Mettre en place un assistant de code souverain
Dans un contexte de tension autour de la souveraineté numérique, les assistants de code pilotés par intelligence artificielle ne font pas exception. En pleine effervescence, ce secteur voit émerger de nombreuses solutions aux côtés des précurseurs comme Microsoft GitHub Copilot ou TabNine. Nous montrons dans cet article comment, grâce à l'élargissement de l’offre, il est possible de mettre à la disposition de nos développeurs un assistant de code souverain à partir d’éléments standards..
Les éléments de son assistant de code souverain
Le marché est en ébullition, on est passé de l’auto-complétion “multi-ligne” (2023) au chat (2024) et aux agents (2025) qui prennent en charge des tâches complètes pouvant aller jusqu’à l’exécution et le test du code généré.
Les IDE jouent un rôle clé : Visual Studio Code et IntelliJ proposent une intégration profonde avec ces assistants via des plug-ins. Certaines solutions (Continue.dev, Tabby) permettent de connecter des modèles LLM au choix. D’autres solutions viennent de manière toute intégrée (Cursor, Claude Code, Firebase studio…)
D’un point de vue technique il existe deux types de fonctionnements :
- Serveur intermédiaire propriétaire (A) : Le plug-in, installé dans l’IDE, se connecte à un serveur du fournisseur qui sollicite ensuite de manière plus ou moins opaque le LLM. C’est le fonctionnement de la plupart des produits commerciaux comme par exemple GitHub Copilot,
- Accès Direct (B) : Le plug-in accède directement à un LLM qui est en général paramétrable. C’est le fonctionnement courant des outils open source.
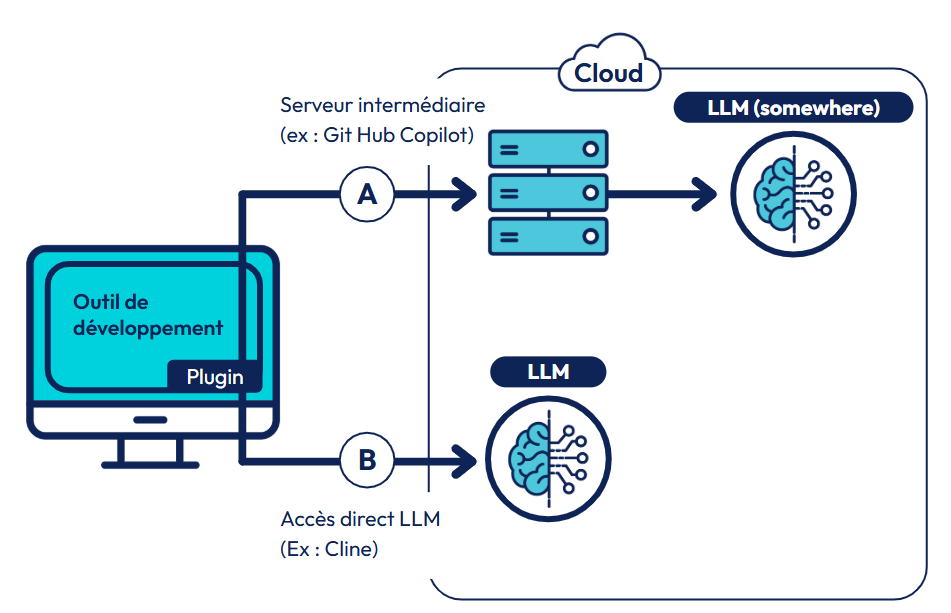
La mise en place d’un assistant de code souverain implique que les différents serveurs soient souverains. L’architecture à base de serveurs intermédiaires (flux “A” sur le schéma) n’est pas adaptée car à l’heure actuelle ces serveurs intermédiaires ne sont pas disponibles sur des infrastructures souveraines. Ces solutions sont fournies principalement par des entreprises nord-américaines et tournent sur des infrastructures de type Azure, Google ou AWS.
La mise en place d’un assistant de code souverain passe donc par :
- Le choix d’un plug-in fonctionnant sans serveur intermédiaire “cloud” et permettant de choisir le LLM cible (Flux B sur le schéma)
- La mise en place d’un LLM souverain
Le choix du plug-in n’est pas très complexe car l’offre n’est pas pléthorique si on se limite à ceux qui ont une architecture “souveraine”. Par contre les options sont plus ouvertes sur la mise en place du LLM souverain, regardons ça de plus prêt.
Les offres évoluent, par exemple GitHub Copilot offre maintenant une option BYOK (Bring your own model key). Dans ce mode les requêtes vers le LLM vont suivre le flux “B”... mais uniquement pour le type d’interaction selectionné, de plus “The Copilot API is still used for some tasks, such as sending embeddings, repository indexing, query refinement, intent detection, and side queries”.
Les options pour le LLM souverain
On distingue deux types de modèles (ou LLMs) :
- Les modèles ouverts (open-source ou open-weight comme Codestral, QwenCoder, Deepseek) qui peuvent être exécutés n’importe où et sont largement disponibles
- Les modèles fermés (GPT-4o/5, Claude Sonnet) qui sont disponibles via API chez des fournisseurs autorisés (LLM as a Service). Certains fournisseurs, comme Mistral, fournissent aussi des possibilités de licences pour exécution chez leurs clients.
Les modèles fermés sont actuellement les plus performants, mais les modèles ouverts progressent très vite et constituent maintenant une alternative qui tient la route. Ces modèles ouverts sont proposés en mode LLM as a Service par un nombre croissant de “Cloud provider souverains”, comme par exemple Scaleway (https://www.scaleway.com/en/docs/generative-apis/reference-content/supported-models/). Exemple de modèles : Codestral 2501 – Mistral, QwenCoder 2.5 – Alibaba, DeepSeek Coder – DeepSeek, LLaMA 3 – Meta
La performance des modèles en terme de pertinence dépend de la tâche (chat, génération, autocomplétion) de nombreux benchmarks en ligne permettent de suivre les évolutions (Livebench, Aider,Codestral Benchmarks)
Du point de vue de l’hébergement du LLM (ou modèle) il y a techniquement 3 options
- LLM as a Service : Le modèle est exécuté sur l’infrastructure d’un fournisseur et est appelé via API. C’est le mode le plus courant pour les modèles fermés et ouverts. Dans notre contexte, l’enjeu est de trouver un fournisseur souverain, ce qui est maintenant possible.
- LLM privé: Exécuter le modèle sur des infrastructures privées, en général fournies par un fournisseur cloud, souverain bien sûr.
- Poste de Dev : Exécuter le modèle sur le poste du développeur
La performance des modèles en termes de rapidité dépend de l’infrastructure sous-jacente. Les modèles accédés par API (LLM as a Service) sont très rapides. Monter une infrastructure d'auto hébergement (LLM privé) uniquement pour un usage d’assistant de code ne nous semble pas adapté dans la majorité des cas du fait de sa complexité et des évolutions rapides matérielles et logicielles. Par contre cela peut être une option si une infrastructure “IA” existe déjà dans l’entreprise ou peut être partagée avec d’autres usages.
Le déploiement de LLM sur le poste du développeur. Est techniquement possible, cependant nous ne recommandons pas cette option
Nous ne recommandons pas le déploiement de LLM en poste local pour les raisons suivantes :
1-Caractéristiques machines : Les caractéristiques nécessaires en termes de calcul (GPU) et mémoire sont loin de celles des postes de développeur actuels. Par exemple, le modèle devstral de Mistral, parmi les plus légers, “se contente” (https://mistral.ai/news/devstral) d’une GPU RTX4090 ou d’un Mac avec 32GB de RAM.
2-Pertinence : pour pouvoir faire tourner les modèles nous avons dû opter pour une quantification qui dégrade la qualité des réponses du LLM et donc le bénéfice d'utilisation.
3-Vitesse de génération : Nos tests ont montré qu’avec une machine puissante (MAC Book Pro 32GB) et un modèle quantifié (Qwencoder2.5_7B_q4_K_m) , le débit de génération est acceptable pour de l’autocompletion mais trop lent pour les autres applications (chat). Avec un affichage “mot à mot” on se retrouve de l’ordre d’un ordre de grandeur plus lent que via API. De plus, la machine chauffe énormément.
En conclusion l’utilisation de LLM as a Service souverain est la voie généralement à privilégier : choix, performance, flexibilité
Exemple de mise en place pratique
Comme présenté dans le début de l’article, la mise en place d’un assistant de code souverain consiste à choisir un plug-in compatible avec son IDE et un LLM souverain. Nous proposons ici des outils qui correspondent aux exigences de souverainetés que nous avons détaillées.
Etape 1 : choix du plug-in
Le développement d’un plug-in maison n’est pas conseillé : les fonctionnalités des LLMs évoluent de manière très rapide et il serait rapidement dépassé. Il est préférable de choisir un plug-in du marché compatible avec l’IDE utilisé par les développeurs. Par exemple “continue.dev” qui est open source. Le choix du plug-in n’est pas “engageant” et on peut imaginer utiliser plusieurs plug-in pour des usages différents, par exemple Continue.dev et Cline.
Etape 2 : choix des modèles à utiliser
Continue.dev permet de spécifier différents modèles d’IA suivant les fonctions. Les critères de choix sont la puissance du LLM et sa disponibilité en hébergement souverain, local à l’entreprise ou en mode LLM as a Service. Pour répondre à ces critères on peut, à l’heure actuelle choisir Codestral ou QwenCoder.
- Chat : Codestral (via Mistral API), QwenCoder (via Scaleway)
- Autocomplete : Codestral 2501 (Mistral)
- Embedding : Mistral-embed, bge-multilingual-gemma2
Comme discuté plus haut, nous recommandons de démarrer avec un LLM as a Service sur cloud européen car cela permet :
- Un déploiement rapide
- Un accès aux derniers modèles
- Un coût à l’usage (en token)
- Aucune infrastructure à gérer
Les coûts sont de l’ordre de 1 ou 2 euros par million de token. Un développeur peut consommer un million de tokens par jour suivant son usage. L’utilisation du mode “agent” (appelé aussi plan/act) peut très fortement augmenter cette consommation, par exemple j’ai pu observer une augmentation de facteur 10.
Alternativement il est possible de se brancher sur le LLM Claude Sonnet disponible sur AWS Bedrock. Cette solution n’est pas complètement souveraine, mais elle permet d’accéder à un des meilleurs modèles actuels sur une infrastructure hébergée en Europe (par exemple eu-west-3) et avec un engagement à ce que les données ne sont pas communiquées pour l'entraînement de modèles (référence AWS Bedrock)
Monitoring et évolution
L’offre en plug-in, LLMs et LLM as a Service évolue littéralement de jour en jour. Il est donc crucial de réexaminer les choix régulièrement, par exemple tous les trimestres.
Cet examen tiendra compte de trois éléments:
- Conservation du caractère souverain : vérifier qu’aucune évolution n’a brisé le caractère souverain de la configuration
- Usage observé : retour des développeurs, consommation, performance, coût
- Evolutions de l’offre : évolution des plug-ins,, nouveaux plug-in, nouvelles propositions de LLM as a Service
Il est possible de faire évoluer son hébergement ou même d’héberger les modèles sur son propre cloud. Cette dernière option est plus complexe à mettre en œuvre et nécessite une étude de ROI car les ressources physiques et les modèles évoluent très rapidement.
Conclusion
La disponibilité de plug-in “assistant de code” open-source, de LLMs open-weight/open source et de LLM As A Service souverain ouvrent la voie à la mise en œuvre aisée d’assistants de code souverains.
Nous préconisons la démarche suivante
👉 Commencez avec des outils sur étagère : Continue.dev, API Scaleway, modèle Codestral. En prenant en compte les critères suivants :
- L’expérience développeur (intégration IDE, confort d’usage, capacité du modèle, temps de réponse)
- Les coûts (fortement dépendant du cas d’utilisation)
- Le niveau de souveraineté
👉 Mesurez les usages et les coûts : nombre de tokens, performance perçue
👉 Envisagez de faire évoluer le mode d’hébergement vers de l’interne si le ROI le justifie
Le marché bouge très vite : nouveaux modèles chaque mois, offres commerciales en évolution, nouvelles régulations. Il faut par conséquent éviter des investissements lourds et à trop long terme et privilégier une approche modulaire (briques existantes) et réversible.
Ressources
- Copilot BYOK : https://code.visualstudio.com/docs/copilot/customization/language-models
- Open weight : https://www.wildcodeschool.com/blog/open-source-vs-open-weight-quelles-diff%C3%A9rences
- Quantification : https://www.ibm.com/fr-fr/think/topics/quantization
- Outil Continue.dev : https://www.continue.dev/
- Outil Cline :https://cline.bot/
- LLM as a Service chez Scaleway : https://www.scaleway.com/en/generative-apis/
- AWS bedrock sercurité : https://aws.amazon.com/fr/bedrock/faqs/, https://aws.amazon.com/fr/bedrock/security-compliance/ et https://docs.aws.amazon.com/bedrock/latest/userguide/data-protection.html