Observabilité - compte-rendu du talk de Fabien Arcellier à La Duck Conf 2019
Le constat est sans appel: nous assemblons de plus en plus de services lorsque nous construisons une application. Le déploiement d’une seule application signifie le déploiement d’une centaine de microservices qui communiquent entre eux. Les outils de monitoring classiques peinent à suivre tout le trafic et surtout détecter les défaillance à temps.
Donc comment assurer la maintenance de SI résilient et hautement disponible avec ces nouveaux éléments?
L’observabilité s'avère une approche approuvée pour gouverner ces nouvelles architectures de SI
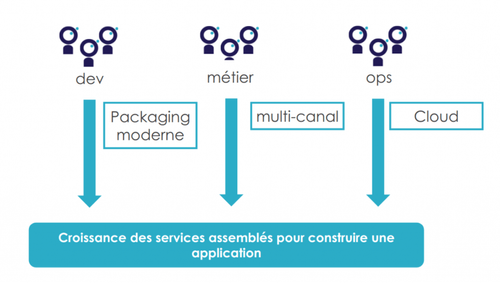
En premier lieu, examinons ce qui cause cette multiplication des services. Trois facteurs majeurs sont distingués :
Le premier est le packaging moderne; L’utilisation systématique d’un gestionnaire de dépendances comme maven ou gradle ou sbt ou npm pour structurer les projets. Ces outils permettent de structurer les projets de définir des modules et surtout d’industrialiser la production d'artefacts (tar.gz, war…) et raccourcir le cycle de d’integration.
En plus des outils de gestion de dépendances, la containerisation. Le container, packagé par Docker, devient l’unité de déploiement et fournit plus rapidement un environnement d’exécution isolé de l’artefact.
Cette facilité de packaging rend la tâche de produire un nouveau service plus simple et plus rapide pour les développeurs.
Le deuxième facteur est le cloud. En effet, avoir des infrastructures dans le cloud signifie des ressources illimitées et surtout présentes et on-run à la demande. En outre, le cloud offre plusieurs outils pour la gouvernance de tenant partagé dans l’organisation et la mise en place des mécanismes d’auto scalabilité, la garantie de la haute disponibilité et la gestion de la résilience des systèmes.
Pour les opérations ça devient beaucoup plus simple de déployer et maintenir des milliers de services en production.

En dernier, le multicanal. Ce concept se traduit via deux aspects. En premier, un parcours consistant : on veut que le produit est dressable quelque soit le canal qu’on consomme et inversement quelque soit le canal utilisé, on peut avoir le bon produit, que je commande mon assurance vie sur mon téléphone ou sur le site web de l’assureur ou dans un guichet j’ai le même résultat.
Ceci oblige le métier à réfléchir que le même service on va utiliser différemment et surtout un service devient une unité, un produit autonome indépendant du canal, de l’usage ou des particularité du processus de traitement qui le consomme.
En second, un parcours fluide : la capacité à interrompre son action et la reprendre sur un canal différent.
Le métier devient demandeur de ce genre de service car cela va leur permettre de mutualiser les comportements et d’avoir une sorte de consistance au niveau des flux et des processus métiers définis. Le service devient un produit à part entière autour duquel le métier peut non seulement, bâtir une stratégie de marketing par exemple ou proposer de nouvelle fonctionnalités à ses clients mais aussi définir une organisation et des équipes comme des features team, chaque équipe multidisciplinaire est responsable de faire évoluer le périmètre fonctionnel lié au service
La multiplication des services n’est pas seulement dû à des raisons techniques comme le cloud mais aussi pilotée par le métier et des aspects de marketing et gestion de relation client.
Cette explosion du nombre de services complique la perception du système d’information. Communiquer autour du système, modifier le système ou le corriger demande plus d’effort et de concertations. En outre, la communication entre les acteurs du SI devient de plus en plus compliquée car ils disposent d’informations différentes. La stratégie et les outils de gouvernance du SI doivent d’adapter et être plus dynamique .
L'observabilité est le moyen qui va vous permettre de monitorer vos services, définir plus efficacement vos budgets et vos planning, suivre l’état de vos machines et ainsi maîtriser mieux votre SI.
Dans cette septième session de la Duck Conf 2019 et afin de bien nous réveiller après la pause déjeuner, Fabien Arcellier, architecte technique chez Octo technology fait une synthèse des besoins auxquels l’observabilité répond et nous fournit les approches adéquates et les outils nécessaires pour rendre nos SI observables et ainsi plus robustes et plus évolutifs.
Mais avant d’aller plus loin, Fabien définit ce que c’est un service
un service se définit par :
- un contrat de service : un service regroupe plusieurs unités d’exécution qui expose des capacités par l’intermédiaire d’un contrat de service. Ce contrat peut défini via un accord entre le fournisseur et les consommateurs
- Des modalités d’exposition : Le contrat de service définit au mieux les modalités d’exposition tel que les protocoles d’échanges, les ressources et opérations exposés, ainsi que leurs attributs non fonctionnels comme SLA (Service Level Agreement), SLO (Service Level Objective), SLI (Service Level Indicator) … que respecte le service
- Des prérequis client : Le contrat de service définit un ensemble de prérequis que le client doit fournir pour respecter la qualité défini dans le contrat de service
Donc comment l'observabilité va permettre de maîtriser et gouverner ces services ?
Commençons par une définition

L’observabilité devient donc un attribut du SI. Ceci dit, comment déterminer si mon SI est observable ?
Pour répondre à cette question, Fabien précise 4 critères pour qualifier l’observabilité d’un système d’information,définir ces critères est nécessaire car C'est comme dire mon travail est de bonne qualité ou mon système est performance, sans critères ça ne veut rien dire. Le diable est dans les critères :
- Auditabilité : capacité à lire l’histoire d’un service et tracer tout ce qui s’est passé, exemple les logs d’accès permettent d’auditer l’usage d’un endpoint web
- Télémétrie : capacité à mesurer l’usage d’un service, exemple les IO Read permettent de mesurer le volume chargé du disque vers la mémoire
- Notification : capacité à notifier en cas de comportement anormal
- Accessibilité : Capacité à partager ces informations aux acteurs concernés, donner accès aux logs aux ops et aux dev dans tous les environnements même la prod.
La théorie est belle, comment je peux m’outiller pour m’assurer que mon système répond aux critères d’observabilité que j’aurai défini avec mes équipes et ainsi avoir un système qui est auditable, mesurable, envoyant des notification en cas d’anormalité et donnant accès aux même niveau d’information à plusiuers acteurs du SI (dev, ops, métier) ?
Fabien a présenté 4 approches techniques pour atteindre ces objectifs.
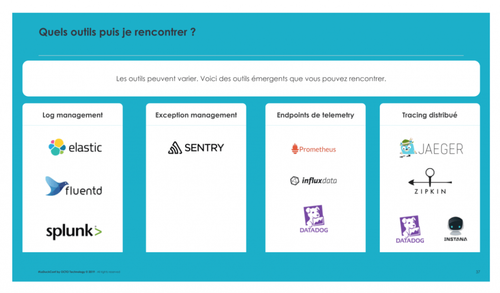
La première est le Log Management. C’est une démarche pour capturer des événements du SI, souvent en provenance des logs pour pouvoir visualiser une activité, analyser des tendances, voir prédire des comportements anormaux. Cette démarche consiste à centraliser en un seul endroit l’ensemble des événements arrivés dans les différents services. Les logs collectés ne sont pas seulement techniques mais aussi applicatifs/fonctionnels. Cette collecte a pour but de filtrer les logs voir les agréger afin de créer des images de logs plus parlantes et plus personnalisées suivant les problématiques du SI.
Ces logs filtrés et structurés vont vous permettre d’investiguer en temps réel en cas de problèmes, de lancer des alertes quand c’est nécessaire et de construire des indicateurs intelligents pour opérer vos systèmes.
Ceci dit, la collecte des logs ne doit pas être faite dans un but d’archivage de log (pour des raisons légales ou autre). En effet, il ne faut pas garder les logs dans le moteur de recherche, comme ELK ou Splunk, pour une longue durée, car les coûts explosent et ces plateformes ne sont pas adaptés au traitement batch (spark, ...) . Pour des logs de plus de trois semaines, pensez à les transférer vers stockage froid , dans S3 par exemple. Ensuite, utiliser une plateforme de log management comme datalake est une pratique non recommandée.
Cela va générer beaucoup de bruit, tous les logs ne seront pas utiliser pour déduire les indicateurs nécessaire au bon fonctionnement du SI. Les plateformes de log management sont efficientes pour l'analyse court ou moyen terme (quelques mois). Un dernier point à ne pas négliger, encoder les logs d’application dont vous avez le contrôle dans un format semi structuré comme json, et ne pas se contenter d’un simple format parsable, une chaine de caractére respectant un pattern. Ce dernier est format est facilement cassable, un espace de trop et le log n’est plus reconnu et analysable.
La deuxième approche est l’Exception Management ou l’Error Tracking. A la différence du log management, cette approche centralise les exceptions sous un format spécifique et les corrèle avec les événements qui ont précédé. Ainsi la plateforme va pouvoir envoyer des alertes intelligentes corrélées avec le déploiement qui l’a causée si vous avez pris le soin de le remonter. Abusez de l'utilisation de cette approche dans tous vos environnement du dev à la pré-prod. En effet, la mise en place de l’Error Tracking va fluidifier la communication entre les développeurs et les Ops. Il devient plus simple de connaître la source d’un problème vu que le déploiement qui a introduit l’anomalie est identifié. En effet, ayant une idée sur la source du problème, les développeurs, recevant l’alerte en temps réelle, peuvent corriger rapidement (changer une url dans un fichier de conf, ou redéployer une nouvelle version des pages statique, ou builder rapidement un nouveau package prêt pour déploiement en prod et contenant la correction)ou demander d’effectuer les rollbacks nécessaires le temps que le problèmes soient corrigés.
La troisième approche est la Télémétrie. Les endpoints de télémétrie offre une instantanée de l’état d’un système sous la forme de compteurs ou de gauges. Ces compteurs peuvent construit pour monitorer des ressources, les flux au niveau des middleware ou suivre le fonctionnement des applications via des métriques d’activité. Ce modèle d’exposition offre aussi l’avantage de découpler la production de métriques et leurs historisations. Un instantannée se présente sous la forme d’une page avec une liste de métriques. Cette page sert de support de discussion entre le métier, les développeurs et les Ops.
La dernière approche est le Tracing distribué. Cette approche génère une instantannée du cycle de vie de la requête en construisant une chaîne d'événements et d’états. Cette approche va vous permettre d’investiguer des défaillance cross service et de diagnostiquer plus efficacement les problèmes de performances au niveau des requêtes. Cette approche s’est démocratisée via les APMs (Dynatrace, AppDynamix, New Relic...). Récemment, un standard d’API a été défini, porté par les géants du web au travers du CNCF, OpenTracing; Si vous voulez mettre en place une stratégie de Tracing distribué, il est recommandé de suivre les spécification de ce standard; D’ailleurs une implémentation de la spécification est devenue accessible en open source cross-runtime via des systèmes tel que Jaeger. Pour le moment, on n’a pas vu des implémentations de cette spécification et les outils correspondants tournant en production encore donc ne ne peut pas pour le moment vous apporter des REX concrets.
Différents outils existent sur le marché pour implémenter et intégrer chaque approche
En fin de compte, avec la mise en place d’architecture micro-service, avoir un système observable (auditable, traçable, envoyant des notifications en cas d’anomalie et ayant des logs accessible à tous les acteurs d’un SI ( développeurs, Ops, métier) ) est une condition de survie.
La mise en place des mécanismes d’observabilité s’inscrit dans une démarche d’amélioration continue. Vous pouvez démarrer les chantier d’une façon opportuniste, ceci dit, c’est une tâche continue, la mise à jour des métriques se fait à fur et à mesure des évolutions des SI.
En conclusion, il existe une multitude d’outils pour rendre un système observable, certains promettent de couvrir plusieurs besoins via un seul agent de surveillance ceci dit sur le terrain en vrai chercher le meilleur outil pour de l'observabilité c'est comme chercher la meilleure voiture pour labourer un champs et faire du circuit. Donc prenez le temps pour définir votre stratégie d’observabilité, identifier les métriques liées au contexte et choisir les bons outils.