MythBuster: Apache Spark • Épisode 2: Planification et exécution d'une requête SQL
Nous poursuivons aujourd'hui notre série d'articles dédiée à la démystification de Spark et plus particulièrement au moteur d'exécution Tungsten.
Pour rappel, dans l'épisode précédent, nous sommes partis d'une requête SQL sous forme de String que nous avons d'abord découpée en une instance de Seq[Token] grâce à notre classe Lexer, puis en une instance d'AST grâce à notre classe Parser. L'arbre formé par l'AST obtenu en sortie permet d'avoir une structure avec laquelle il est relativement simple d'intéragir au travers de notre code.
Dans cet épisode, nous allons chercher à transformer cet AST en un plan d'exécution, ce qui sera l'occasion de plonger au coeur du moteur d'optimisation Catalyst, dont nous détaillerons certains mécanismes utilisés dans la version 2.2 de Spark.
Nous aurons alors tout le matériel nécessaire pour mettre en place un modèle de génération de code similaire à celui de Spark, que nous traiterons dans le troisième épisode cette série d'articles.
L'ensemble du code dont nous allons parler ci-dessous est disponible dans notre dépôt GIT. N'hésitez-pas à aller y faire un tour !
Planification
Un peu de théorie…
Reprenons notre cheminement. Grâce à l'épisode précédent, nous sommes capables d'avoir une représentation sémantique d'une requête SQL exprimée au départ sous forme de texte. L'AST, produit en sortie du Parser, permet en effet de donner un sens à la requête d'origine, et de l'exploiter plus facilement grâce à sa structure d'arbre.
Maintenant que nous sommes capables de donner un sens à cette requête au travers du code, nous allons devoir déterminer quelle est la meilleure façon de l'exécuter. C'est là qu'interviennent successivement le Logical Plan (ou plan d'exécution logique) et le Physical Plan (ou plan d'exécution physique).
Plan d'exécution logique
Il s'agit d'un arbre (oui, encore un) qui modélise l'ensemble des opérations ensemblistes nécessaires pour exécuter la requête SQL. La Projection, le Filtre, la Jointure sont des exemples d'opérations ensemblistes qui peuvent faire partie du plan d'exécution logique.
En clair, le plan d'exécution logique décrit l'ensemble des étapes nécessaires pour exécuter une requête.
Plan d'exécution physique
Le plan d'exécution physique décrit la manière dont ces opérations ensemblistes vont être réalisées. Il se distingue en cela du plan d'exécution logique qui, lui, ne décrit que de façon abstraite les opérations à effectuer.
Concrètement, le plan d'exécution physique comprend l'ensemble du code qui va être utilisé pour exécuter une requête SQL.
Un Join peut p. ex. être réalisé par :
- Un Hash Join (on va indexer dans une map toutes les valeurs de l'une des deux tables, et itérer sur la seconde en réalisant un lookup dans la map créée auparavant) : cet algorithme est efficace lorsque l'une des deux tables est suffisamment petite pour être indexée en mémoire. Dans Spark, on part alors plus spécifiquement de Broadcast Hash Join.
- Ou bien un Nested Loop Join (on va réaliser deux boucles imbriquées avec une comparaison à chaque sous-itération) : cet algorithme est applicable quelle que soit la taille des tables en jeu, mais nécessite de re-parcourir les tables à chaque fois (sauf si elles sont mises en cache, et l'on parle alors de Block Nested Loop)
Ces deux types de Join ne sont pas exhaustifs et sont plutôt les représentants simplistes de deux familles : il existe en effet de nombreuses autres implémentations qui reposent sur des optimisations de l'un ou l'autre des algorithmes (p. ex. le Sort-Merge Join est semblable au Nested Loop Join mais est plus rapide sur des tables déjà triées par leurs clés de jointure).
L'étape qui va permettre de passer du plan d'exécution logique au plan d'exécution physique correspond à ce que l'on appelle la planification : c'est lors de cette étape que vont être mis en relation le modèle logique de données et le modèle physique. Sur la plupart des SGBDR, il est possible de récupérer ce plan d'exécution en utilisant les commandes EXPLAIN ou EXPLAIN PLAN.
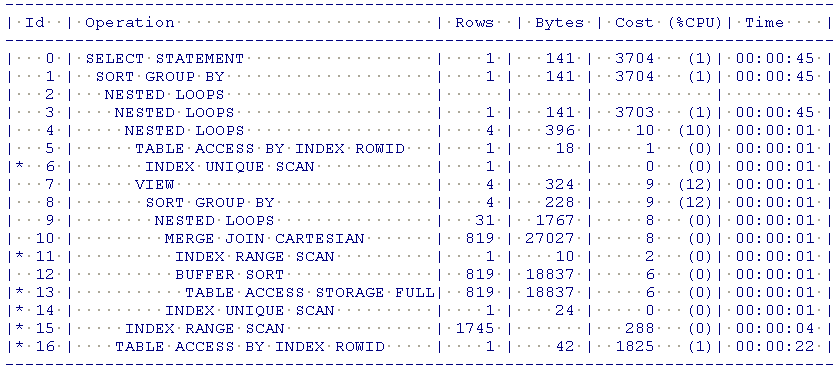
Durant l'étape de planification, nous avons quasiment une relation 1-pour-1 entre le Logical Plan et le Physical Plan, et c'est lors de l'étape d'optimisation que le Physical Plan sera susceptible d'évoluer pour obtenir de meilleures performances lorsque notre requête sera exécutée…
Optimisations
Les optimisations correspondent à un ensemble de transformations que l'on va appliquer à nos plans d'exécution logiques et physiques de manière à accélérer la requête. C'est en appliquant des optimisations sur nos différents plans d'exécution que l'on comprend tout l'intérêt de distinguer l'aspect logique de l'aspect physique :
- Dans le cas d'un plan d'exécution logique, les optimisations ne vont être qu'ensemblistes ou bien réalisées sur les Expressions. Il s'agit d'optimisations génériques pour lesquels peu (voire pas) d'informations sur la donnée sont nécessaires. P. ex., sans connaissance préalable du contexte, on sait qu'il est intéressant de regrouper plusieurs filtres successifs en un seul, ou bien évaluer des constantes, factoriser des termes…
- Dans le cas du plan d'exécution physique, les optimisations vont être réalisées sur la manière dont on accède aux données (p. ex. déporter un filtre directement dans la base de données source quand c'est intéressant, on parle alors de Predicate Pushdown) ainsi que sur la manière dont les relations vont être réalisées en fonction des métadonnées des tables en jeu (les stats d'Oracle, ça vous rappelle quelque-chose ?)
Notre implémentation !
Petit focus sur le trait TreeNode
Avant de rentrer dans le détail en tant que tel, nous allons commencer par décrire le trait TreeNode défini dans le fichier TreeNode.scala, qui va nous servir de structure de base à plusieurs reprises.
Ce trait modélise une structure en arbre habituelle : chaque instance de type TreeNode peut faire référence entre 0 et plusieurs fils eux aussi de type TreeNode. Cependant, deux propriétés rendent ce trait vraiment intéressant :
- Chaque instance d'une classe implémentant
TreeNodedoit être immutable (et ne peut donc pas être altérée) - Tout comme une instance de
Seqpeut être transformée à l'aide de la méthodemap(), une instance d'une classe implémentantTreeNodepeut-être transformée à l'aide de la la méthodetransformDown()pour modifier l'ensemble des enfants de l'arbre - Le trait
TreeNodepossède une annotation self-type du type qui va l'implémenter (ce qui va nous permettre d'utiliser ce trait de manière totalement transparente dans notre code, sans jamais le référencer)
Nous pouvons p. ex. voir dans le fichier TreeSpec.scala qu'il est possible de décrire la règle de factorisation d'entier et l'appliquer sur une expression quelconque en quelques lignes seulement :
expression.transformDown { case Add(Multiply(a, b), Multiply(c, d)) => (a, b, c, d) match { case _ if a == c => Multiply(a, Add(b, d)) case _ if a == d => Multiply(a, Add(b, c)) case _ if b == c => Multiply(b, Add(a, d)) case _ if b == d => Multiply(b, Add(a, c)) } }
On traverse notre arbre d'expressions, et chaque fois qu'un noeud correspond à la forme Add(Multiply, Multiply), on applique notre factorisation. Les autres noeuds restent inchangés ! Notons que l'on s'appuie fortement sur la notion de PartialFunction de Scala.
Dans la suite de cet article, nous allons voir que de nombreux concepts reposent sur des structures de données en arbre. C'est pourquoi ce trait TreeNode est central dans notre implémentation, car bon nombre de nos classes vont s'appuyer dessus.
Les classes LogicalPlan, PhysicalPlan et QueryPlanner
Tout comme Spark, nous nous reposons fortement sur les case classes et la notion de Pattern Matching pour convertir notre AST de départ en une instance de LogicalPlan.
Le trait LogicalPlan
Ce trait LogicalPlan et l'ensemble de ses implémentations est défini au sein du fichier LogicalPlan.scala. Il est intéressant de noter que ce trait étend TreeNode (et correspond donc à une structure en arbre) mais n'impose l'implémentation d'aucune méthode : il ne s'agit en effet que d'une représentation sémantique de notre requête SQL. La structure d'arbre est quant à elle utile pour effectuer facilement des transformations qui vont servir à optimiser le plan logique d'exécution.
trait LogicalPlan extends TreeNode[LogicalPlan]
C'est la méthode apply de notre companion object LogicalPlan qui va être en charge de transformer notre instance d'AST, obtenu en sortie du parsing, en une instance de LogicalPlan. Ou plus précisément en un Try[LogicalPlan] car la conversion peut échouer si notre AST n'est pas valide.
C'est lui qui fait le lien entre la sémantique de notre requête SQL et sa représentation en termes d'opérateurs. Il devient ainsi possible de raisonner d'un point de vue purement logique au moment d'optimiser notre requête.
La classe LogicalPlanOptimizer.scala a pour but de rassembler l'ensemble de ces règles d'optimisation (qui sont encore en cours de développement).
Le trait PhysicalPlan
Le trait PhysicalPlan et l'ensemble de ses implémentations sont présents au sein du fichier PhysicalPlan.scala. Le trait est relativement semblable à celui défini ci-dessus, hormis qu'il est cette fois nécessaire d'implémenter la méthode execute() qui doit retourner un Iterator[InternalRow]. Elle sera appelée lors de l'exécution effective de notre requête. Nous parlerons plus en détail de cette méthode par la suite.
trait PhysicalPlan extends TreeNode[PhysicalPlan] { def execute() : Iterator[InternalRow] }
Notons à titre d'exemple la classe CSVFileScan qui va lire des lignes d'un fichier CSV et les retourner sous forme d'InternalRow : c'est grâce à cette classe que nous allons pouvoir utiliser des fichiers .csv comme tables.
Les optimisations du plan d'exécution physique sont listées dans PhysicalPlanOptimizer.scala et définies dans package.scala. C'est justement au sein de ces règles d'optimisation que l'on se rend compte de la puissance du trait TreeNode associé au Pattern Matching de Scala.
La classe QueryPlanner
La conversion entre le LogicalPlan et le PhysicalPlan est réalisée à l'aide du QueryPlanner à cet endroit défini dans le fichier QueryPlanner.scala.
Du côté de chez Spark
Le mécanisme que nous avons mis en place est vraiment très similaire à celui que Spark propose au sein de son moteur d'optimisation Catalyst. Les plans logiques et physiques sont représentés par des arbres sur lesquels des optimisations peuvent être effectuées.
De même, les Expressions sont traités comme des arbres à part entière (qui implémentent donc la classe TreeNode). Pour simplifier, les Expressions correspondent aux opérations appliquées sur les colonnes notamment pour les Projections ou les Filters.
P. ex. pour la requête :
SELECT 2 * (longueur + 1) FROM rectangles, le terme2 * (longueur + 1)correspond à uneExpressionqui peut être représentée sous la forme suivanteMultiply(Constant(2), Add(Literal("longueur"), Constant(1))).L'avantage, encore une fois, est que l'on peut appliquer facilement des optimisations sur les
Expressions en effectuant des opérations sur les arbres.
Dans Spark, les optimisations s'appliquent donc à la fois aux opérateurs et aux Expressions. C'est la classe Optimizer définie dans Optimizer.scala qui répertorie l'ensemble des optimisations et qui sert de classe de base du SparkOptimizer (c'est ici que l'on trouve l'ensemble des règles appliquées !).
La classe SparkPlan correspond à la classe de base des classes Exec qui correspondent à nos PhysicalPlan est définie dans le fichier SparkPlan.scala.
Enfin, le fichier SparkStrategies.scala contient l'ensemble des stratégies qui permettent de passer d'un plan d'exécution logique à un plan d'exécution physique (les classes Exec) en se basant sur le QueryPlanner et (avec comme implémentation le SparkPlanner, les stratégies utilisées sont d'ailleurs déclarées au sein de ce dernier).
Pour aller plus loin…
User Defined Fonctions et optimisations
Comme beaucoup de moteurs SQL, Spark offre la possibilité de définir ses propres fonctions à appliquer dans des requêtes SQL : les User Defined Fonctions ou UDF. En pratique, lorsqu'on définit une UDF cela correspond à créer une nouvelle implémentation de l'interface Expression, comme le montre la classe ScalaUDF. La fonction définie par l'utilisateur sert alors d'implémentation à la méthode eval du trait Expression.
De ce fait, les UDF offrent une grande souplesse pour le développeur qui peut utiliser n'importe quel code Scala au sein de sa requête SQL. Néanmoins, cette liberté a un coût puisque le moteur Catalyst n'est plus capable de comprendre le contenu de l'Expression et d'appliquer des optimisations dessus : une UDF est perçue par Spark comme une boîte noire. Il est donc important de les utiliser avec parcimonie pour éviter des problèmes de performances (voir Performance Considerations).
Néanmoins, depuis Spark 2.0, il est possible d'implémenter ses propres règles d'optimisation et ainsi tenir compte de ses propres UDF (dont seul l'utilisateur connait le contenu).
Apache Calcite… Le retour !
Nous avons déjà mentionné Apache Calcite dans le premier article de cette série étant donné que ce framework permet de résoudre de manière générale les problématiques inhérentes au parsing SQL…
Il se trouve que Calcite possède également son propre moteur d'optimisation (qui est, lui aussi, utilisé par Hive).
Cost Based Optimizer
Jusqu'à la version 2.2 de Spark, l'optimisation des plans d'exécution se basait uniquement sur des règles indépendantes des données elles-mêmes, et ignorait certaines informations comme :
- La cardinalité des lignes qui vont être vont être produites par un plan d'exécution (p. ex., pour le produit cartésien va produire N × M lignes si le premier fils produit N lignes et le seconds fils M lignes)
- La manière dont les données sont distribuées (p. ex., combien y a-t-il d'éléments distincts)
En fonction de ces informations supplémentaires, il peut être intéressant d'optimiser différemment le plan d'exécution : plus le contexte de la requête exécutée est connu, plus l'optimisation sera pertinente. On parle alors de Cost Based Optimization.
Ces notions doivent rappeler des souvenirs aux utilisateurs de SGBDR… On retrouve en effet ici les fameuses statistiques qui ont causé du fil à retordre à nos DBA préférés.
Depuis Spark 2.2, on voit apparaître dans le code des fonctionnalités relatives à ces statistiques (on peut p. ex. voir dans Statistics.scala la manière dont elle sont stockées et elle seront a priori exploitées dans QueryExecution.scala qui pour l'instant prend le premier plan d'exécution physique).
Execution
Toujours en partant de notre requête SQL sous forme de String, nous avons à présent un PhysicalPlan qui décrit de manière exhaustive ce qui doit être réalisé pour obtenir un résultat… Il n'y a donc plus qu'à exécuter la requête ! Et c'est pour cela que nous allons implémenter la fameuse méthode execute()…
Un peu de théorie
La notion de Volcano Model
Le plan d'exécution physique modélise le parcours de chaque tuple d'origine (qui est issu d'une table) pour aboutir (ou non, p. ex. s'il est filtré au niveau d'une clause WHERE) au résultat de la requête.
Depuis plus d'une vingtaine d'année, la manière dont les plans d'exécution physique sont executés repose sur la notion de Volcano Model, dont les bases ont été théorisées au sein de ce papier (qui date de 1994 !). Oracle, PostgreSQL, etc. reposent en grande partie sur cette notion.
Le Volcano Model se base sur trois principes :
- Faire correspondre à chacune des étapes du plan d'exécution logique une étape du plan d'exécution physique
- Le deuxième principe repose sur le fait que toutes les étapes du plan d'exécution physique sont chaînées (chaque étape mère est associée à une ou plusieurs étapes filles) : à chaque étape correspond donc un opérateur
- Enfin, étant donné que l'objectif du plan d'exécution physique est d'évaluer la requête, le troisième principe spécifie que l'on va laisser le parent contrôler le flux des tuples qui vont naviguer d'un opérateur à l'autre en demandant aux enfants les tuples un par un
Il est intéressant de noter que le Volcano Model repose sur le principe de pull de la donnée : le parent demande aux enfants le prochain tuple à traiter.
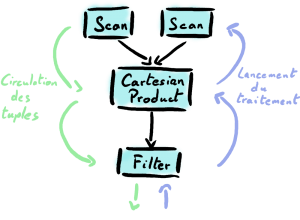
L'exemple ci-dessus modélise donc un filtre Filter appliqué sur le produit cartésien Cartesian Product de deux sources de données Scan : pour peu que ce filtre permette de faire le lien entre nos deux sources de données, nous avons ici l'exemple d'une jointure naïve réalisée avec la combinaison de 3 opérateurs !
Notre implémentation !
Nos types de base
Nous allons commencer par définir le type InternalRow qui va correspondre à une ligne. Une ligne est composée de colonnes de type InternalColumn (qui peut être issu d'une table identifiée par son nom de type RelationName ou d'une expression) identifiée par un nom de type ColumnName et à chaque colonne correspond une valeur de type Any.
De ce fait :
type Name = String type ColumnName = Name type RelationName = Name type InternalColumn = (Option[RelationName], ColumnName) type InternalRow = Map[InternalColumn, Any]
La méthode execute()
L'idée générale
Le passage d'une instance de LogicalPlan vers une instance de PhysicalPlan a été effectué à l'aide du QueryPlanner dont nous avons parlé ci-dessus. Nous n'avons par contre pas parlé de l'objectif de la méthode execute() de notre trait PhysicalPlan qui doit être définie au sein des implémentations.
Le contrat établi par les opérateurs du Volcano Model ressemble beaucoup à celui rempli par l'interface Iterator de Scala… En effet, chaque opérateur va récupérer 1 par 1 les tuples qu'il va traiter. Eh bien capitalisons là-dessus en imposant à cette méthode execute()de retourner un Iterator[InternalRow].
Pour rappel :
trait Iterator[E] {
def next(): E
def hasNext: Boolean
}
Implémentation du Filter
On a notre base de travail : notre trait est défini. On peut maintenant implémenter un Filter :
case class Filter(child: PhysicalPlan, predicate: Predicate) extends PhysicalPlan {
override def execute(): Iterator[InternalRow] = {
child.execute().filter(predicate.evaluate)
}
}
On constate alors que Filter fait référence à l'opérateur précédent nommé child. En effet, pour chaîner l'ensemble des opérateurs, chacun d'eux va devoir référencer celui qui le précède, comme un arbre. Filter collecte ainsi 1 par 1 les tuples renvoyés par l'opérateur qui le précède et applique sur chacun d'eux un Predicate (i.e. vérifie si une condition est respectée).
Puisque chaque opérateur appelle le précédent, le dernier opérateur à traiter un tuple est celui qui va servir de point d'entrée au traitement : on demande au dernier opérateur de lancer le traitement, qui va alors demander à son (ou ses) enfants de lancer leurs propres traitements et ainsi de suite. On retrouve bien ici le mode pull dont nous parlions précédemment. Ce fonctionnement n'est en fait qu'une conséquence direct de la description de notre plan physique sous forme d'arbre : c'est le noeud racine de l'arbre qui référence tous les autres. Lorsque l'on appelle la méthode execute() sur ce noeud, on appelle execute() sur l'ensemble de ses enfants, et ainsi de suite jusqu'à arriver à la source de données.
Chaque tuple traité doit ainsi traverser chacune des classes de chacun des opérateurs du plan physique. La modularité du modèle vient du fait qu'il est facile de chaîner de nouveaux opérateurs entre eux, et de faire des optimisations notamment en modifiant l'ordre des différents opérateurs.
Démonstration de bout en bout
Du côté de chez Spark…
La classe SparkPlan qui correspond à la classe de base des classes Exec qui correspondent à nos PhysicalPlan est définie au sein de SparkPlan.scala
Il est intéressant de noter que, dans Spark, les RDD sont utilisés, alors notre implémentation se base sur des Iterator, et c'est ça la force de Spark SQL puisque le calcul va être distribué ! L'itérateur est ainsi partagé entre plusieurs machines. Mais ça, ça sera pour un prochain article…
Pour aller plus loin
Predicate Pushdown
Une autre optimisation intéressante que propose Spark en termes de plan d'exécution physique est le fait de pouvoir déléguer certaines opération directement à la source de données : c'est ce que l'on appelle le Predicate Pushdown.
Typiquement, si les données d'un DataFrame sont issues d'une base de données, il est possible d'effectuer le filtre directement au niveau de la base de données et de ne renvoyer à Spark que les données qui ont pu valider ce premier filtre. La quantité de données à transférer est donc réduite.
RDD vs Dataframe vs Dataset
Maintenant que nous voyons à quoi ressemblent les mécanismes sous-jacents à l'exécution d'une requête dans Spark, faisons un point sur les 3 structures proposées par le framework pour manipuler des données.
A noter que depuis Spark 2.0, le Dataframe n'est qu'un sous-cas non typé du Dataset. La plupart des optimisations appliquées à l'un sont donc applicables à l'autre.
Le gros intérêt d'utiliser les Dataset ou Dataframe est de profiter de toutes les optimisations décrites dans cet article. La requête SQL décrit le besoin de l'utilisateur et le rôle du moteur d'optimisation Catalyst est de trouver le moyen le plus rapide d'apporter la réponse à ce besoin.
Une nouvelle problématique survient lorsque l'utilisateur décide d'utiliser ses propres fonction en passant p. ex. par l'opérateur map() sur une instance d'un DataFrame. Dans ce cas là, on sort du contexte SQL et le code est perçu comme une boîte noire par Catalyst : c'est l'utilisateur qui décrit la solution technique au lieu d'exprimer un besoin.
Jusqu'à la version 1.5 de Spark, la méthode map(), appliquée à un DataFrame renvoyait un RDD car le contenu de l'itérateur ne correspond plus à un tuple classique (une Row), mais à objet Java ou Scala. L'utilisateur prenait alors la responsabilité d'apporter une solution technique performante, car Catalyst n'était plus en mesure de fournir ses optimisations.
A partir de la version 1.6, et avec l'arrivée des Dataset, il devient possible d'avoir un itérateur d'objets Java ou Scala (le DataFrame n'est alors plus qu'un Dataset[Row]). La méthode map() permet ainsi de renvoyer un DataSet à partir d'un autre DataSet. La méthode map() est alors interprétée comme un opérateur du LogicalPlan. Néanmoins, son contenu reste inconnu à Catalyst. Chaque tuple doit ainsi être désérialisé puis resérialisé pour pouvoir travailler sur la donnée.
Une piste d'amélioration envisagée pour les versions futures de Spark consiste à interpréter le contenu de la fonction passée en paramètre de la méthode map() en étudiant directement le bytecode qui le constitue, c'est-à-dire en regardant comment la fonction est compilé par le compilateur Java ou Scala.
L'objectif final serait de vérifier automatiquement s'il est possible de traduire cette fonction en une succession d'opérateurs SQL classiques : on veut traduire la boîte noire en opérateurs interprétables (et donc optimisables) par Catalyst.
Les travaux actuels sur le sujet s'appuient sur Javassist pour étudier le bytecode de la fonction. La logique est essentiellement présente dans le fichier ClosureToExpressionConverter.scala.
A suivre…
Nous avons vu que le Volcano Model est une notion qui n'est pas propre à Spark en tant que tel : de nombreux SGBDR tel que Postgres, MySQL ou même Oracle s'appuient sur ce modèle.
La grosse amélioration apportée par Spark 2.x repose sur le fait qu'il est possible, dans certains cas, de sortir de ce modèle standard pour directement générer le code qui va permettre d'exécuter la requête SQL, et ainsi gagner en performance… Mais ça, c'est pour la suite !