Let's play with Cassandra...(Part 2/3)
In this part, we will work in more details and closer to the code with Cassandra. The idea is to provide a kind of simplified current account system where a user has an account and the account has a balance… This system will so manipulate the following concepts: - A client has different kind of properties defining his identity - A client has one account - The account has a list of operations (withdrawal, transfer are all kind of operations) Here is the way it would have been modelized in the relational world (or at least UML world) 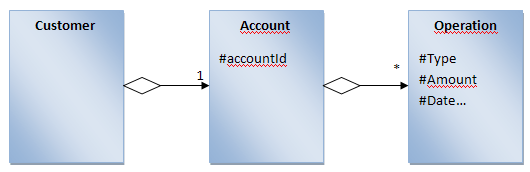
The Cassandra set up
I will not drive deep into the details of a Cassandra set up. This article explains it in details but here are the main points.
Define your cluster
Each nodes of the cluster has a configuration file called storage-conf.xml where are defined the following main sections - Cluster and Keyspace definition. The cluster is made of several nodes (the Seed) which store all the Keyspaces you will define (and of course data). As we talked about in the previous part [add a link], you define the Keyspace that will contain all the ColumnFamily.
<storage>
<clustername>Test Cluster</clustername>
<autobootstrap>false</autobootstrap>
<keyspaces>
<keyspace Name="myBank">
...
</keyspace></keyspaces>
...
<partitioner>org.apache.cassandra.dht.RandomPartitioner</partitioner>
<initialtoken></initialtoken>
<seeds>
<seed>192.168.216.129</seed>
<seed>192.168.216.130</seed>
</seeds>
</storage>
Then, you define the IP address of all the nodes (ie. The seeds) that will compose your cluster. During the startup phase, all the nodes will communicate to each other (using Gossip protocol), thus detecting starting or node failures. You can go further in the definition of your cluster topology and group (as far as I know in another conf file) IPs by datacenters.
The InitialToken, if not defined, will automatically be set by Cassandra (based on the cluster topology and following the Consistent Hashing algorithm). The documentation gives more details about ring management The partitioner is a much more tricky and Cassandra provides, by default, two partitioners : the RandomPartitioner and the OrderPreservingPartitioner. In the first case, the data will be partitioned using a row key hash (typically md5). In the second case, the data will be partitioned in their natural order and thus facilitates the range queries. So once again, the choice you made (and you cannot change it during your cluster life) is depending on the way your data is manipulated.
- Node access
<listenaddress>192.168.216.128</listenaddress>
<storageport>7000</storageport>
<thriftaddress>192.168.216.128</thriftaddress>
<!-- Thrift RPC port (the port clients connect to). -->
<thriftport>9160</thriftport>
...
The ListenAddress and ThriftAddress enable to define the current IP and listening port for the current node. The first IP is used by all the nodes to gossip each others. The second address is the one used by thrift clients to connect to the node and insert, delete or update data.
Define your data models
In our example, we will define two ColumnFamily. The first one will store all the customers. The second one all the operations.
<keyspace Name="myBank">
<columnfamily CompareWith="UTF8Type" Name="customers"/>
<columnfamily CompareWith="TimeUUIDType" Name="operations" ColumnType="Super" CompareSubcolumnsWith="UTF8Type"/>
<replicationfactor>2</replicationfactor>
<replicaplacementstrategy>org.apache.cassandra.locator.RackUnawareStrategy</replicaplacementstrategy>
<keyscachedfraction>0.01</keyscachedfraction>
<endpointsnitch>org.apache.cassandra.locator.EndPointSnitch</endpointsnitch>
</keyspace>
To begin with the simplest things, the replicationFactor defines the number of nodes the data will be replicated. Then let’s talk about the ColumnFamily. First, you will notice that the schema for each ColumnFamily is not defined (whereas the actual 0.6 version of Cassandra does not allow dynamically adding or removing ColumnFamily, the 0.7 should provide this feature) and you only know that customers and operations will be stored. Data modeling If you look at the UML diagram representing the different concepts, you will notice that there is a “one-to-many” relationship between an account and the operations on this account. An easy way to model this in Cassandra is by using the SuperColumn. Thus the operation has the following structure:
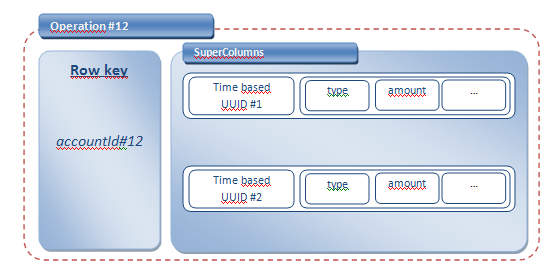
Thus: - The key is the account Id - The “Value” is a SuperColumn which stores all the operations for this account (the limitation of this model is the number of operations you could have…). Thus the operation is a list of columns (type, amount, date…) ordered by a time-based UUID inside the SuperColumn. The CompareWith tells Cassandra how to sort the columns (remember the column are sorted, within a row, by their name. In our examples, I want my operations (whose name is a time-based UUID) to be chronologically sorted. That's what I specify to Cassandra with the CompareWith attribute. The CompareSubcolumnsWith attribute will be responsible for sorting the Column included in the SuperColumn... Here is what you get using the Cassandra-cli tools