Multitasking or reactive?

For years now, any process running in parallel of others has required a dedicated thread. We believe this paradigm to be outdated.
As the number of clients rises at an unprecedented speed, it seems no longer possible to multiply the number of threads without negatively impacting performance. We showed in our JavaEE Bench (witten in French) how performance can be improved by reducing the number of threads.
To understand this, we must first differentiate soft-threads (a multi-task simulation on the same core) from hard-threads (processes running on different cores).
The soft-threads are organized by the OS in a circular list. For example, assume a distribution every 10ms and a dispatcher without priority. Every 10ms, the current process is interrupted to execute the next thread. For six threads, the loop lasts 60ms.
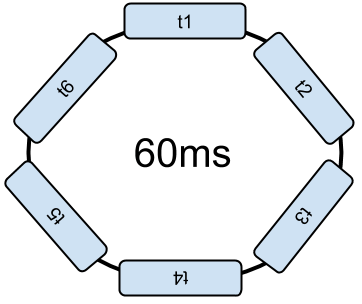
This mechanism is called "context switching". And it uses the CPU for 60ms. To complete the loop, each thread must run at least once.
If a soft-thread initiates a network or file input/output (IO), the soft-thread is removed from the loop until the IO is completed. This makes more time for other processes to run.
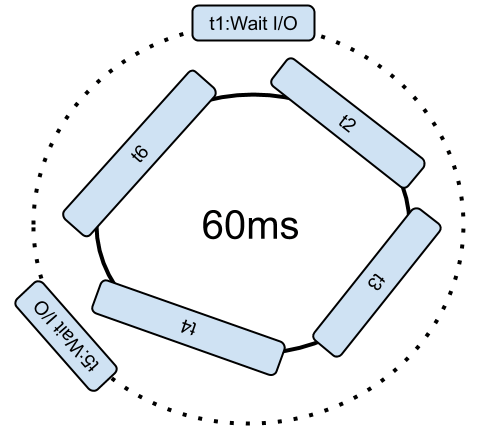
Adding threads is harmful to all the others running.
Two strategies are used to dynamically adjust the time dedicated to each soft-thread. The first idea is to reduce the time span dedicated to each. A loop still lasts 60ms, but each process is stopped more frequently.
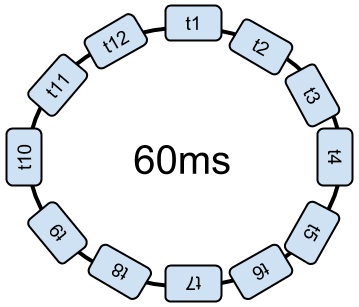
This increases the number of context switches, and it takes up more time unnecessarily. Or, better yet, the dispatcher raises the total time to go through the loop in order to reduce the number of interruptions.
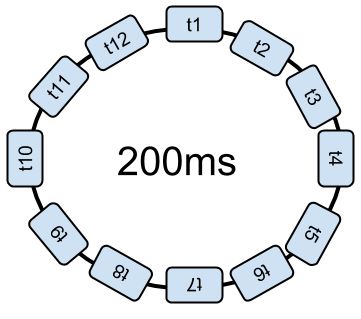
Once the OS interrupts a task, it must take a full loop before it can resume its execution. In theory, with a loop of 10,000 threads, we need 10,000 x 10ms to make complete the loop; or 100 seconds before restarting the processing!
Some audit tools such as jClarity alert the developer if there is too much "Context Switching". Meaning there is too much code dedicated to the transition from one thread to the next. These tools can measure the time lost moving from one thread to the next in increments of time.
With more cores, the same loop is executed on several hard-threads.
The processor manufacturers are making efforts to improve parallelism. Unable to increase the frequency, they multiply cores and improve the capacity of each core to perform several processes simultaneously. For example, hyper-threading™ is used to multiply the capacity of each core. The processor runs multiple assembly instructions in parallel for each one via a multiplication of transistors. But for this to work, the instructions executed in parallel on the same core must be independent. One should not depend on the result of the other.
To reduce dependencies, some versions of processors rename registries when possible.
The 9500 series and following Intel processors Itanium™ offer specific instructions (EPIC) to optimize thread management via flags included by compilers and interpreted by processors. Parallelism strategies are applied by the compiler (JIT), which organizes the code and injects specific instructions enabling the processor to improve parallelism.
With these processors' evolutions, multiple instructions of the same thread and/or multiple threads run in parallel according to the processor's capabilities.
It is then possible to increase the number of hard-threads, supported directly by the electronics. Despite the increased capabilities of processors, additional soft-threads reduce performance.
The current model of thread management is probabilistic. In real life, the processed user requests spend most of their time waiting for resources (file reading, response to a query against database, web service response, etc.). To avoid having an idle processor, the threads are multiplied with the hope that one can run while waiting for another. There are actually three concurrency situations with only two threads:
The two threads run alternately during the idle time (the ideal case)
The two threads run simultaneously. In fact, it is the operating system that distributes the 10ms time slots between threads. At each changeover, a context switch is executed. The latest versions of processors improve this phase, but it uses resources.
The two threads are simultaneously pending.
Since the waiting period is proportionately longer than the processing time, there is a high probability that the two threads are waiting simultaneously. To improve this, we increase the number of threads. But, at the same time, we increase the probability of context switching. There is no quick fix.
The classical approach is therefore probabilistic, with a low chance of hitting the best case scenario. One can bet that the processes will be alternated by adding more threads.
In fact, CPU consumption higher than 35% on a server is rarely noticed (without triggering the GC). This is also a figure noted by Intel! The queries spend most of their time waiting for resources. That means 65% of untapped CPU capacity!
If your application performs practically only IO, it is perhaps simpler to multiply threads. With each IO added into the threads of the distribution loop, there is in fact little CPU capacity loss. On the other hand, it consumes lots of memory. But if your queries calculate pages or json flow, CPU is necessary.
The reactive approach
The reactive approach, described in a previous article (in French), suggests a different approach: deterministic. The idea is to be limited to hard-threads. Only one thread per core. No more. Thus, all processes are actually performed in parallel. The CPU is maximized.
For this, all IO calls must use asynchronous APIs. Thus, the processors don't have to wait anymore. An engine must then distribute processing for each event response.
More and more companies use this model. This is the case in retail for example.
With a different development approach, based on events and fewer threads, it is possible to be more efficient. In fact, Intel recommends only the use of hard-threads to manage requests to the Information System.
To conclude
Hard-threads are physical threads, corresponding to different microprocessor cores. Eight cores? Eight threads (sixteen or more if we agree to use hyper-threading). But no more for the entire program.
Additional soft-threads may be present if they are idle most of the time. This is the case for the algorithms of purges, timers, etc. For the garbage collector, the question arises: should we dedicate a core for it or slowdown reactive processes? Different strategies are possible.
The standard language libraries now offer a pool of hard-threads shared by all frameworks. This is no accident.
Scala offers an ExecutionContext, Java 8 offers a commonPool which is also a ForkJoinPool, .Net offers a TaskPool. This shared pool adjusts itself to the running platform. The developer will have only four threads, for example, while the production server will have sixteen. As a minimum, the program must be able to operate with a single hard-thread. Reactive development architecture enables this. This is also the approach chosen by node.js.
In next articles, we will see how to write programs without threads, the French blog post already exists.
Whenever possible, we recommend using a reactive approach. Then, it is possible to improve application performance without having to increase the number of machines or memory. Moreover, this architecture offers horizontal scalability, fault tolerance and is able to absorb peak loads.
This approach can be imposed for an entire project or used tactically in some parts.
Unless your application primarily computes calculations, it is time to consider the reactive approach. All languages are candidates for this paradigm.