OCTO's vision on the Service Mesh: radiography of the Service Mesh
This year, the Service Meshs are of all conferences: istio, linkerd, kubeflix, even zuul?... In a first article, we positioned the Service Mesh and its stakes in the ecosystem of microservices. We will now propose a radiography of these.
Our definition of Service Mesh is as follows:
The Service Mesh refers to a platform responsible for ensuring the security, routing and traceability of communications between microservice applications deployed dynamically in containers.
Different solutions have emerged to meet these needs:
- At the infrastructure level, container orchestration platforms such as Kubernetes are expanding with solutions such as Istio to provide an infrastructure platform
- At the API level, solutions like Kong are expanding to become more dynamic and gain in traceability
- At software level, software frameworks such as HAPI or Spring offer plugins and libraries that provide very similar functionalities
Multiplying solutions is, in our view, the wrong approach. But are all these different solutions equivalent? Insights will be given here to compare the features of these implementations. This will help choose or compose the best Service Mesh solution according to your needs and your legacy.
In our first article, we listed two fundamental issues for current applications: modularity and scalability. Here we will describe a framework to list the features required to meet these challenges. For that, we have mainly reused 12-factor apps patterns to characterise these features independently of their implementation.
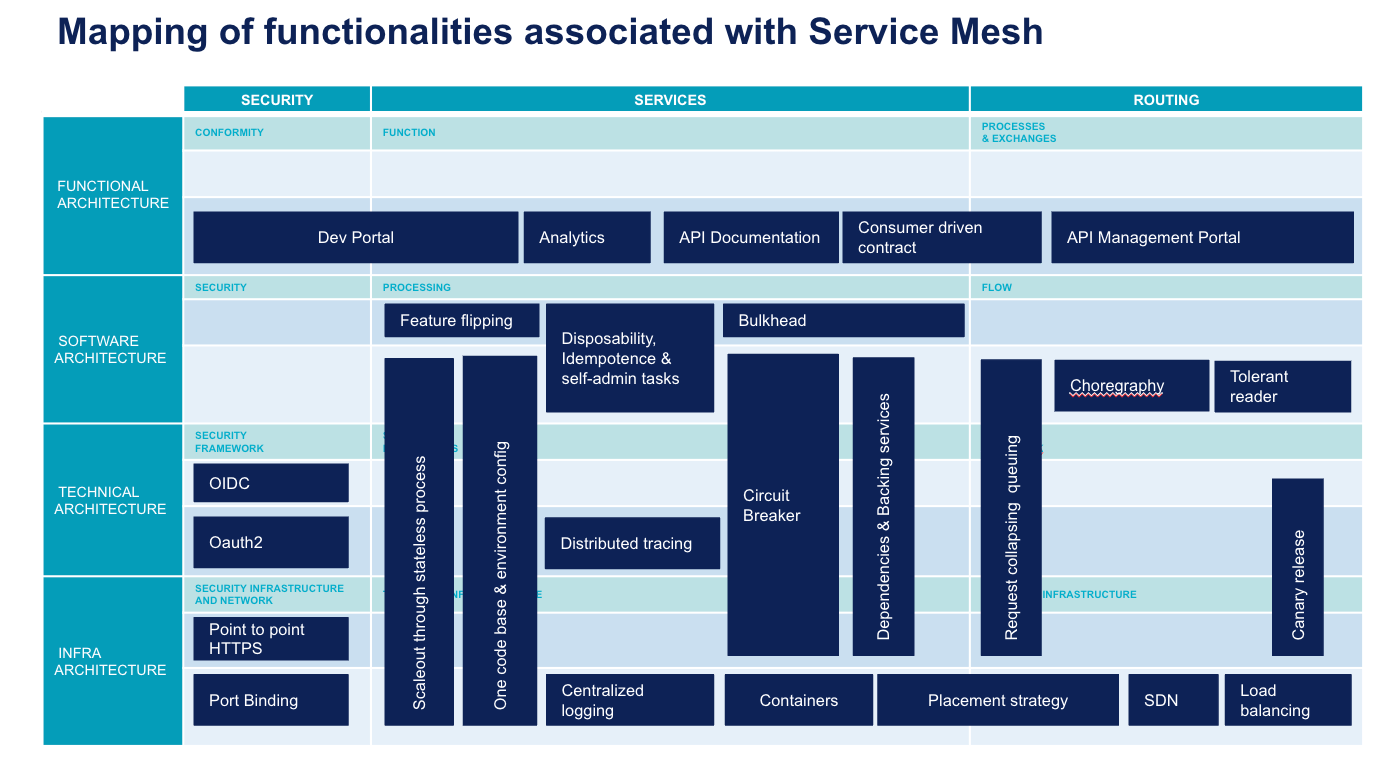
We have positioned these different patterns along 2 axes:
- The level of technical specificity of each of these patterns with four levels: functional, applicative, technical and infrastructure
- The type of problem to tackle: services, routing / integration and transverse security
We will quote here some solutions for illustration purposes, without being exhaustive on the features for each of them. We will discuss the functional coverage of these solutions in the following articles.
Security

If we consider a microservice exposing an API, security can be based on the following elements:
- Developer portal: it allows developers to register with the API and obtain all the information required to make its first authenticated call.
- OAuth2 : propagates a user's rights (all its permissions) between several applications
- OIDC : Open ID Connect extends OAuth2 feature with authentication capability
- Point to Point HTTPS: HTTP over TLS, or simply HTTPS, secures connections. Frequently, TLS protection were stopped at a central reverse proxy. From now on, security can be achieved not only up to the cluster entry-point, but up to each container entry-point
- Port Binding: segregates traffic up to the container level, each container only getting the traffic routed to it
For example, Linkerd and Istio offer a feature from TLS to the final container in a transparent way for applications. Istio can provide RBAC authorisation functionality, but will delegate all authentication. Conversely, a tool à-la Kong will be better equipped to integrate with an OAuth2 and OIDC infrastructure.
Services
In a digital ecosystem, we look for modular, scalable services. Deployment is automated or continuous. An application can be divided into a large number of microservices. Data driven development is gradually being implemented with the collection of metrics on a large scale. Needs are also driven by the possibilities of the different platforms.
Here is a non-exhaustive but as representative as possible list of the state of the art of microservices:
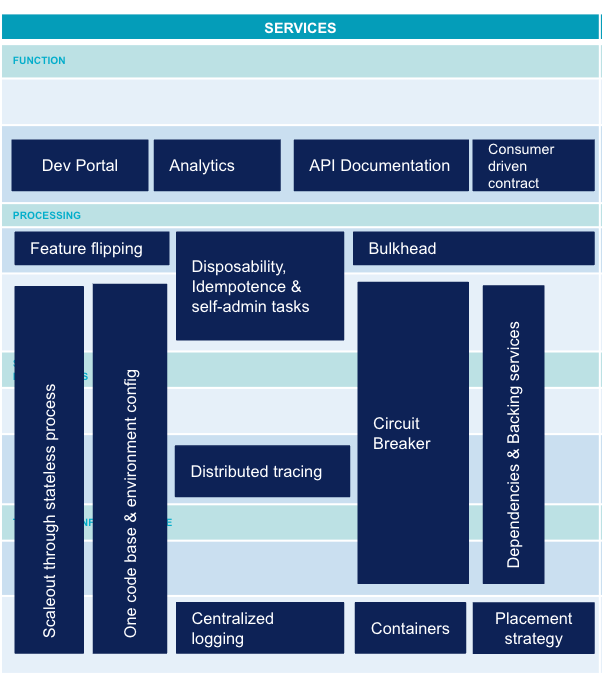
- Feature flipping: Continuous deployment of new features is not always desired by users who may need time before the official roll-out. Training may be necessary or simply promotion must be done on the new feature. Feature Flipping enables or disables a feature. This allows to decouple production roll-out and deployment which is fundamental to allow continuous deployment.
- API Documentation: ability to provide all API information to make it more intuitive for a client developer.
- Developer Portal and Analytics: user identification is a prerequisite for collecting statistics. These metrics can range from SEO on the API development portal to drills down into methods response times as part of performance management.
- Centralised logging: in a context of ephemeral containers, logs must be extracted and correlated to each other to provide a global view of the application for error management and diagnosis.
- Distributed tracing: beyond logs, the traceability of exchanges between different microservices is an essential functionality to understand routing and diagnose possible latency problems.
- One codebase & environment configuration: in order to follow the version of an application from end to end, all these elements must be versioned. On the one hand a basic code that remains identical between environments, and on the other hand an environment configuration managed by an infrastructure solution as code (container or other orchestrator). This configuration will also be versioned and used for deployment in each environment.
- Disposability, idempotence & self-admin tasks: ability to handle all start/stop tasks (e.g. data initialisation, deduplication of messages that are already processed) by the microservice itself. This is an essential feature of an application for it to run on a dynamic platform such as a container orchestrator. Indeed, at any time the instance can be destroyed or created again. The microservice needs to configure itself to be ready to process requests.
- Bulkhead: like the watertight housing of a boat's hull, an application's ability to continue to respond in degraded mode in the event of a serious error on one of its components or one of its dependencies.
- Circuit breaker: like the physical circuit breaker, a proxy implementing a state machine that will disable calls to a dependency in case of too many errors. This pattern allows not to overload a microservice due to a problem in another downstream microservice.
- Container: packaging of a process that isolates the filesystem and IT resources from the execution of this process. Docker is the most well-known type of container. A container is used to standardise deployment. Container orchestrators can thus process all microservices in an industrialised way.
- Scaleout through stateless process: ability to distribute processing over several processes that do not share any states. This is an essential feature of the application so that it is scalable and can leverage the capacity of an on-demand infrastructure such as a cloud or container orchestrator.
- Placement strategy: functionality at the heart of container orchestrators that allows a container to be executed on the most appropriate physical node based on a number of constraints.
Istio and Linkerd will provide advanced distributed tracing features. But they will have to rely on other tools for centralisation of metrics or identification. Some application features such as Circuit Breaker can also be supported by these tools. But for a totally transparent behaviour for the user, these generic tools will always be limited. For example, an elegant graceful degradation strategy cannot be implemented by a generic business-agnostic tool.
Communication - routing
The finer the modularisation granularity becomes, the more complex the communication between different microservices. The following features are gradually becoming essential to manage this complexity:
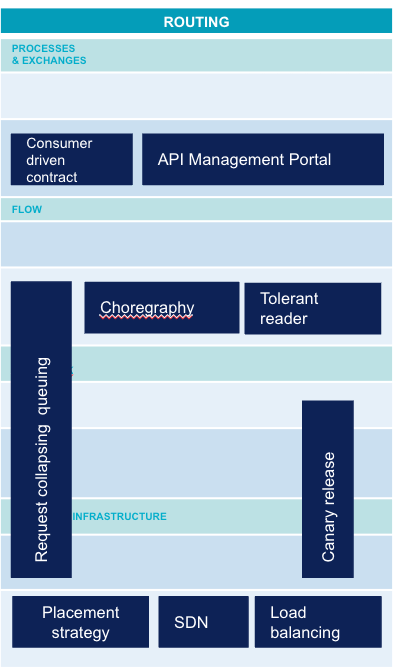
- Consumer Driven Contact (CDC): If we use Sam Newman's definition in "Building Microservices": "With the Consumer Driven Contract, we define the expectations of a consumer on a service [...]. Its expectations are captured in the form of tests, which are then executed on the producer service. As a target, these CDCs must be executed in the ongoing integration of the service, so as to ensure that the service is never deployed if it does not respect one of these contracts."
- API Management Portal: This extension of the developer portal allows to configure APIs and configure query routing. It can also manage API documentation.
- Tolerant Reader: The principle is to ensure that the consumer of any external system is tolerant to the evolution of the data schema that is provided to it in read mode. This consists in providing palliative solutions in the event of unexpected value, absence of value or not respecting the expected format. Web browsers, for example, are relatively tolerant of deviations from the HTML standard.
- Orchestration: SOA's traditional approach consists of having a central component (often an ESB) to orchestrate all exchanges between services. The orchestration approach consists in delegating this responsibility to the various microservices and thus decentralising it.
- Request Collapsing & Request Queuing: ability to delay or group several requests to make only one physical request to the target service. This pattern optimises scalable routing.
- Canary Release: ability to release a new version of the application to a subset of selected clients. This allows the new version to be validated before it is widely deployed. Read more about it in our article about Zero Downtime Deployment.
- Load balancing: ability to redirect a network stream to multiple components transparently to the caller. This makes it possible to distribute the load or to compensate for the failure of one of the components.
- Software Defined Network (SDN): completely virtual network environment where the routing part itself (data plan) is separated from the routing plan part (control plan) which defines the routing rules globally.
Istio and Linkerd provide very advanced functionalities in terms of dynamic routing and traffic management. They are also very well integrated with the SDN functionality of container orchestrators. Their differentiation is based precisely on an SDN-like architecture (the data plan in a container is attached to the application container, such as a sidecar is attached to a motorcycle).
Service Mesh applies this concept to application routing. Their choice to have a transparent approach towards applications will necessarily limit them on the API and application part. API management solutions will be very well equipped for API management and load balancing, but they will require more development to follow the dynamic topology of a container orchestrator.
Through this framework, we were able to show that the Service Mesh provides very useful functionalities to meet the challenges of modularity and scalability. But the tool by itself may not be sufficient or it may not be necessary in your context. Like any tool, it is essential to identify your needs beforehand. Choosing it because it is on everyone's lips today will only add technical debt to your architecture. Twisting a tool to meet a new need for which it was not designed will have the same type of adverse consequence.
We hope this article will help you make an informed choice.