Nous étions à la KubeCon Europe (2/2)
Kubernetes et son écosystème pour la production
La KubeCon n’était pas que l’occasion de présenter la roadmap et les nouvelles fonctionalités de Kubernetes. C’était aussi l’occasion de faire le point sur son écosystème grandissant et sur son utilisation en production.
Pour être serein en production, nous nous attendons à ce qu’un framework comme Kubernetes propose :
- Une installation automatisée et idempotente
- Du cloisonnement d’environnement (Multitenant)
- De la persistence sur les données
- Du monitoring
- De la haute disponibilité
- Du Continuous Intégration et du Continuous Delivery
- Des stratégies de tests d’intégration
C'est l'ensemble de ces aspects traités pendant les conférences que nous allons développer dans la suite de cet article.
Kubernetes c'est bien beau mais comment je l'installe chez moi ?
De l’aveux même de Kelsey Hightower, le plus difficile est d’installer Kubernetes. Son utilisation est faite pour être simple et “automagique”. Les playbooks/recettes/scripts d’installation sont de plus en plus nombreux, nous retiendrons notamment Kubespray. Ce playbook Ansible permet d’installer un cluster Kubernetes déjà packagé avec ses dépendances, il fonctionne sur plusieurs distributions, et permet d’embarquer simplement les plugins third party de votre choix.
Tout le monde sur un seul cluster ? Mes projets risquent ils de se marcher dessus ?
Kubernetes seul ne propose pas de solutions permettant de cloisonner différents namespaces. Tous les conteneurs peuvent communiquer ensemble. Pour répondre au besoin du cloisonnement, des solutions de SDN (Software Defined Networking) dédiées à Kubernetes (ou pas) se sont multipliées ces derniers mois.
Deux types de solutions rentrent en concurrence :
Les solutions overlay
Nuage Network s’appuie sur ce modèle qui permet le cloisonnement inter et intra namespaces. La solution se veut simple : la configuration se fait en définissant la politique de sécurité dans une interface dédiée. Le point fort de cette solution : elle ne se cantonne pas à Kubernetes, puisqu’elle fonctionne également avec Openshift v3, mais aussi avec OpenStack, VMware, et rend possible la fédération de tous ces environnements.
OpenContrail suit la lignée de Nuage Network mais remplace Open vSwitch par un vRouter fait maison. Le fonctionnement et les points forts sont quasiment similaires : une configuration par GUI qui se veut simple, et qui fonctionne avec Kubernetes, Openshift v3, OpenStack et VMware. Cette solution à l’avantage d’être open source et utilisable sans licence.
Openshift-SDN est une solution de même type, dédiée cette fois-ci à Openshift v3. Le projet est jeune, permet le cloisonnement entre les différents namespaces Openshift par le biais d’une ligne de commande. La solution est nativement intégrée à Openshift mais pose certaines contraintes comme l’incapacité de fermer un flux ouvert entre deux projets.

Les solutions de pur niveau 3 qui remplacent Open vSwitch par un Virtual Router ou directement par iptables :
Romana est un acteur récent, qui pousse le principe de Cloud Native SDN. Leur objectif est de supprimer la complexité des configurations Overlay, en s’appuyant sur des règles de routages statiques. L’apport de leur solution (qui fonctionne sur Kubernetes et OpenStack) est la simplicité d’architecture (plus simple à troubleshooter), la performance et la segmentation. La configuration se fait via le CLI de Kubernetes. Slides de leur présentation.
Le Projet Calico poursuit sa montée en puissance. L’objectif de cette solution est d’offrir simplicité d’exploitation, forte scalabilité et sécurité, en utilisant les mécanismes de routages directement intégrés dans le noyau Linux. L’utilisation est similaire à Romana puisqu’elle se fait directement via le CLI, ou par la configuration d’objets Kubernetes.

Si les promesses de Calico et Romana sont à prendre au sérieux et doivent être explorées, c’est plutôt du côté d’OpenContrail et de Nuage Network, les plus expérimentés, que nous nous tournerons pour notre production à court termes.
Vous m'avez dit qu'un conteneur est volatile et éphémère, quid de mes bases de données ?
Une des problématiques majeure liée à l’utilisation de conteneurs en production est la persistance des données. En effet par définition un conteneur est éphémère et non persistant.
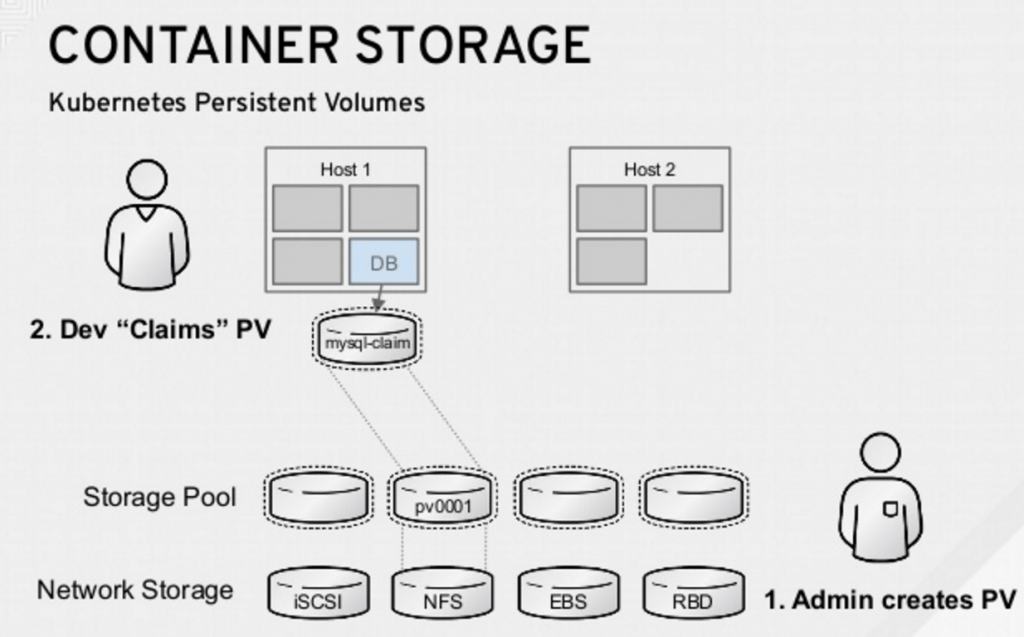
La solution poussée par Kubernetes est l’utilisation des Persistent Volume.
Le cycle de vie est le suivant :
- L'administrateur du cluster Kubernetes définit un certain nombre de PV (Persistent Volume), ces PV sont caractérisés par :
- La taille de l’espace disque mis à disposition
- Le mode d'accès (ReadWriteOnce/ReadWriteMany)
- Le système de stockage (Ceph, GlusterFS, NFS, local, etc … )
- Les applications font des requêtes de stockage via un PVC (Persistent Volume Claim), caractérisé par :
- L’espace disque souhaité
- Le mode d’accès
Les mécanismes internes de Kubernetes font ensuite le mapping entre les PV et les PVC permettant ainsi d’abstraire complètement pour les pods le système de stockage sous-jacent.
Comment respire ma plateforme ?
Bien connu dans la gestion des réseaux des conteneurs, Weave a présenté sa solution de monitoring ou plutôt, de visualisation d’architecture de type microservice : Weave Scope. Intuitif, cette solution propose une cartographie des conteneurs (Docker), des process et du host. Une solution sous licence Apache 2.0 à suivre pour Kubernetes.
Autre solution, présente sur les stands de la KubeCon, Datadog présente un modèle en SaaS. Des agents sont installés sur les différents hosts qui remontent leurs métriques. Les dashboards sont à configurer, allant du plus simple au plus complexe, en allant piocher dans un catalogue de “briques monitorables”. Si la solution est complète, il faudra débourser une quinzaine d’euros par agent, relativement abordable compte tenu du service rendu.
Enfin, une solution qui s’adresse aux utilisateurs de shell et de la CLI Kubernetes : Sysdig. Cette solution est l’equivalent de la commande “top” dans un shell. Elle permet de visualiser directement en ligne de commande : la consommation CPU, RAM des conteneurs sur le cluster, l’état des conteneurs et bien d’autres métriques.
J’ai besoin de haute disponibilité, quelles solutions s'offrent à moi ?
La haute disponibilité se décline sous plusieurs aspects et peut être gérée sur différentes applications de la stack. Principalement deux niveaux de HA ont été abordés lors des conférences : la haute disponibilité des bases de données, et celle dans Kubernetes
Deux solutions ont été présentées pour assurer le HA des bases de données :
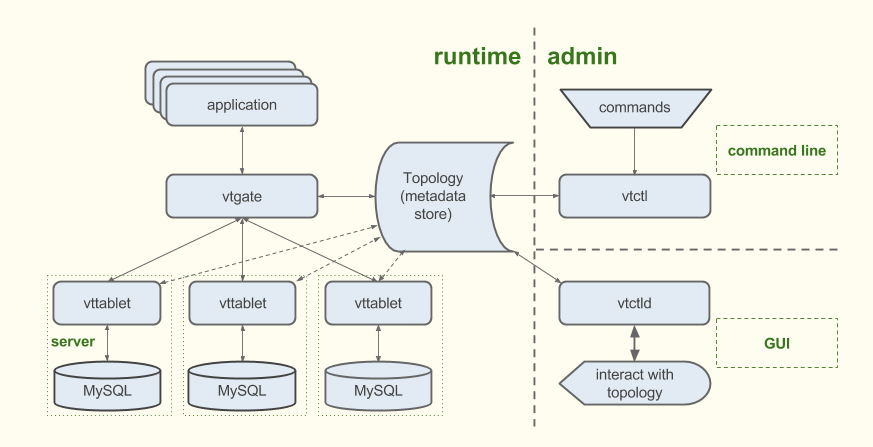
- vitess.io permettant de monter un cluster de MySQL
- Patroni : Une solution opensource développée par Zalando permettant de créer un cluster PostgreSQL en utilisant Zookeeper ou ETCD.
Le mécanisme de HA natif à Kubernetes est le ReplicationController. Il permet de s’assurer qu’à tout instant un pod est opérationnel. Si par exemple le niveau de réplication est défini à 2 dans le Replication Controller, Kubernetes va s’assurer que le contrat est bien rempli et va relancer un pod si l’un venait à tomber pour s’assurer que 2 pods sont bien opérationnels.
Une autre fonctionnalité qui a été présentée est le déploiement en mode RollingUpdate. Ce mode de déploiement est similaire à un blue/green deployment au niveau des pods
Et mes pipelines d’intégration et de déploiement continue ?
Le sujet du Continuous Integration / Continuous Delivery a été abordé avec le retour d’expérience de Michael Ward de Pearson. Avec plus de 400 équipes de développement partout dans le monde, Pearson doit délivrer très fréquemment des pipelines de CI/CD, tout en conservant les tests de sécurité, de performance et d’assurance qualité. La clé de leur succès est de considérer les pipelines comme du bétail (cattle vs pets pattern). Ces méthodes ont permis de faire économiser aux développeurs 10% de leurs temps.
Pour allier leurs contraintes avec une grande vélocité, plusieurs solutions ont été mises en place :
- Les conteneurs de base ont été standardisés
- Les exigences de sécurité ont été intégrés aux images
- Le pipeline de build intègre tous les tests de QA, sécurité et performance
- Les boucles de feedback ont été réduites entre les dev et les OPS
Chaque développeur doit pouvoir déployer son pipeline, il n’est plus question de n’avoir qu’une personne dans l’équipe responsable de sa construction. Pour faciliter le processus de construction, Pearson s’appuie sur du ChatOps : Une communication avec un hubot permet de créer un repository bitbucket automatiquement, déploie un pipeline Jenkins… Tout l’écosystème est créé à partir d’une ligne de chat.
https://twitter.com/chriswiggy/status/708242403258462208
Enfin, pour décrire un environnement, les développeurs doivent fournir une fichier yaml décrivant:
- L’environnement courant (ex : development)
- Le next environnement (ex : staging)
- La méthode de déploiement Kubernetes (ex : Rolling Upgrade pour un déploiement en zero downtime)
- Le repository et sa branche
- Les commandes à effectuer lors du build (ex : rake db:migrate)
Apprenda, qui a décidé d’intégrer Kubernetes à son offre pour un meilleur support des Cloud Native Application, aborde également le sujet du CI/CD. Leur objectif est de proposer un PaaS capable d’héberger les applications legacy / monolithiques, et les cloud native applications. L’utilisation d’une plateforme de CI/CD capable d’orchestrer le déploiement d’applications hybrides (leur démo s’appuie sur UrbanCode) est une première étape qui permet de répondre à la problématique du déploiement. Les problèmes ne sont pas tous résolus et notamment le fait que :
- Le pipeline de déploiement doit être régénéré à chaque ajout/suppression de composant
- Le déploiement va à la vitesse du composant le plus lent
Leur solution est de créer une plateforme spécifique qui comprend les mécanismes des deux mondes, facilitant le déploiement et la communication des applications entre elles. Nous espérons qu’elle soit un jour reversée à la communauté.
Comment tester rapidement mes applications ?
Can Yücel, ingénieur logiciel chez LaunchPad Central est venu expliquer la stratégie de tests applicatif qu'ils ont mis en place. Nous parlons bien de tests d’applications déployées sur Kubernetes et non des tests de l’infrastructure Kubernetes (les grands oubliés de cette KubeCon).
Kubernetes permet de déployer rapidement des applications, c’est cette propriété qui a été initialement utilisée chez LaunchPad. L’orchestration est la suivante :
- Un cluster complet est construit
- Ce cluster contient les applications à tester
- Lorsque les tests sont tous bons le cluster est détruit
- Dans le cas inverse, il est conservé pour debugging
Provisionner un cluster isolé pour du tests est une bonne pratique. Cependant la boucle de feedback peut être longue et cela nécessite d’avoir des machines à disposition.
Comment réduire ma boucle de feedback ?
https://twitter.com/etiennecoutaud/status/707972505781334016
Les namespaces Kubernetes permettent de séparer logiquement les ressources au sein d’un même cluster. Ainsi il est recommandé de séparer chaque environnement d’un projet dans son namespace isolé. Grâce à cela, les tests sont exécutés sur le même cluster que la production, il n’est plus nécessaire d’avoir des machines dédiées au testing, la boucle de feedback est réduite.
Suis je le seul sur Kubernetes ? Que font les autres ? qui norme ?
La fondation CNCF (Cloud Native Computing Foundation) a été un sujet récurrent lors des deux jours de conférences.
L’objectif de cette fondation est de soutenir et pousser l’adoption des technologies de conteneurisation, les architectures distribuées de type microservice, et l’automatisation de leur gestion. Certaines tables rondes ont été faites pour discuter de la gouvernance autour des Cloud Native Applications, et de l’alignement des stratégies de contenerisation. La CNCF, fondée en Novembre 2015, a annoncé que Kubernetes est le premier projet à être intégré lors de la KubeCon 2016.
https://twitter.com/lxpollitt/status/707928855865126913
Toutes les bonnes choses ont une fin ...
En conclusion, cette édition 2016 de la KubeCon a été riche en annonces, retours d'expérience et démonstrations des outils gravitant dans l'écosystème Kubernetes. OCTO Technology a pu ainsi conforter sa vision de l’intégration de ces outils chez ses clients.
Cet écosystème autour du conteneur est un changement de paradigme pour tous les acteurs de l’IT, du développeur à l’opérationnel. Même si cette technologie peux paraître difficile à mettre en place et à apprivoiser, la principale difficulté est le changement des organisations, des méthodologies et des processus. Comme l’a dit Ivan Pedrazas ‘It’s not a technology thing, it’s all about people”.