The new Web application architectures and their impacts for enterprises - Part 1
Web applications evolve. From static HTML sites first to AJAX applications more recently, through multiple dynamic technologies (PHP, ASP, Java, Ruby on Rails…), Web application architectures and their dedicated tools regularly experience major advancements and breakthroughs.
For two years, we have seen a new wave of technologies coming, transforming the landscape of Web applications. Unlike RIA or AJAX before, there is no well defined name yet for this new trend. We will call it "MV* client-side architectures".
Here is the main principle: the server no longer manages the whole page but only sends raw data to the client; all the pages generation and user interactions management is done on the client side, that is to say in the browser.
In this post, we will go into details of this architecture and explain why it is emerging. In a second post, we will see why it is relevant to embrace it today, opportunities they offer and what are the likely impacts for enterprises.
New Web application architectures: what are we talking about?
This diagram illustrates the evolution of Web application architectures:
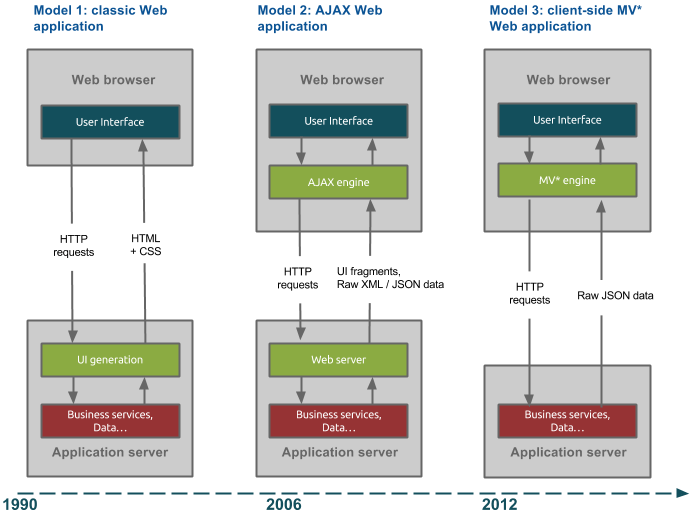
Model 1: classic Web application
On the first diagram, the Web application is mainly executed on the server side. It sends directly to the browser HTML pages, CSS and possibly JavaScript enhancing the behavior. Then, for each user action requiring new data, the server is queried and returns a whole new HTML page.
Model 2: AJAX Web application
The second diagram introduces the AJAX pattern, for Asynchronous JavaScript And XML, which appeared in the mid-2000s (see also this article by Jesse James Garrett: http://www.adaptivepath.com/ideas/ajax-new-approach-web-applications/).
This architecture principle can make the application more responsive by reducing exchanges between browser and server. When a user action generates a client call to retrieve new data, the server only returns view fragments. Thus, only a small part of the screen is refreshed, rather than the entire page. This requires the development of client-side JavaScript in order to manage partial refreshments, for example by using the jQuery library and its $.Ajax function or others tools more integrated with server platforms (such as Java Server Faces or Google Web Toolkit for Java environments).
This architecture brought more reactivity but also more complexity. It has many pitfalls:
- the extensive use of jQuery can make impossible the application maintenance, without implementing complex technical rules (offered today by MV* frameworks like Backbone.js and AngularJS)
- despite their aim to ease developments, server-side frameworks like Java Server Faces turned out to be very heavy and complex, leading to many bugs and performance issues.
Model 3: client-side MV* Web application
The third diagram shows the new MV* client-side architecture, whose principle disrupts with the previous ones: now the server sends only raw unformatted data and the client is responsible for generating the screen out of it.
The term MV* refers to the MVC pattern, for Model View Controller, widely used server-side to separate data and views management. More and more we use this term MV*, in order to highlight the little differences from pure MVC implementations. But this is an expert discussion…
The important point in this new architecture is the shift of all the UI logic from the server to the client.
This separation of concerns between server and client is not a new phenomenon. It has been taken back by native mobile applications, consuming APIs independent from the client. The new Web application architectures bring this possibility to Web applications.
Why were these architectures not implemented earlier?
Basically, the JavaScript language is there since the Web exists. The principle does not seem so revolutionary, since it is very similar to the classic client-server applications that existed already before the Web. So why did not we think of this new architectures earlier?
The answer is simple: it was not possible; except if you are Google!
Indeed, two factors were limiting the possibility to develop with JavaScript:
- browser limitations in terms of capacities and performances
- the lack of industrialization of JavaScript development
The end of browser limitations
The first point was obvious until Microsoft launches Internet Explorer 9 and 10. Slowness and bugs in previous versions prevented the deployment of applications massively using JavaScript.
Unless having the strike force of a Google engineering team, developing a Gmail in Internet Explorer 6 was simply not realistic.
Since Firefox and Chrome have become popular in the browser market, Microsoft has caught up, as shown in this chart:
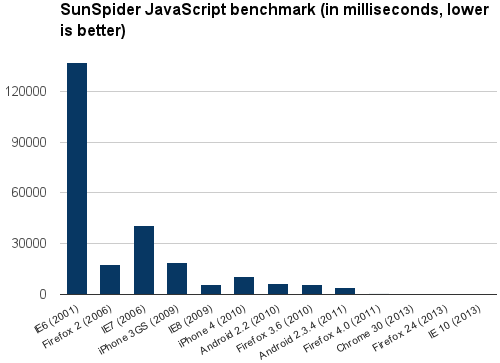
The results of SunSpider JavaScript performance tests in different browsers, illustrate the breakdown which happened around 2010, with the huge improvements in Internet Explorer: between IE6 and IE8, performance tests results have improved by factor 25, from 177000 ms to 7000 ms.
Since then, performances keep improving significantly. Together with the new capacities of both desktop and mobile devices, the browser can now do more than just displaying Web pages: it can dynamically generate pages, make 2D/3D drawings, execute complex algorithms, etc.
JavaScript development industrialization
But having a powerful execution platform is useless if we can not develop effectively.
The second technological revolution of Web development simply resides in JavaScript development tooling.
If you are following this blog, you may have already heard about AngularJS or Grunt. These are examples illustrating the new JavaScript development ecosystem, which can be summarized in two main categories:
- Development frameworks: while we had libraries like jQuery before for easing JavaScript development, developers now have proper frameworks for structuring their applications. There are two advantages: accelerating development and ensuring a better maintainability of the code. As of today, the best frameworks are AngularJS, Backbone.js and Ember.js.
- Industrialization tools: the industrialization of JavaScript development has exploded in the past two years, heavily inspired by what already existed for other platforms such as Java. The same way Java developers use Maven, JavaScript developers can now use Grunt to automate testing and build their application, as well as applying the specific front-end development workflow (files concatenation and minification, CSS sprites generation, etc.).
The industrialization is also driven by the fact that JavaScript is spreading over other areas than just Web applications, especially server-side with node.js. This is even more surprising to learn that node.js itself is used as the technical platform for Grunt and its numerous plug-ins.
As a conclusion, all the required tools exist today for developing effectively and industrializing JavaScript.
Conclusion of Part 1
In this article, we have presented what we mean by "MV* client-side architectures" and why they are now emerging.
In the following part, we will study why you should now use these architectures, what are the pitfalls to avoid and what are the impacts for enterprises.