Open-source analytics on MongoDB, with Schema
Victoire ! Votre nouvelle application rencontre un grand succès ! Elle collecte des données précieuses, stockées dans MongoDB. L’heure est venue de les analyser pour en tirer profit ! Malheureusement, vos analystes se trouvent bien démunis avec leurs outils SQL favoris... Mais où est donc déclaré le schéma des données ?
Confrontés à de telles difficultés, nous avons assemblé, complété, et mis en production une plateforme qui vous aidera à analyser vos données MongoDB. La solution retenue consiste à synchroniser en temps réel les données stockées dans MongoDB vers une base PostgreSQL en leur appliquant au passage un schéma relationnel. On retourne alors dans le monde bien connu des analystes et de leurs outils.
Persuadés que cette solution répond à un besoin fréquemment exprimé, nous proposons une plateforme intégrant l’ensemble des services nécessaires pour :
- extraire le schéma NoSQL source,
- synchroniser vos données vers PostgreSQL,
- visualiser le nouveau schéma relationnel,
- et analyser les données dans une interface web de Business Intelligence (BI).
Cette plateforme est basée sur des containers Docker, orchestrés par Docker Compose. Un script de haut niveau permet de lancer une démonstration sur des données publiques. Vous pouvez également y connecter vos données en quelques commandes.
Si vous souhaitez tester sans attendre, direction le répertoire github : mongo_sql_analytics_platform.
Pour ceux qui préfèrent les belles images aux articles de fond, voici une présentation (vidéo) réalisée à PyParis 2017 : “Open-source analytics on MongoDB, with Schema”.
MongoDB, un choix de plus en plus fréquent
De plus en plus d’applications utilisent MongoDB pour stocker leurs données. Ce Système de Gestion de Bases de Données (SGBD) présente en effet de nombreux avantages pour les développeurs.
- MongoDB n’impose pas de schéma sur les données à l’écriture. Cette flexibilité simplifie l’évolution du modèle de données, et donc de l’application.
- MongoDB stocke très naturellement des données au format json, qui est le format d’échange par excellence entre applications.
- C’est une solution open-source, moderne, soutenue par une communauté active.
En conséquence, MongoDB a continuellement gagné en popularité au cours des 5 dernières années, au point d’égaler aujourd’hui d’autres SGBD open-source phares tels que Postgresql (source).
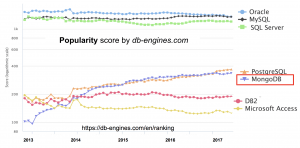
Avec une telle popularité, les analystes sont de plus en plus souvent amenés à travailler sur des données stockées dans MongoDB. Or si ce SGBD est populaire chez les développeurs, ce choix engendre des défis importants pour les analystes.
Dans notre contexte, MongoDB était trop intégré dans l’architecture de l’application pour être remis en cause. C’est la raison pour laquelle une solution de synchronisation des données avec une nouvelle base est proposée ici. Dans la suite de l’article, nous prendrons l’hypothèse qu’une migration vers une base de donnée relationnelle n’est pas envisageable.
Nous souhaitons cependant attirer l’attention sur la nécessité de ne pas sous-estimer ces défis lors du choix initial du SGBD de votre application, en particulier quand l’analyse des futures données stockées représente un véritable enjeu.
Les mondes parallèles du développeur et de l’analyste
Prenons un peu de temps pour comprendre en quoi le choix d’un SGBD non relationnel peut compliquer le travail de l’analyste.
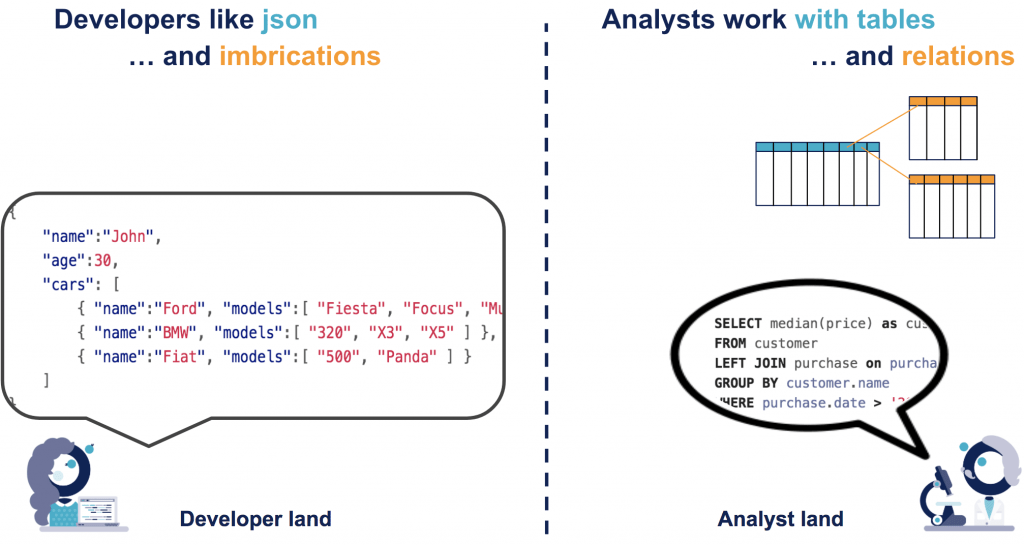
Do you speak JSON or SQL ?
La première difficulté vient du langage de requête, et de la forme des données.
Pour les développeurs, JSON est un format pratique pour créer des objets et les manipuler. Ils apprécient les API modernes de MongoDB, disponibles dans de nombreux langage de programmation.
Les analystes sont en revanche profondément habitués à manipuler des tables, que ce soit pour filtrer des données ou agréger des statistiques. Ils savent utiliser le langage de requêtes SQL pour manipuler ces tables. De plus, la plupart des outils de BI ont été développés pour accéder à des bases relationnelles. Rares sont ceux proposant des connecteurs complètement intégrés vers des bases MongoDB (cf plus plus bas : “MongoDB Connector for BI”). Enfin, pour parler d’usages innovants, c’est généralement un format tabulaire qu’il faudra fournir aux modèles de Machine Learning.
En conséquence, une formation est nécessaire aux analystes pour se familiariser avec ce nouveau langage de requêtes. Des outils spécifiques doivent être appréhendés, voire développés, pour continuer à valoriser les données stockées.
Si ces arguments vous semblent à contre-courant, voici un excellent article qui détaille les raisons du succès de SQL voici plus de 40 ans, et pourquoi il revient en force aujourd’hui. L’argument central est que SQL est l’interface universelle pour accéder à des données. Il est maîtrisé par une vaste classe d’utilisateurs qui ne sont pas des développeurs professionnels et l’algèbre relationnelle sur laquelle se base SQL est sans équivalent pour filtrer des données et agréger des statistiques.
La marque de la troisième voiture de Jean Neige
Deuxième enjeu : la structure de stockage des données NoSQL permet l’imbrication plus ou moins profonde des objets et des listes. Cette approche s’éloigne fortement des formes normales, chères aux bases de données relationnelles, avec leurs tables liées et leurs puissantes jointures. L’analyste ne manipulant ses données qu’avec des tableaux, il se retrouve fort dépourvu face à des listes imbriquées dans un objet.
Das Model
Troisième difficulté : la majorité des bases MongoDB sont configurées sans spécifier de schéma. Aucune contrainte sur la structure des données n’est appliquée par la base au moment de l’écriture.
Or un schéma est indispensable au travail des analystes. Une schéma est une API d’accès aux données. C’est une cartographie pour comprendre ce que les données contiennent. Et c’est un contrat sur la structure des données, nécessaire pour produire des analyses robustes.
Bien sûr, la “structure” des données est formalisée - d’une façon ou d’une autre - dans le code de l’application. Cette structure est pensée par les développeurs, pour les développeurs. C’est à dire dans le langage de programmation de l’application, via des couches d’abstractions entre les objets manipulés et les documents Mongo (par exemple via mongoengine).
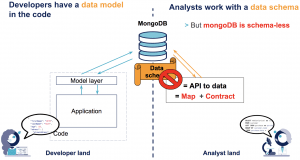
Cette structure n’est donc pas accessible aux analystes. Lorsqu’ils travaillent sur une base MongoDB, ils n’ont pas d’autre choix que de parcourir quelques éléments pour “découvrir” le modèle des données. Cependant, il n’est pas garanti que le schéma ainsi découvert sur un échantillon soit généralisable à l’ensembles des éléments.
La librairie pymongo-schema que nous mettons à disposition en open source résout ce problème d’extraction du schéma des données MongoDB (cf plus bas).
Les alternatives
Avant de présenter notre solution, discutons d’abord des alternatives.
La première réponse est de confier l’analyse des données à des développeurs. Ils pourront mettre à profit les puissants pipelines d’agrégation de MongoDB. Ce choix peut sembler naturel selon votre organisation. Il suppose que les développeurs ont des compétences en statistiques, analyses et visualisations de données; ou que les analystes soient de bons développeurs : cette combinaison de compétences est assez rare. En pratique, cette solution immédiate restreint vos données à une classe limitée d'utilisateurs et d'usages.
Une autre réponse est d’utiliser la solution de MongoDB Enterprise : MongoDB Connector for BI. Son principe est d’exposer une interface SQL devant MongoDB, en convertissant à la volée les requêtes et les résultats (cf la documentation et notre schéma ci-dessous). L’intérêt de cette solution est qu’elle est officielle et supportée. Elle permet notamment d’y connecter l’outil de BI commercial Tableau.
Le principal inconvénient de MongoDB Connector for BI est que son intégration est limitée. Il est possible d'y connecter un client MySQL, Tableau ou Qlik Sense, mais vous rencontrerez certainement des difficultés pour connecter d'autres outils (ex Superset). Par ailleurs, ce connecteur nécessite l’achat d’une licence MongoDB Entreprise. Enfin, le traitement des requêtes se fait en boîte noire. Il sera par conséquent difficile d’optimiser les requêtes en cas de performances insuffisantes.
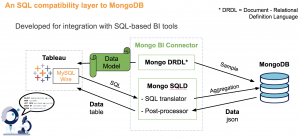
Description du fonctionnement de MongoDB Connector for BI
Une dernière alternative est d’utiliser un outil ETL capable de synchroniser les données de MongoDB vers une base relationnelle. Nous avons par exemple identifié StichData et Talend, mais n’avons pas réalisé une étude exhaustive. Ces outils fonctionnent sur le même principe que notre solution open-source, et nécessitent des étapes similaires. Ils n’utilisent pas la brique mongo-connector, et réimplémentent des mécanismes de réplication. StichData propose par exemple une synchronisation par micro-batch, en s’appuyant sur une clé de réplication.
Suivez le lapin blanc sous le capot
Au cours d’une mission, nous avons été confrontés à la séparation entre les mondes parallèles de l’analyste et du développeur. Pour passer d’un monde à l’autre, nous avons entrepris de développer une solution open-source permettant d’utiliser les outils d’analyses habituels sur des données issues d’une base MongoDB.
Le principe ? Synchroniser en temps réel la base MongoDB vers une base PostgreSQL. Cette dernière pourra être utilisée comme data warehouse, sur laquelle connecter des outils d’analyse de données.
Derrière la simplicité apparente de la solution annoncée se cache la complexité de la transition entre deux structures de données foncièrement différentes. Il est en effet nécessaire de désimbriquer un modèle de données qui n’est pas connu a priori.
Pour ce faire, nous avons eu recours à trois briques open-source complémentaires :
- mongo-connector : développée par MongoDB Labs, permettant de synchroniser les modifications d’une base de données MongoDB source vers une base de données cible
- mongo-connector-postgresql : librairie développée par Malt, permettant de traduire ces modifications en requêtes SQL à partir d’un fichier de mapping
- pymongo-schema : développée par notre collectif, permettant de générer le fichier mapping en question à partir de l’analyse de la base source.
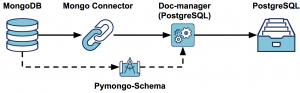
mongo-connector
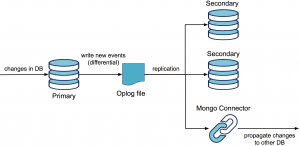
mongo-connector est donc la brique principale, qui synchronise la base MongoDB source vers une base cible.
Le fonctionnement est similaire à la synchronisation d’un membre du replica set. Une première phase de remplissage est réalisée via un transfert complet des collections de la base source. La synchronisation en temps réel est ensuite assurée par la lecture continue du fichier oplog, qui stocke les dernières modifications.
mongo-connector-postgresql
La brique mongo-connector est agnostique de la base cible vers laquelle elle propage des modifications. Pour traduire les instructions dans le langage cible, elle utilise une librairie dédiée selon la base, appelée “doc-manager”. Des doc-manager sont déjà intégrés pour des bases cibles NoSQL : MongoDB bien sûr, mais aussi SolR et ElasticSearch.
Malt a développé un doc manager pour PostgreSQL - mongo-connector-postgresql -, auquel nous avons contribué en ajoutant des tests et en corrigeant des bugs. Cet outil écrit des requêtes SQL pour propager les instructions des modification de Mongo. La complexité réside dans le fait qu’il faille passer de la structure imbriquée des données de MongoDB vers une forme relationnelle.
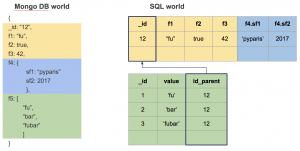
Passage d’une structure imbriquée à une structure relationnelle
Ce travail nécessite notamment de transformer les listes imbriquées (de valeurs ou d’objets) en des tables liées. Cette correspondance entre les structures Mongo et Postgres est spécifiée par l’utilisateur, via un fichier mapping.json.
pymongo-schema
Ce fichier de mapping peut être écrit à la main. Cela nécessite toutefois de :
- connaître le modèle des données dans MongoDB,
- ne pas se tromper dans la correspondance entre objets imbriqués et tables liées.
Ce processus manuel est long, source d’erreur et difficile à maintenir. En conséquence, nous avons développé la brique pymongo-schema, qui permet d’automatiser la génération de ce fichier de mapping.
Pymongo-schema s’utilise en 2 étapes :
- Le schéma de la base MongoDB est extrait dans un fichier, par un parcours exhaustif de la base. Pour chaque collection, on liste l’ensemble des champs rencontrés, en gardant la structure imbriquée et le type.
Sans parler d’analyse de données, ce schéma est très utile pour connaître l’état d’une base MongoDB. Pymongo-schema peut s’utiliser indépendamment pour cette seule fonctionnalité. Des formats de sortie variés sont d’ailleurs proposés pour ce fichier : json, csv, excel, markdown ou encore html.
- Le fichier de schéma est ensuite transformé en un fichier de mapping, en appliquant les règles de passage d’une structure imbriquée vers une structure relationnelle. Des tables liées sont donc définies avec les clefs étrangères associées.
- Une étape intermédiaire, optionnelle, consiste à filtrer le schéma produit à la première étape, pour ne synchroniser qu’une partie des données. Il faut pour cela écrire un fichier décrivant les collections ou champs à inclure ou exclure, au même format que le namespace.json de mongo-connector.
All together
La combinaison de ces trois briques permet de créer un pipeline assurant la synchronisation d’une base MongoDB vers une base PostgreSQL. Il est alors facile d'y analyser vos données, avec n'importe quel langage de programmation ou outil de BI.
Dans notre optique de présenter une solution totalement open-source lors de la conférence PyParis 2017, nous avons choisi l’outil Superset, open-sourcé par AirBnB et incubé désormais par la fondation Apache. La dernière partie de la vidéo de la conférence (ici) permet de visualiser un exemple simpliste du résultat obtenu.
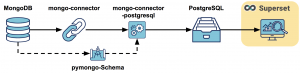
Schéma de la solution complète
The road ahead
Cette solution est aujourd’hui mise en production au sein d’une de nos missions et est régulièrement enrichie de nouvelles fonctionnalités. Nous souhaitions donc partager notre travail avec la communauté en espérant faciliter ainsi l’analyse de données issues de bases MongoDB.
Certains axes d’amélioration subsistent encore. Tout d’abord, nous manquons de retour d’expérience d’autres utilisateurs, afin notamment d’améliorer la documentation.
Ensuite, cette solution ne permet pas de suivre automatiquement les évolutions du modèle de données dans MongoDB. Il est nécessaire de définir un nouveau mapping et de réinitialiser la synchronisation. Dans le cadre particulier du projet pour lequel nous avons développé cette solution, un script nous permet d’extraire le modèle de données directement depuis le code de notre application. Cette brique est malheureusement spécifique à MongoEngine et à cette application.
Un autre enjeu est de passer à l’échelle sur de plus gros volumes. Il serait notamment facile d’accélérer le travail de pymongo-schema, en ne parcourant qu’une partie des données tel que le fait variety. Nous n’avons cependant pas rencontré ce besoin dans notre projet et n’avons donc pas développé ces fonctions.
Toute réutilisation et toute contribution sont bienvenues. Pull-Requests are welcomed :)
Remerciements
Ce travail a été réalisé grâce aux précieuses collaborations de Thomas Weiss, David Delassus (Scille) et Julie Rossi (Scille).
Pour en savoir plus
Article de Hugo Lassiege, CTO de Malt, qui a initié mongo-connector-postgresql
Article de Maxime Gaudin, mainteneur à Malt de mongo-connector-postgresql
Bonne explication du problème de l’analytics on MongoDB par MongoDB au début de cette page
Cet excellent article détaille ce qui a fait le succès de SQL voici plus de 40 ans, et pourquoi il revient en force aujourd’hui
Article sur la notion de frontière dans les SI, qui explique l'intérêt générique de réutiliser SQL, et le risque de "mentir" en exposant une interface SQL devant une base NoSQL
Répertoires Github
Support de la présentation à Pyparis 2017 : lien
Vidéo de la présentation à Pyparis 2017 : lien