REX - Migrer un SI critique
Abstract
Vous n’entendrez jamais parler de cet événement, notamment parce que tout s’est passé de façon si transparente que notre client n’a pas interrompu ses activités. Vous n’en entendrez jamais parler aussi parce que, comme pour nombre de nos clients, certaines de nos missions sont soumises à la confidentialité. Cet article a donc été anonymisé, mais nous avons utilisé des termes et conservé les échelles de statistiques pour que la criticité des environnements dans lesquels nous opérons ressorte. Cette migration aurait très bien pu se produire chez un acteur de l’énergie, un acteur du transport, une chaîne d’approvisionnement de ressources critiques, en bref, toute infrastructure essentielle au fonctionnement d’un territoire. L’article qui suit détaille notre approche pour sécuriser des opérations d'environnements de production critiques.
TL;DR
Fin 2024, l’équipe Infra de Coresys a préparé et réalisé une montée de version de la plateforme de production. Pour ce faire, l'intégralité de la plateforme a été détruite/reconstruite sans perte de service pour les utilisateurs. Ce document est une synthèse des enseignements que nous en avons tirés. Il aborde le chantier sous plusieurs angles : techniques, méthodologiques et organisationnels. Peut-être que l’un de ces points de vue pourrait vous intéresser.
Contexte
Coresys c’est quoi ?
Coresys est un système d’information spécialisé pour les techniciens de maintenance. Il est en cours de déploiement en France, région par région. C’est une galaxie d’applications utilisées 24h/24 - 7j/7 qui permettent de :
- collecter et centraliser les alertes critiques
- géolocaliser les alertes
- assurer la conduite des opérations par la création et le pilotage des opérations (quelle équipe part, de quel centre d’opérations, dans quel véhicule d’intervention…)
- générer automatiquement des itinéraires optimisés pour les véhicules d’intervention
- mettre à disposition les données générées par le SI, pour permettre par exemple la gestion des indemnités des techniciens de maintenance d’astreinte
- …
Si le service tombe, piloter les alertes et les opérations devient très difficile. Il existe des modes dégradés pour continuer à prendre les alertes, en revanche, il n'est plus possible de faire fonctionner les bippers pour mobiliser les techniciens de maintenance, localiser les alertes, avoir la connaissance du personnel et des moyens disponibles (tels que les véhicules d’intervention), etc. Cela ralentit l’activité opérationnelle où chaque minute compte.
Les SRMU, (Service Régional des Maintenances d’Urgence) migrent progressivement sur Coresys en fonction de leur capacité d’intégration, de leurs contraintes locales, des contrats avec leurs éditeurs de solutions actuelles, des contraintes politiques… Tous les services régionaux n’ont pas les mêmes besoins, et Coresys ne sait pas encore tout faire.
Coresys, en quelques chiffres :
- en décembre 2024, 4 régions utilisent le système
- 15,5k alertes d’urgence par semaine
- 12k techniciens de maintenance (d’astreinte ou non)
- 5,5k opérations par semaine
- 4 ans d’historique
- Une première mise en service pour un service régional en janvier 2024
Situation avant la migration
En septembre 2024, avant la migration, 4 régions utilisent les applications Coresys comme outil opérationnel principal. Il y a six plateformes centrales :
- Dev : porte toute l’intégration continue pour le plateau de réalisation (environnement d’intégration, review apps, runners gitlab…)
- Qualif : porte différents environnements à destination du plateau de réalisation (plateformes de recette, d’intégration pour les partenaires tiers…) et à destination des services régionaux (environnement de formation pour les techniciens de maintenance, environnement d’intégration et de validation des données…)
- Production : expose les applications Coresys utilisées par les services régionaux en production
- Tooling : héberge tous les outils transverses (stack de logging, de sécurité…)
- Test et Scratch : peuvent être détruites et reconstruites à la volée par l’équipe Ops pour faire des tests d’infrastructure avant de déployer sur les autres environnements
Il y a également :
- Des plateformes locales hébergées sur des clusters Kubernetes directement dans les locaux des différents services régionaux. Ces plateformes hébergent les services passerelles connectés aux assets locaux des centres d’opérations (téléphonie, imprimantes, bippers, radios...)
- Un réseau privé appelé ALERTE, co-construit et maintenu avec l’opérateur réseau. Il permet d’interconnecter toutes les plateformes (centrales et locales) entre elles
Le problème à résoudre :
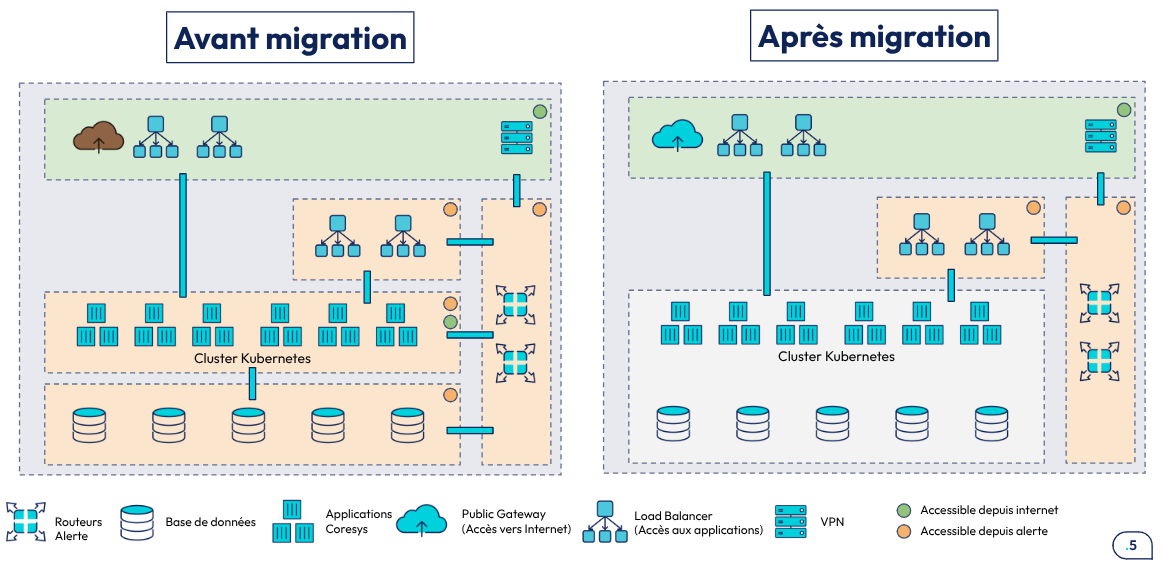
La plateforme de production n’est plus à l’image des autres plateformes anté-production (dev, qualif, tooling, test). Faire évoluer cette plateforme a plusieurs intérêts :
Rendre la plateforme de prod la plus proche possible des autres plateformes :
- Pouvoir faire des tests représentatifs de la production sur les autres plateformes
- Simplifier les modèles mentaux à connaître pour l’équipe Ops : un seul modèle d’infra, une seule architecture à comprendre, une seule topologie réseau. Cela permet une intégration plus simple pour les personnes intégrant l’équipe et une exploitation plus facile au jour le jour. Plus besoin de passer son temps à jongler entre le modèle anté-prod et le modèle de prod !
- Ne maintenir qu’une seule base de code et une seule manière de déployer pour toutes les plateformes. Moins il y a de code, moins il y a de bug.
Améliorer la sécurité de la plateforme :
- Ne plus exposer les nœuds du cluster Kubernetes sur Internet. Jusqu’à maintenant, ils ont par défaut une patte sur Internet et une IP publique sur laquelle sont posés des ACLs pour en limiter l’accès.
- Ne plus exposer les bases de données directement sur le réseau ALERTE : il n’y a aucune raison pour que d’autres clients que les applications centrales se connectent aux bases de données.
- Ne plus exposer les IPs privées via des enregistrements DNS sur le service DNS public du cloud provider. Quelqu’un de malin qui requête tout ou partie des noms de domaines Coresys est capable de récupérer la majorité des IPs internes des services et d’en déduire tout ou partie de l’architecture ou du découpage réseau.
Réduire les coûts :
- La plateforme scratch a pour unique utilité d’être une plateforme qui ressemble à la prod. Elle permet de tester des mises à jour avant d’aller en prod. En rendant la prod iso aux autres plateformes, nous pouvons supprimer cette plateforme et économiser environ 3k€/mois.
Voici une vue macroscopique de ce qui est à modifier sur la plateforme de production
Comment sommes-nous arrivés dans cet état ?
Toutes les plateformes anté-production ont été construites entre 2019 et 2022 avec les briques d’infrastructures disponibles à l’époque sur le cloud provider. La plateforme de production a été pensée et déployée en 2023, en prenant en compte les évolutions du portfolio des services proposés par le cloud provider. Dès le départ, la plateforme de production n’était pas à l’image des autres plateformes.
Durant l’année 2024, le cloud provider a, de nouveau, fait évoluer son offre de services et a forcé ses clients à migrer. Nous avons été particulièrement impactés par des évolutions sur leur offre Kubernetes Managé. Toutes les plateformes SAUF la plateforme de production étaient concernées.
L’équipe Ops a décidé de re-provisionner de zéro l’ensemble des plateformes anté-production qui n’avaient pas évolué depuis plusieurs années. Ces opérations ont eu lieu pendant le premier semestre de 2024. Elles se sont déroulées rapidement, sans trop de complexité et ont nécessité très peu de coordination avec les autres acteurs du programme. Dès qu’il était nécessaire d’interrompre les services des plateformes concernées, nous avons pu le faire.
Une fois les plateformes anté-production à jour, la situation était :
- Toutes les plateformes: dev, qualif, tools, test utilisaient les dernières versions des services managés proposées par le cloud provider. Elles n’avaient plus de topologie réseau legacy.
- La plateforme de production (et sa petite sœur scratch) étaient dans un entre-deux. Elles n’étaient pas assez obsolètes pour nécessiter une migration/refonte en urgence, mais elles étaient assez différentes des autres plateformes pour qu’on juge nécessaire de les faire évoluer.
Chronologie du projet de migration
Il faut donc organiser une refonte complète de notre infra de production, en limitant l’impact pour les utilisateurs. Le chantier s'est étalé sur le dernier trimestre de 2024
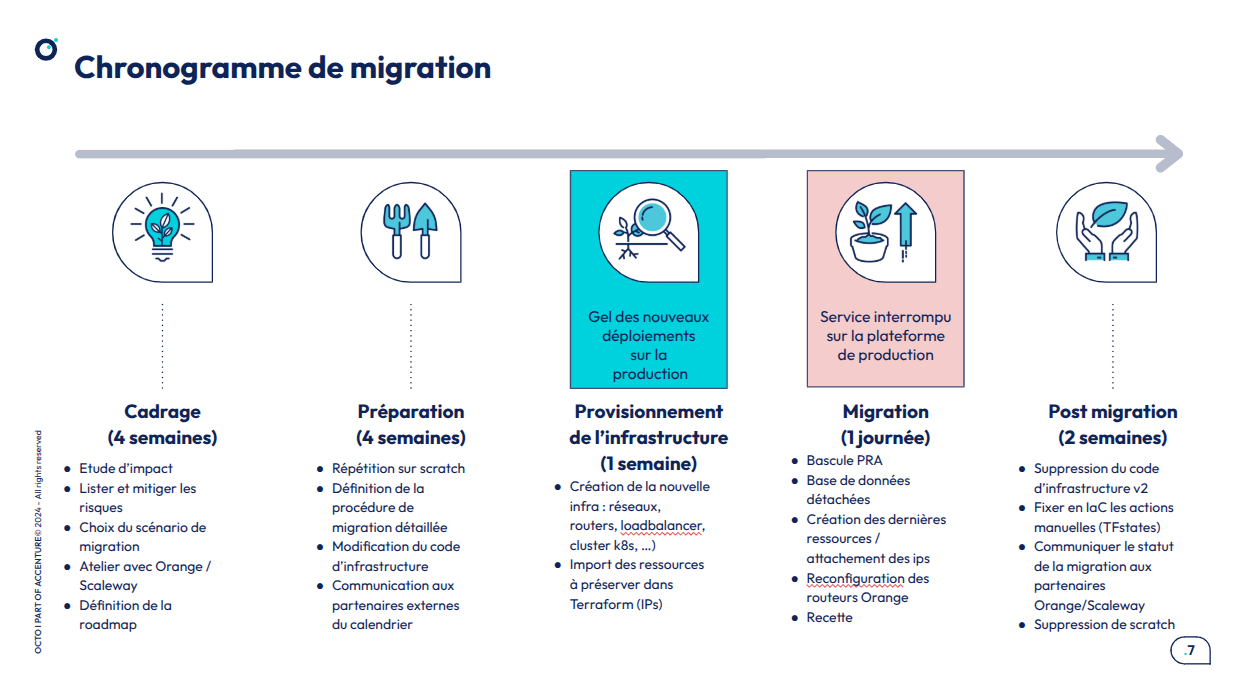
1 - Phase de préparation de la migration
Les outils utilisés

Comme nous avions du mal à avoir une première idée claire de tout le travail à réaliser, à la fois d’un point de vue technique, mais aussi d’un point de vue méthodologique et organisationnel (est-ce qu’il allait falloir interrompre le service ? si oui combien de temps, avec quelles contre-mesures ? …), la première étape a été de tout poser en désordre dans une Mind Map pour voir différentes thématiques émerger. Cela a permis de mettre en lumière : le reste à faire, les points d’ombre à creuser et ce qui n’avait pas besoin d’être modifié.

Très vite, il est apparu que nous aurions besoin d’aide extérieure pour mener ce chantier à bien.
Nous allions avoir besoin de communiquer souvent et à des niveaux d’abstraction différents pour expliquer : nos objectifs, leur importance, notre méthode, et les moyens nécessaires à leur mise en œuvre.
On a décidé de créer un unique deck de slides qui s'adresse à deux grandes populations :
- Le pilotage : Les slides sont haut niveau et répondent aux questions : “Pourquoi ?”, “Quoi ?”, “Quel impact pour les utilisateurs ?”, “Quels besoins pour y arriver ?” …
- Les experts techniques (développeurs, architectes, partenaires) : Les slides entrent plus dans le détail. Elles mettent en évidence les changements, ce qui reste inchangé, les points d’attention, les questions en suspens… Elles peuvent être consultées en asynchrone.

Ce deck a permis de ne jamais être pris au dépourvu lorsque le sujet de la migration s'invitait par surprise lors d’une réunion. Il a, par exemple, fallu en parler au pied levé en comité de pilotage en 3 minutes chrono.

Il contient :
- La liste des grandes étapes de migration : bascule des utilisateurs, recette de la nouvelle plateforme…
- Un porteur pour chaque étape (individu ou équipe)
Ce Chronogramme a été co-construit avec les équipes de pilotage et de la DSI.

Il a été utilisé avant le jour J pour toutes les répétitions avec les services régionaux. Il a servi de pont entre l’équipe de réalisation technique côté Ops et l’équipe de pilotage. Il a permis de construire peu à peu l'enchaînement des étapes : nous avons pu nous rendre compte qu’il manquait une étape à un endroit, que l’ordre n’était pas le bon…
C’est le document qui a été utilisé le jour J et il a parfaitement joué son rôle de source de vérité pour savoir où nous en étions dans les actions et qui avait la main.

Ce document reprend les grandes étapes définies dans le chronogramme macroscopique avec un découpage en actions fines et unitaires. Pour chaque action, il y a :
- Un porteur :
- Permet d’identifier clairement tous les acteurs nécessaires
- Permet de bloquer les créneaux pour que les personnes soient disponibles le jour J
- Permet à chaque personne de savoir exactement ce qui est attendu d’elle
- Un critère de validation : pour s’assurer que l’action s’est bien déroulée
- Un temps de réalisation : pour estimer le temps total nécessaire pour chaque grande étape
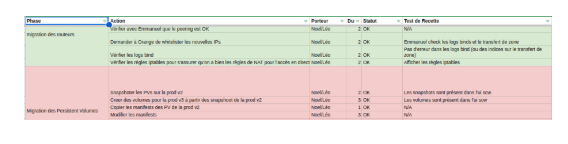
Ce chronogramme détaillé a été rédigé par une troisième personne externe au “binôme projet migration”. Cela a permis d’avoir :
- un regard neuf et critique sur la migration
- une posture active pour ne pas juste lire et commenter quelque chose qui a été écrit par quelqu’un d’autre : cela a forcé la personne à comprendre pourquoi chaque étape, pourquoi dans cet ordre, est-ce bien la bonne manière de valider et à challenger la proposition…
Il a évolué au fur et à mesure des séances de questions/réponses et des répétitions de migration.
Il a été utilisé pour un bon nombre d’objectifs. Il a permis lors de cette migration de :
- proposer une estimation du temps d’interruption total
- identifier les moments de handover entre équipes : quand le porteur change, c’est qu’une action de communication/coordination est nécessaire. Ça peut permettre de réagencer les actions les unes par rapport aux autres pour limiter les phases de passation
- tracer toutes les actions : il n’est plus nécessaire de se souvenir comment réaliser toutes les actions et dans quel ordre. Comme tout est écrit dans le chronogramme, il suffit de le suivre de façon mécanique
- rejouer, répéter, préparer et partager le mode opératoire de migration avec les différents partenaires, chaque action est listée, séquencée, ça permet d’avoir un bon support pour poser des questions…
Beaucoup d'actions auraient pu être automatisées en y consacrant un peu plus de temps. Cependant le choix a été de ne pas prendre ce temps là car le niveau de confiance de l’équipe Ops était assez bon. Il a été décidé de ne pas industrialiser plus les étapes de migration.
Choix clés
Au fur et à mesure de l’étude de la migration, nous avons fait quelques choix structurants :

Le scénario de migration retenu nécessite d’interrompre le service sur la plateforme de production pendant plusieurs heures.
Coup de chance ou planification au top, nous travaillons également depuis plusieurs semaines sur la mise en place d’une plateforme centrale pra (Plan de Reprise d’Activité). Elle est hébergée hors de France pour pallier d'éventuels problèmes de disponibilité sur la plateforme de production à Paris. Dans sa v1, cette plateforme a été conçue pour offrir un sous ensemble de fonctionnalités de la plateforme de production.
Cette plateforme a été déployée durant l’été 2024 mais n’a pas encore été testée par les services régionaux. Toutes les questions fonctionnelles de la plateforme n’ont pas encore été abordées : comment alimenter cette plateforme, avec quels paramétrages pour les services régionaux, comment réconcilier à posteriori les opérations qui ont été ouvertes sur la plateforme pra avec celles ouvertes sur la production... Pra était donc une opportunité pour assurer la continuité du service pendant la migration. En revanche c’était un challenge, car cette plateforme et l’organisation des processus autour d’elle n’étaient pas encore tout à fait finies.

Lors de nos premières estimations, nous avions prévu une indisponibilité de la production d’environ 24h. Le temps de provisionner, déployer et paramétrer l’intégralité de la nouvelle plateforme. Pour réduire ce temps d’interruption, nous avons cherché à trier les actions dans 3 grands groupes :
- Toutes les actions qui pouvaient être réalisées avant d’interrompre le service sur la plateforme de production
- Toutes les actions qui ne pouvaient être réalisées que pendant l’interruption de service
- Toutes les actions qui pouvaient être réalisées sans risque après que la plateforme de production soit remise en service
Finalement, nous avons provisionné et déployé 90% de la nouvelle plateforme une semaine avant l’interruption de service. Cela a permis de :
- Gagner du temps en ne faisant que le nécessaire le jour J
- Dérisquer un grand nombre de composants/opérations avant le jour J
- Réduire le nombre d’opérations sur lesquelles il était nécessaire de s'entraîner

Pendant l’interruption de service, nous avons cherché à commencer par les actions les plus risquées. A partir d’un certain moment, il est difficile de revenir en arrière (à partir du moment où nous migrons des données : moteurs de base de données, volumes Kubernetes…). Le plus risqué pour nous était de migrer les routeurs. Cette opération a donc été effectuée en premier. Si jamais la première action échoue, il n’y a qu’une action sur laquelle il faut revenir en arrière pour arrêter l’opération.

Les opérations de Dump/Restore sont très coûteuses en temps sur de gros volumes de données (plusieurs heures dans notre cas). Nous avons eu l’opportunité de ne pas faire de recopie des données d’une base à une autre mais plutôt de détacher/rattacher les bases de données d’un réseau à un autre. Au total, l’étape de déplacement des bases de données de l’ancienne production à la nouvelle production a pris 5 minutes.
Comment les Ops se sont organisés
L’équipe Ops est composée de six personnes. À chaque sprint (2 semaines), 3 binômes sont formés et se répartissent les sujets :
- 1 binôme réaction/run : prise en charge des demandes de support, petites évolutions/paramétrages, réponse à incident… La tâche principale du binôme, c’est de pouvoir être dérangeable et faire tampon pour que les autres binômes puissent rester concentrés sur leurs chantiers.
- 2 binômes projet/build : cadrage, build de projet, accompagnement d’équipe sur des sujets longs…
Pour la migration, un binôme projet/build a été dédié au sujet pendant un peu plus de 4 sprints.
Sur la période, le binôme a tourné 1 fois mais pendant la majorité du projet, ce sont les 2 mêmes personnes qui étaient impliquées sur le chantier.
Comment le reste du programme s’est organisé
Une fois le cadrage effectué par l’équipe Ops, il a été restitué aux autres équipes. Un certain nombre d’actions ont ensuite été distribuées :
Priorisation des user-stories dans les différentes équipes par le pilotage
- L’équipe Data pour la synchronisation des données entre les plateformes prod et pra
- L’équipe transverse pour que les pagers des techniciens de maintenance puissent bipper en étant branchés sur la plateforme de pra
- L’équipe infra-locales pour modifier les configurations DNS des infra-locales pour qu’elles pointent sur les DNS de la plateforme pra pendant que la plateforme de prod est éteinte
Accompagnement des services régionaux par l’équipe transformation digitale
- Communication auprès des services régionaux
- Préparation et répétition avec les services régionaux des scénarios de bascules sur pra
- Planification des dates et des créneaux horaires pour les tests et la bascule
- Suivi des services régionaux : réponses aux questions…
Suivi de l’avancement des travaux de migration par le pilotage
2 - Le jour J
Organisation du déroulé des opérations
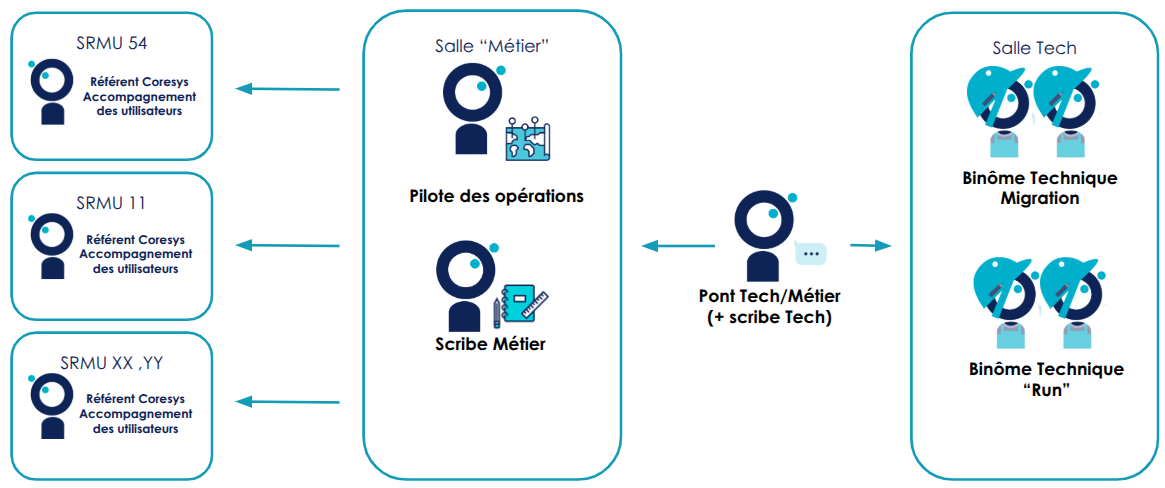
Organisation Logique : Nous avons pris le parti de voir cette opération comme un incident planifié, nous avons donc réutilisé l’organisation pour les incidents :
- Un pilote global des opérations : C’est la personne qui coordonne l’ensemble des actions et des acteurs durant toute la durée de l’opération.
- Des référents métier dédiés à l’accompagnement des utilisateurs : Leur rôle est d’informer les utilisateurs des actions à mener, de les rassurer et les tenir au courant de l’avancement des opérations. Pour cette opération, plusieurs personnes se sont déplacées dans chacune des régions pour être au plus près des coordinateurs.
- Un binôme dédié aux opérations techniques : Ce binôme a pour objectif de dérouler le chronogramme détaillé élaboré en amont de la migration. Être deux (ou plus) permet d’éviter les erreurs d'inattention, de se relayer, et de partager collectivement la responsabilité des opérations.
- Une personne qui fait le pont entre le groupe technique et le groupe métier : Il est l’interlocuteur privilégié des deux mondes et fait tampon si nécessaire. Il centralise les demandes métier pour ne pas déranger trop souvent l’équipe technique.
- Un scribe métier et un scribe technique : Malgré une opération répétée, planifiée, organisée, des imprévus peuvent toujours survenir. Le scribe en garde une trace. Cela permet lors du point Post Mortem (à défaut d’avoir un meilleur terme même si l’opération s’est bien passée) de relire le déroulé de l’opération et d’en tirer des axes d’améliorations.
- Un binôme dédié au run : Ce binôme sert à assurer le support des services devant continuer de tourner. Exemple : les équipes de développement doivent continuer de travailler et ont besoin de runner gitlab, certains clients utilisent des environnements anté-production à des fins de formation… Pour tous ces services, il faut pouvoir continuer d’en assurer la disponibilité sans que les personnes déjà mandatées pour les opérations sur la production ne soient sollicitées.
Organisation Physique :
Créer des lieux / espaces dédiés à des actions définies : Deux salles et deux canaux de messagerie instantanée / visio conférences séparées pour :
- Les responsables métiers/pilotage, les utilisateurs dans les services régionaux et le scribe métier
- Le binôme technique et le scribe technique
Suivi des opérations
Un unique support de communication
Le chronogramme de migration a servi de support de communication unique pour suivre l’avancement pendant la migration. Il est resté affiché en visio pendant toute la journée et les étapes étaient surlignées par le pilote au fur et à mesure qu’elles étaient complétées. Il est devenu le référentiel commun : utilisateurs, métiers, techniques pour savoir où en est chaque action et qui est à la manœuvre.
Suivi avec les experts externes
Deux interlocuteurs externes pouvaient nous aider pendant la migration :
- l’opérateur réseau qui opère le réseau ALERTE
- le cloud provider qui héberge et manage les infrastructures centrales
Quelques semaines avant la migration, nous avons :
- récupéré les contacts directs des experts pour éviter d’avoir à passer par plusieurs couches de support pour les atteindre en cas de problème
- partagé et fait challengé le chronogramme des actions ainsi que les moments où nous pourrions avoir besoin d’eux
- bloqué les agendas des experts afin qu’ils soient mobilisables en cas de pépins
Nous leur avons partagé l’avancée des opérations via le chronogramme. Ils pouvaient savoir exactement où en étaient les opérations et s’ils devaient monter à bord.
3 - Après le jour J

Pendant les opérations, certains fix ont été appliqués à la main pour ne pas perdre trop de temps et respecter la fenêtre de temps d’interruption définie au départ. Nous avons par exemple découvert que certaines routes statiques étaient poussées automatiquement par le cloud provider. Ces routes prenaient la précédence sur d’autres routes empêchant ainsi l’accès aux bases de données. Nous avons supprimé les routes à la main, mais cette suppression est éphémère. Elle ne survit pas à un reboot des VMs. Il a fallu reporter la modification proprement dans notre code d’infrastructure.

La migration a permis de ne plus utiliser une partie importante du code qui était jusque-là dédiée à l'infrastructure de production. Il restait à supprimer tout ce code mort : terraform pour le provisionning des infrastructures des plateformes de production et scratch, code ansible pour le déploiement des VM spécifiques à la prod, documentation là aussi spécifique à l'ancienne plateforme de production.

Cette migration a été un succès pour tout le monde. Les utilisateurs ont pu travailler sur une plateforme pra fonctionnelle. Ils sont satisfaits de l’accompagnement et de l'organisation rassurante qui s’est mise en place autour de cette opération. Du côté de la DSI, il y a de la fierté d’être en capacité d’organiser une opération d’ampleur sans problème majeur.
Il reste encore à organiser un REX transverse pour capitaliser sur cette expérience. Ce REX n’a pas encore eu lieu à l’heure où nous écrivons ce document. Il y a peu de chance qu’il ait lieu un jour, tout le monde étant reparti dans des sujets plus urgents.
Les enseignements de cette migration :
Les réussites

La DSI a l’habitude d’organiser des ECRs (Essais en Condition Réelle) avec les utilisateurs pour les faire tester et les faire s’approprier progressivement les fonctionnalités de Coresys.
Quelques semaines avant la migration, la DSI a organisé avec chaque service régional une journée de bascule en conditions réelles sur la plateforme pra, ces exercices ont permis de :
- mettre en lumière des anomalies qui ont pu être corrigées avant la bascule réelle (données erronées, erreurs de paramétrages, flux réseau pas ouverts, erreurs dans les scripts de recopie…)
- habituer les coordinateurs à l’exercice de bascule sur pra puis au retour sur la production afin que cela soit fluide le jour J : faire attention à être sur la bonne URL, seul élément différenciant entre pra et prod, être à l'écoute des chefs de salle…
- se familiariser avec la bascule des données : quand arrêter de saisir des opérations sur la prod et commencer sur pra, quelles données recopier sur pra, lors de la bascule retour, comment récupérer sur la prod les opérations démarrées sur pra…

L’isolation physique des différentes parties prenantes en fonction des rôles pendant les opérations de migration a très bien fonctionné. Au début des opérations, une ou deux personnes métier sont venues déranger la salle du groupe technique. La personne chargée de faire le pont entre le groupe métier et technique a fermé la porte de la salle technique et est allée rappeler la règle : Tout échange entre les deux mondes doit passer par lui pour éviter le bruit inutile. Dès lors, il n'y a plus eu de sollicitations externes.

La période de la journée a fait l’objet d’un arbitrage. Lors des premières négociations avec les services régionaux, ils voulaient tous que les opérations aient lieu la nuit entre minuit et 6h. Mais après plusieurs échanges, la DSI a réussi à convaincre tout le monde de faire l’opération de jour, cela nous a permis :
- D’avoir des experts de l’opérateur réseau et du cloud provider disponibles (et heureusement car nous avons eu besoin d‘eux)
- D’avoir toutes les équipes de développement et de recette de la DSI disponibles pour faire une première passe sur les applications dès que nous avons remonté la plateforme de production
- D’avoir également les bonnes personnes dans les services régionaux quand nous avions une question.

La durée des opérations annoncée a été volontairement plus importante que celle réellement estimée. Cela a permis de prendre le temps de résoudre les problèmes lorsque des imprévus surviennent, sans avoir besoin de communiquer sur un éventuel retard. C’est moins de stress et de charge mentale.
La migration théorique devait durer 2h30. La durée annoncée était de 4h. Elle a réellement pris 3h30/3h45.
Les échecs

Certaines régions n’étaient pas officiellement en production, mais étaient très proches de l’être et utilisaient certaines briques de la plateforme de production à des fins de test, de paramétrage ou de formation. Pour les régions en production, nous avions préparé le terrain pour qu’elles continuent à pouvoir résoudre tous les domaines en coresys.fr même si la plateforme de production n’était plus disponible. Malheureusement, nous n’avons pas fait ce travail pour les services régionaux hors production et plusieurs services régionaux se sont retrouvés sans service le temps de l’opération.

Une étape de la migration consistait à détacher les bases de données d’un réseau pour les rattacher à un autre réseau. Bien que cette étape ait été testée sur les environnements anté-production, en production lorsque les bases de données ont été rattachées au nouveau réseau, elles n’étaient plus joignables. Il a fallu une intervention manuelle du cloud provider pour que les moteurs soient à nouveau accessibles (à ce jour nous ne savons toujours pas quel était le problème et ce que le cloud provider a fait pour le résoudre…).
Le cloud provider étant en constante évolution, et même en ayant un code d’infrastructure complètement iso entre environnements anté-production et environnement de production, nous nous sommes à nouveau retrouvés avec une plateforme de production pas tout à fait iso : le cloud provider a rendu obligatoire une brique de routage virtuelle qui n’existe pas sur les autres plateformes. Ce composant pousse des routes statiques sur toutes les VMs de production qui prennent la priorité sur nos routes. Une intervention du cloud provider a été nécessaire pour comprendre ce problème et malgré une migration toute fraîche, nous nous retrouvons avec à nouveau des différences à rattraper entre les différentes plateformes.

Le projet a pour spécificité de répliquer des enregistrements depuis nos DNS de production vers des DNS de l’opérateur réseau. Les DNS de l’opérateur réseau mettaient plus de 5 minutes pour se synchroniser avec les nôtres, cassant le déploiement Ansible. Cela a nécessité un patch de la part de l’opérateur réseau.
Les leçons apprises :

Tester, re-tester différents scénarios de migration pour arriver à la meilleure solution, répéter, se faire relire par ses pairs, prendre les retours et adapter le plan prend BEAUCOUP du temps. Cela peut sembler long et un peu frustrant mais passer par toutes ces étapes de préparation a permis de dérisquer une majorité des problèmes et d’attaquer la migration sereinement. L’Infra As Code permet de tester plus rapidement et de façon plus fiable.

Prendre le temps de préparer le terrain avec les équipes de pilotage et avec les utilisateurs a été payant : nous aurions pu avoir des utilisateurs mécontents d’avoir à changer leurs habitudes et d’avoir à faire du travail en plus parce que la plateforme de production n’était pas disponible pendant 4h. Mais à force d'explications, de préparation et de communication, l’ensemble des utilisateurs était heureux de savoir que leurs outils seraient mis à jour. Ils ont également pu constater que la plateforme pra et les process associés sont fonctionnels et utilisables en cas de problème sur la plateforme de production.
Les services régionaux ont accepté de faire l’opération la journée parce que les équipes Dev ont re-priorisé l’implémentation des fonctions de mobilisation sur la plateforme pra (capacité de faire biper les pagers des techniciens de maintenance). Cette feature ne devait pas être disponible dans la première version pra. Cependant les différents échanges ont permis d’arriver à un compromis acceptable entre risque pour les équipes techniques de delivery et risque/charge opérationnelle pour les techniciens de maintenance. Ce changement de comportement des services régionaux est uniquement dû à la communication en amont et à l’accompagnement de ces derniers.

Même quand le chemin semble balisé, il peut toujours y avoir des doutes ou des erreurs. Le monde de l’informatique (organisationnel, méthodologique, technique) n’est pas une science exacte. Il existe une part d’imprévu qu’il est bon d’essayer de dérisquer. Bloquer du temps chez les partenaires lors des opérations délicates, permet de mitiger certains risques.