My reading of Percolator architecture: a Google search engine component
In April 2010, Google updated its indexing system. Caffeine - the name of this project - was pretty transparent for the large public but represents an in depth change for Google. It does not directly improve the search page, like instant search, but the indexing mechanism, the way to provide pertinent search results. For the end user, this change allows reducing the delay between when a page is founded and when it is made available in the Google search. Google has recently published a research paper about Percolator, one of the backend systems that subtend Caffeine. Research papers that described the previous system were written on Map/Reduce and Google File System. These two papers became the foundation for Hadoop on which I have written some articles. Therefore I was excited to discover this new architecture. After reading it, I decided to write out this article to give you, not just a summary in itself, but my understanding of this new architecture.
The way to build it
Google designs and builds tools for its particular needs. Percolator is used in building the index - which links keywords and URLs - used to answer searches on the Google page. Percolator goals are therefore particularly clearly defined: being able to reduce the delay between page crawling (the first time the page is browsed by Google) and its availability in the repository for query. Technically speaking, the previous system, based on Map/Reduce, used a batch approach. When some new pages are added, the whole repository (or a large part of it) is re-processed in order to change in a coherent way all the pages in the repository impacted by the addition (e.g. a link from a new page points to an existing page increasing its page rank). By contrast, Percolator should run on the fly: newly crawled pages should be available in the index straight away. Technically it involves:
- To be able to process incrementally the indexing pipeline for each new page individually
- To maintain invariants (e.g. links pointing on a page) during concurrent processing
Relational databases are valid tools for such needs but do not satisfy Google's size constraint. The important point I want to highlight is that Google did not just tune a relational database; they removed some requirements like the latency. Percolator is only designed for background processing, so tens of seconds of delay are not worthwhile if the sustained throughput is high.
The architecture
Percolator has been designed on top of BigTable. BigTable is a multi-dimensional, sparse, sorted map used in conjunction to the Map/Reduce pattern in the preceding indexing system. BigTable is a multi-dimensional table: each cell -each piece of data- is identified by a row key, a column key and a timestamp. BigTable is building itself on top of the GFS (the Google Distributed File System). Finally it provides atomic read/write on a row basis. Please refer to this research paper for further information.
- Percolator uses an API similar to BigTable. It provides cross-table and cross-row ACID properties, allowing developers to safely reason about the state of the systems by preserving invariants.
- Moreover, Percolator provides a way to add observers - pieces of code that are triggered by modifications.
Hence Percolator is a layered system as described in the first schema. 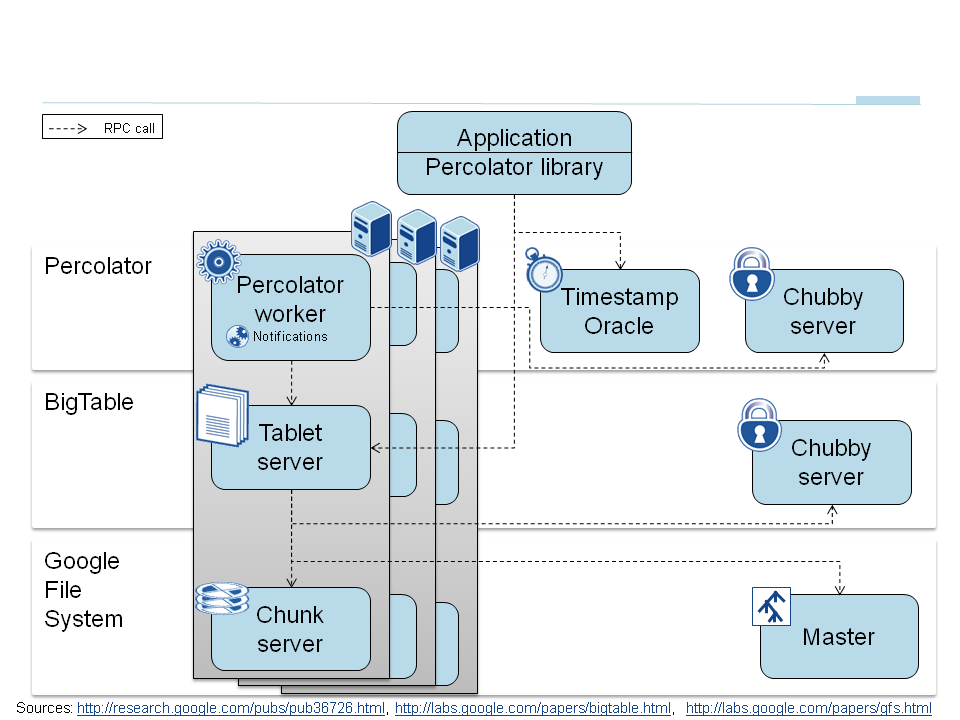
Each Percolator server hosts processes for the Google File System layer, the BigTable layer and finally the Percolator server. Each layer communicates with the underlying one through an RPC call. I will now give you explanations of these views of the two main functionalities of Hadoop.
ACID transactions
- First Percolator uses the atomicity of a row write of BigTable. As BigTable provides a reliable (replicated through GFS) storage with atomic write, it has been chosen as the lock support
- Then Percolator uses the timestamp dimension of BigTable in order to provide snapshot isolation. Snapshot isolation is a transactional isolation level in which previous versions of data are kept in order to give a consistent snapshot of the database to each transaction. It is used in the most famous database (Oracle, SQL Server,
Percolator uses a two phase commit protocol, coordinated by the client, as described in the schema below. 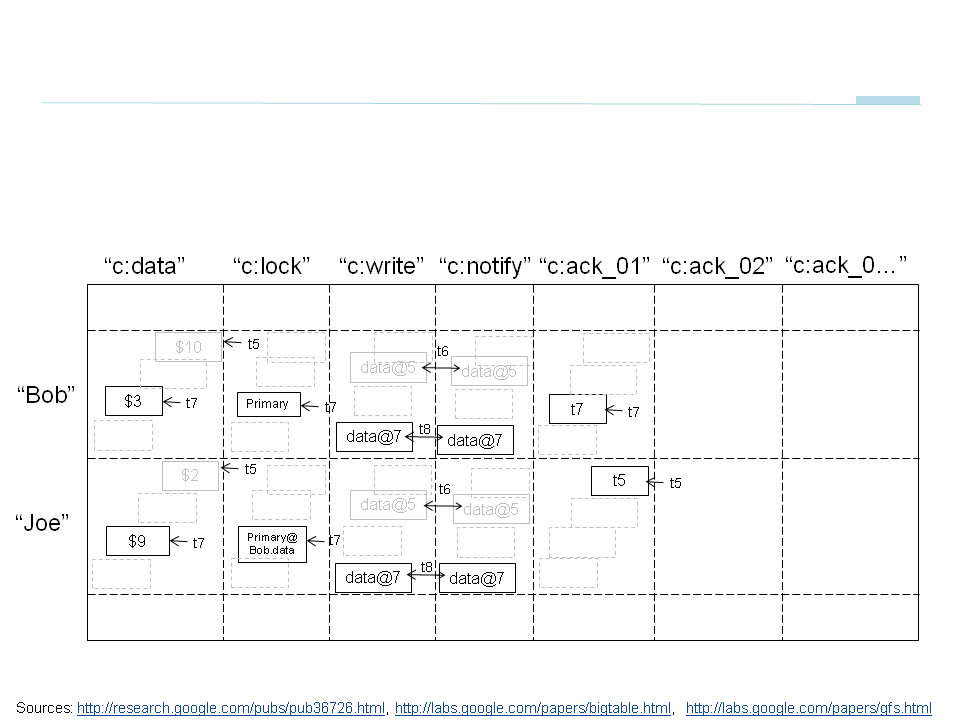
Percolator uses metadata columns in BigTable: for transactions c:data, c:lock and c:write. The high level synopsis for writing it is the following:
- Get a timestamp from the Oracle server (no relation to the RDBMS server, it is a sequence server, like a sequence in a Database). Assume the result is t7
- Write a lock in the
c:lockcolumn of the first row at the given timestamp t7 and data in thec:datacolumn. This is an atomic write. - Write a reference to the first row in the
c:lockcolumn of the second row at the given timestamp t7 and data in thec:datacolumn. This is an atomic write. We have now reached the end of the request phase. - If both writings succeed (no concurrent locks found, no writes after t7), it is equivalent to the end of the Commit Request Phase.
- Get a timestamp from the Oracle server. Assume it is t8
- Write a reference to t7 in the
c:writecolumn of the first row at the t8 timestamp - Write a reference to t7 in the
c:writecolumn of the second row at the t8 timestamp
Correspondingly, a get() request a timestamp, let's say t10 (not on the schema). If it encounters a lock before t10, get() method waits. In the other case it returns the data at t10. Please refer to the research paper to get all details about conflicts and failover details. I prefer to focus on one point: locks are released in a lazy way. In the case of a client failure some locks can remain. To secure transactions, a lock is designed as primary. This is the transitional lock. If a client fails when this lock exists, the transaction should be rolled back: lock and data removed. If it fails after, the transaction must be rolled forward: the second client row should be committed. This process is handled in a lazy way by another client. When a client encounters a blocking lock
- It first checks if the transaction is alive (Chubby is used for this performance improvement. Chubby is a lock service written by Google.) Each transaction writes regularly a timestamp in Chubby in order to show it is alive.;
- Then if the transaction is dead, the previous transaction is rolled back. Whereas if the transaction is still alive the second transaction waits.
Such an approach would not have been acceptable for OLTP scenario, but is the best choice for Google use case. Indeed, the probability of concurrency (as the page URL is the key of the row) is smaller than in an OLTP scenario. The latency is not a problem like in an OLTP scenario. Tests have been made by the teams and increasing the number of concurrent threads allows them to keep a good throughput.
I have learned from this transactional architecture that a good understanding of the needs, of the constraints that can be relaxed and a clear understanding of the consequences of choices are the best means to identify your architecture. XA transactions (distributed transactions) have been known for a long time. I have already been confronted to concurrency issues with XA transactions without finding a satisfactory issue. What I have learned today is that distributed transactions are complex but can be useful if adapted to the business need.
Observers
Percolator has been designed as an incremental system. Observers are designed for that goal: Percolator is designed as a series of observers. Notifications can be seen as similar to database triggers but they have a simpler semantic than triggers' one: they run in a different transaction so there are not intended to preserve invariants. Developers have to care about infinite observer's cycles too.
For an observed column, an entry is written in the c:notify column each time data is written in the c:data column. Observers are implemented in a separate worker process. This worker process performs a distributed scan to find the row that has an entry in the c:notify column. This column is not a transactional one and many writes to the column may trigger the observer only once. I will not go into details of the observer's implementation: locality of the observer column, random scanning and locking mechanism to efficiently look for the few modifications in a large repository. Please refer to the whole paper for further information.
Such architecture is rather different from actual architectures in business IT:
- Percolator is based on a data sharing pattern whereas distributed architectures (mainly Service Oriented Architectures) are rather stateless;
- Percolator observers look like database triggers but they are very different: they run in a separate process that scan the modification and do not modify data invariants. The observers do not enforce data invariants like triggers but only provide a tool for an event driven architecture.
Cost of the scalability
Percolator system has been built on top of an existing layer and in a distributed way. The provided scalability comes at a cost. First it involves much more RPC requests than a Map/Reduce processing. Last, releasing locks in a lazy way combined with blocking API causes contention. These two issues have been resolved:
- By batching RPC like Read-Write-Modify instead of doing 3 RPC call for each business write;
- By pre-fetching data in the same row;
- By delaying lock's releasing;
- By increasing the number of threads in order to preserve enough concurrency;
Consequently Percolator has been carefully evaluated by comparing it to Map/Reduce and by running synthetic workload based on TPC-E, the last database benchmark for OLTP workload. To summarize, Percolator reached its goal as it allows reducing the latency (time between page crawling and availability in the index) by a factor of 100. It allows simplifying the algorithm. The previous Map/Reduce algorithm has been tuned to reduce the latency and required 100 different Map/Reduce whereas Caffeine requires only about 10 observers. The big advantage of Percolator is that the indexing time is now proportional to the size of the page to index and no more to the whole existing index size. However, when the update ratio (% of the repository size updated by hour) is increased Percolator advantages disappear. At about a 40% update ratio, Percolator is saturated (notifications starts accumulating and latency explodes) and Map/Reduce becomes more efficient. Map/Reduce reaches a limit too, but this limit is reached with a far more important (and not measured) update rate.
So an incremental system is more efficient for continuous small updates, and Map/Reduce batch for big changes. In my past experience I have seen difficulties when some batches, for loading start of day data, were replaced by EAI message driven middleware without changing the timeline. Such results tend to confirm my point of view: batch and on the fly processing require different kind of architecture.
Some measures were then performed. The conclusion is that read overhead of Percolator compared to a direct read on BigTable is very light: about 5% but write overhead is much larger: about 400%.
Last benchmark is based on TPC-E to be able to compare percolator to databases. Some adaptations have been made: one update has been deactivated due to conflict - another implementation was described but has not been measured - and the latencies are larger than the maximum bearable for an OLTP workload. Despite all those limitations the important results were:
- Throughput by core was linear up to 500 Transactions Per Second / 650 cores and linear with a smaller slope up to about 11,000 TPS / 11,000 cores.
- It was more than 3x more than the TPC-E record with 30x more CPU
My conclusion is that despite these relatively bad results on a performance perspective, Percolator's architecture is very interesting because it provides horizontal scalability and resilience. The gain in scalability and resilience comes at a cost. In particular layering causes the most important overhead. Google concluded that TPC-E results suggest a promising direction for future investigation.. I'm a fervent believer of NoSQL. Scalability has strongly modified application architecture, in particular with the web. Distribution of the data has allowed Google and other big internet actors to reach scalability unbelievable till now. I think NoSQL can bring such gains for business IT (throughput, scalability). However, as a result of the distribution, there is a performance penalty. My assumption is to compare it with the difference between mainframe batches on ISAM/VSAM files: for how long does a relational database perform better on batch than a VSAM file processing (if they process better)? Such NoSQL architectures are inspiring influence for use cases or future evolution in application design (e.g. new way to manage schema, new way to search, etc.) where NoSQL will globally outperform database despite the performance penalty.
Relative works and conclusion
Percolator research papers ends by re-enforcing the fact that incremental processing avoids latency and wasted work - like re-reading the whole repository again and again instead of seeking - of batch processing systems like Map/Reduce for small batches of updates. By constrast Map/Reduce batches are more efficient and scalable for big updates. Some improvements proposed to Map/Reduce do not completely solve the problem thus leading to a full redesign. Compared to other systems, the main particularities of Percolator's design are:
- It is not a fully-fledged database: it does neither provide a query language nor join operations. It emphasizes throughput over latency. But it does provide a better scalability than RDBMS or parallel RDBMS;
- Organization of data, distributed transactions originates from parallel databases. Some references date as far back as 30 years ago;
- Compared to distributed storage like HBase or Amazon Dynamo, Percolator should be seen as much more a transformation system. It does not provide some of their functionalities like cross-datacenter replication.
- Some research works (e.g. but not exhaustively CloudTPS) are trying to build ACID transactions on top of distributed storage
Faster CPUs than disks have made multi-CPU shared memory system (aka monolithic systems) simpler competitive to the distribution approach for databases. Today, huge datasets like Google index processed by Percolator changes this situation and a distributed architecture is required. Percolator has been in production since April and achieves the goal. TPC-E benchmark is promising but the linear scalability comes at a 30-fold overhead compared to a traditional database. The next challenge, at the end of this research paper, would be to know if it can be tuned or if it is inherent to distributed systems.
Such in-depth panorama of Percolator architecture was for me a good way to clearly understand the way the architecture was built, from constraint analysis to optimizations. Even if it is not directly applicable to day to day work, Google is one of the key innovative leaders for large scale architecture. Analyzing such architecture enabled me to stand back from traditional architectures. Percolator may drive some open-source projects like Hadoop built according to GFS, BigTable and Map/Reduce research papers. If it's not so, Percolator architecture will surely remain a reference, because it is a pioneer in its domain.
Main sources
- Google Percolator Research paper:“Large-scale Incremental Processing Using Distributed Transactions and Notifications”, Daniel Peng, Frank Dabek, Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation, 2010.
- Google research papers on GFS, BigTable, MapReduce