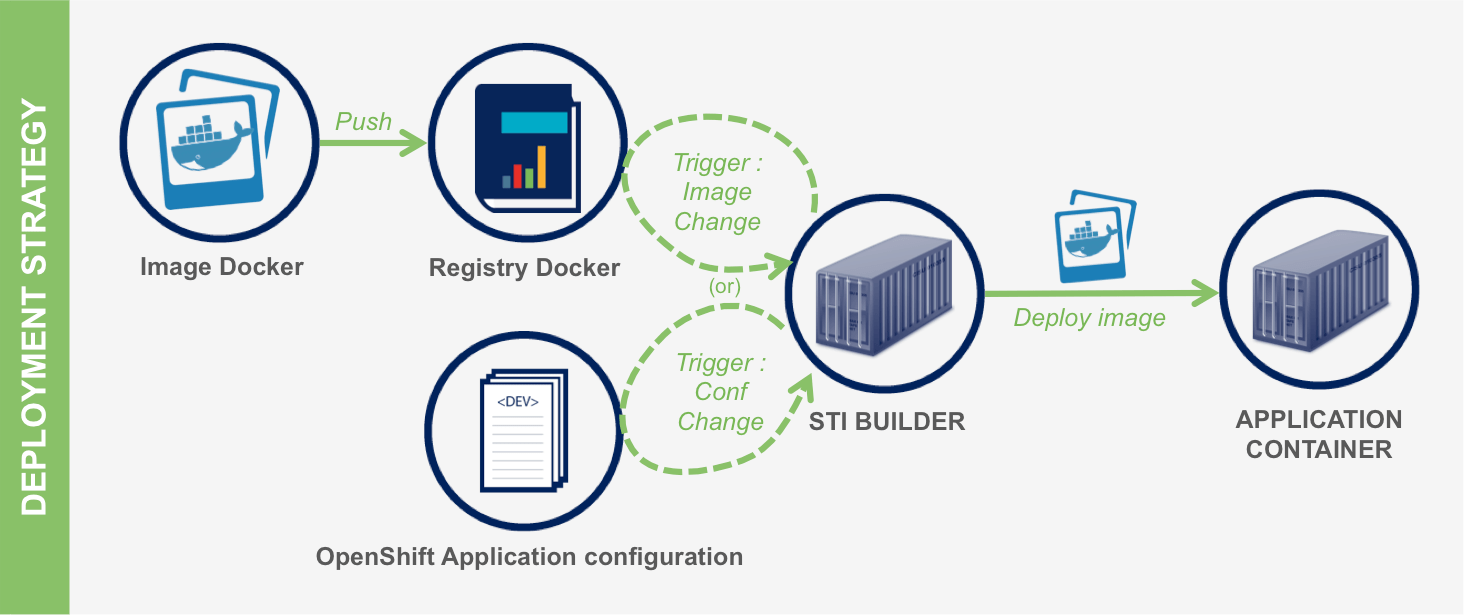
OpenShift 3 permet aussi de définir une stratégie de déploiement automatisé d'une application lorsque qu'une nouvelle version d'image est publiée dans la registry ou lorsque que la configuration de l'application est mise à jour.
En complément de ces modes de build et de déploiement, OpenShift 3 offre la possibilité de définir ses propres « blue prints » applicatifs sous forme de fichiers « templates » au format Json ou Yaml. Ces « blue prints » décrivent à la fois la topologie de l’architecture de l’application et la politique de déploiements des containers. Le schéma ci-dessous illustre l’assemblage des différents composants d’un « template » d’une application 3-tiers dans OpenShift.
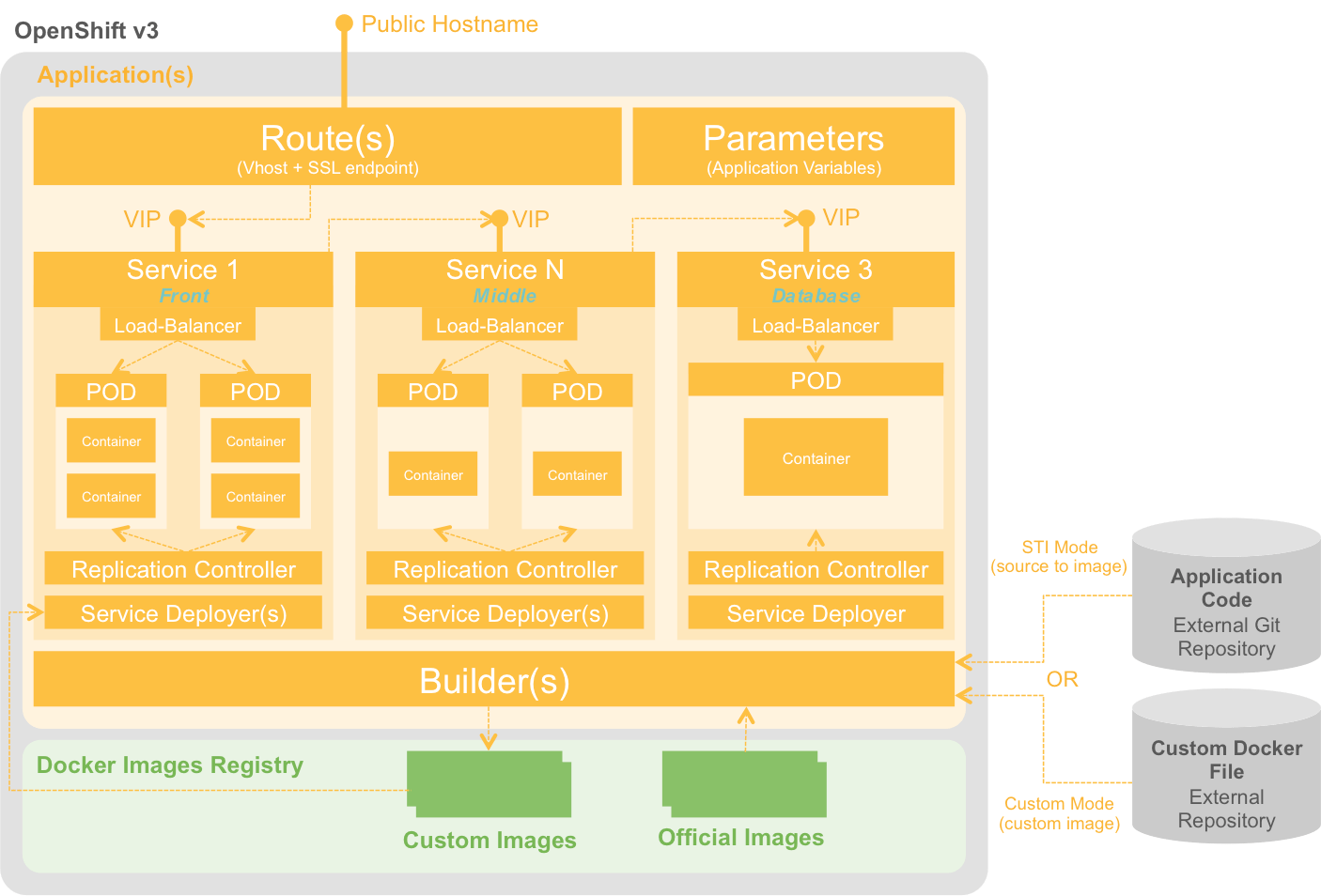
Les différents composants assemblés dans un « template » sont en partie hérités des concepts de Kubernetes. Les principaux objets à retenir sont les suivants :
- Un « POD » est un environnement d’exécution de container(s) Docker local à un serveur (on déploiera deux types de containers sur un même POD s’il est nécessaire de partager des ressources locales).
- Un « Service » est un point d’entrée (VIP) rendant abstrait un accès « load-balancé » à un groupe de containers identiques. En principe, on déploie un Service par tiers de l’architecture.
- Un « Service Deployer » ou « Deployment Config » : est un objet qui décrit une politique de déploiement d’un container sur la base de triggers (par exemple : redéployer lorsqu’une nouvelle version d’une image est disponible dans la registry Docker)
- Un « Replication Controller » est un composant technique en charge de la résilience des POD
- Une « Route » expose un point d’entrée (DNS hostname ou VIP) à l’extérieur d’une application
Grâce à ses différents mécanismes de déploiement et à la possibilité de définir ses propres « blue prints », OpenShift v3 se plie aux architectures applicatives les plus complexes et exigeantes.
Sous le capot : une architecture élégante
Le déploiement d’une infrastructure OpenShift 3 peut se faire soit de manière standalone (en déployant l’image Docker suivante : « openshift/origin »), soit de manière distribuée en utilisant les playbooks ANSIBLE fournis par OpenShift. Dans ce dernier cas, on déploie sur des serveurs des rôles de type « Master » ou de type « Node ».
Les nœuds de type « Master » servent à la fois à :
- traiter les requêtes à l’API d’administration (en provenance du CLI ou du portail Web)
- réaliser les opérations de build des images et de déploiement des containers
- assurer la résilience des PODs (réplication)
Les « Masters » utilisent un annuaire distribué etcd pour le partage de configuration et la découverte des services.
Les « Nodes » hébergent les PODs et exécutent des containers (application et/ou Registry).
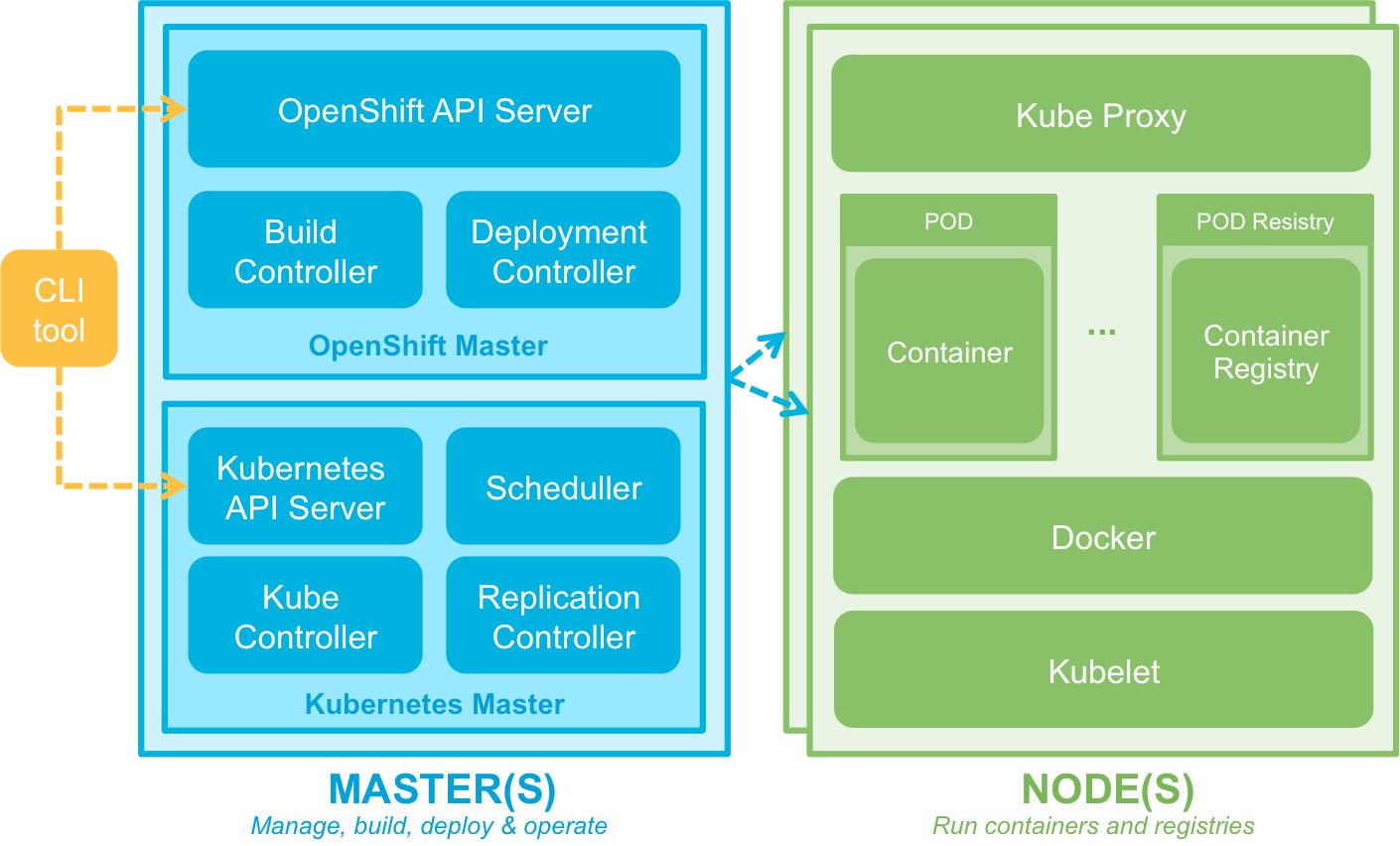
L’architecture ainsi proposée est à la fois distribuée, scalable et résiliente. Le seul bémol concernant le passage à l'échelle : le provisionnement et la gestion de la capacité des serveurs sous-jacents restent à réaliser manuellement pour le moment.
Il est possible d’interagir avec la plateforme au travers de son API REST, en CLI ou via son portail Web (uniquement en lecture seule, pour le moment).
Le point de vue d’OCTO
OpenShift 3 propose une passerelle intéressante du monde du « Platform-as-a-Service » vers le monde du « Container-as-a-Service » (CaaS). La solution proposée par Red Hat est audacieuse et son architecture est à l'état de l'art. Nous apprécions particulièrement le format de spécification des « blue prints » d’architecture et d’orchestration de déploiement.
Dans sa version actuelle (bêta 3), OpenShift met peu l’accent sur l’exploitabilité de la plateforme. Il faudra donc attendre encore un peu avant de l’employer en production. Toutefois, on retrouve à la roadmap des user stories à ce sujet :
- concentration de log avec ElasticSearch-Logstash-Kibana ou Fluentd
- monitoring avec Heapster,
- métrologie,
- facilités pour le déploiement de clusters.
Apprendre à modéliser une application dans OpenShift 3 constitue selon nous, un nouveau métier et à ce titre requiert de nouvelles compétences afin de se poser les bonnes questions : Comment organiser les conteneurs? Faut-il utiliser des routes ou des services? Comment gérer les données (persistence, réplication, sauvegarde)? Comment gérer le multi-tenant? Que devient mon usine de développement et de déploiement (UDD)?
En synthèse, cette solution de PaaS privé s'annonce très prometteuse. Elle permet de réduire le time to market en automatisant dès le début du projet, les processus de construction et de déploiement d'une application. Elle est compatible avec les architectures Web les plus complexes, bien que les problématiques de la gestion des données et de l'intégration avec des services externes ne soient que partiellement adressées pour le moment.
Nous croyons qu'Openshift 3 a tout pour s'imposer sur le marché comme la référence en matière de PaaS privé basé sur Docker.
Pour aller plus loin : http://fr.slideshare.net/NewHopeKim/open-shift-and-docker-october2014