MythBuster: Apache Spark • Épisode 3: Génération de code à la volée
A la fin de l’épisode précédent, nous étions capables d’exécuter une requête SQL à partir d’un plan d'exécution optimisé. Ce fut notamment l’occasion de plonger au coeur du moteur d’optimisation Catalyst.
Nous allons à présent nous intéresser à une optimisation issue du moteur Tungsten, embarquée dans Spark dès la version 2.0, qui remet en cause ce Volcano Model, pourtant standard sur la plupart des SGBDR…
Pour rappel, dans l'épisode précédent, nous sommes partis d’un AST correspondant à une requête SQL, et nous avons construit un PhysicalPlan décrivant une façon d'exécuter cette requête.
Ce PhysicalPlan possède une méthode def execute() qui va retourner un Iterator[Row] qui sera retourné lors de l'exécution effective de la requête. L’implémentation de cette méthode s’appuie sur le principe du Volcano Model qui est lui même rendu possible grâce à la structure en arbre du PhysicalPlan.
Voyons comment la génération de code peut encore améliorer les performances d'exécution de notre PhysicalPlan…
L’ensemble du code décrit dans cet article est accessible dans ce dépôt GIT et constitue une implémentation extrêment simplifiée du moteur Catalyst, dans un but purement didactique.
Génération de code
Principe général
Jusqu’ici, chaque opérateur physique (SELECT, FILTER, JOIN…) était représenté par une instance d’une classe Scala : ceci est une conséquence directe des principes imposés par le Volcano Model. Pour reprendre le fonctionnement de Spark 2.x, nous allons maintenant relaxer cette contrainte du modèle Volcano pour optimiser l’exécution de la requête.
En effet, grâce à la génération de code, plusieurs opérateurs pourront être regroupés en un seul opérateur fait sur mesure. Plus précisément, nous allons créer une implémentation de PhysicalPlan dynamiquement (au moment de l’exécution) que nous allons instancier pour constituer un nouveau plan physique. Nous ne serons ainsi plus limités aux opérateurs déjà implémentés dans le framework Spark.
Conceptuellement, cette manipulation consiste à rendre le traitement plus data centric et moins operator centric : on se focalise sur ce qui est le plus performant pour une structure de tuple donnée, et on adapte les opérateurs en fonction.
Un peu de théorie
Principe
L’approche adoptée par les développeurs de Spark est très largement inspirée de ce papier de recherche. Celui-ci explique, entre autres, que les cycles CPU constituent aujourd’hui un goulet d’étranglement pour les moteurs d’exécution, devant le réseau et les accès disques, et propose une méthode de génération de code pour en limiter l’impact.
Nous l’avons vu, l’idée général de cette méthode va être de regrouper plusieurs opérateurs qui constituent le plan d’exécution physique en un seul et unique opérateur spécifique à notre besoin.
Il y a plusieurs avantages à cela :
- Etant donné que chacun des opérateurs en jeu est une implémentation concrète du trait
PhysicalPlan, la multiplication de ces implémentations et des appels à des fonctions virtuelles peut avoir un coût sur les temps d'exécution au niveau de la JVM (voir ci-dessous) ; - Le code de notre unique opérateur va être structuré de manière à ce que les données restent le plus longtemps possible au sein des registres CPU, en évitant notamment d’intercaler des appels à des fonctions virtuelles entre chaque opérateur. On limite alors le Pipeline Breaking : pour un tuple donné, on réalise tous les traitements à la suite lorsque cela est possible.
Puisque notre moteur, tout comme Spark, interprète les requêtes SQL à l'exécution (et non à la compilation), nous allons devoir créer dynamiquement notre nouveau PhysicalPlan à ce moment-là : son code va donc devoir être généré et compilé à la volée.
C’est une forte évolution puisque l’on casse le premier principe imposé par le Volcano Model : un CodeGeneratedStage va correspondre à plusieurs LogicalPlan !
PhysicalPlan et interfaces
Avec le Volcano Model
Rappelez-vous, dans l’épisode précédent lorsque nous avons construit nos différents opérateurs, ceux-ci faisaient référence à leurs enfants en pointant vers d’autres PhysicalPlan. De façon schématique, l’implémentation d’un opérateur ressemble à ceci:
case class MyOperator(child: PhysicalPlan) extends PhysicalPlan { override def next():InternalRow = { child.next() <... some operations ..> } }
En réalité, dans notre implémentation, nous utilisons la méthode
def execute(). Cependant celle-ci renvoie unIteratorqui lui expose la méthodedef next()dans laquelle tous les traitements sur les tuples sont effectués. Par soucis de simplicité, nous parlerons ici uniquement de la méthodedef next().
On constate que lorsque plusieurs opérateurs d’un plan d’exécution physique s’enchaînent, chaque tuple doit passer par une succession d’appels à la fonction virtuelle def next(). L’inconvénient est que, au moment de la compilation, on ne sait pas encore quelle implémentation de def next() utiliser : cela dépend du plan d’exécution, lui-même construit à partir de la requête SQL. Cela rend les optimisations difficiles pour le compilateur Scala/Java, et même pour le compilateur JIT de la JVM.
Les traitements effectués par nos opérateurs sont ainsi entrecoupés d’un appel à une fonction virtuelle. Ces fonctions induisent un surcoût car la JVM doit déterminer à chaque fois quelle implémentation utiliser, mais surtout parce que les traitements ne peuvent pas se faire directement les uns à la suite des autres et profiter des caches processeurs. On parle alors de Pipeline Breaker.
Pour des benchmarks plus détaillés, cet article décrit bien le fonctionnement des fonctions virtuelles en Java. Un autre benchmark relativement accessible est décrit dans celui-ci. Pour une vision plus bas niveau, voir ici ou ici.
Avec génération de code
Au moment de l’exécution, on connaît enfin le PhysicalPlan que l’on va utiliser, ainsi que toutes les implémentations de def next() dont nous avons besoin. On peut donc générer du code en remplaçant les appels à def next() directement par leur contenu. On crée un nouveau PhysicalPlan dont la fonction def next() regroupe celles de plusieurs PhysicalPlan. On obtient ainsi, à l’exécution, un code plus explicite, plus facile à optimiser que le code générique initialement compilé.
Tout ceci revient en fait à inliner nos appels à la fonction def next() à la place du compilateur lorsque celui-ci ne parvient pas toujours à le faire tout seul.
La requête SQL de départ est en fin de compte compilée et non plus réinterprétée à chaque tuple. Le modèle Volcano est en effet une implémentation d'interpréteur SQL qui permet de structurer un plan d’exécution physique. Avec, la génération de code nous profitons de la souplesse du modèle Volcano tout en préservant les performances d’un code écrit à la main.
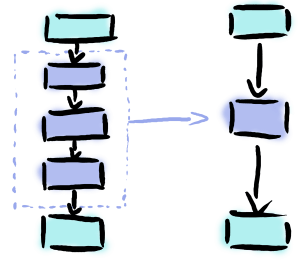
Bien évidemment, dans la plupart des applications Java ou Scala, les interfaces ont un impact négligeable sur les performances. Dans le cas de Spark, chaque tuple doit parcourir un ensemble d’interfaces réalisant chacune une part du traitement total. L’utilisation de ces interfaces fait que l’on perd entre chaque partie du traitement le résultat précédent des registres processeur. C’est cela qui est coûteux, notamment lorsque l’on doit traiter des millions, voire des milliards de tuples…
Notre implémentation
Génération de code
Le principe est simple : puisque le PhysicalPlan dérive de TreeNode (et a donc une structure en arbre), il est possible d’ajouter des opérateurs à n’importe quel endroit du plan physique.
Nous allons donc intégrer un nouvel opérateur à la racine du plan physique pour indiquer à l’optimiseur de générer du code à partir de cet endroit-là. On obtient le plan physique suivant : JavaCodeGenerationStage(Filter(Projection(CSVScan))). Cet opérateur ne réalise aucune opération directement sur les tuples, il s’agit simplement d’une étape intermédiaire à la construction du plan physique final.
A partir de là, le JavaCodeGenerationStage va demander à son fils (le Filter) de générer du code, qui va lui même demander cela à Projection, etc. Chaque opérateur génère alors une String correspondant à du code Java réalisant l’opération souhaitée par cet opérateur. Par exemple, prenons la requête SQL suivante :
SELECT my_projected_column FROM my_table WHERE my_column = 2
Nous avons alors 3 opérateurs : un Filtre, une Projection et un Scan.Dans ce cas là, le Filter va générer un code semblable à ce qui suit :
if(!row.getColumn('my_column').equals('2')) { skipRow(); } else { <... code généré par les autres opérateurs ...> }
La projection va, elle, générer par exemple :
row = row.keepColumns('my_projected_column')
L’opérateur CSVScan ne supporte pas la génération de code : on va donc devoir l'encapsuler avec un InputAdapter pour faire le lien entre les opérateurs classiques (i.e qui suivent le Volcano Model) et les opérateurs dont le code est généré et compilé à la volée.
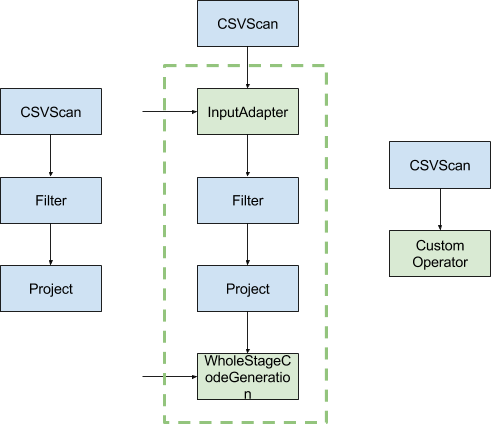
On obtient alors, dans une seule fonction def next(), l’ensemble du code qui va être appliqué à chacun des tuples.
La compilation du code
Comment transformer cette String en du code utilisable ?
Dans notre implémentation nous avons choisi un fonctionnement simple qui permet de comprendre l’ensemble des mécanismes :
- Une fois la totalité du code Java généré sous forme de
String, nous écrivons ce contenu dans un fichier texte avec une extension.java - Nous appelons alors depuis notre code, le compilateur
javacen tant que processus externe (pour cela nous appelons simplement la classeProcessBuilderqui permet d’exécuter des commandes comme si nous étions dans un terminal classique) - Le fichier
.javaest ainsi compilé dans un nouveau fichier avec l’extension.classcomme n’importe quel fichier java compilé - Ensuite, nous construisons un
ClassLoaderen lui indiquant le chemin vers le dossier temporaire contenant le fichier java compilé - Nous appelons la méthode
loadClass('nomDeLaClassGénérée')afin que leClassLoadercharge contenu du fichier.classet donne accès à notre nouvelle classe fraîchement compilée - Enfin, il ne reste plus qu’à appeler le constructeur de notre classe taillée sur mesure pour en récupérer une instance
Nous obtenu ainsi un PhysicalPlan capable de s’intégrer parfaitement à notre modèle Volcano.
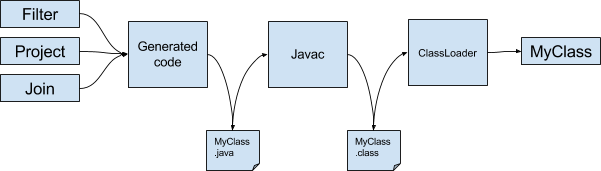
L’implémentation de ces étapes est présent au sein du fichier JavacJavaClassCompiler.scala.
Exemple
Jeu de données
Jusqu’ici, nous n’avons utilisé que des tables de très faible volumétrie pour tester notre prototype de moteur SQL : au mieux, il n’y avait qu’une petite dizaine de lignes. Pour cet article, nous allons avoir besoin de réaliser des tests avec des tables dont la volumétrie est beaucoup plus importante.
Pour cela, quoi de mieux que l’Open Data ? Grâce aux données fournies par à la RATP et la Mairie de Paris, nous allons baser nos tests sur :
- Le fichier validations.csv qui contient les données relatives au nombre de validations dans chacune des stations RATP
- Le fichier pedestrians_in_nation.csv qui contient les données relatives aux flux piétonnier à la Place de la Nation
Ces fichiers (qui vont donc nous servir de table) vont nous permettre de réaliser la requête SQL suivante :
SELECT p.pedestrian_count, v.validation_count FROM pedestrians_in_nation p JOIN validations v ON p.day = v.day WHERE v.subway_station_name = 'NATION' AND v.validation_type = 'NAVIGO' AND p.day = '2016-12-25'
Démonstration
Benchmark
Toujours en nous basant sur la requête et le jeu de données décrits ci-dessus, nous avons réalisé un benchmark de comparaison de l'exécution du code avec et sans la génération de code, en augmentant progressivement le nombre de lignes dans chacune des tables.
Le détail du benchmark est présent dans le fichier CodeGenerationBench.scala.
Du côté de chez Spark
Dans le code de Spark, la mécanique est assez proche, mais tout le processus de compilation du code source et de récupération de la classe compilée est délégué à la librairie Janino qui a l’avantage d’être plus rapide que l’appel au compilateur Java classique car elle réalise toutes les opérations en mémoire (pas besoin d’écrire le fichier source dans un fichier temporaire en amont).
La règle définissant la génération de code dans Spark est définie dans la classe CollapseCodegenStages à partir de la méthode def apply(). Celle-ci prend un plan physique (un SparkPlan) en entrée et renvoie un nouveau plan physique en sortie, en ajoutant aux endroits adéquats l’étape de génération de code via la classe WholeStageCodegenExec. On peut retrouver certains opérateurs ici : basicPhysicalOperators.scala.
Pour un dataset donné myDS, il est facile de visualiser le code généré par une requête SQL via la commande myDS.queryExecution.debug.codegen().
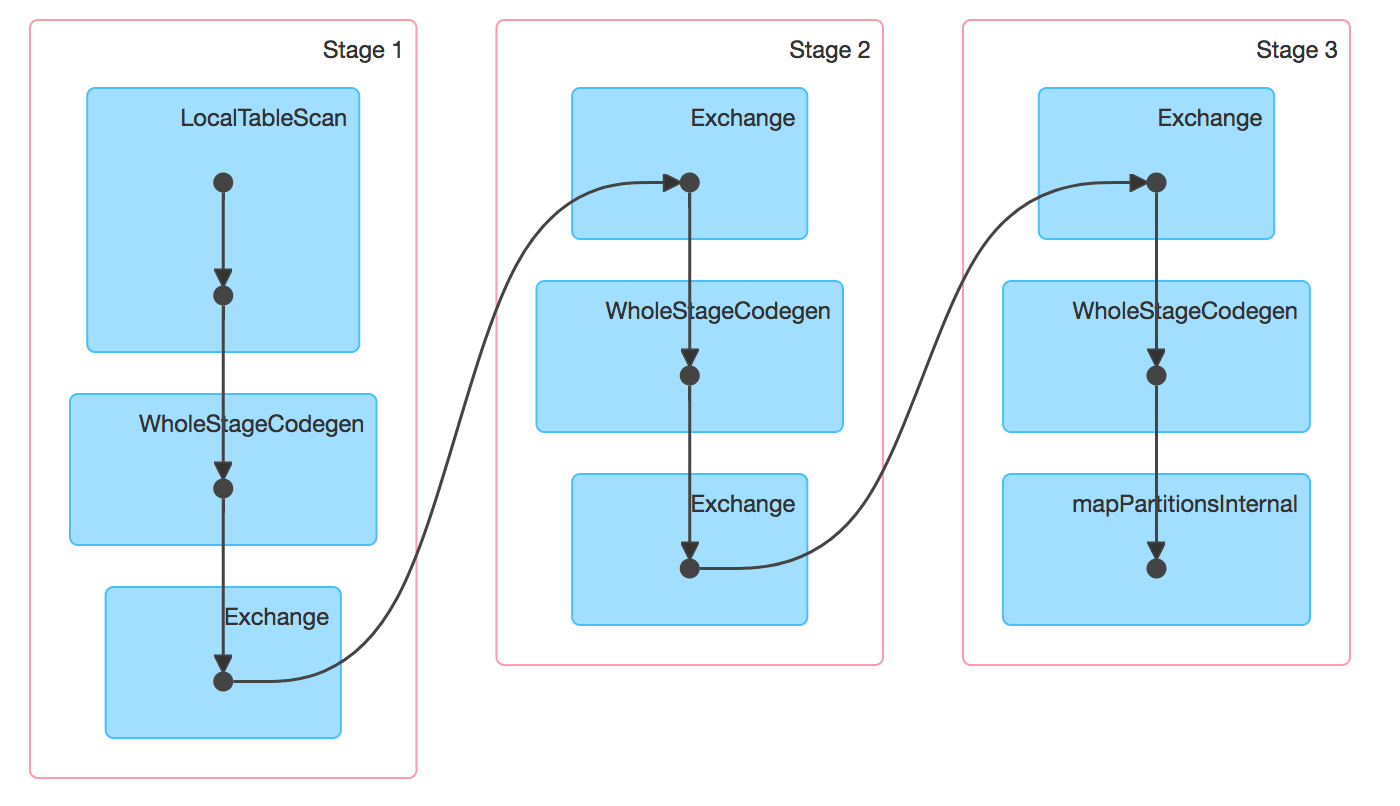
Dans la console Spark, on peut également observer les stages dans lesquels de la génération de code a lieu en visualisant le DAG d’exécution du job :
Pour aller plus loin
Organisation du code généré
L’inconvénient d’écrire le code source sous forme de String et de compiler le tout au runtime est que les éventuels erreurs de compilation ne se voient qu’à l’exécution. C’est pourquoi Spark organise son code généré autour d’un CodegenContext qui préserve, par exemple, le nom des différentes variables instanciées. On pourra notamment faire appel à une même variable dans plusieurs morceaux de code généré.
C’est aussi via le CodegenContext que l’on peut déclarer les opérations à effectuer dans la méthode init(...), et ainsi utiliser des objets fournis depuis l’extérieur de la classe générée. Par exemple, pour réaliser un Broadcast Hash Join, notre PhysicalPlan va devoir exploiter une HashMap fournie par une des deux branches de l’arbre d’exécution.
Pour cela, la méthode init(Object[] references) prend en argument un tableau d’objets dont chacun des éléments constitue la valeur des attributs duPhysicalPlan généré. C’est le CodegenContext qui va maintenir un index du contenu de ce tableau et faire le lien entre les attributs et leurs valeurs.
Cas de User Defined Functions
Nous avons expliqué dans l’épisode précédent que les UDFs Spark sont des implémentations de la classe Expression dont la méthode def eval() est définie par l’utilisateur. Nous avons ainsi vu que les UDFs sont perçues par le moteur d’optimisation Catalyst comme des boîtes noires, difficiles à optimiser.
Cette problématique revient également lors de la génération de code. Par exemple, pour générer le code correspondant à une Projection, il est également nécessaire de générer le code des différentes Expressions portées par l’opérateur. Dans le cas des UDFs, il est difficile de générer le code Java correspondant de façon performante.
Une astuce consiste à écrire soit même l’implémentation de la méthode doCodeGen() de l’Expression correspondant à notre UDF, en écrivant dans une String l’équivalent Java de ce qui est réalisée par l’UDF. L'opération est possible et succinctement décrite ici, mais elle reste déconseillée, à moins de bien maîtriser le fonctionnement de la génération de code.
Conclusion
Spark est loin d’être le seul outil de l'écosystème Big Data qui s’appuie sur la génération de code pour optimiser ses traitements (Impala s’appuie par exemple sur LLVM pour compiler le code correspondant à une requête SQL). Plus généralement, la technique de génération de code pour accélérer le processing de données est héritée de nombreux ETL existants (Talend va générer du code Java, ODI va générer du code PL/SQL, DataStage du code C, etc.).
La génération de code est l’une des techniques mises en oeuvre au sein du projet Tungsten, mais ça n’est pas la seule : Spark utilise par exemple à présent un stockage en mémoire orienté colonne qui permet l’utilisation du Column Pruning qui accélère également les traitements sur de grosses volumétries (voir également la présentation de Databricks sur le sujet).
Ce sont ces différentes évolutions techniques, portées par une communauté grandissante, qui font de Spark l’un des outils les plus performants du moment, tout en maintenant un niveau d’abstraction de manipulation de la données élevé (langage SQL, DataFrame, etc.) qui permet au développeur de se concentrer sur des problématiques métier avant tout.
En dehors des développements core, Spark fait aujourd’hui aussi l’objet de nombreuses recherches d’optimisations bas niveau voire hardware par la communauté, en témoignent les différentes présentations sur le sujet au cours du Spark Summit du 24-26 Octobre 2017 : pour l’utilisation de hardwares spécifiques voir ici et là, et voir cette présentation pour une approche zero-copy des shuffles dans Spark.