NewSQL
NewSQL. Beaucoup penseront à NoSQL. NewSQL est tiré du monde NoSQL mais reste différent. Comme NoSQL il s'agit d'une nouvelle architecture logicielle qui propose de repenser le stockage des données. Comme NoSQL elle tire partie des architectures distribuées, des progrès du matériel et des connaissances théoriques depuis 30 ans. Mais contrairement à NoSQL elle permet de conserver le modèle relationnel au coeur de notre SI. Est-ce seulement un moyen de plus pour surfer sur la vague NoSQL? Nous ne le pensons pas. Dans cette série d'articles nous allons étudier en profondeur cette architecture. Notre objectif est de vous montrer les innovations et leurs apports dans l'architecture de stockage d'un SI d'aujourd'hui. Cette étude a été étayée par la réalisation d'un POC tirée d'un cas réel pour vous faire partager également les difficultés de mise en oeuvre de tels produits.
Qu'est-ce que NewSQL ?
Ce schéma - librement adapté de la version originale de InfoQ - montre que NewSQL est né de la rencontre de 3 types d'architecture : relationnelle, NoSQL et grille de données (ou cache distribué). 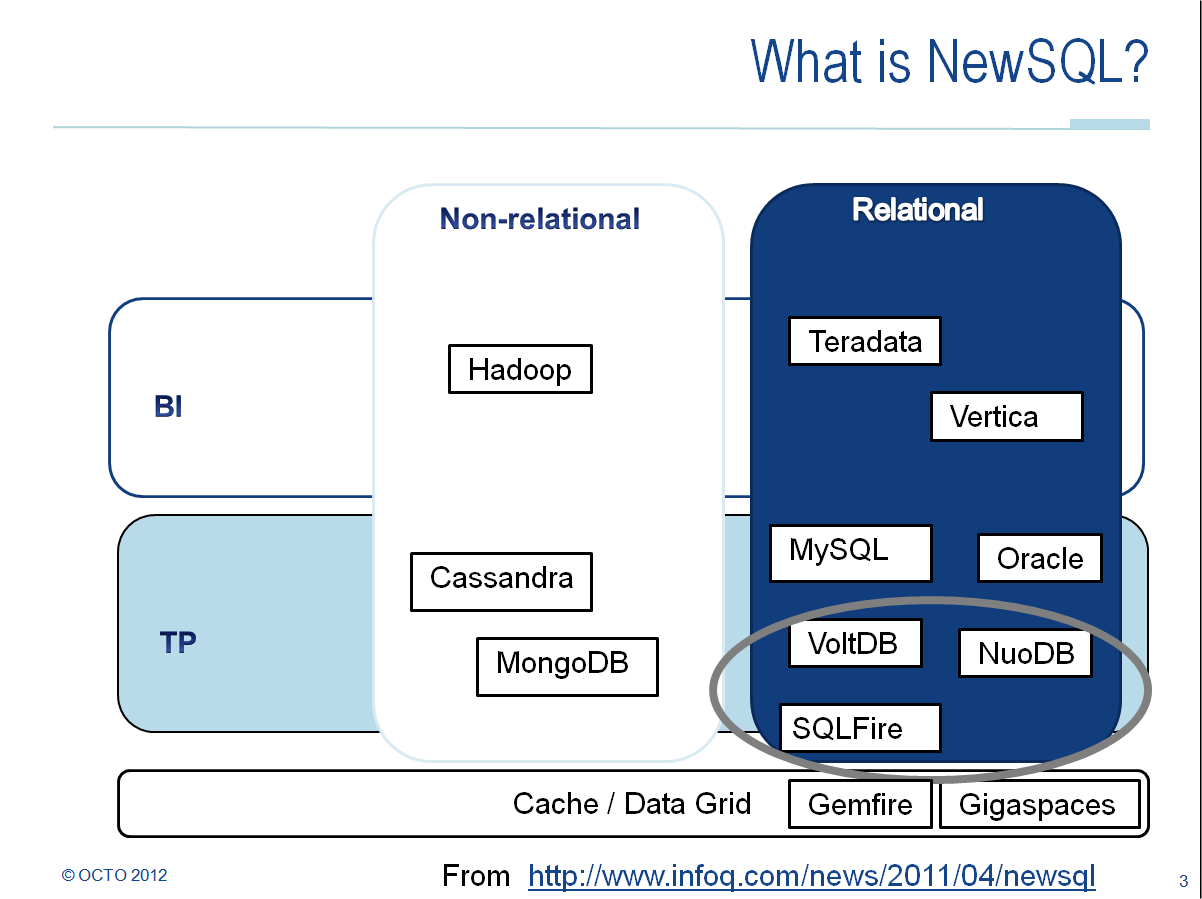
En synthèse une solution NewSQL est un stockage distribué, potentiellement entièrement en mémoire, et pouvant être requêté classiquement par une interface SQL.
Qu'est-ce que NewSQL a de différent?
Depuis plusieurs années déjà - mi 1990 sur Mainframe -, des bases relationnelles distribuées existent. Ce marché est particulièrement développé côté décisionnel, un petit peu avec Oracle RAC et DB2 côté transactionnel. Ces produits concurrencent les grands serveurs depuis quelques années sur des benchmarks comme le TPC-C. Cependant le marché n'a jamais complètement décollé. Ces produits sont selon moi plus complexes qu'une base de données sur un grand serveur tout en nécessitant des architectures de type SAN. La distribution d'un schéma relationnel est également un sujet très épineux. En effet, pour assurer des transactions distribuées totalement ACID un modèle Shared Disk ou Shared Data est nécessaire. Des technologies très avancées dans ce domaine sont nécessaires pour que les transactions distribuées ne posent pas de problème de performance.
Depuis plusieurs années déjà - fin des années 90 -, les grilles de données existent. Elles offrent des débits 10 fois supérieurs aux SSD (Solid State Drive) et des temps d'accès 100 fois inférieurs.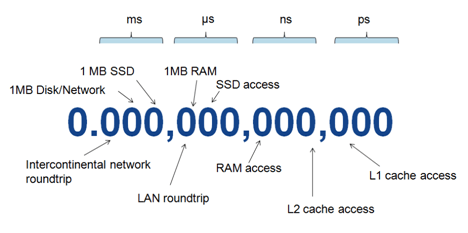
[caption id="attachment_34719" align="aligncenter" width="567" caption="Chute d'un noeud sur Oracle Coherence (Figure 8.3 de la documentation)"] 
Plus récemment, les technologies NoSQL ont montré leur puissance en terme de scalabilité pour répondre aux besoins des grands du web. Les techniques de partitionnement de la donnée, et la capacité à utiliser du commodity hardware d'un bout à l'autre de la chaîne ont été éprouvées chez ces grands acteurs que sont Google, Amazon et Facebook. En particulier, ces acteurs ont largement investi en recherche opérationnelle sur la résilience de ces solutions et la capacité à ajouter ou fournir de nouveaux noeuds. Cependant là encore, l'adoption reste lente à se faire. La différence d'interface - base colonne ou base document - reste forte par rapport au standard SQL des SI. Mais c'est aussi cette simplicité des interfaces qui permet d'identifier facilement des clés de partitionnement permettant la distribution des données.
L'architecture NewSQL n'est donc pas totalement nouvelle mais reprend de ces expériences antérieures plusieurs caractéristiques tout en faisant des choix qui lui sont propres.
- Le choix d'une interface SQL et d'un schéma relationnel. SQL étant la lingua franca du SI.
C'est un argument majeur par rapport aux autres solutions. - Un schéma relationnel avec des limitations pour faciliter la distribution des données et des traitements.
Malgré certaines divergences entre les produits, toute action d'écriture dont le plan d'exécution ne peut pas être colocalisé n'est pas nativement supportée en SQL et renverra une erreur. Une procédure spécifique, sous forme de Map/Reduce peut offrir une solution palliative. De la même façon, le niveau des transactions est souvent limité au modeREAD_COMMITTED. Ce choix structurant par rapport aux bases relationnelles distribuées améliore les performances en réduisant drastiquement les échanges entre les noeuds. Est-ce une contrainte par rapport à la promesse du SQL de répondre à toutes les requêtes? Certainement. Mais en lisant plus en détail A relational model of data for large shared data banks - l'acte de naissance du modèle relationnel - on remarque que la notion de table n'est qu'un cas particulier de la relation. Chaque colonne est vue comme un ensemble indépendant. En lisant A history of system R - System R est la première implémentation de l'architecture relationnelle - en particulier le paragraphe RSS access path, on comprend que la notion de table telle qu'on l'a connait est devenue fondamentale pour stocker les données avec la relation pour que les écritures et lectures simples minimisent le nombre d'I/O : Rather than storing data values in separate "domains" [...], the RSS chose to store data values in the individual records of the database. En somme nous vivons depuis 30 ans avec quelques contraintes liées à l'écriture sur disque. A mon avis, les contraintes liées à la distribution sont tout autant supportables. - Utiliser la distribution et la réplication des données pour assurer la scalabilité et la résilience des données.
Ce changement d'architecture majeur permet à ces technologies de fonctionner sur un ensemble de machines de type commodity hardware.
Pourquoi est-ce un sujet aujourd'hui?
Les bases de données relationnelles ont été conçues il y a près de 30 ans. Elles ont progressivement bénéficé des avancées technologiques, notamment les SSD ces dernières années, mais elles restent basées sur des axiomes liés au matériel de ces années là :
- Stockage orienté disque et indexé
- Utilisation du multi-threading pour masquer les accès I/O
- Concurrence basée sur des verrous
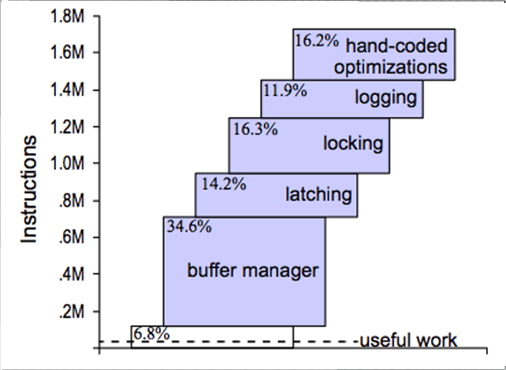
L'étude présentée par Ben Stopford à QCon 2011 montre que seulement 6% des instructions sont réellement utilisées pour le stockage des données.
Michel Stonebaker, co-auteur de PostgreSQL puis fondateur du produit VoltDB, participait à une étude en 2007 sur les bases de données. Cette étude porte le sous-titre It’s Time for a Complete Rewrite. La notion de résilience à l'aide d'un log y est par exemple challengée.
L'exemple le plus frappant à mon sens du progrès des technologies est l'évolution comparée du prix des composants de stockage [2].
| 1980 | 2010 | |
|---|---|---|
| HDD | 500,000 $/GB | 0.1 $/GB |
| RAM | 2,000,000,000 $/GB | 2 $/GB |
Malgré l'explosion du volume de données, l'ensemble des données opérationnelles tient aujourd'hui pour la majorité des cas en mémoire et la totalité des données historiques sur les disques.
Les expériences des Géants du Web en terme de partitionnement de la donnée ont également contribué à faire progresser la science informatique et à montrer que la distribution de la donnée était viable.
Alors, est-ce aujourd'hui la fin des bases de données relationnelles? Pas forcément car elles ont prouvé leur efficacité pendant plus de 30 ans. De la même façon que les fichiers indexés sont encore là, les applications existantes continueront de fonctionner sur les bases de données relationnelles. Mais dans certains environnements, notamment les environnements virtualisés et le cloud, stocker la donnée de façon distribuée sur un ensemble de machines banalisées peut constituer un avantage décisif. Et, selon moi, ce sujet doit être traité dès à présent pour tirer parti des nouvelles architectures.
Conclusion
Alors, comment passer à NewSQL? Je suis le premier à reconnaître que même en cas de besoin de performance, optimiser une base relationnelle et/ou la couche Hibernate reste plus rapide que migrer vers une technologie disruptive. Les objectifs du POC réalisés ont donc été :
- En partant d'une application existante avec Hibernate sur une base relationnelle, quels sont les changements à réaliser pour aller vers une base NewSQL?
- En partant sur une solution NewSQL, quels gains de performance puis-je espérer?
- Quelle architecture proposer pour tirer parti de NewSQL?
Les articles suivants de cette série vous présenteront différents retours de ce POC que nous avons réalisé dans un premier temps avec le produit SQLFire de VMWare.