Let's play with Cassandra... (Part 3/3)
In this part, we will see a lot of Java code (the API exists in several other languages) and look at the client part of Cassandra.
Use Case #0: Open and close a connection to any node of your Cluster
Cassandra is now accessed using Thrift. The following code opens a connection to the specified node.
TTransport tr = new TSocket("192.168.216.128", 9160);
TProtocol proto = new TBinaryProtocol(tr);
tr.open();
Cassandra.Client cassandraClient = new Cassandra.Client(proto);
...
tr.close();
As I told previously, the default API does not provide any pool connections mechanisms that would have (1) the capacity to close and reopen connections in case a node has failed, (2) the capacity to load-balance requests among all the nodes of the cluster and (3) the capacity to automatically requesting another node in case the first attempt fails.
Use Case #1: Insert a customer
The following code insert a customer in the storage space (note that the object aCustomer is the object you want to persist)
Map<String , List< ColumnOrSuperColumn > > insertClientDataMap = new HashMap< string ,List<ColumnOrSuperColumn > >();
List< ColumnOrSuperColumn > clientRowData = new ArrayList< ColumnOrSuperColumn >();
ColumnOrSuperColumn columnOrSuperColumn = new ColumnOrSuperColumn();
columnOrSuperColumn.setColumn(new Column("fullName".getBytes(UTF8),
aCustomer.getName().getBytes(UTF8), timestamp));
clientRowData.add(columnOrSuperColumn);
columnOrSuperColumn = new ColumnOrSuperColumn();
columnOrSuperColumn.setColumn(new Column("age".getBytes(UTF8),
aCustomer.getAge().toString().getBytes(UTF8), timestamp));
clientRowData.add(columnOrSuperColumn);
columnOrSuperColumn = new ColumnOrSuperColumn();
columnOrSuperColumn.setColumn(new Column("accountIds".getBytes(UTF8),
aCustomer.getAccountIds().getBytes(UTF8), timestamp));
clientRowData.add(columnOrSuperColumn);
As you can read, the first line is in fact a Java representation of the structure: a map in which a row is identified by its key, and the value is a list of columns. The rest of the code only create and append ColumnOrSuperColumn objects. Here, the columns have the following names: fullName, age, accountIds. You will also notice that when you create the column, you specify the timestamp the column is created. Remember that this timestamp will be used for "read-repair" and so that all your clients must be synchronized (using a NTP for instance)
insertClientDataMap.put("customers", clientRowData);
The above lines put the list of Columns into the ColumnFamily named customers (so you can add several ColumnFamily in one time with the batch_insert method). Then, the following line inserts the customer into the Cassandra Storage. You need so to specify the keyspace, the row key (here the customer name), the Column family you want to insert and the Consistency Level you have chosen for this data.
cassandraClient.batch_insert("myBank", aCustomer.getName(), insertClientDataMap, ConsistencyLevel.DCQUORUM);
Use Case #2: Insert operations for an account
Inserting an operation is almost the same code instead we are using SuperColumn.
Map< string , List< ColumnOrSuperColumn > > insertOperationDataMap = new HashMap< string , List< ColumnOrSuperColumn > >();
List< ColumnOrSuperColumn> operationRowData = new ArrayList< ColumnOrSuperColumn >();
List< Column > columns = new ArrayList< Column >();
// THESE ARE THE SUPERCOLUMN COLUMNS
columns.add(new Column("amount".getBytes(UTF8),
aBankOperation.getAmount().getBytes(UTF8), timestamp));
columns.add(new Column("label".getBytes(UTF8),
aBankOperation.getLabel().getBytes(UTF8), timestamp));
if (aBankOperation.getType() != null) {
columns.add(new Column("type".getBytes(UTF8),
aBankOperation.getType().getBytes(UTF8), timestamp));
}
For now, there is nothing new. A list of Columns is created with three columns: amount, label and type (withdrawal, transfer...).
// here is a superColumn
SuperColumn superColumn = new
SuperColumn(CassandraUUIDHelper.asByteArray(CassandraUUIDHelper.getTimeUUID()),
columns);
ColumnOrSuperColumn columnOrSuperColumn = new ColumnOrSuperColumn();
columnOrSuperColumn.setSuper_column(superColumn);
operationRowData.add(columnOrSuperColumn);
This case is different from the previous one. Instead of adding the previously defined Columns to the row, we create a SuperColumn with a dynamic (and time-based UUID) name...Quite dynamic isn't it? Then, the three columns are added to the super column itself. The end of the code is similar to the previous one. The row is added to the ColumnFamily named operations and then associated to the current customer account id.
// put row data dans la columnFamily operations
insertOperationDataMap.put("operations", operationRowData);
cassandraClient.batch_insert("myBank", aCustomer.getAccountIds(),
insertOperationDataMap, ConsistencyLevel.ONE);
Here is what you get when reading the operations for the accounId 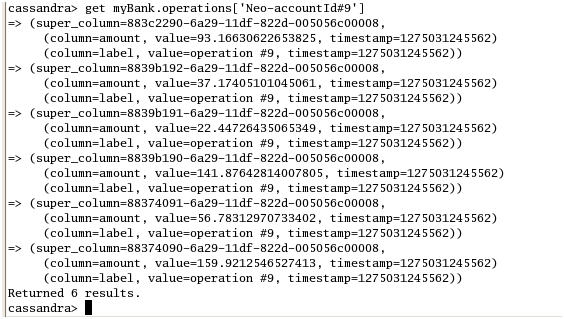
Use Case #3 : Removing an item
Removing a complete row is - in terms of API - as simple as the rest of the API.
cassandraClient.remove("myBank", myAccountId, new ColumnPath("operations"), timestamp, ConsistencyLevel.ONE);
It is yet a little more complex when you are looking inside. In brief, in a distributed system where node failure will occur, you can't simply physically delete the record. So you replace it by a tombstone and the "mark as deleted" record will be effectively deleted once the tombstone will be considered enough old. At least, you can still use "logical deletion" and write a code that do not use these flagged records.
To (quickly) conclude this series of articles
I really like Cassandra which looks like a ready to use tools (even if NoSQL is plenty of great tools) and a way to achieve high performance system at “low” (at least lower) cost than with commercial tools. There are still concerns I hope I will be able to discuss like security (Cassandra provides authentication mechanisms…), searching (or at least getting ranges of datas), monitoring (and how to monitor all the nodes of your cluster into a unique tools like Ganglia, Nagios or Graphite or even how to use Hadoop above Cassandra.
To be continued…