Multitâches ou réactif ?

Depuis de nombreuses années, tout traitement effectué en parallèle d’autres traitements mérite un thread dédié. Nous pensons que ce paradigme arrive à essoufflement.
Au vu de l’augmentation sans précédent du nombre de clients, il ne semble plus possible de multiplier le nombre de threads sans impact négatif sur les performances. Nous avons montré dans un Bench JavaEE que les performances peuvent s’améliorer en réduisant le nombre de threads.
Pour bien comprendre, nous différencions les soft-threads (qui sont une simulation d’un multi-tâche sur le même coeur) des hard-threads (qui sont des traitements s’exécutant sur des coeurs différents).
Les soft-threads sont organisés par l’OS dans une liste circulaire. A titre d’exemple, prenons le cas d’une répartition toutes les 10ms et un répartiteur sans priorité. Périodiquement le traitement actuel est interrompu pour exécuter le thread suivant pour 10ms. Pour six threads, un tour de boucle dure donc 60ms.
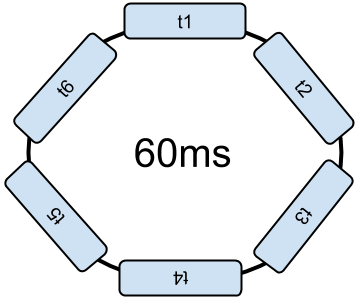
C’est ce mécanisme que l’on appelle “Changement de contexte” (Context switching). Et cela consomme de la CPU sur 60ms disponible. Pour terminer la boucle, il faut que chaque thread s’exécute au moins une fois.
Si un soft-thread invoque une entrée/sortie (IO) de type réseau ou fichier, le soft-thread est supprimé de la boucle tant que l’IO n’est pas terminée. Cela laisse plus de temps aux autres traitements.
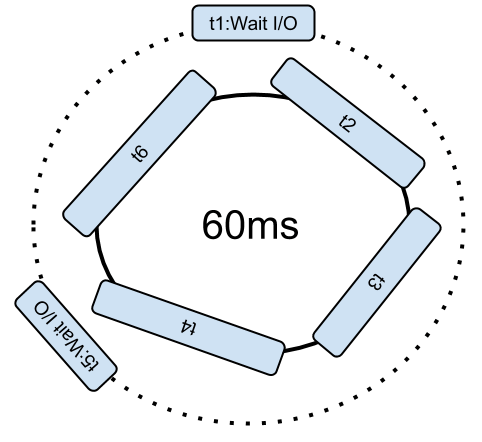
Ajouter des threads est nuisible à tous les autres faisant des calculs.
Deux stratégies sont utilisées pour ajuster dynamiquement le temps dédié à chaque soft-thread. La première idée est de réduire le temps dédié à chacun. Un tour de boucle dure toujours 60ms mais chaque traitement est interrompu plus fréquemment.
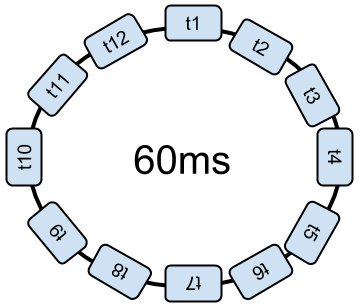
Cela augmente alors le nombre de changements de contexte, et cela prend du temps inutilement. Ou bien, le répartiteur augmente le temps complet de la boucle pour interrompre moins souvent les traitements.
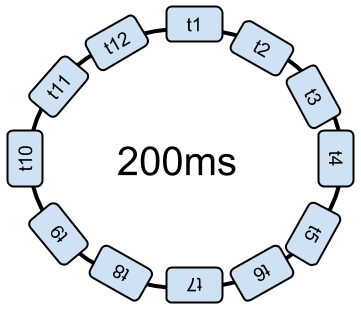
Dès que l’OS interrompt une tâche, il faut attendre un tour complet de la boucle avant qu’elle ne puisse reprendre son exécution. En théorie, avec une boucle de 10 000 threads, il faut 10 000 x 10ms pour faire un tour de boucle ; soit 100 secondes avant de reprendre le traitement !
Les outils d’audit comme jClarity alertent le développeur s’il y a trop de « Context Switching », c’est-à-dire trop de code consacré à la transition d’un thread au suivant. Ces outils sont capables de mesurer le temps perdu à passer d’un thread au suivant par tranche de temps.
Avec plusieurs coeurs, la même boucle est exécutée sur plusieurs hard-threads.
Les fondeurs de processeurs font des efforts pour améliorer le parallélisme. Ne pouvant augmenter la fréquence, ils multiplient les coeurs et améliorent la capacité de chaque coeur à effectuer plusieurs traitements simultanément. Par exemple, l’hyper-threading™ est une technologie permettant de multiplier la puissance de chaque coeur. Le processeur exécute plusieurs instructions assembleur en parallèle pour chacun, via une multiplication des transistors. Mais, pour que cela fonctionne les instructions exécutées en parallèle sur le même coeur doivent être indépendantes. L’une ne doit pas dépendre du résultat de l’autre.
Pour réduire les dépendances, certaines versions des processeurs renomment les registres si cela est possible.
Les séries 9500 et suivantes des processeurs Intel Itanium™ proposent des instructions spécifiques (EPIC) pour optimiser la gestion des threads via des flags inclus par les compilateurs et interprétés par les processeurs. Les stratégies de parallélisme sont appliquées par le compilateur (JIT) qui se charge d’organiser le code et d’injecter des instructions spécifiques pour permettre au processeur d’améliorer le parallélisme.
Avec ces évolutions des processeurs, ce sont plusieurs instructions du même thread qui s’exécutent en parallèle et/ou plusieurs threads en parallèle suivant les capacités du processeur.
Il est alors possible d’augmenter le nombre de hard-threads, supporté directement par l’électronique. Néanmoins, au-delà des capacités des processeurs, les softs-threads complémentaires nuisent aux performances.
Le modèle actuel de gestion des threads est probabiliste. En effet, dans la vraie vie, les traitements des requêtes utilisateurs passent l’essentiel de leur temps à attendre des ressources (la lecture d’un fichier, la réponse à une requête sur la base de données, le retour d’un service web, etc.). Pour éviter d’avoir un processeur qui ne fait rien, on multiplie les threads avec l’espoir qu’un traitement pourra s’exécuter pendant l’attente d’un autre. Il y a en fait trois situations de concurrence avec seulement deux threads :
Les deux threads s’exécutent alternativement pendant les temps de pause (cas idéal)
Les deux threads s’exécutent au même moment. En fait, c’est le système d’exploitation qui distribue des tranches de temps de 10 ms entre les threads. À chaque basculement, il doit exécuter un changement de contexte. Les dernières versions des processeurs améliorent cette phase, mais cela consomme des ressources.
Les deux threads sont simultanément en attente.
Comme la période d’attente est proportionnellement plus longue que les périodes de traitements, il y a une forte probabilité que les deux threads attendent simultanément. Pour améliorer cela, on augmente le nombre de threads. Mais en même temps, on augmente la probabilité d’avoir des changements de contextes. Il n’y a pas de solution miracle.
L’approche classique est donc probabiliste, avec une faible chance de tomber sur le scénario optimal. Ajouter des threads, c’est faire le pari que les traitements seront alternés.
Dans les faits, on remarque rarement une consommation CPU supérieure à 35% sur un serveur (hors déclenchement du GC). C’est d’ailleurs un chiffre constaté par Intel ! Les requêtes passent l’essentiel de leur temps à attendre des ressources. Il resterait 65% de CPU non exploitée !
Si votre application n’effectue pratiquement que des IO, il peut être simple de multiplier les threads. Chaque IO éjectant le thread de la boucle de distribution, il y a, en fait, peu de perte CPU. Par contre, cela consomme beaucoup de mémoire. Mais si vos requêtes calculent des pages ou des flux JSon, la CPU est nécessaire.
L’approche réactive, décrite dans un article précédent, propose une approche différente, déterministe. L’idée est de se limiter à des hard-threads. Un seul thread par coeur. Pas plus. Ainsi, tous les traitements s’effectuent réellement en parallèle. La CPU est exploitée au maximum.
Pour cela, il faut que toutes les invocations aux IO utilisent des API asynchrones. Ainsi, les processeurs n’attendent plus. Un moteur doit alors distribuer les traitements à chaque réception d’événement.
De plus en plus d’entreprises exploitent ce modèle. C’est le cas dans la grande distribution par exemple.
Avec une approche de développement différente, basée sur les événements et moins de threads, il est possible d’être plus efficace. Dans les faits, Intel préconise de n’utiliser que des hard-threads pour gérer les requêtes au système d’information.
Pour conclure
Les hard-threads sont des threads physiques, correspondant aux différents cœurs du microprocesseur. Huit coeurs ? Huit threads (seize ou plus si l’on accepte d’exploiter l’hyper-threading). Mais pas plus pour l’intégralité du programme.
Des soft-threads complémentaires peuvent être présents s’ils sont au repos la plupart du temps. C’est le cas pour les algorithmes de purges, les timers, etc. Pour le ramasse-miettes, la question se pose. Faut-il dédier un cœur pour cela ou ralentir les traitements réactifs ? Différentes stratégies sont possibles.
Les librairies standard des langages proposent maintenant un pool de hard-threads, partagé par tous les frameworks. Ce n’est pas un hasard.
Scala propose un ExecutionContext, Java 8 propose un commonPool qui est également un ForkJoinPool, .Net propose TaskPool. Ce pool partagé s’ajuste à la plate-forme d’exécution. Le développeur n’aura que quatre threads par exemple, alors que le serveur de production en aura seize. A minima, le programme doit être capable de fonctionner avec un seul hard-thread. L’architecture de développement réactive permet cela. C'est d'ailleurs l'approche choisie par node.js.
Dans les prochains articles, nous verrons comment rédiger des programmes sans threads.
Autant que possible, nous préconisons d’utiliser une approche réactive. Ainsi, il est parfaitement possible d’améliorer les performances des applications sans augmenter le nombre de machines ou la mémoire. De plus, ces architectures proposent une scalabilité horizontale, une tolérance aux pannes et sont capables d’encaisser des pics de charge.
Cette approche peut être imposée pour l’intégralité d’un projet ou utilisée tactiquement sur certaines portions.
A moins que votre application effectue essentiellement des calculs, il est temps d’envisager l’utilisation d’approches réactives. Tous les langages sont candidats à ce paradigme.
Philippe PRADOS et l'équipe "Réactive"