Let's play with Cassandra... (Part 1/3)
I have already talked about it but BigTable.
Hybrid firstly because Cassandra uses a column-oriented way of modeling data (inspired by the BigTable) and permit to use Hadoop Map/Reduce jobs and secondly because it uses patterns inspired by Dynamo like Eventually Consistent, Gossip protocols, a master-master way of serving both read and write requests...
Another DNA of Cassandra (and in fact a lot of NoSQL solutions) is that Cassandra has been built to be fully decentralized, designed for failure and Datacenter aware (in a sense you can configure Cassandra to ensure data replication between several Datacenter…). Hence, Cassandra is currently used between the 50+ TB of data on a 150 node cluster.
Data Modeling
The column oriented model is quite more complex to understand than the Key/Value model. In a Key/value model, you have a key that uniquely identify a value and this value can be structured (based on a JSON format for instance) or completely unstructured (typically a BLOB). Therefore and from the basis, the simplest way to understand the column-oriented model is to begin with a Key/Value model and imagine that the Value is a collection of other Key/Value elements. In brief, this is a kind of structure where Hashmaps are included in another Hashmap...
Completely lost? Here are a the main elements Cassandra defined (this article or the Cassandra documentation provide a more in depth view of the different types of structures you can have in Cassandra) - Column. The basic element which is a tuple composed of a timestamp, a column name and a column value. The timestamp is set by the client and this has an architectural impact on clients’ clocks synchronization. - SuperColumn. This structure is a little more complex. You can imagine it as a column in which can store a dynamic list of Columns. - ColumnFamily: A set of columns. You can compare a ColumnFamily to a table in the relational world except the number and even (I am not sure this is the best idea but anyway) the names of columns can vary from a row to another. More important, the number of columns may vary during time (in the case for instance your schemas need to be upgraded etc…). Cassandra will not force any limitation in that case but your code will have to deal with these different schemas. - KeySpaces: A set of ColumnFamily. Hence, the Keyspace configuration only defines (from the data modeling concern) the included ColumnFamily. The notion of “Row” does not exist by itself: this is a list of Columns or SuperColumns identified by a row key.
Data Partitioning and replication
Data Partitioning is one of tricky point. Depending on the studied tools, partitioning can be done either by the client library or by any node of the cluster and can be calculated using different algorithms (one of the most popular and reliable being the Consistent Hashing. Cassandra lets the nodes of the cluster (and not the client) partitioning the data based on the row key. Out of the box, Cassandra can nevertheless use two different algorithms to distribute data over the nodes. The first one is the RandomPartitionner and it gives you an equally and hash-based distribution. The second one is the OrderPreservingPartitioner and guarantees the Key are organized in a natural way. Thus, the latter facilitates the range queries since you need to hit fewer nodes to get all your ranges of data whereas the former has a better load balancing since the keys are more equally partitioned across the different nodes. Then, each row (so all the Columns) is stored on the same physical node and columns are sorted based on their name.
Moreover, and this is more linked to data replication, Cassandra natively enables replication across multiple datacenters and you can - by configuration - specify which nodes are in which Data Center. Hence, Cassandra would take care of replicating the data on at least one node in the distant Data Center (the partition-tolerant property of the CAP Theorem is so meaning full and I guess simpler to understand...).
Consistency management, conflict resolution and atomicity
NoSQL solutions like Voldemort or Cassandra have chosen Availability and Partition-tolerance over Consistency. Thus, different strategy have been setting up: “Eventually Consistent”.
Dealing with consistency is so a matter of dealing with data criticism and being able to define –for each data – the consistency level you need (based on the trade-offs the CAP Theorem imply). Cassandra defines different levels of consistency and I will not go into further details but here are a couple of them: - ONE. Cassandra ensures the data is written to at least one node's commit log and memory table before responding to the client. During read, the data will be returned from the first node where it is found. In that case, you must accept stale state because you have no warranty the node you hit to read the data has the last version of the data. - QUORUM. In that case, Cassandra will write the data on < replicationfactor >/2 + 1 nodes before responding to the client (the Replication factor is the number of nodes the data will be replicated and is defined for a Keyspace). For the read, the data will be read on < replicationfactor >/2 + 1 nodes before returning the data. In that case, you are sure to get a consistent data (because N is smaller than R+W where N is the total number of nodes where the data is replicated, R the number of nodes where this data is being read and W the number of nodes the data is being written) - ALL. In that case, Cassandra will write and read the data from all the nodes.
Of course, at a given time, chances are high that each node has its own version of the data. Conflict resolution is made during the read requests (called read-repair) and the current version of Cassandra does not provide a Vector Clock conflict resolution mechanisms (should be available in the version 0.7). Conflict resolution is so based on timestamp (the one set when you insert the row or the column): the higher timestamp win and the node you are reading the data is responsible for that. This is an important point because the timestamp is specified by the client, at the moment the column is inserted. Thus, all Cassandra clients’ need to be synchronized (based on an NTP for instance) in order to ensure the resolution conflict be reliable.
Atomicity is also weaker than what we are used to in the relational world. Cassandra guarantees atomicity within a ColumnFamily so for all the columns of a row.
Elasticity
"Cassandra is liquid" would have written any marketer and to be honest, a lot of NoSQL solutions have been built upon this DNA. First of all, elasticity is at the data modeling level. Your data will live longer than your business rules and softness in the way your data schemas can evolve across the time is an interesting point.
But elasticity is also about infrastructure and cluster sizing. Adding a new node to Cassandra is simple. Just turn on the AutoBootstrap property and specify at least one Seed of the current cluster. The node will hence be detected, added to the cluster and the data will be relocated (the needed time depends on the amount of data to transfer). Decommissioning a node is almost as simple as adding a node except you need to use the nodetool utility (which provides more options to visualize the streams between the nodes...) or a JMX command.
Cassandra monitoring
Cassandra runs on a JVM and exposes JMX properties. You can thus collecting monitoring information using jConsole or any JMX compliant tool.
For instance, you can monitor - Your nodes (which are part of the cluster, which are dead…) 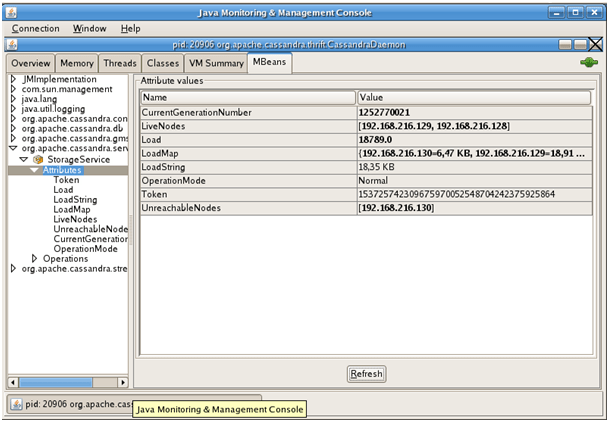
- the streams between your nodes (especially in the case you added or removed nodes) - Or stats. For instance, per-Column Family basic stats would be: Read Count, Read Latency, Write Count and Write Latency etc...
More JMX plugins are available here (provides graphs...) and some guys are developing web console.
Access protocol
Cassandra is called using Thrift (even if the 0.6 version introduced Avro protocol). As we told previously, Cassandra is responsible for routing the request to the proper node so you can reach any node of your cluster to serve your request. Nonetheless, the default thrift client API does not provide any load-balancing or connection pool mechanisms. Concerning the connection pool, the main lacks, in my opinion, are (1) the capacity to close and reopen connections in case a node has failed, (2) the capacity to load-balance requests among all the nodes of the cluster and (3) the capacity to automatically request another node when the first attempt fails. A higher level of load-balancing could be setup on the service layer
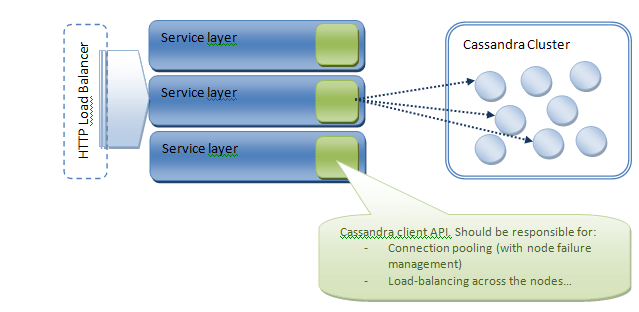
Certain library (for instance Hector in the Java World) provides connections pooling mechanisms and even kind of round-robin load balancing...
In the next part, we will play in more details with Cassandra...