NewSQL: Comment distribuer ses données avec SQLFire
Contexte
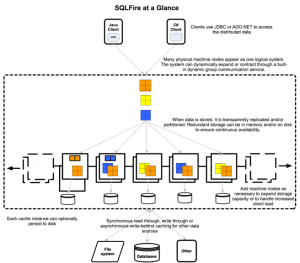
SQLFire est une base de données relationnelle "in memory", c'est-à-dire qu'à tout instant ses données sont disponibles en mémoire vive. Les performances attendues sont donc très élevées, mais ce choix impose une limite sur le volume de données que peut stocker efficacement une instance (hors overflow sur le disque).
Pour franchir cette limite, pour permettre un failover en cas de panne matérielle et pour pouvoir monter en puissance, les concepteurs de SQLFire ont choisi d'encourager les développeurs à partitionner et répliquer leurs données sur plusieurs machines, toutes connectées sur un réseau local.
L'architecture choisie est de type share nothing, ce qui a des conséquences intéressantes à la fois pour le développeur et pour les performances. Ce deuxième article va présenter le mécanisme de partitionnement de SQLFire, proposer une méthodologie pour adapter le modèle de données, et discuter les conséquences des choix d'architecture de la solution.
Comment réaliser son partitionnement
Les concepts fondamentaux de SQLFire sont assez ordinaires pour ceux qui ont déjà touché le sujet : modélisation relationnelle, sharding, share nothing, colocalisation, réplication synchrone et asynchrone… Ils sont néanmoins implémentés d'une manière originale qui exige un travail de modélisation rigoureux.
Les choix de partitionnement sont explicités dans le schéma SQL, enrichi de quelques mots-clefs pour l'occasion (ces extensions sont d'ailleurs la seule déviation de SQLFire par rapport à la norme). Une fois le schéma décrit, le partitionnement sera transparent pour toutes les insertions, lectures, et updates.
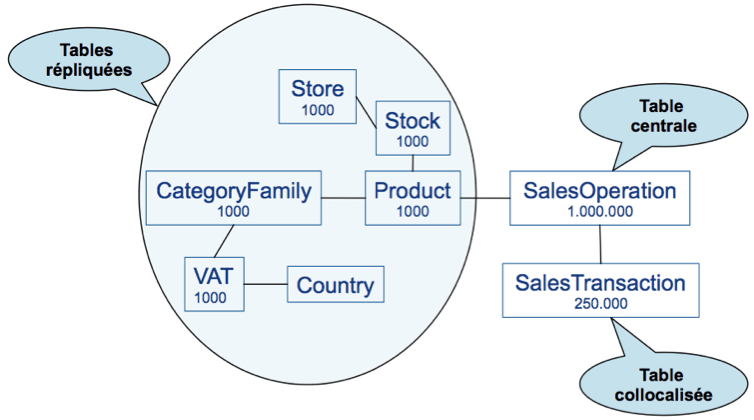
La première tâche consiste à identifier au sein du modèle métier un concept central qui servira de pivot pour organiser le reste des données volumineuses. Dans une banque, l'analyse du compte et des prêts en cours se fera autour d'un Client. Dans un supermarché, l'élément central pourra être un passage en caisse, lié à un ensemble d'articles et à un paiement.
CREATE TABLE BankClient (… primary key (id))
PARTITION BY (id);
Afin de bien répartir ces objets sur toutes les instances SQLFire, il est important que la colonne choisie pour le partitionnement contienne suffisamment de valeurs différentes. Pour un accès aléatoire, un identifiant unique hashé fonctionnera bien. Par contre choisir le mois du passage en caisse serait contre-productif, car la plupart de mes insertions concerneraient le mois courant, donc une seule instance !
Il faut ensuite identifier les données auxiliaires, des tables volumineuses qui seront colocalisées avec l'objet métier central. La colocalisation doit être explicite.
Autour d'un client de la banque, on aura donc tous ses comptes, son historique, ses données personnelles etc. Colocaliser ces données est une bonne pratique, car les traitements locaux sont plus rapides que les traitements distribués; en SQLFire c'est aussi obligatoire (on verra pourquoi plus tard).
CREATE TABLE Account (… client_id int constraint FK4A[..] references BankClient …)
PARTITION BY COLUMN (client_id)
COLOCATE WITH (BankClient);
Un point important: la clef de partitionnement doit aussi être la clef de partitionnement de l'objet principal. Toutes les tables colocalisées doivent posséder la ou les colonnes qui constituent la clef de partitionnement de la table principale.
Si les données de la table principale sont équilibrées, on peut s’attendre à ce que les tables auxiliaires soient aussi bien équilibrées, sauf biais très important.
A cet instant, il faut prendre le temps d’examiner les patterns d’accès pour valider les choix précédents. Est-ce que mes accès en journée sont bien répartis sur toutes les instances ? Est-ce que les requêtes les plus fréquentes et mon batch de reporting trouveront toutes les données nécessaires sur la même instance ?
Les données restantes seront typiquement des données référentielles, assez statiques et moins volumineuses. Ces données seront répliquées intégralement et à l'identique sur chacun des nœuds. Toute modification sera propagée de manière synchrone sur le réseau local. Exemple simple: la liste des points de vente.
CREATE TABLE Store (…) REPLICATE;
CREATE TABLE Country (…) REPLICATE;
Exemple de partitionnement
Limitations
Il est indispensable de mentionner un point fondamental d'architecture SQLFire: une jointure ne peut se faire que sur des données de l'instance locale. Autrement dit, sur la table centrale, les données colocalisées et les données référentielles.
Si le schéma ne permet pas de prouver que les données d'une jointure se trouvent sur la même instance, SQLFire refusera d'exécuter la requête.
Est-ce une limitation? Oui, mais c'est une limitation que toutes les bases de données distribuées vont rencontrer dans la vie réelle en essayant de scaler horizontalement. SQLFire a décidé d'être ferme sur ce point, et d'éliminer à la source le goulet d'étranglement. On ne fait pas circuler des données sur le réseau local lors d'une jointure, donc on restera performant en ajoutant des instances.
Bénéfices
En échange de cette discipline, SQLFire offre un certain nombre de bénéfices:
- les données et la charge de travail sont bien réparties
- la scalabilité des requêtes est excellente (car aucune donnée de jointure ne passe par le réseau). Elle n'est limitée que par la taille du résultat
- la scalabilité des inserts est bonne, car il est toujours possible de savoir à partir d'une ligne vers quelle instance elle sera stockée (1 hop au maximum à partir de l’instance qui reçoit la requête)
- la garantie qu'une nouvelle requête distribuée ne provoquera pas de mauvaise surprise
- un rééquilibrage des données lors de l’ajout/suppression d’un noeud
Et bien sûr le partitionnement est transparent pour le client.
Autres informations utiles
Pour bien répartir les données, SQLFire fournit plusieurs options. Il est possible de hacher la colonne de partitionnement, de fournir des listes et intervalles de valeurs. Il est aussi possible de hacher une fonction de n'importe quels champs de la table.
Les données sont par défaut redondées sur plusieurs instances. Si une instance tombe, SQLFire se débrouillera pour avoir les données sur au moins deux instances avant de permettre de nouveaux commits. C'est un failover beaucoup plus rapide que le Dataguard d'Oracle, par exemple.
SQLFire prend en compte la topologie physique pour redonder le mieux possible: il observe les IP de ses instances et accepte un paramètre de « groupe » qui représente par exemple des racks physiques connectés sur des alimentations différentes. Ainsi, il copiera une donnée sur une instance d’un groupe différent, ou avec une IP différente.
Conclusion
Le partitionnement offert par SQLFire est simple, explicite et efficace. Il impose au développeur de créer un schéma distribué propre et garantit des performances prédictibles et une bonne scalabilité.