Détection d'anomalies visuelles automatique : faut-il apprendre du défaut ou de la normalité ?
Imaginez être chargé de détecter un produit défectueux dans une usine, une image violente sur un réseau social, ou encore une zone suspecte sur une radio médicale. Trois univers, un même enjeu : détecter l’anomalie avant qu’elle ne coûte — que ce soit en argent, en sécurité ou en santé. Néanmoins, l'œil humain ne peut inspecter des centaines de produits par minute, ni être toujours vigilant et concentré à 100%.
Les modèles de vision, appartenant au domaine de l’IA, ont la capacité d’automatiser cette vigilance, tout en permettant de traiter des volumes d’images élevés. Mais cela soulève une question stratégique : faut-il montrer des exemples de défauts au modèle (supervisé) ou le laisser apprendre seul la normalité (non supervisé) ?
Le choix n'est pas technique, il dépend majoritairement des contraintes opérationnelles. Cet article explique le fonctionnement des méthodes supervisées, et non supervisées sur un cas réel (production de vis industrielles). Il introduit deux exemples de métriques pour évaluer un modèle de détection d’anomalies, et explicite les critères de décision selon vos contraintes opérationnelles.
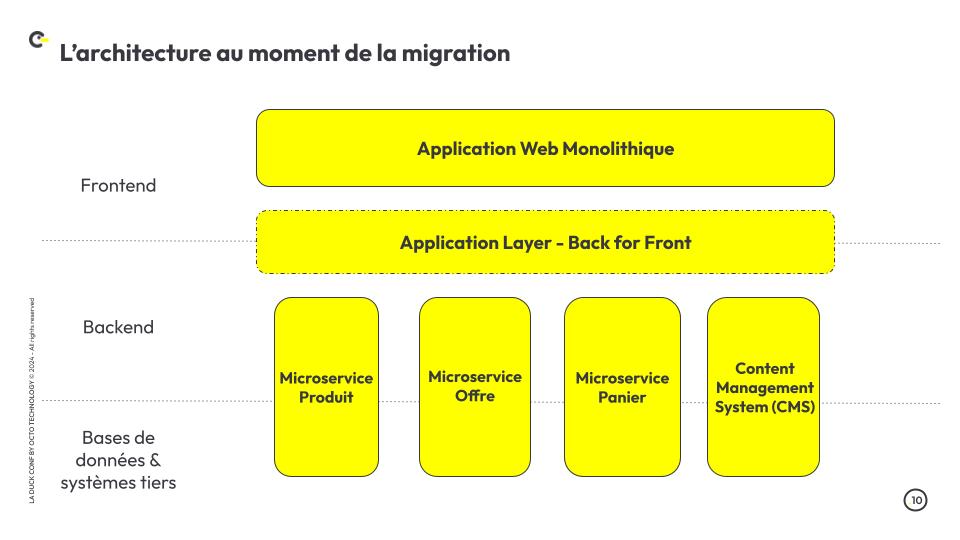
Méthode de détection automatique d’anomalies visuelles
Comment un algorithme voit une image ?
Dès la démocratisation de l’informatique et des appareils photos, le traitement d’images automatique est devenu un challenge. Puis, avec le temps, et l’explosion du volume d’images produites, c’est devenu une nécessité. Au cœur de cela, les modèles de vision. C’est le nom que l’on donne aux algorithmes qui effectuent des tâches à partir d’images (classification, détection d’objets, …).
Avant de comprendre les modèles de vision, il est important de rappeler qu’une image est un tableau multidimensionnel contenant des valeurs numériques. Chaque nombre stocké dans ce tableau représente l’intensité lumineuse mesurée par le capteur de l’appareil photo.
Au sein d’une image, les valeurs d’intensité lumineuse sont organisées (Figure 1). Tout d’abord, chaque intensité est associée à une paire de coordonnées spatiales (row, column). Cela permet de savoir sur quelle zone de l’image afficher cette intensité lumineuse. De plus, l’intensité lumineuse peut être décrite de plusieurs manières : par un seul nombre (ex : niveau de gris), ou par un vecteur décrivant plusieurs intensité de couleurs (ex : RGB).

Figure 1 - Structure d’une image RGB de résolution 3x3.
Cette définition permet de mettre en lumière une notion fondamentale. Lorsqu'un humain regarde une image, il interprète les pixels et leur donne un sens (ex : un chien, une voiture, de l’herbe, …). Lorsqu’un modèle de vision regarde une image, il ne voit qu’un ensemble structuré de pixels. Et c’est bien là sa limite.
Prenons un exemple. Je pose mon appareil photo sur un trépied, et je prends une première photo de ma tasse de café posée sur mon bureau. Ensuite, je le décale d’un centimètre vers la droite, et réduit très légèrement la luminosité en baissant les volets roulants. Je prends une seconde photo. Je donne ensuite les deux images à un modèle de vision qui les compare, pixel par pixel. Le résultat ? Le décalage rompt l’alignement des pixels, la luminosité modifie les intensités. Pour le modèle de vision, les deux images n’ont rien avoir.
Les pixels décrivent la structure complète d’une image, pas ce qu'elle représente. Analysés de manière isolée, ils fournissent une information qui n’est ni stable, ni globale.
Si on reprend notre exemple, on aimerait que notre modèle de vision détecte une tasse de café dans les deux images, et non pas un léger changement d’environnement. Il faudrait essayer d’identifier des groupes de pixels caractéristiques, qui sont présents dès lors qu’il y a une tasse de café dans l’image. C’est ce que l’on appelle des motifs (ou patterns en anglais).
Malgré les conditions légèrement différentes, nos deux images de tasse contiennent sensiblement les mêmes motifs caractéristiques. Par exemple, un contour circulaire, une anse en forme de crochet et une surface intérieure aux pixels homogènes et sombres (le café).
Ces motifs se traduisent d'une certaine manière à travers les pixels de l'image. Le contour circulaire de la tasse, par exemple, est une transition abrupte d'intensité lumineuse : d'un côté les pixels clairs de l'arrière-plan, de l'autre les pixels sombres de la céramique. Ce n'est pas un pixel isolé qui le définit, mais la relation entre plusieurs pixels voisins.
Un motif plus complexe, comme l'anse, est lui-même composé de motifs plus simples : des bords courbes qui forment un arc, une surface intérieure aux pixels homogènes, un contraste marqué avec le fond. Le motif "anse" émerge de la combinaison de ces structures élémentaires.
En utilisant des motifs pertinents, on est capable de lire la sémantique d’une image à travers sa structure (Figure 2).
Alors, plutôt que de comparer des pixels, on cherche des motifs au sein d’une image.
 |  |
|---|---|
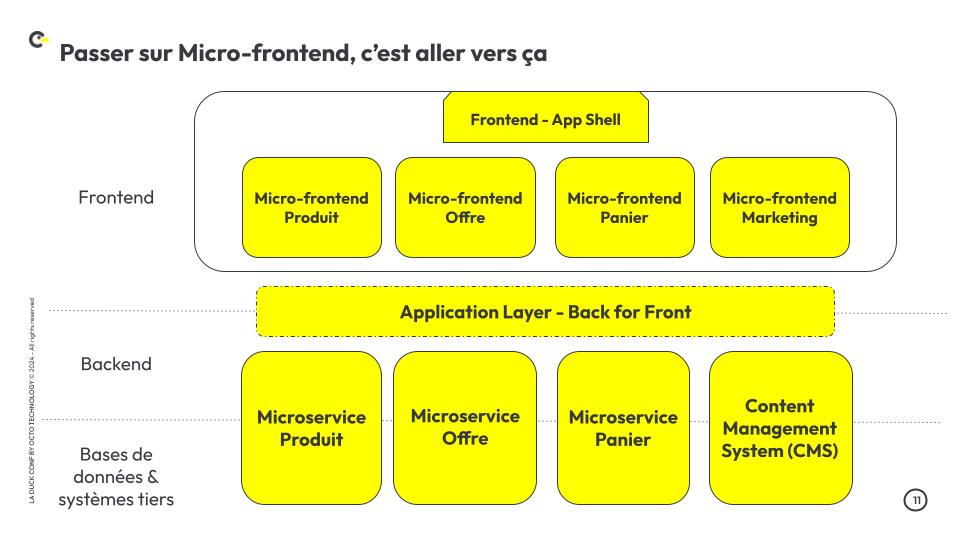 |  |
Figure 2 - À gauche, deux images de tasse de café qui, comparées pixel par pixel, ne se ressemblent pas. À droite, on a appliqué une règle de détection de motif : chaque pixel est colorié en bleu selon son niveau de contribution à la reconnaissance d'une tasse de café. Les zones bleues se concentrent aux mêmes endroits sur les deux images : le contour, et l'anse malgré leurs différences visuelles.
Définition automatique de motifs à partir d’exemples d’images
Des images de tasse de café, il en existe certainement des milliers, voire des millions. Ces images couvrent une grande variété de tasses (couleur, forme, …), et de conditions d’environnement (angles, arrière-plan, luminosité, …). Comment trouver les motifs que notre modèle de vision doit utiliser pour reconnaître une tasse dans toutes ces images ?
On pourrait, avec certaines hypothèses et analyses statistiques, trouver manuellement les motifs qui sont présents dans la majorité des images de tasses de café. Maintenant, que se passe-t-il si je veux que mon modèle de vision puisse différencier une tasse, un verre et un bol ?
Il faudrait alors identifier manuellement les motifs caractéristiques de chaque objet — ceux qui sont propres à un verre, ceux propres à un bol, ceux propres à une tasse. Et c'est là que ça se complique.
Certains motifs sont partagés : une tasse et un verre ont tous les deux un contour circulaire et une surface intérieure homogène. Comment distinguer les motifs qui font qu'une tasse est une tasse, et pas un verre ? Il faudrait affiner, chercher des motifs plus subtils, plus spécifiques — comme l'anse, ou la céramique. Et si demain on veut ajouter une bouteille, une carafe, une théière ? Le travail est à recommencer.
Cette approche manuelle atteint rapidement ses limites : elle est coûteuse, fragile, et ne passe pas à l'échelle. Et si on pouvait trouver, pour un ensemble d’objets, des motifs qui permettent de tous les différencier de manière automatique ?
De nombreux travaux ont été réalisés à ce sujet, et mis sous le feu des projecteurs en 2012 avec l’arrivée du modèle de deep learning AlexNet. Ce fût un tournant décisif dans le domaine de la vision par ordinateur. AlexNet a démontré qu'un réseau de neurones profond, entraîné sur suffisamment de données, était capable d'apprendre automatiquement ces motifs discriminants, sans qu'un humain n'ait besoin de les définir à la main.
C’était le début d’une nouvelle ère pour les modèles de vision : celle de l’apprentissage automatique.
Cette nouvelle catégorie de modèles de vision appartient au domaine de l’intelligence artificielle, et plus précisément au domaine du deep learning. Avec ce nouveau paradigme, on entraîne automatiquement notre modèle de vision à partir d’exemples d’images. L’entraînement, c’est la phase qui consiste à optimiser un ensemble de motifs, afin de regrouper les images du même type ensemble (ex : toutes les images de tasse), sans pour autant confondre différentes catégories (ex : tasse et voiture, tasse et bol, …).
En sortie, le modèle de vision produit un vecteur (Figure 3). Ce vecteur est appelé représentation latente, ou embedding en anglais. L'embedding, c'est un vecteur qui résume les motifs détectés par le modèle dans l'image. Les motifs utilisés par le modèle ne sont pas forcément interprétables : il s’agit d’une optimisation mathématique. C’est également le cas de l’embedding.
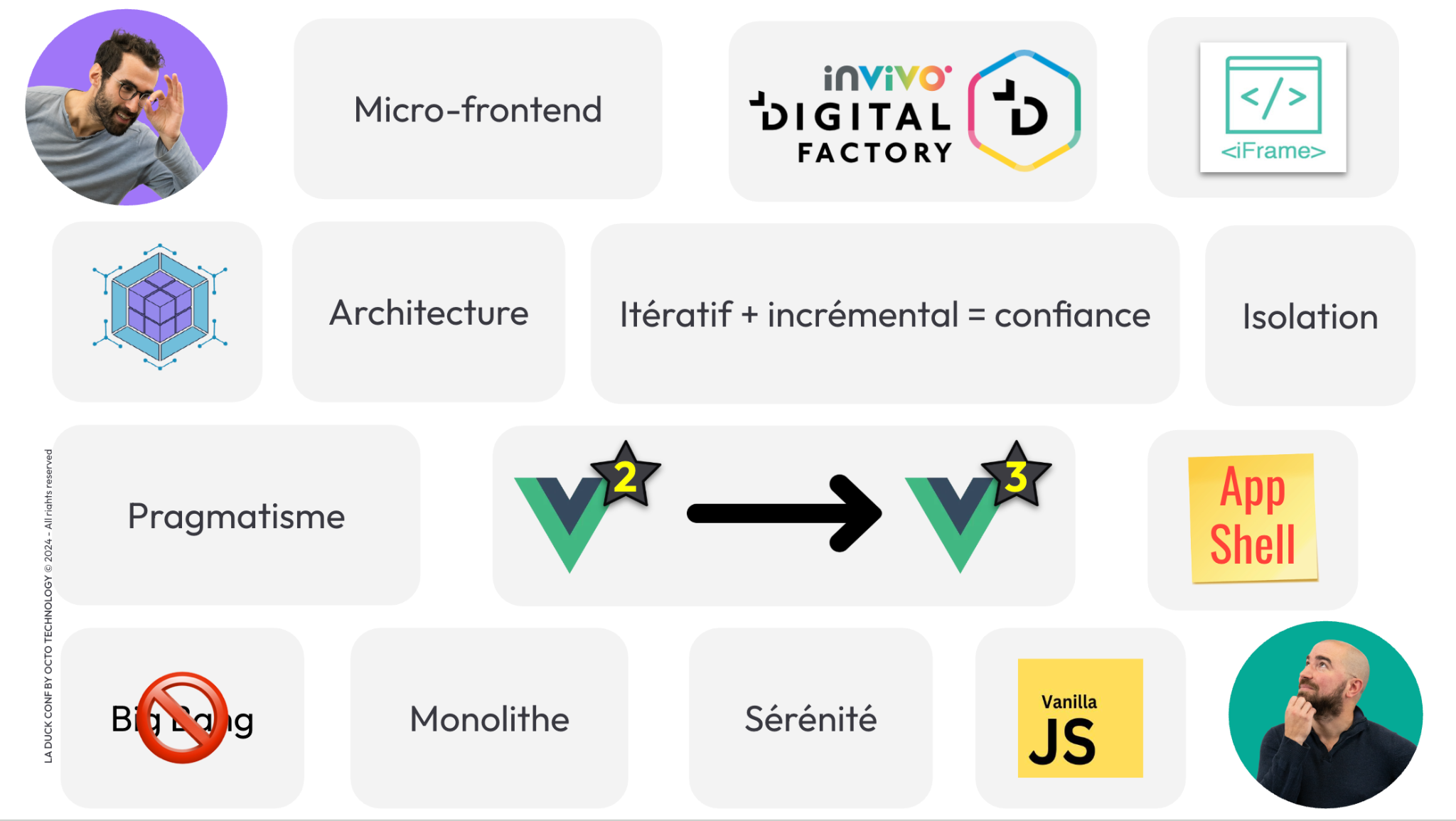
Figure 3 - En deep learning, un modèle de vision transforme une image en un vecteur d’embedding.
Malgré leur manque d’interprétabilité, les embeddings possèdent des propriétés intéressantes. Par exemple, deux images de bureaux contiennent certains motifs communs que le modèle de vision détecte. Leurs embeddings finaux seront alors similaires. Au contraire, une image de bureau et une image de forêt n'activent quasiment aucun motif commun. Leurs embeddings seront donc différents.
En tant que tel, les embeddings permettent de comparer des images entre elles. Mais, ces représentations vectorielles peuvent aussi être utilisées comme base pour d’autres tâches (Figure 4).
Comme une tête de classification dans un LLM, un petit modèle spécialisé reçoit en entrée un vecteur d’embedding d’un modèle de vision. Il est ensuite entraîné à les interpréter, pour réaliser une certaine tâche. Par exemple : classifier (ex : régression logistique), détecter des objets (ex : dernière couche de YOLO, décodeur DETR), segmenter une image (ex : UNET, Feature Pyramid networks), …
Figure 4 - On utilise des modèles spécifiques pour lire les embeddings, et les utiliser pour réaliser une tâche spécifique.
Architectures et modèles de fondation
Parmi les modèles de vision actuels, on distingue deux types d’architectures dominantes. D’un côté, les réseaux de neurones convolutionnels, ou convolutional neural network (CNN) en anglais (Figure 5).
Deux opérations constitue le socle pour bien comprendre le principe derrière cette architecture :
- Les convolutions, qui permettent de détecter des motifs au sein d’une image.
- Les couches de pooling, qui permettent couche après couche de construire une représentation globale de l’image.
Les CNNs capturent d’abord les motifs locaux d’une image (ex : lignes, contrastes, …) , et les mettent en lien petit à petit pour former une représentation globale (ex : l’image contient un chien). Pour mieux visualiser ce concept, je vous propose de faire un tour sur cette page web interactive : https://poloclub.github.io/cnn-explainer/.
Figure 5 - Exemple d’un CNN avec une tête de classification. L’architecture du modèle de vision est en rouge et noir, le modèle de classification en bleu et jaune.
De l’autre côté, on retrouve les Vision Transformers (ViT). Comme pour le traitement du langage, ces modèles sont constitués de blocs transformer (“transformer encoder”) successifs (Figure 6). Dans leur version initiale, ces blocs transformers sont constitués d’une couche d’attention, de deux couches de normalisation, et d’une couche réseau de neurones.
Pour adapter leur fonctionnement aux images, on utilise une couche de projection linéaire pour transformer l’image de départ en vecteur compatible avec les couches transformers, et on utilise une attention bi-directionnelle.
![Architecture d’un ViT. Le token [class] en jaune sert à construire un vecteur d’embedding pour l’image entière, contrairement aux autres qui construise un vecteur d’embedding pour des patchs d’images.](/octo-article-de-blog-10/image9.webp)
Figure 6 - Architecture d’un ViT. Le token [class] en jaune sert à construire un vecteur d’embedding pour l’image entière, contrairement aux autres qui construise un vecteur d’embedding pour des patchs d’images.
Grâce au mécanisme d’attention, les ViT peuvent faire des liens dès les premières couches entre des éléments spatialement éloignés dans l’image. Par exemple, en imagerie médicale, il est utile de relier des petites lésions dispersées dans un scanner pour diagnostiquer une pathologie. Avec un CNN, l’information des lésions est diluée au fur et à mesure des couches, ce qui empêche le modèle de faire des liens précis entre des éléments éloignés.
Ces architectures produisent des embeddings d’excellente qualité, à condition d’avoir suffisamment d’images et de ressources de calcul à disposition. Pour donner un ordre d’idée au lecteur, AlexNet dont nous avons parlé précédemment, a été entraîné sur plus d’1 million d’images. C’était en 2012.
Construire un modèle de vision de zéro avec du deep learning, ce n’est pas à la portée de tout le monde. C’est pour cela qu’on utilise des modèles de fondation. Les modèles de fondation, comme CLIP, DINO ou encore YOLO, sont des modèles de vision entraînés sur des volumes massifs de données avec des objectifs généraux. L'un des effets remarquables de cet entraînement à grande échelle est la qualité de l'espace latent qu'ils produisent.
L’architecture CNN a donné naissance à de nombreux modèles de fondations, qui se distinguent par leur architecture et leur cas d’usage. Par exemple, des architectures comme EfficientNet, ResNet ou ConvNeXt sont plutôt entraînés sur des tâches de classification, alors que des architectures plus hiérarchiques, comme DarkNet (encodeur de YOLO) ou UNET, sont plutôt utilisées pour des tâches de de détection ou segmentation d’objets.
De nombreux modèles de fondations existent sur la base de l’architecture ViT, et se distinguent par leur objectif d’entraînement. Par exemple, les modèles DINO sont des ViTs entraînés de manière auto-supervisée, les modèles CLIP sont des ViTs entraînés en associant du texte à des images, et les modèles SAM ViT sont entraînés sur des tâches de segmentation d’image. On retrouve également quelques variations de l’architecture ViT, comme Swin, pour réduire les coûts d’inférence et s’adapter à des résolutions hétérogènes.
Cela ne signifie pas que la frontière entre ces deux catégories est fixe. Certains modèles hybrides font leur apparition, en combinant astucieusement les couches de convolution et d’attention. C’est par exemple le cas pour la détection d’objets, avec les dernières versions des modèles YOLO et DETR.
Chaque modèle de fondation possède ses propres spécificités, comme son type d’architecture, son objectif d’entraînement, les images utilisées, son coût, … Chaque recette produira des embeddings aux propriétés différentes : adaptée à un domaine spécifique, à une tâche spécifique, …
En somme, les pixels constituent la matière brute de toute image, mais leur analyse isolée reste insuffisante pour en comprendre le contenu — c'est pourquoi les modèles de vision cherchent à détecter des motifs, ces structures caractéristiques qui émergent des relations entre pixels voisins.
Grâce au deep learning, deux grandes familles d'architectures permettent d'extraire ces motifs automatiquement : les CNN, qui construisent une représentation globale en agrégeant progressivement des motifs locaux, et les ViT, qui exploitent le mécanisme d'attention pour relier dès les premières couches des éléments spatialement éloignés. Le résultat de cette extraction est un embedding, un vecteur compact qui résume les motifs détectés et permet de comparer des images, de les classifier ou de les utiliser comme base pour d'autres tâches.
Aujourd'hui, les modèles de fondation — qu'ils soient basés sur CNN ou ViT — rendent ces capacités accessibles sans repartir de zéro, en offrant des espaces latents riches et généralisables, entraînés sur des volumes massifs de données.
Mais ces modèles ne font que décrire une image. Comment les utiliser pour distinguer le normal de l'anormal ?
Détecter des anomalies visuelles à l’aide de modèles de vision
Avant de rentrer dans les détails de la détection d’anomalie visuelle, rappelons qu’il faut pour tout algorithme de détection d’anomalies 3 éléments (Figure 7).
En premier, il faut construire une norme, c'est-à-dire apprendre à partir d'un échantillon d'exemples à quoi ressemble un comportement normal. La normalité n’est pas un concept aux frontières claires : nous verrons par la suite qu’elle englobe une variabilité naturelle complexe, des cas limites ambigus, et des exceptions légitimes qui la rende complexe à modéliser.
Une fois la norme définie, on peut l’utiliser pour détecter des anomalies sur de nouveaux individus. On calcule un score d'anomalie, qui mesure à quel point notre individu s'écarte de notre norme. Enfin, un seuil de décision détermine à partir de quel score on considère que l'écart est suffisamment grand pour déclencher une alerte.
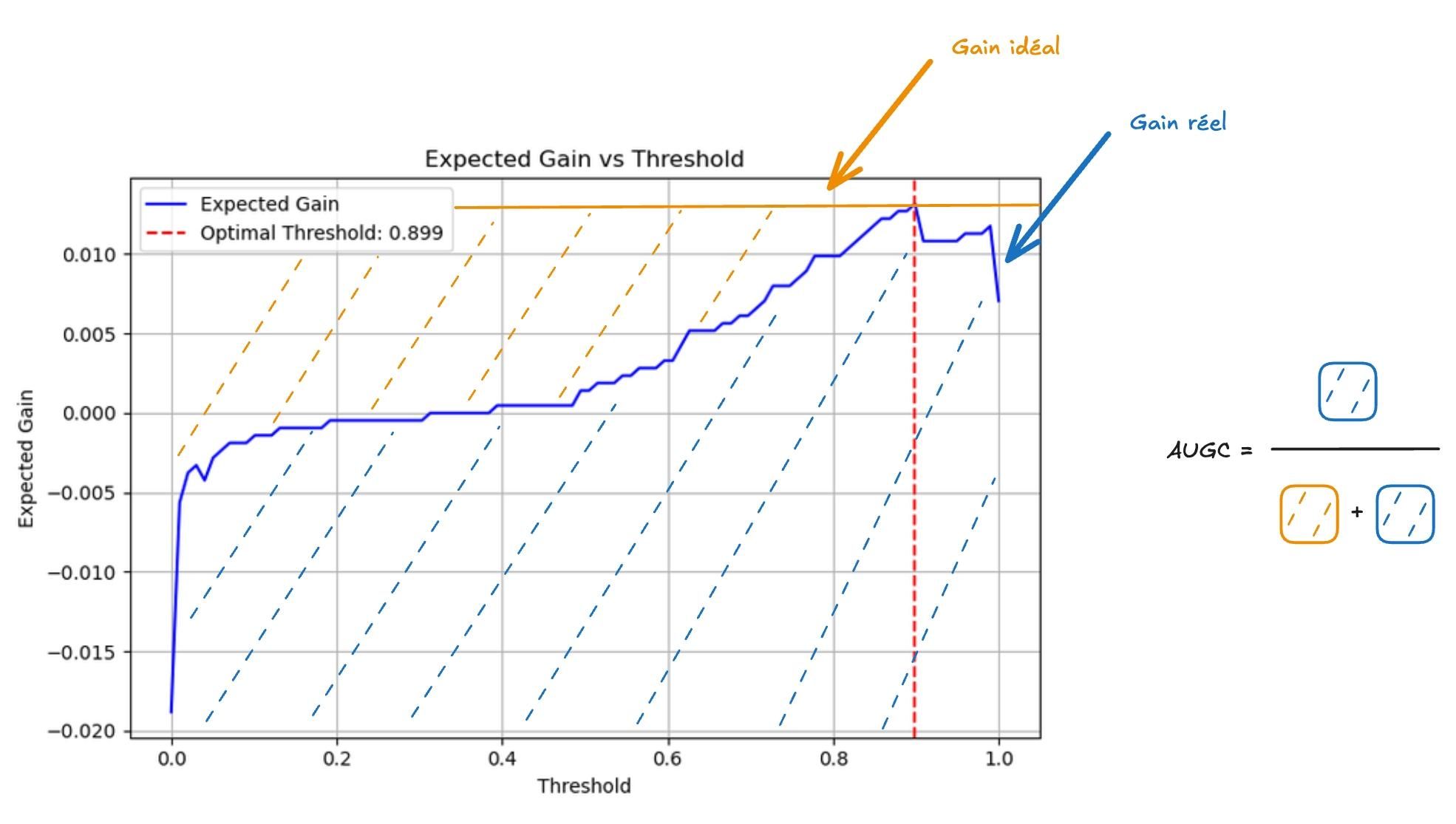
Figure 7 - Illustration du rôle de la norme, du score d’anomalie, et du seuil de décision à travers un exemple de détection de défaut sur une image de vis.
Le défi majeur concerne les deux premiers éléments : Comment établir une norme à partir d’images ? Et comment, ensuite, produire un score d’anomalie pertinent pour une nouvelle image ?
Pour mieux comprendre les concepts abordés tout au long de cette partie, on se place dans une production industrielle de vis. Sur une ligne de production, on place une caméra qui prend en photo toutes les vis produites. On aimerait construire un modèle capable de détecter automatiquement si la vis est défectueuse ou non.
Construire une norme de manière supervisée
Une première manière de construire un norme, est de manière supervisée. Je trouve ici très parlant de commencer par un exemple. Illustrons la construction d'une norme supervisée à travers notre exemple de vis.
Dans un premier temps, on récolte des images de vis normales, et des images de vis défectueuses. Puis, on essaye de trouver les motifs discriminants : ceux qui apparaissent systématiquement dans les vis défectueuses et jamais dans les vis normales, ou inversement.
Ces motifs constituent notre norme. Ils caractérisent le normal et l’anormal.
Pour classifier une nouvelle image, on calcule un score d'anomalie compris entre 0 et 1, à partir de la norme. Ce score reflète l'équilibre entre les motifs détectés : une image qui active majoritairement des motifs normaux — filetage régulier, surface lisse, tête intacte — obtient un score proche de 0. À l'inverse, une image qui active des motifs caractéristiques de défauts obtiendra un score proche de 1. Entre les deux, le score varie continûment : plus l'image est ambiguë, plus il se rapproche de 0.5.
Enfin, on fixe un seuil de classification : c'est lui qui traduit le score en décision concrète. En dessous du seuil, la vis est normale. Au-dessus, elle est anormale.
Il reste une question qui subsiste : comment identifier les motifs qui définissent notre norme ? Je pense que vous l’aurez deviné : les modèles de vision sont au cœur de la construction de la norme.
Alors, comment ça marche concrètement ?
Dans un premier temps, on a besoin d’un jeu d’images étiquetées — des vis normales et des vis anormales — pour entraîner le modèle.
Puis, on utilise un modèle de fondation pour entraîner un modèle de classification binaire. Voici l’idée derrière cette structure. On produit des embeddings pour chacune des images avec le modèle de fondations, déjà capable d’identifier de nombreux motifs. Puis, on entraîne un modèle de classification binaire à lire les embeddings de modèle de fondation, et à séparer les embeddings normaux des embeddings anormaux (Figure 8).
En d’autres termes, le modèle de classification va tenter d’identifier si les motifs utilisés par le modèle de fondation ne permettent pas déjà de séparer les images normales et anormales. Auquel cas le modèle de fondation constitue notre norme.
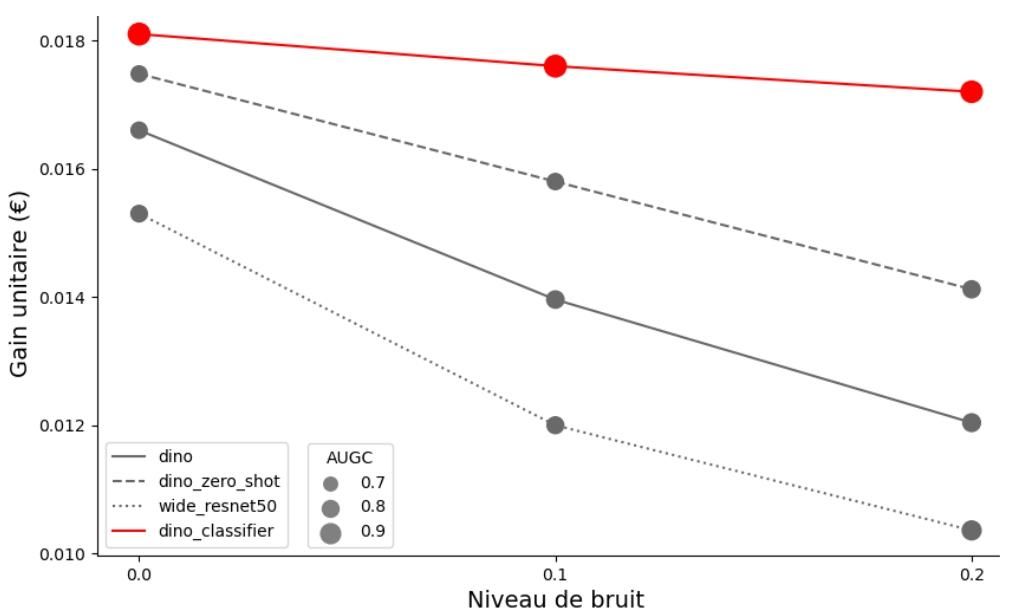
Figure 8 - Architecture d’un modèle de détection d’anomalie supervisé.
En pratique, les motifs des modèles de fondations sont assez généraux, ils décrivent bien qu’il s’agit d’une vis, mais ne sont pas nécessairement sensibles à une légère rayure sur un filetage ou à une microfissure sur une tête de vis.
Pour améliorer les résultats, on peut s’y prendre de deux manières. On peut complexifier notre algorithme de classification (Figure 9.1), en utilisant des modèles de classification avancés (ex : Support Vector Machine (SVM), Multi Layer Perceptron (MLP)).
Ce n’est pas une méthode que je recommande : elle conduit souvent vers un sur-apprentissage du modèle. On essaie de trouver des relations complexes entre des motifs généralistes, pour classifier notre image. Le risque est de construire une frontière de décision fragile, qui repose sur des corrélations artificielles plutôt que sur des motifs réellement discriminants. Le modèle pourrait par exemple apprendre que les vis défectueuses de votre jeu de données étaient légèrement plus sombres — non pas parce que l'obscurité est un signe de défaut, mais parce que les photos ont été prises dans des conditions différentes. Une telle frontière sera efficace sur les données d'entraînement, mais s'effondrera dès qu'elle rencontrera de nouvelles conditions de capture.
On peut également utiliser le fine-tuning, pour adapter les motifs appris par notre modèle de fondation à notre cas d’usage. Cela produit des représentations plus discriminantes (Figure 9.2), qui permettent de conserver un modèle de classification simple.
On cherche à adapter les motifs, et non à les reconstruire. Les premières couches du modèle, qui détectent des motifs universels comme des bords ou des textures, sont conservées telles quelles. Seules les couches finales, responsables de l'interprétation de haut niveau, sont adaptées pour devenir sensibles aux spécificités du domaine — ici, les défauts caractéristiques d'une vis.
 | 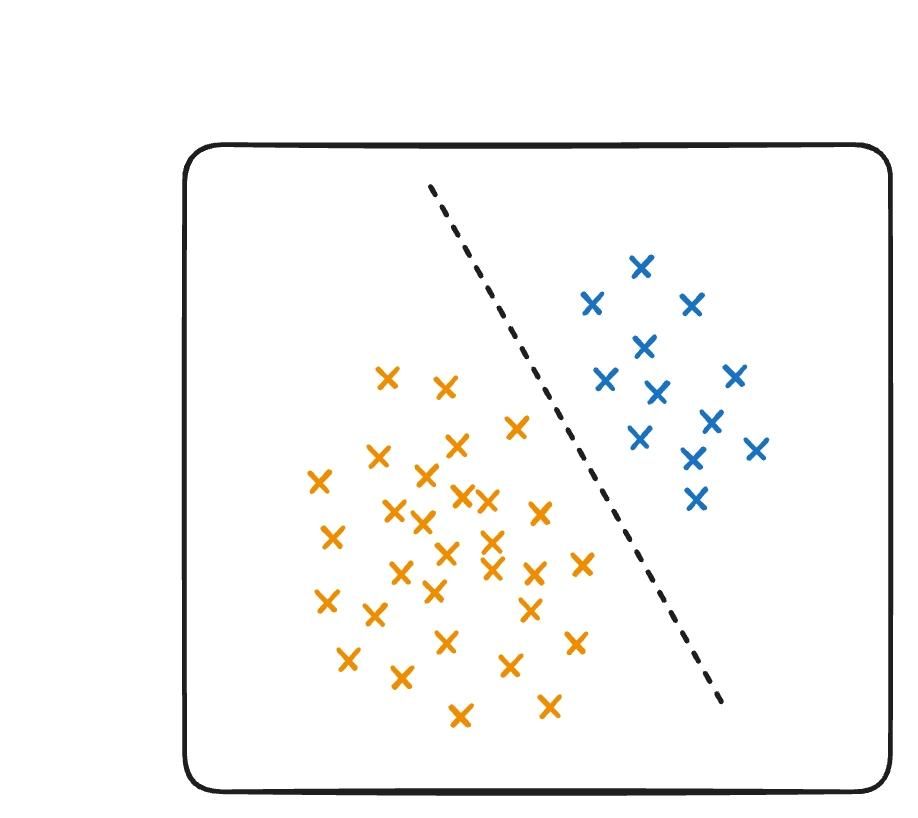 |
|---|---|
| 1/ Complexifier la frontière de décision. | 2/ Ajuster les motifs du modèles. |
Figure 9 - Ajuster les motifs (fine-tuning) est plus pertinent que de complexifier la frontière de décision.
Néanmoins, la qualité de l’entraînement ne dépend pas que de l’architecture, mais aussi des données d’entrée. En effet, pour que le modèle puisse fonctionner sur la ligne de production, les données sur lesquelles il est entraîné doivent représenter au mieux les conditions réelles. Sinon, les motifs qu’il aura appris ne seront plus utiles.
Dans de nombreux cas de détection d’anomalies, comme le nôtre, il est très difficile de construire un jeu d’entraînement représentatif de la réalité de la production :
- Par définition, une anomalie est rare. Il est très difficile d’en collecter suffisamment d'exemples pour que le modèle puisse trouver des motifs communs et généraux entre les défauts.
- Ce qui est rare est imprévisible. On peut attendre 6 mois, sans qu’un type précis de défaut ne soit jamais apparu. On ne peut pas collecter ce qu'on ne sait pas qu'il existe.
La robustesse des méthodes supervisées reste donc limitée par la nature même de notre cas d’usage. Si on les utilise, il faut régulièrement surveiller qu’il n’y a pas de dérives.
Pour contourner ce problème, on peut recourir à la simulation. L’objectif est de simuler des défauts jamais observés, pour enrichir le jeu d’entraînement et espérer améliorer la généralisation du modèle. C’est, par exemple, la solution utilisée par Waymo (voitures autonomes). L’entreprise entraîne les modèles qui contrôlent les voitures dans des simulations, pour les entraîner à réagir sur des cas qui ne se produisent presque jamais dans le monde réel.
Pour la détection d’anomalies, il existe des méthodes pour créer des défauts synthétiques plus ou moins réaliste :
- Peu réaliste, facile et rapide : Ajout de bruit (SimpleNet), perturbations géométriques basiques (CutPaste).
- Réaliste, complexe et plus coûteux : Génération réaliste via GANs ou modèles de diffusion (ex : voir l’article “Quand la génération synthétique permet de voir ce qui n’existe pas” de notre blog).
En résumé, l’approche supervisée définit une normalité qui caractérise le normal et l’anormal. Pour cela, on adapte légèrement les motifs appris par un modèle de fondation, pour qu’ils s’adaptent aux spécificités de nos images. Néanmoins, le principal frein des modèles supervisés, c’est qu’une norme n’est pas fixe, et qu’il est complexe d’en définir les cas rares ou extrêmes. On doit donc les entraîner en sachant qu’ils n'auront pas toutes les informations à disposition (notamment pour les défauts).
Pour faire face à ce manque de représentativité des défauts, la création de défauts synthétiques offre une perspective intéressante. On pourrait également se poser la question suivante : est-ce qu’on a vraiment besoin de connaître les défauts pour détecter des anomalies ?
Pour répondre à cette question, prenons le temps de s’intéresser aux méthodes non supervisées de détection d’anomalies.
Comparer à la normalité pour détecter une anomalie
Face à la difficulté de collecte de défauts, les méthodes non supervisées détectent des anomalies sans jamais en avoir vues. En pratique, les mécanismes sous-jacents sont variés — reconstruction d’images (auto-encodeur, GAN, diffusion) ou basé sur les embeddings (banque mémoire, teacher/student, normalizing flow, …) — mais partagent tous ce même objectif.
Le but de cet article n’est pas d’être exhaustif sur les méthodes. Nous allons tout de même illustrer, à travers notre exemple de vis, le fonctionnement d’un type d'architecture non supervisée : les modèles de banque mémoire.
Comme pour tous les modèles non supervisés, on récolte dans un premier temps un ensemble d’images de vis normales. En pratique, on peut même se permettre de ne pas trier rigoureusement les images : si les défauts sont rares, ils ne représentent qu'une infime fraction du jeu de données, et leur influence sur l'apprentissage de la norme sera négligeable. Le modèle apprendra essentiellement ce qu'est une vis normale, sans être perturbé par les quelques exemples défectueux glissés dans le lot.
Puis, on utilise un modèle de fondation pour créer un embedding pour chacune des images de notre jeu d’entraînement. En projetant suffisamment d'images normales en embeddings, on active certains motifs du modèle de fondation de manière répétée : les vecteurs se regroupent spontanément dans des régions denses et cohérentes de l'espace. Ces embeddings sont stockés, et constituent la mémoire du modèle.
Ces embeddings constituent notre norme. Ils caractérisent le normal.
Pour classifier une nouvelle image, son embedding est comparé aux embeddings calculées précédemment stockés dans la mémoire, en recherchant ses k voisins les plus proches. Si la distance entre l'embedding de l'image et ses voisins les plus proches dépasse un certain seuil, l'image est considérée comme anormale.
Dans cet exemple, on calcule un seul embedding par image. Mais cette approche a une limite que nous avons déjà rencontrée : les embeddings des modèles de fondation ne sont pas assez discriminants. Un défaut subtil, localisé sur une petite zone de la vis, peut être "noyé" dans l'embedding global et passer inaperçu. Il est donc très difficile de créer une norme qui est bien distincte des défauts.
Malheureusement, nous n’avons pas de défauts à portée de main pour affiner les représentations du modèle de fondation.
Pour y remédier, on découpe l'image en patchs — de petits carrés de taille N×N pixels — et on calcule un embedding pour chacun d'eux (Figure 10). Chaque embedding de patch capture des informations plus locales et plus précises : plutôt que de décrire la vis dans son ensemble, il décrit ce qui se passe dans une zone restreinte. Un défaut de filetage sur une portion de la vis aura alors beaucoup plus de chances d'être détecté.
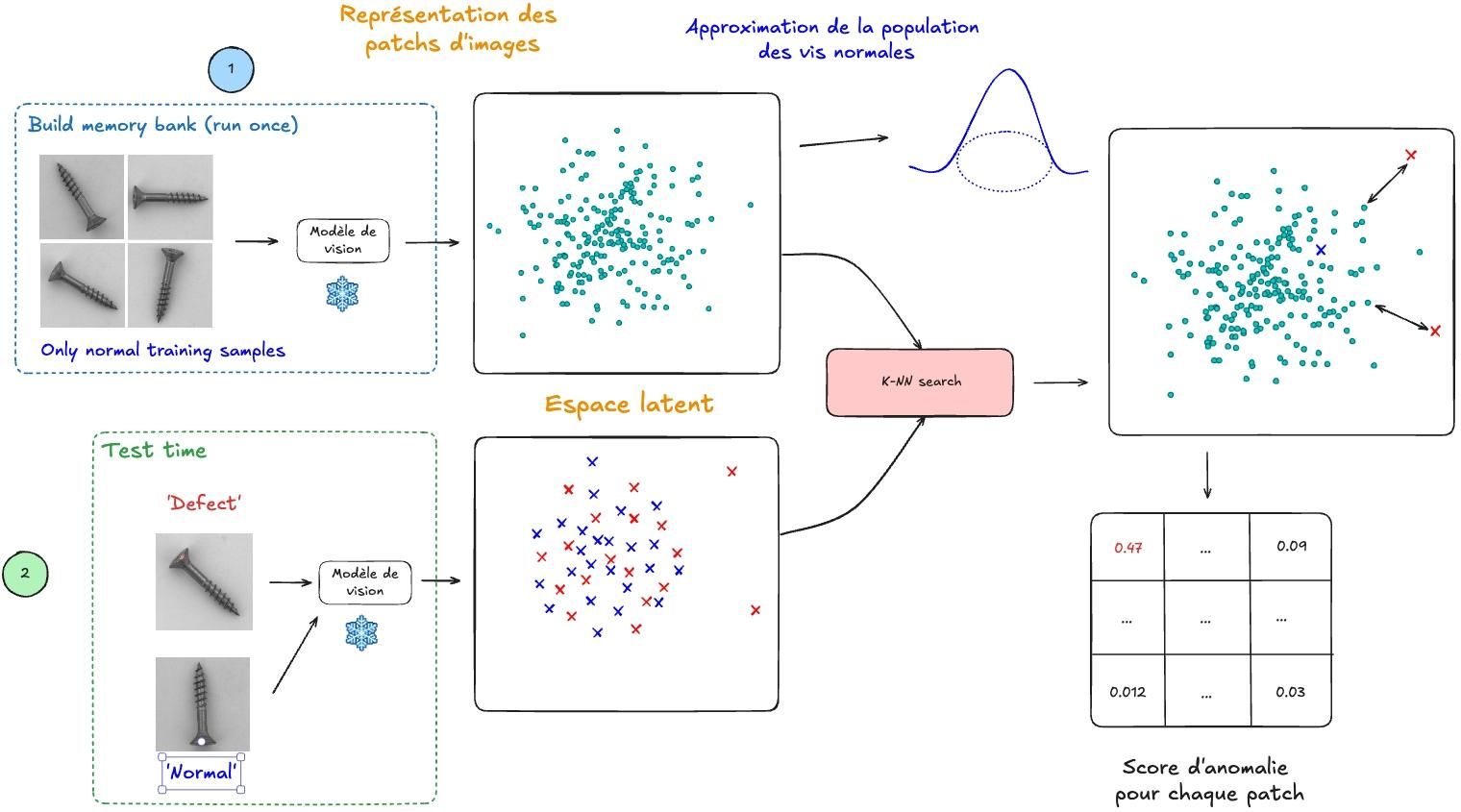
Figure 10 : Modèle de détection d’anomalie “banque mémoire”.
Mais cette précision a un coût. En travaillant à un niveau d'abstraction plus faible, les embeddings de patchs deviennent beaucoup plus sensibles aux petites perturbations d'environnement. Une légère ombre, un grain de poussière, une variation d'éclairage sur une zone restreinte suffit à faire dévier l'embedding de sa position normale dans l'espace latent — et à déclencher une fausse alerte. Ce qui était un détail négligeable à l'échelle de l'image entière devient un signal potentiellement trompeur à l'échelle d'un patch.
C'est donc un compromis entre sensibilité — détecter des défauts subtils et localisés — et robustesse — ne pas se laisser perturber par des variations d'environnement sans signification.
Les méthodes non supervisées construisent leur norme à partir d'images normales, puis détectent toute image qui s'en écarte, sans jamais avoir vu de défaut. Les modèles de banque mémoire illustrent bien ce principe : les embeddings des images normales constituent une mémoire, et toute nouvelle image trop éloignée de ses voisins dans cet espace est signalée comme anormale. Pour gagner en précision sur les défauts localisés, on peut travailler à l'échelle des patchs — au prix d'une plus grande sensibilité aux perturbations d'environnement.
Ces deux approches ont donc chacune leurs forces et leurs limites. Mais comment choisir concrètement entre l'une et l'autre ? Plutôt que de répondre dans l'abstrait, plaçons-nous dans un contexte industriel réel et comparons-les là où ça compte vraiment : leur impact économique.
Comparaison des approches sur un cas d’usage concret
Choix du modèle avec des métriques sans seuil
Dans la littérature scientifique, on retrouve deux métriques principales pour évaluer et comparer les modèles de détection d’anomalie : l'AUROC (Area Under the ROC Curve) et l'AU-PRC (Area Under the Precision-Recall Curve).
Ces deux métriques sont construites à partir de courbes — respectivement la ROC Curve (Figure 11) et la PR Curve — elles-mêmes calculées à partir des résultats de classification d'un modèle sur un jeu de test. Ces deux courbes partagent le même objectif : qualifier les performances du modèle.
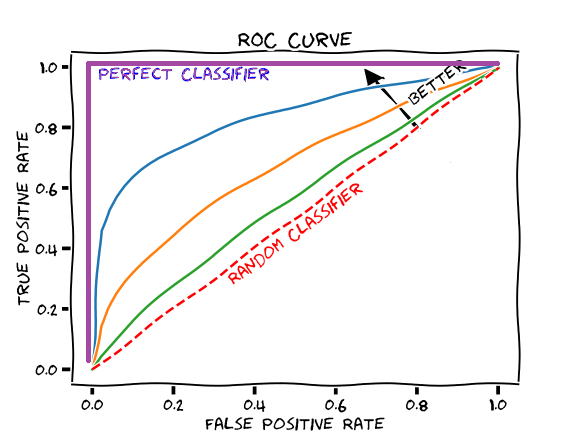
Figure 11 : Exemple de courbes ROC.
La ROC Curve permet de répondre à la question suivante : si je veux obtenir x% de faux positifs, quelle proportion y de défauts je vais détecter ?
La PR Curve permet de répondre à la question suivante : si je veux détecter x% des défauts, quelle proportion y de mes alertes seront de vraies anomalies ?
Néanmoins, comparer deux courbes entre elles n'est pas pratique. On préfère les résumer en un seul nombre : c'est le rôle de la métrique. Pour résumer chacune des deux fonctions, on calcule la moyenne de ses valeurs sur l'ensemble des seuils. Cela revient à calculer l’aire sous la courbe de la fonction, et c’'est précisément ce que signifie le préfixe AU : Area Under, soit "aire sous la courbe".
Concrètement, une AUROC de 0,7 signifie qu'en moyenne, le modèle détecte 70% des défauts réels. Une AUPRC de 0,8 signifie qu'en moyenne, 80% des alertes levées par le modèle correspondent à de vraies anomalies — soit seulement 20% de faux positifs parmi les détections.
L’AUROC est généralement la plus utilisée : elle n’est pas sensible à la proportion entre les deux classes, ni aux proportions des différents types de défauts.
Lier le terrain et les métriques
Les métriques sans seuil permettent de comparer les modèles, et de choisir le plus performant. Seulement, comment choisir le seuil que l’on va utiliser pour le modèle choisi ?
On pourrait se fixer un objectif : je veux que mon modèle détecte 90% des défauts. Dans ce cas, on regarde sur notre courbe AUROC le seuil associé au point recall=0,9. Cependant, c’est un peu arbitraire, et pas forcément la stratégie la plus optimisée.
Il est également possible d’optimiser le seuil pour qu’il maximise un score. Le F1-score optimal en est l'exemple le plus courant : on teste tous les seuils possibles et on retient celui qui maximise le F1-score sur le jeu de test. On cherche le meilleur compromis entre la détection des vrais défauts et la limitation des fausses alertes avec les résultats proposés par notre modèle.
De surcroît, derrière une anomalie se cache un coût, que le F1 score ne prend pas en compte. Dans un contexte opérationnel, il peut s’avérer plus pertinent d’optimiser le seuil de manière à maximiser les gains (ou minimiser les pertes / risques).
Pour notre cas d’étude de vis, on pose les heuristiques suivantes :
- Capacité de production : 10 millions de vis par mois.
- Cadence : 300 vis/minute, sur 22 jours ouvrés.
- Coût de fabrication : 100 000 vis = 2 000 €.
- Prix de vente : 100 000 vis = 4 000 €.
- Part de défaut observée : environ 3%.
Sous ces heuristiques, on peut construire une matrice qui énumère les gains/pertes provoqués par notre modèle (Figure 12). Autrement dit, chaque prédiction de notre modèle correspond à un des 4 cas de figure ci-dessous. Dans notre exemple, on fait le choix de pénaliser les faux négatifs (FN) 10× plus qu'un faux positif (FP) (client insatisfait, garantie, réputation).
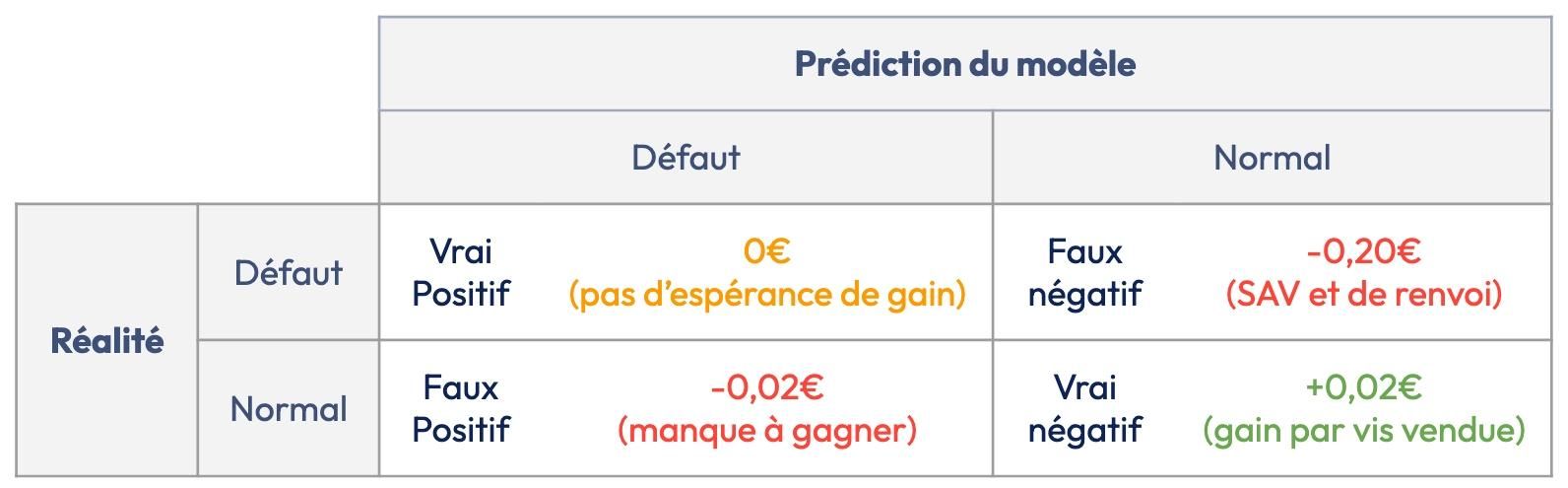
> Figure 12 - Matrice de confusion et coûts associés.
Avec cette matrice, on peut calculer l'espérance de gain. Cela permet de simuler le gain attendu en production, indépendamment de la distribution du jeu de test.
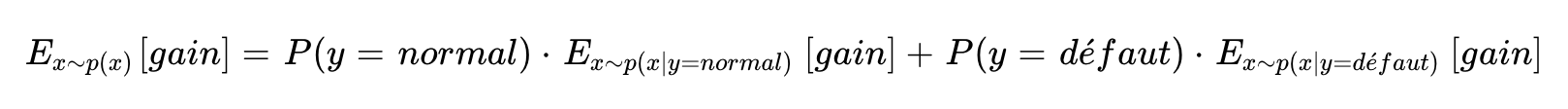
Lorsqu'on calcule l'espérance, on décompose le gain en deux termes : ce que le modèle gagne en moyenne sur les images normales, et ce qu'il gagne en moyenne sur les images défectueuses. Ces deux termes sont estimés séparément à partir du jeu de test — c'est le rôle des espérances conditionnelles.
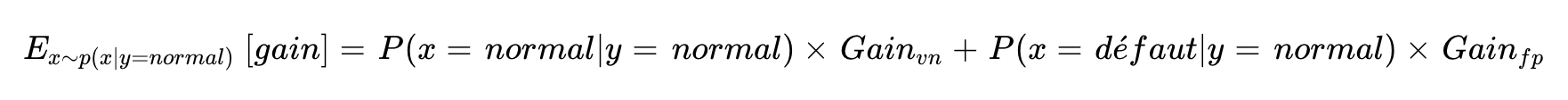
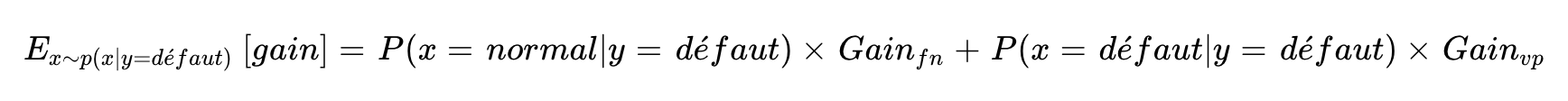
Ce qui change selon le contexte, c'est le poids qu'on leur accorde : P(y=0) et P(y=1). Si on calcule simplement la moyenne sur le jeu de test, ces poids sont fixés par la proportion de défauts dans l'échantillon — qui ne reflètent pas forcément la production réelle. En revanche, en formulant explicitement l'espérance, on peut fixer P(y=1) selon la réalité métier — par exemple 0.1% si un défaut apparaît une fois toutes les mille pièces — et obtenir une estimation du gain réellement attendu en production.
En résumé, la sélection du modèle et son déploiement suivent deux étapes distinctes. On commence par comparer les modèles à l'aide d'une métrique sans seuil. Une fois le meilleur modèle identifié, on optimise son seuil de classification pour maximiser l'espérance de gain en production, en tenant compte des coûts réels associés à chaque type d'erreur.
Recette d’évaluation
Pour évaluer notre modèle, on doit créer un jeu de test. Comme nous l'avons vu, récolter des exemples de défauts est long et coûteux — ce qui limite mécaniquement la taille du jeu de test.
Face à ce constat, la tentation est de rééquilibrer les classes en réduisant le nombre d'images normales. Mais réduire la taille de l'échantillon, c'est prendre le risque que l'espérance estimée s'éloigne de l'espérance réelle — on perd en représentativité ce qu'on gagne en équilibre.
La bonne approche est donc de conserver un jeu de test déséquilibré, aussi grand que possible, et de laisser le calcul de l'espérance faire le travail d'ajustement. En fixant explicitement P(y=1) selon la réalité de la production, on corrige le déséquilibre sans sacrifier la représentativité de l'échantillon.
Pour calculer des métriques représentatives, on les calcule avec une validation croisée stratifiée. Plutôt que de figer un seul jeu de test, on divise l'ensemble des données en k sous-ensembles en veillant à ce que chaque sous-ensemble conserve la même proportion de défauts (Figure 13). On entraîne et évalue le modèle k fois, en faisant tourner le rôle du jeu de test. L'espérance de gain est alors une moyenne sur les k évaluations.
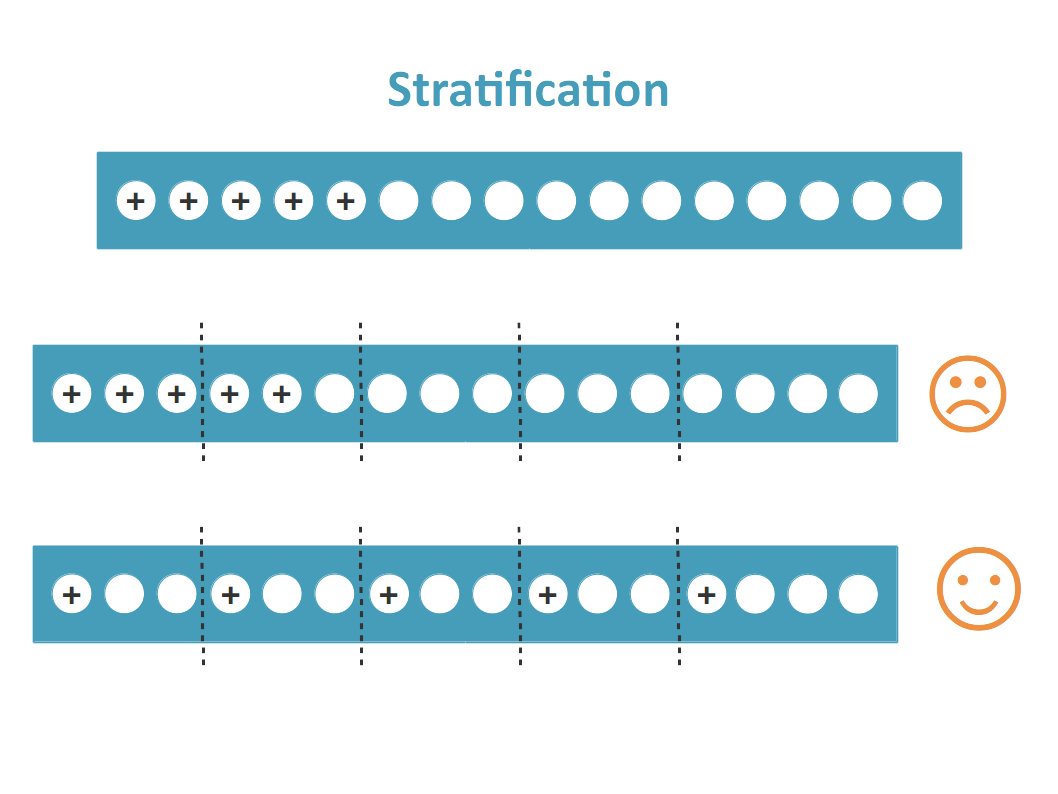
Figure 13 : Validation croisée stratifiée. Les défauts sont représentés par le signe +, et doivent être correctement répartis au sein de chaque sous ensemble.
Cette approche présente deux avantages. D'abord, elle utilise l'intégralité des données disponibles pour l'évaluation, ce qui est précieux quand les défauts sont rares. Ensuite, elle fournit une estimation plus stable et moins sensible aux particularités d'un seul échantillon de test. C'est particulièrement utile pour comparer des modèles dont les performances sont proches : là où un seul jeu de test peut avantager l'un ou l'autre par chance, la validation croisée stratifiée donne une image plus fiable.
Enfin, pour se placer dans un contexte moins parfait qu’un dataset très propre, on applique avec une certaine probabilité du bruit sur les images lors de la phase de test. On simule du bruit réaliste (flou, salt & pepper, …), pour simuler les conditions variables d’un environnement réel.
Quelle méthode utiliser ?
Avec les métriques et notre recette d’évaluation, on peut maintenant comparer différentes approches. On veut comparer l’approche supervisée et non supervisée, ainsi que la performance de ViTs et des CNNs (Tableau 1).
Pour les modèles supervisés, on fine-tune les dernières couches du modèle, et on entraîne un modèle de classification linéaire. Pour les modèles non supervisés, on utilise un modèle de type banque mémoire avec un modèle de fondation. Le code de ce benchmark est disponible sur github pour plus de détails sur l’entraînement et l’évaluation des modèles.
Gains opérationnels
Voici les deux axes que l’on peut tirer des résultat de l’évaluation des modèles sur nos images de vis :
- Le ViT se distingue particulièrement par sa meilleure résistance au bruit.
- Sur des défauts connus et documentés, les modèles supervisés sont plus performants que les modèles non supervisés. Notamment sous conditions bruitées.
| Conditions stables | 20% des images bruitées | ||||
|---|---|---|---|---|---|
| Modèle de vision | Méthode | AUROC | Gain pour 100k vis | AUROC | Gain pour 100k vis |
| ViT DINOV3-S (21M) | Supervisé | 0,95 ± 0,01 | 1 810 € | 0,94 ± 0,01 | 1 720 € |
| Non-supervisé | 0,77 ± 0,05 | 1 750 € | 0,81 ± 0,03 | 1 340 € | |
| CNN Wide-resnet50 (68M) | Supervisé | 0,93 ± 0,02 | 1 780 € | 0,90 ± 0,02 | 1 610 € |
| Non-supervisé | 0,80 ± 0,02 | 1 510 € | 0,79 ± 0,02 | 1 250 € |
> Tableau 1 - Gain opérationnel proposé par les modèles supervisés (backbone fine-tuné + modèle de classification linéaire).
Cependant, ces résultats soulèvent une question stratégique importante : l'approche supervisée nécessite un étiquetage exhaustif et coûteux des anomalies, souvent difficile à maintenir en production face à l'évolution des défauts ou l'arrivée de nouvelles références produit.
Face à cette réflexion, on peut se poser les questions suivantes :
- Quand privilégier le supervisé ?
- Quand opter pour le non supervisé ?
- Et si la solution idéale était un hybride des deux ?
Quel choix faire pour mon modèle de détection d’anomalies ?
Le choix de la méthode repose sur trois piliers : la nature de votre environnement de production, votre connaissance préalable des défauts, et l'équilibre entre risques et coûts.
| Type d’approche | Quand l’utiliser ? | Limites |
|---|---|---|
| Non-supervisé | - Démarrage d’une nouvelle production, ou - coût critique des FN. | Sensibles au bruit liés aux variations d’environnement. |
| Supervisé | - Défaut récurrents, et - labels abondants | Ne détecte pas les nouveaux types d’anomalies. |
| Hybride | - Défauts évolutifs, et - besoin de flexibilité | Plus complexe à mettre en œuvre et à maintenir. |
> Tableau 2 - Framework de décision pour choisir le bon type de modèle de détection d’anomalie.
L'approche hybride
L'approche hybride essaye de combiner les forces des deux approches précédentes, pour masquer leurs faiblesses respectives.
Comment ça fonctionne ?
Le système fait fonctionner deux modèles en parallèle :
- Le modèle supervisé détecte les défauts habituels avec une grande précision et certitude
- Le modèle non-supervisé analyse ensuite les échantillons classés "normaux" par le supervisé pour y débusquer d'éventuels nouveaux types de défauts
C'est comme un contrôle qualité en deux étapes : le premier inspecteur repère rapidement les problèmes connus, puis un second passe au crible fin ce qui semble sain pour détecter l'inhabituel. Cette architecture évite qu'un nouveau défaut passe totalement inaperçu simplement parce qu'il n'était pas dans le catalogue.
Conclusion
La détection d'anomalies visuelles est un problème riche, qui mobilise des briques techniques complémentaires — de la représentation des images jusqu'à l'évaluation économique des modèles.
Tout commence par la compréhension de ce qu'est une image : une grille de pixels dont l'analyse isolée ne dit rien, mais dont les relations locales font émerger des motifs. Les modèles de vision (CNN ou ViT) apprennent à détecter ces motifs automatiquement et à les comprimer en un embedding, qui capture le sens plutôt que la structure brute. Les modèles de fondation rendent aujourd'hui ces capacités accessibles sans repartir de zéro, en offrant des espaces latents riches et généralisables.
Sur ces fondations, on peut construire des modèles de détection d’anomalies visuelles. Pour comparer leur capacité à séparer les images normales et anormales, l'AUROC est une métrique de référence. Une fois que l’on a identifié le modèle le plus performant avec notre métrique sans seuil, le calcul de l'espérance de gain permet d’optimiser ses performances et de les traduire en impact économique réel.
On distingue deux grandes approches qui permettent de construire des modèles de détection d’anomalies visuelles.
Les approches supervisées tirent parti des exemples de défauts disponibles pour tracer une frontière précise entre le normal et l'anormal. Elles sont particulièrement adaptées aux défauts récurrents et bien documentés, mais restent fragiles face aux anomalies rares ou inédites.
Les approches non supervisées contournent ce problème en apprenant uniquement à partir d'images normales. Elles sont à privilégier au démarrage d'une nouvelle production, ou lorsque le coût d'un défaut non détecté est critique.
Entre les deux, les approches hybrides offrent un compromis pour les contextes où les défauts évoluent et où une certaine flexibilité est requise, au coût d'une complexité accrue. Dans tous les cas, le ViT se distingue par sa meilleure résistance au bruit environnemental.
Le dilemme technique n'est pas le cœur de la question. La problématique est avant tout opérationnelle : quel est le coût d'un défaut manqué versus une fausse alerte ? Combien coûte l'annotation ? Votre environnement dérive-t-il ? L'excellence opérationnelle commence par la rigueur dans la définition du problème métier.
Sources
- Xie, G., Wang, J., Liu, J., Lyu, J., Liu, Y., Wang, C., Zheng, F., & Jin, Y. (2024). IM-IAD : Industrial Image Anomaly Detection Benchmark in Manufacturing. IEEE Transactions On Cybernetics, 54(5), 2720‑2733. https://doi.org/10.1109/tcyb.2024.3357213
- Zhang, J., He, H., Gan, Z., He, Q., Cai, Y., Xue, Z., Wang, Y., Wang, C., Xie, L., & Liu, Y. (2024). A Comprehensive Library for Benchmarking Multi-class Visual Anomaly Detection. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2406.03262
- Roth, K., & al. (2022). Towards Total Recall in Industrial Anomaly Detection. 2022 IEEE/CVF Conference On Computer Vision And Pattern Recognition (CVPR), 14298‑14308. https://doi.org/10.1109/cvpr52688.2022.01392
- Damm, S., Laszkiewicz, M., Lederer, J., & Fischer, A. (2025). AnomalyDINO : Boosting Patch-based Few-Shot Anomaly Detection with DINOv2. CPVR, 1319‑1329. https://doi.org/10.1109/wacv61041.2025.00136
- Li, C., Sohn, K., Yoon, J., & Pfister, T. (2021). CutPaste : Self-Supervised Learning for Anomaly Detection and Localization. CPVR, 9659‑9669. https://doi.org/10.1109/cvpr46437.2021.00954
- Liu, Z., Zhou, Y., Xu, Y., & Wang, Z. (2023). SimpleNet : A Simple Network for Image Anomaly Detection and Localization. CPVR, 20402‑20411. https://doi.org/10.1109/cvpr52729.2023.01954
- Varatharasan, V., Calarn, S. (2022, 16 septembre). Quand la génération synthétique permet de voir ce qui n’existe pas - OCTO Talks ! https://blog.octo.com/quand-la-generation-synthetique-permet-de-voir-ce-qui-n'existe-pas
- Bergmann, & al. (2021). The MVTec Anomaly Detection Dataset : A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. International Journal Of Computer Vision, 129(4), 1038‑1059. https://doi.org/10.1007/s11263-020-01400-4