Rendre résilient un projet RAG
(Version anglaise. Pouce appréciée)
Dans un article précédent (“Ne mettez pas les projets RAG en production trop vite !”), nous avons évoqué la difficulté de rendre résiliente une application RAG. Dans cet article, nous allons particulièrement traiter des solutions dans le cadre de l’utilisation de LangChain.
LangChain est un framework incontournable pour la réalisation de projets embarquant des LLMs. Il permet d’utiliser des abstractions, nous aidant à intégrer toutes les évolutions technologiques qui ne cessent d’arriver dans cet écosystème. Il est aisé de changer de modèle, de base de vecteur, de convertisseur de fichiers, etc.
L’objectif de cet article est de vous aider à renforcer vos applications LLM, afin de les rendre moins fragiles et plus stables.
Dans le précédent article, nous avons évoqué plusieurs difficultés rencontrées dans les projets RAG:
- Saturation du disque par des fichiers temporaires nécessaires au chargement de fichiers venant de Cloud Storage ;
- instabilité des bases de données SQL et vectorielle, si un crash arrive au mauvais moment ;
- utilisation d’API synchrones interdite dans un environnement asynchrone, type FastAPI.
Nous allons vous proposer des solutions pour adresser ces difficultés.
Lectures de fichiers depuis un Cloud Storage
LangChain propose différentes approches pour extraire le texte de tout un tas de formats de fichiers. Le répertoire document_loaders en propose de nombreux.
La classe ConcurrentLoader() permet d’indiquer deux paramètres importants : un BlobLoader, dont le rôle est d’obtenir un blob depuis un fichier, et un BaseBlobParser avec toute une collection de parseur à partir d’un blob. Pour rappel, un blob est le contenu binaire du fichier.
Le seul BlobLoader proposé s'appuie sur un répertoire local. Cela est incompatible avec les clouds storages. Du coup, il n’est pas possible d’utiliser toutes les implémentations de BaseBlobParser à partir de fichiers venant du cloud. Cela est pourtant un scénario très courant.
Une alternative consiste à télécharger les fichiers du cloud localement, avant de les parser avec FileSystemBlobLoader(). Ce n’est pas idéal et présente le risque de laisser des fichiers temporaires localement, ce qui va saturer le disque du container. En général, les répertoires temporaires sont supprimés lors de la sortie de l’application. Comme il s’agit généralement de serveur d’API, ils ne sont jamais arrêtés, et donc les fichiers ne sont jamais détruits.
Nous proposons maintenant CloudBlobLoader(). C’est une copie presque parfaite de FileSystemBlobLoader() à la différence de ce dernier, la classe est initialisée avec une URL d’un cloud storage, de la forme s3://bucket/, az:/bucket/, gs://bucket/ ou file://bucket (Les authentifications utilisent les variables d’environnement habituelles).
root_dir="s3://bucket/"
loader = ConcurrentLoader(
blob_loader=CloudBlobLoader(root_dir, glob="/*.txt"),
blob_parser=TextParser(),
)
for doc in loader.lazy_load():
print(doc)
En utilisant MimeTypeBasedParser() pour le paramètre blob_parser, le choix du parseur peut s’effectuer par le type mime du fichier. Il est ainsi possible de lire des PDF ou tout type de fichier, directement depuis le cloud, sans fichier intermédiaire. Nous avons publié un pull-request pour cette nouvelle fonctionnalité, que vous retrouverez ici.
Rendre transactionnel l’import de document
Dans un projet RAG, une étape cruciale est l’alimentation de la base de vecteurs à partir de documents. Chaque document est découpé en chunk (fragments), un vecteur sémantique est calculé pour chaque chunk, puis chaque vecteur est ajouté à une base de vecteurs. Un identifiant unique est alors retourné pour identifier le vecteur d’embedding associé au chunk dans la base de vecteurs.
Si vous implémentez un RAG plus complexe, il est probable que chaque chunk subira différentes transformations avant d’enrichir la base de vecteurs.
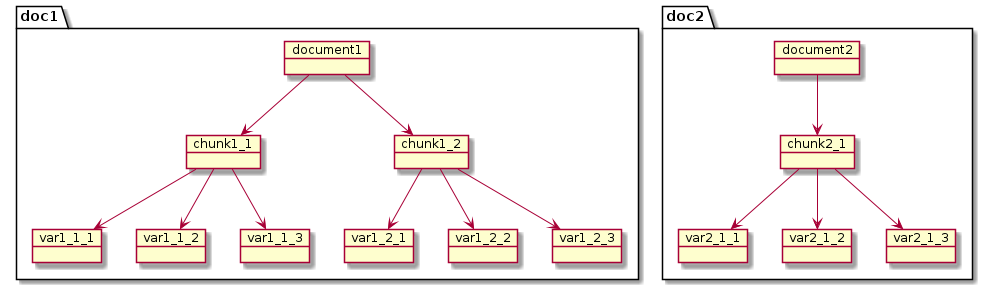
En effet, afin d’améliorer la proximité entre la question de l'utilisateur et les chunks disponibles, il est pertinent de proposer plusieurs vecteurs pour chaque chunk, plusieurs variations. L’un sera le vecteur classique, calculé à partir du chunk, puis d’autres vecteurs seront calculés pour des versions simplifiées du chunk (résumé) ou réduits à une question dont le chunk possède la réponse (les différentes variations dans le schéma). Ainsi, avec le vecteur de la question de l’utilisateur, on pourra calculer la proximité avec un chunk, son résumé et trois questions dont nous sommes certains que le chunk est capable de répondre. Il est fort probable que comparer un vecteur de questions avec un autre vecteur de questions soit plus efficace.
Nous proposons un composant Open Source (RagVectorStore) que nous avons présenté à la Grosse Conf, pour faciliter ce type de scénario.
Les problèmes arrivent lorsque l’on souhaite actualiser un document. En effet, il faut alors:
- Identifier qu’une mise à jour est véritablement nécessaire. Si le document n’a pas bougé, pourquoi calculer à nouveau le vecteur, générer des questions et autres transformations coûteuses en appel de LLM ?
- Garder le lien entre le document, les chunks associés et toutes les transformations correspondantes. Ainsi, il est possible de supprimer les vecteurs d’une ancienne version du document avant d’ajouter les nouveaux vecteurs pour la nouvelle version.
Pour gérer cela, LangChain nous propose une API dédiée : index(). Cette fonction a besoin d’avoir un lien avec deux bases de données via une clé unique. D’une part, un record_manager, généralement de type SQLRecordManager(), est chargé de garder la valeur de hash du contenu du document ainsi que les identifiants de tous les vecteurs associés aux chunks. D'autre part, une base de données vectorielle pour y stocker les vecteurs. Enfin, une clé ( ou une lambda), doit permettre d’extraire un identifiant unique pour chaque document.
index(
[doc1, doc2, doc3],
record_manager,
vectorstore,
cleanup=None,
source_id_key="source",
)
Question à 1000€ : il se passe quoi si le code crash au milieu de l’import ?
Il peut crasher pour de nombreuses raisons : une des bases de données est temporairement indisponible, une mise à jour de l’application à tuer le processus au mauvais moment, un chaos monkey a décidé, juste pour vérifier la résilience, de tuer des composants brutalement, kubernetes ou terraform décident de tuer un composant, d’effectuer un rolling-update, (voir les fallacies of distributed computing)...
C’est un problème complexe, important, qui empêche tous les projets LangChain d’être résilients. Par défaut, il n’est pas possible de proposer un projet résilient avec LangChain (version 0.2.0), puisqu’un crash lors de l’import casse la cohérence entre deux bases de données. Bonne chance pour réparer “à la main”, la cohérence entre les deux bases de données !
Naïvement, on peut se dire : “je n’ai qu’à importer de nouveau !”. Cela ne fonctionne pas. Vous allez avoir des vecteurs en doublons dans la base de vecteurs (ce qui dégrade la qualité des réponses - voir l’article précédent) ou des chunk référencés, mais inexistants.
L’application est cassée en profondeur, puisqu’il faut fixer les bases de données !
Comment régler cela ? Nous nous y sommes attelés et avons trouvé une solution.
Commit à deux phases ?
Le problème est complexe. Nous avons une fonction qui manipule deux bases de données hétérogènes. Une base SQL et une base de type vecteur.
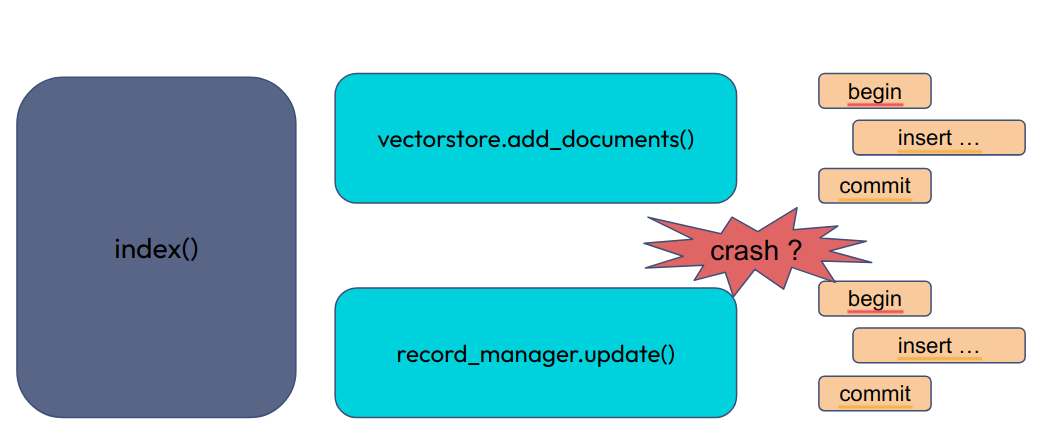
Nous souhaitons que l’import s’effectue complètement ou pas du tout. Qu’un crash, à tout moment, est équivalent à n’avoir jamais commencé l’import. En un mot, nous voulons un import transactionnel.
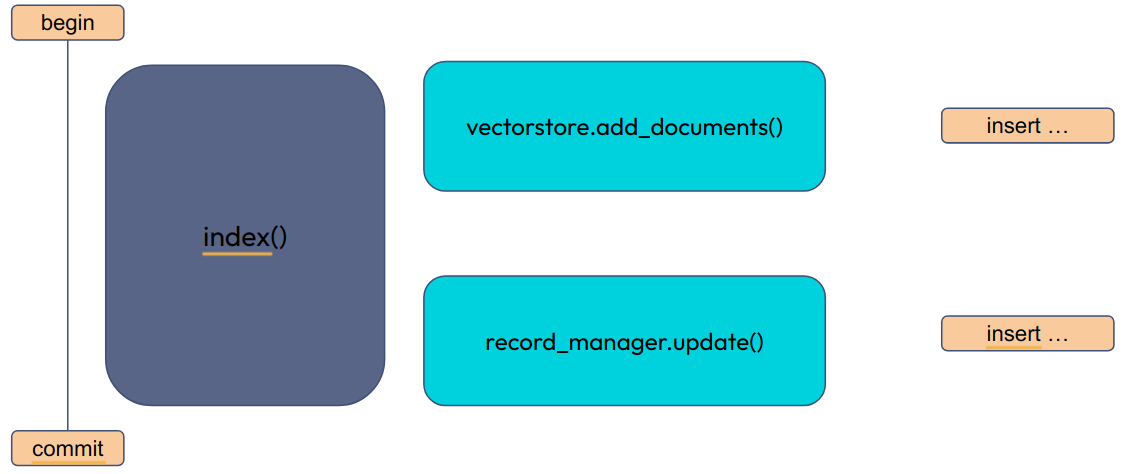
Il existe une technologie pour permettre à une transaction d’être appliquée à plusieurs sources de données: le commit à deux phases. Il faut que toutes les sources de données soient compatibles XA ( c’est un protocole de communication avec un gestionnaire de transaction, chargé d’orchestrer les différentes bases de données).
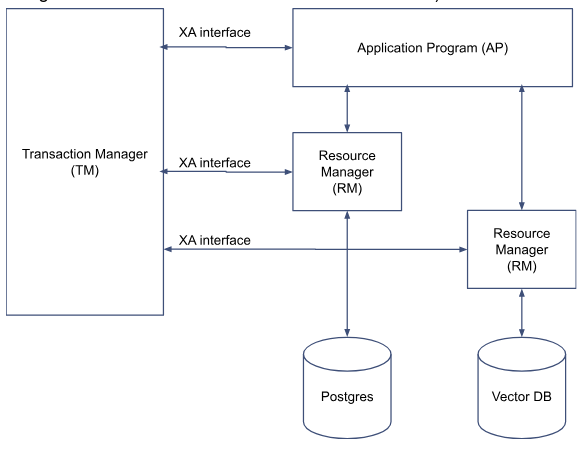
Pour être plus clair, prenons un scénario simple: un virement entre deux banques. Chaque banque possède sa base de données. Un virement ne doit, en aucun cas, être interrompu, sinon, soit les sommes disparaissent, soit le compte destinataire récupère le double de la somme. Le commit à deux phases consiste à réduire le délai de risque lors de la validation de la transaction. Dans la première phase d’une transaction, le gestionnaire de transaction demande à chaque partie s’il est prêt à valider la transaction, s’il n’y a pas de violation d’intégrité ou autre raison pouvant nécessiter un rollback. Lorsque tous les participants ont indiqué qu’ils étaient ok et prêts à valider rapidement la transaction en cours, la seconde phase commence. Elle consiste à envoyer un message à chacun pour l’informer de la valider irrévocablement.
Mais, que se passe-t-il si le système crash durant la deuxième phase ? D’abord, l’approche “commit à deux phases” est conçue pour minimiser au maximum la durée de la seconde phase. Cela réduit fortement la probabilité d’un crash à ce moment précis. Néanmoins, si une base tombe à ce moment-là, lors du redémarrage, elle saura qu’elle n’a pas encore terminé une transaction. Elle va contacter le gestionnaire de transaction pour lui demander quoi faire : valider ou invalider la transaction.
Bon, cela étant présenté, nous voyons bien que la seule façon d’avoir une unité transactionnelle lors de l’invocation de la méthode index(), est d’utiliser uniquement des sources de données compatibles XA, et de les paramétrer correctement. Et bien, à notre connaissance, il n’existe pas de base vecteurs compatibles XA.
Il nous reste quoi comme stratégie ? Mettre tout cela dans une seule transaction, dans la même base de données. Il se trouve que Postgres, avec l’extension PGVector, peut jouer les deux rôles dans notre scénario. Dans la même base de données, on peut y stocker la table pour le record manager et pour les vecteurs. Il faut réussir à encapsuler tout cela dans une seule et unique transaction.
Comment savoir si on y arrive ? Le meilleur moyen est probablement de demander les traces des requêtes SQL. Si vous constatez qu’il y a plusieurs BEGIN/COMMIT lors de l’import, ce n’est pas une bonne nouvelle. Il y a plusieurs transactions pour implémenter index(). Un crash peut arriver lors d’une modification partielle des bases de données.
Il se trouve que toutes les communications avec les bases de données SQL dans LangChain, utilisent SQLAlchemy. C’est un framework sympathique, permettant d’invoquer des requêtes SQL ou de sauver des objets, quelle que soit la base de données SQL sous-jacente. Nous allons utiliser des fonctionnalités subtiles de ce framework pour atteindre notre objectif.
Transaction synchrone
Regardons le code source de SQLRecordManager(). Nous avons de la chance : le code est bien écrit. Une instance de cette classe propose un attribut session_factory, probablement pour les traitements avancés que nous allons faire.
Qu’est-ce qu’un factory de session ? C’est une fonction ou une classe implémentant __call__(), dont le but est de créer une session SQL. Une session permet de délimiter une transaction. Au terme du traitement, on peut commiter ou rollbacker la session (et donc la transaction SQL).
Le code nous indique que l’attribut est initialisé avec sessionmaker().
Cela indique que dès qu’un traitement a besoin d’une session, on va créer une instance Session à partir de l’engine (le moteur de base de donnée). Cela explique pourquoi il y a une nouvelle transaction pour chaque traitement.
Nous constatons que cet attribut est utilisé dès qu’une session est nécessaire.
"""Check if the given keys exist in the SQLite database."""
with self.session_factory() as session:
records = (
session.query(UpsertionRecord.key)
.filter(
and_(
UpsertionRecord.key.in_(keys),
UpsertionRecord.namespace == self.namespace,
)
)
.all()
)
found_keys = set(r.key for r in records)
return [k in found_keys for k in keys]
C’est bien pour cela que l’attribut est présent. Pour permettre la manipulation de la création de session.
Notre idée est d’ouvrir une session, avant d’invoquer index(), et de s’arranger pour que toutes les sessions nécessaires à index() utilisent la session que nous avons créée. Pour cela, il existe un wrapper de sessionmaker, dont le rôle est de vérifier si une session n’est pas déjà ouverte. Si c’est le cas, alors elle est utilisée et aucune nouvelle session n’est alors créée.
scoped_session() est là pour cela. Comment cela fonctionne ? Via des variables de threads. L’idée est de créer une session, de la placer dans une variable de thread. Lorsque le factory est invoqué, le code vérifie si une session n’est pas déjà ouverte et associée au thread. Si c’est le cas, elle est utilisée.
session_maker = scoped_session(sessionmaker(bind=connection))
Mais, il y a une subtilité. Cela ne fonctionne que si la session est initialisée à partir de la connexion, et non à partir de l’engine. Pour regrouper toutes les sessions dans une seule requête SQL, nous initialisons sessionmaker sur la connexion. Un seul COMMIT à la fin.
Nous pouvons alors modifier le paramètre session_factory de record_manager avant le lancement de index().
record_manager.session_factory = session_maker
Nous avons partiellement réglé le problème. Il reste à faire de même pour PGVector. Nous avons proposé un PR (Add async mode for pgvector) pour permettre cela.
Le résultat final semble un peu compliqué, mais finalement, pas tant que cela. On encapsule l’invocation de index() dans une session, ouverte à partir d’une connexion.
db_url = "postgresql+psycopg://postgres:password@localhost:5432/"
engine = create_engine(db_url,echo=True)
embeddings = FakeEmbeddings()
pgvector = PGVector(
embeddings=embeddings,
connection=engine,
)
with engine.connect() as connection:
record_manager = SQLRecordManager(
namespace="namespace",
connection=connection,
)
record_manager.create_schema()
# Read this
session_maker = scoped_session(sessionmaker(bind=connection))
record_manager.session_factory = session_maker
pgvector.session_maker = session_maker
with connection.begin():
loader = CSVLoader(
"data/faq/faq.csv",
source_column="source",
autodetect_encoding=True,
)
result = index(
source_id_key="source",
docs_source=loader.load(),
cleanup="incremental",
vector_store=pgvector,
record_manager=record_manager,
)
connection.commit()
print(result)
Voilà. L’index() est exécuté dans une seule transaction. Notre code est résilient.
Regardons les traces. Attention, il existe des transactions complémentaires pour initialiser le schéma de la base de données ou pour ajouter l'extension vectorielles. Il ne faut pas en tenir compte. Ce qui nous intéresse est la transaction unique, s’occupant d’alimenter les différentes tables. Nous avons réduit les traces, pour insister sur ce qui nous captive : l’insertion dans deux tables, dans une seule transaction.
BEGIN (implicit)
…
INSERT INTO langchain_pg_embedding (id, collection_id, embedding, document, cmetadata) VALUES (...
INSERT INTO upsertion_record (uuid, key, namespace, group_id, updated_at) VALUES (...
COMMIT
Comment valider le code ? Il y a plusieurs stratégies:
- Ajouter des tests unitaires, avec un mock qui se charge de générer une exception au bon moment et de vérifier que les bases de données n’ont pas été modifiées ;
- Utiliser un chaos monkey, pour tuer aléatoirement des middlewares en production.
Il reste un problème à régler : la même chose en mode asynchrone. Comme évoqué dans l’article précédent, il n’est pas question d’utiliser des api synchrones manipulant les fichiers ou le réseau depuis une application asynchrone, comme une API FastAPI.
Transaction asynchrone
LangChain est un framework qui propose (presque) systématiquement deux API : l’une synchrone, à utiliser dans les notebooks ou dans un batch par exemple, l’autre asynchrone à utiliser dès qu’il s’agit d’exposer l’application sur le WEB. En général, une API asynchrone est reconnaissable par la présence de async et le nom de la méthode qui reprend le nom de la version synchrone, en ajoutant un a (def methode(): … async def amethode():...).
Nous avons résolu l’unicité transactionnelle dans le cas d’un accès synchrone à la base de données. Mais comment faire pour exposer une API WEB d’import des données ? Nous devons avoir un code similaire, mais asynchrone.
Il se trouve que PGVector ne propose pas d’implémentation asynchrone (langchain v0.2.0). Il est donc impossible de proposer une approche résiliente et asynchrone !
Pour régler cela, nous proposons un Pull Request qui ajoute toutes les API asynchrone pour PGVector.
Au niveau de l’encapsulation de la transaction mère, il n’est plus possible d’utiliser scoped_session() puisque nous ne travaillons plus dans des threads, mais dans des tâches asynchrones. Une alternative est possible.
session_maker = async_scoped_session(
async_sessionmaker(bind=connection),
scopefunc=current_task)
La classe async_scoped_session permet d’implémenter l’équivalent à une variable de thread, mais pour une tâche asynchrone. Il faut juste lui indiquer quel identifiant utiliser (scopefunc=current_task).
Une petite limitation de LangChain, nous interdit de valoriser session_maker. Un PR (Make sql record manager fully compatible with async), nous permet maintenant de pouvoir le faire.
Nous pouvons désormais proposer une invocation asynchrone de aindex().
db_url = "postgresql+psycopg://postgres:password@localhost:5432/"
engine = create_async_engine(db_url, echo=True)
embeddings = FakeEmbeddings()
pgvector = PGVector(
embeddings=embeddings,
connection=engine,
)
record_manager = SQLRecordManager(
namespace="namespace",
engine=engine,
async_mode=True,
)
await record_manager.acreate_schema()
async with engine.connect() as connection:
session_maker = async_scoped_session(
async_sessionmaker(bind=connection),
scopefunc=current_task)
record_manager.session_factory = session_maker
pgvector.session_maker = session_maker
async with connection.begin():
loader = CSVLoader(
"data/faq/faq.csv",
source_column="source",
autodetect_encoding=True,
)
result = await aindex(
source_id_key="source",
docs_source=loader.load()[:1],
cleanup="incremental",
vector_store=pgvector,
record_manager=record_manager,
)
await connection.commit()
print(result)
Pour garder la compatibilité avec SelfQueryRetriever, nous devons à nouveau proposer un PR : Add pgvector to list of supported vectorstores in self query retriever.
Rendre transactionnelle la sauvegarde de l’historique des messages
Nos travaux ont également montré des difficultés d’implémentation dans les classes SQLChatMessageHistory et PostgresChatMessageHistory. Nous avons complètement revu l’implémentation asynchrone dans un PR. Maintenant, en plus d’un fonctionnement correct en asynchrone, l’ajout d’une liste de messages (constituant un échange), est sauvegardée dans une seule transaction. Ce risque d’instabilité est fixé.
Enfin…
Dans l’article précédent, nous avons évoqué la rigueur nécessaire à avoir, lors du développement, dans l’utilisation systématique des apis async. Nos travaux nous ont fait identifier de nombreux manques dans LangChain. Nous les avons systématiquement corrigés à l’aide de PR dédiés :
- Add native async support to SQLChatMessageHistory
- Add SQL storage implementation
- Make EmbeddingsFilters async
- Add native async implementation to LLMFilter, add concurrency to both sync and async paths
- …
Pour conclure
Après un effort important, nous avons réussi à permettre la résilience d’une application RAG avec LangChain.
Dans le cadre de nos travaux, pour durcir les applications LLM, nous avons été amenés à proposer de nombreuses Pull-Request à LangChain, afin de compléter les API, ou de régler des problèmes nous interdisant de rendre notre application résiliente. Nous avons pratiquement revu toutes les interactions principales entre LangChain et les Sqlachemy ;-)
Publier un PR ne veut pas dire qu’il sera rapidement accepté. Loin de là. Nous avons des PR ouvert depuis plusieurs mois, pourtant capables de réduire la facture ou l’empreinte carbone, sans validation de l’équipe en charge du projet. À défaut, il est toujours possible de déclarer une dépendance vers le fork de la PR, ou d’intégrer les nouvelles classes ou les patchs, directement dans votre projet.
Ce n’est pas parce que des milliers de projets LangChain ne sont pas résilients, qu’on doit faire de même !
Bonne nouvelle, tous nos PR autour de ce sujet ont été validé. Langchain peut maintenant être résilient, à condition de l’utiliser correctement. Pour cela il faut utiliser au minimum les versions suivantes:
- Langchain-core ^0.2.7
- Langchain-community ^0.2.5
- Langchain ^0.2.5
- Langchain-postgres ^0.0.7
Comme on dit chez OCTO: This is a better way