Compte-rendu – Le Comptoir OCTO Données synthétiques : le nouveau carburant caché des modèles d'IA
Ce compte-rendu fait écho au replay vidéo du comptoir sur les données synthétiques, disponible ici, animé par Louison Roger (Senior ML Engineer @ OCTO), ainsi que André Amalor (Expert Données Synthétiques @ OCTO) qui sont intervenus sur plusieurs projets nécessitant l’usage de ces données synthétiques pour entraîner des modèles d’IA.
L’intitulé de cet article est certes prometteur et reflète aujourd’hui tout l’intérêt que nous portons à l’utilisation d’un nouveau genre de données: les données synthétiques. Oui, les données synthétiques peuvent être considérées comme le nouveau carburant caché et un levier d'accélération de l'entraînement de nos modèles d'IA, notamment dans les cas d’usage liés à l’inspection visuelle. Aussi, nous allons montrer, dans cet article, comment les données synthétiques sont en train de révolutionner le domaine de l'intelligence artificielle (IA).
Elles offrent une solution innovante pour surmonter les défis liés à la génération de données, à leur annotation et aux exigences réglementaires liées à la protection des données. Cet article va proposer un aperçu de l'utilité et des avantages des données synthétiques à travers des cas d'application concrets. Il va se diviser en 4 parties distinctes:
- Quelques petits rappels sur l’IA 🧠 et son fonctionnement ⚙️
- Quel est l’intérêt des données synthétiques❓
- Exemples d’application de ces données synthétiques à la Computer Vision 📸
- Enfin, une illustration avec un REX de contrôle qualité 🔎 dans l’aéronautique ✈️
Embarquons pour le monde passionnant et innovant des données synthétiques.
Quelques petits rappels sur l’IA 🧠 et son fonctionnement ⚙️
Avant de démarrer l’aventure, il convient de revenir aux bases de l’IA et de rappeler comment les modèles d’Intelligence Artificielle fonctionnent et les conditions pré-requises. Les données sont le point de départ pour construire un modèle d’IA. Celles-ci peuvent être structurées (comme les fichiers SQL, CSV) ou non structurées (comme les textes, images, audios et vidéos). Pour créer un modèle d'IA supervisé performant et robuste, les données non structurées doivent être contextualisées et annotées. Ces données ont un rôle crucial dans l’IA. Il convient de respecter les différentes étapes de création d’un modèle d’IA supervisé:
Acquisition de données : Collecte de données brutes.
Annotation : Ajout de labels et de métadonnées pour contextualiser les données.
Entraînement : Utilisation des données annotées pour entraîner le modèle.
Test/Validation : Évaluation des performances du modèle sur des données de test.
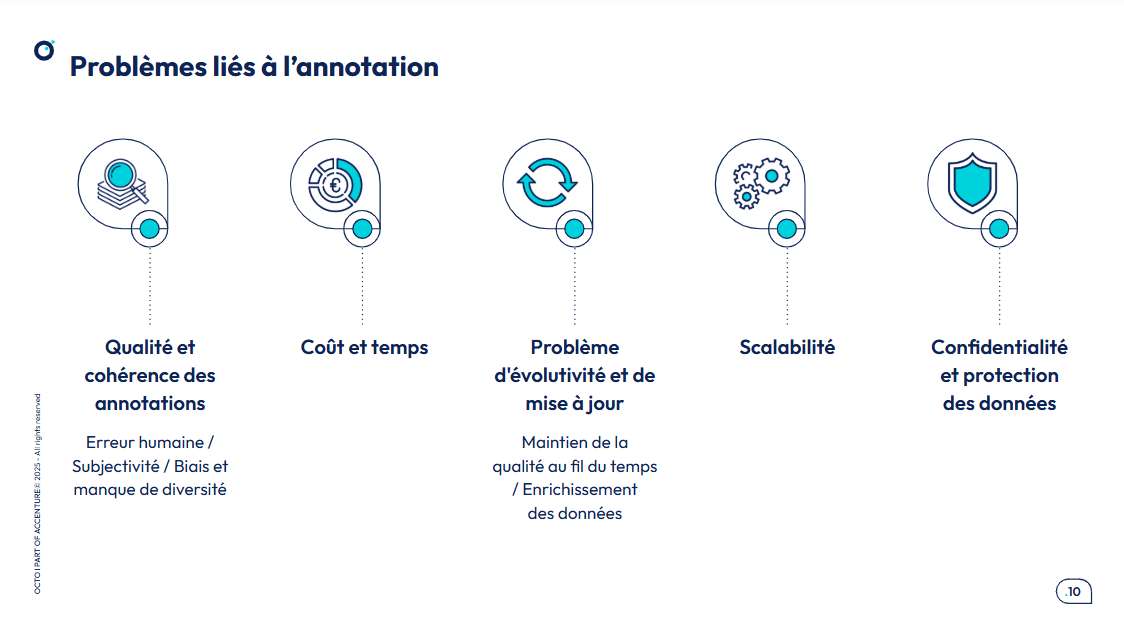
La phase d’annotation des données présente plusieurs défis. En effet, l'annotation des données est une étape critique mais souvent coûteuse et sujette à des erreurs humaines, des biais et des problèmes de diversité voire de disponibilité de la donnée. De plus, maintenir la qualité des annotations au fil du temps et assurer la scalabilité tout en protégeant la confidentialité des données restent des challenges majeurs au quotidien.
Les problèmes courant sont:
Quel est l’intérêt des données synthétiques❓
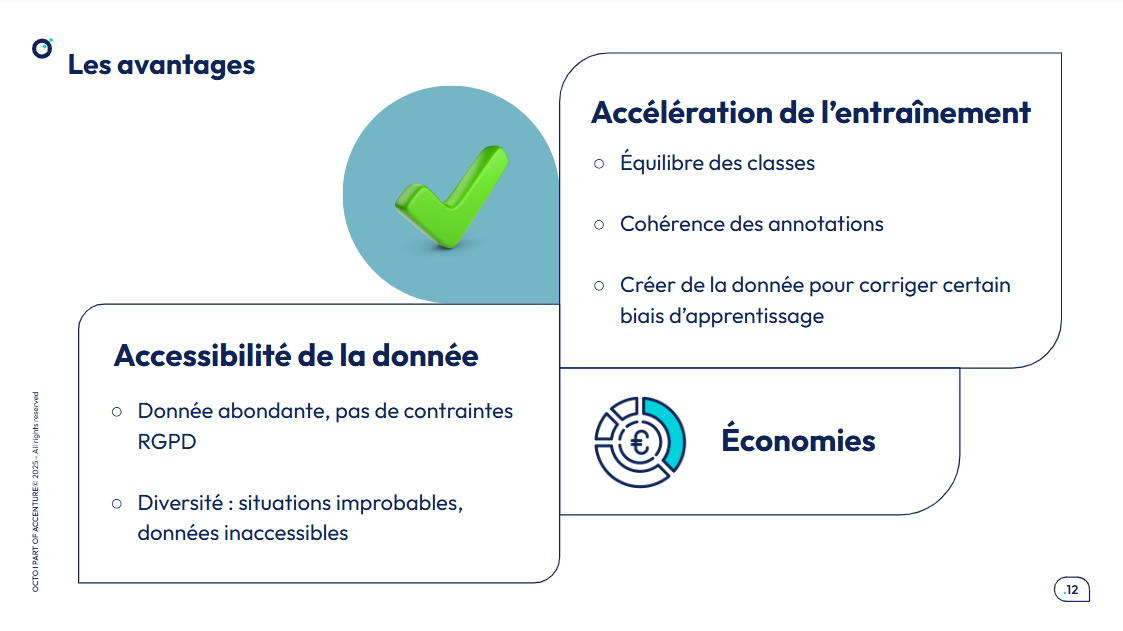
Aussi, les données synthétiques offrent plusieurs avantages qui les rendent particulièrement attractives pour l'entraînement des modèles d'IA: accélération de l’entraînement et accessibilité de la donnée.
Les cas d’application de l’utilisation de données synthétiques sont assez nombreux:
- Traitement du Langage Naturel (NLP) :
- Amélioration de la compréhension et de la génération de texte (analyse de sentiments, dialogue avec des chatbots, traduction automatique, reconnaissance d’entités,...).
- Utilisation de données synthétiques pour entraîner des modèles NLP à comprendre et générer du texte de manière plus précise.
- Reconnaissance Vocale :
- Entraînement de modèles de reconnaissance vocale (reconnaissance d’accents ou de dialectes, bruits de fond, voix synthétiques,...).
- Génération de données vocales synthétiques pour améliorer la précision des modèles de reconnaissance vocale.
- La vision par ordinateur qui va être le point focal de la suite de cet article. Les deux prochaines parties de cette synthèse vont se focaliser sur des cas concrets faisant appel à des données synthétiques utilisées pour entraîner des modèles d’IA pour faire de l’inspection visuelle, donc plutôt dédiées à traiter des données de type images ou vidéos.
Exemples d’application de ces données synthétiques à la Computer Vision 📸
Après avoir effectué les rappels nécessaires concernant le fonctionnement des modèles d’IA et montré tout l’intérêt de travailler avec des données synthétiques, il est temps d’entrer dans le vif du sujet et notamment citer des exemples concrets d’utilisation de ces données synthétiques lors de projets implémentant des algorithmes d’IA, liés à de l’inspection visuelle.
Dans le secteur industriel, les données synthétiques sont utilisées notamment pour développer des modèles d’AI pour faire de l’inspection visuelle :
- Dans la production pour accélérer les développements des cas d’usage d’inspection qualité basée sur des images ou des vidéos.
- Pour des applications industrielles d’inspection et de robotique.
- Dans le cadre des voitures autonomes pour enrichir les données d'entraînement.
Des exemples concrets permettent d’illustrer comment ces données synthétiques peuvent contribuer à accélérer et faciliter la mise en oeuvre opérationnelle des cas d’usage:
- Pour de la détection de défauts sur des pneus :
- Utilisation de la génération d'images virtuelles pour entraîner des modèles à détecter des défauts sur des pneus avant leur fabrication.
- Au cours de ce projet, on a inséré des défauts connus sur des images "neutres" réelles, ce qui nous a permis d'obtenir un dataset équilibré.
- Pour de de la détection de points chauds sur le fuselage de fusée :
- Grâce à la modélisation 3D et la génération de défauts, des données sont générées pour entraîner un modèle d’IA visant à identifier des anomalies sur le fuselage.
- Ce cas d'usage inclut la modélisation 3D, la génération de défauts, l'entraînement du modèle et les tests sur des données réelles via un prototypage.
Un exemple d’application de ces données synthétiques à la Computer Vision 📸
Afin de terminer le voyage dans le monde des données synthétiques, rien ne vaut la démonstration par l’exemple d’un cas d’usage concret et bien réel. Ce cas d’usage s’est déroulé lors d’une problématique de contrôle Qualité dans l'Aéronautique. En utilisant des données synthétiques, une solution mobile a été développée pour détecter les plis sur des sièges d'avion, réduisant ainsi les coûts de non-qualité et augmentant la précision des inspections.
La problématique initiale était le développement d’un modèle d’Intelligence Artificielle pour réaliser de l’inspection visuelle qualité de sièges d’avion. L’objectif de cette inspection était de détecter les défauts présents sur les sièges lors de la réception avant d’être montés dans l’avion. Ces défauts divers peuvent aller du simple pli jusqu’à un accroc en passant par diverses typologies définies par les équipes métier en charge habituellement du contrôle qualité.
- Inspection manuelle : Soumise à des erreurs et coûteuse.
- Remplacement des sièges défectueux : Engendre des coûts élevés.
La solution s’est portée sur le développement d'une solution mobile de type “lunettes connectées” ou “smartphones” pour détecter les plis sur les sièges. Le modèle d’IA développé pour faire la détection automatique a été entraîné avec des données synthétiques.
- Exploitation de données synthétiques pour entraîner une IA capable de détecter les plis avec précision.

Les avantages d’une telle approche innovante ont été:
- Développement accéléré : inspection plus rapide.
- Coût réduit : Réduction des coûts liés aux inspections et aux remplacements.
- Précision accrue : Moins d'erreurs humaines et plus de cohérence dans les inspections.
Afin d’arriver à un tel résultat, le processus de création et de développement du modèle d’IA pour l’inspection visuelle a été le suivant:
- Modélisation 3D de Siège :
- Un modèle de siège spécifique a été choisi pour le Proof of Concept (PoC).
- Création de l'environnement 3D :
- Utilisation du moteur de jeu UNITY pour créer un environnement réaliste avec éclairage et ombres personnalisables.
- Création des défauts :
- Utilisation d'Adobe Substance et de l'IA générative pour créer des défauts réalistes.
- Génération aléatoire des défauts :
- Randomisation des défauts en termes de forme, transformation et intensité.
- Création de l'environnement d’acquisition :
- Intégration des défauts visibles sur le siège et acquisition des images pour le dataset.
Conclusion
Les données synthétiques ne remplacent pas complètement les données réelles, mais elles les complètent de manière significative et pertinente. Un entraînement mixte combinant données synthétiques et réelles avec un ratio de 15% de données réelles est recommandé pour obtenir des modèles d'IA plus performants et fiables.
En conclusion, l'utilisation de données synthétiques pour entraîner des modèles d'intelligence artificielle dans le domaine de l'inspection visuelle représente une avancée significative et prometteuse. Ces données, générées artificiellement, permettent de surmonter plusieurs défis inhérents à l'utilisation de données réelles. En premier lieu, elles offrent une solution efficace au problème de la rareté des données annotées, souvent coûteuses et chronophages à obtenir. Grâce aux données synthétiques, il est possible de créer des ensembles de données vastes et diversifiés, couvrant une multitude de scénarios et de variations qui seraient autrement difficiles à capturer.
En somme, les données synthétiques constituent un outil puissant et indispensable pour le développement de modèles d'IA performants dans le domaine de l'inspection visuelle. Elles offrent des avantages considérables en termes de coût, de flexibilité et de qualité des données, tout en permettant de surmonter les limitations des approches traditionnelles. À mesure que la technologie continue d'évoluer, il est essentiel de continuer à explorer et à exploiter le potentiel des données synthétiques pour repousser les frontières de ce qui est possible avec l'intelligence artificielle.
Pour en savoir plus sur les dernières avancées en matière de données synthétiques et d'IA, n’hésitez pas à contacter les experts d’OCTO Technology et découvrez notamment nos formations et conférences à venir.