Multitâche sans thread 3/5 – Coroutine

Pour faciliter le développement d’application réactive, les langages de développement proposent différentes technologies. Dans les chapitres précédents, nous avons parcouru les générateurs et le pattern Continuation. Nous continuons notre analyse des techniques permettant de gérer du multitâche sans threads, avec les coroutines. Le terme coroutine a été inventé, en 1963 par Conway et Melvin. Cette technologie a été beaucoup utilisée sous MSDOS (1984) car l’OS n’était pas ré-entrant. Pour les mêmes raisons, ce modèle a perduré sur les premières versions de Windows jusqu’à la version 3.0 (1990). Il a fallu attendre Windows 3.1 (1992) pour avoir de vrais soft-threads dans l’écosystème Microsoft.
Une coroutine est un thread léger collaboratif. C’est-à-dire que la transition vers une autre coroutine s’effectue à sa demande.
Le modèle de thread actuel est basé sur un scheduleur pré-emptif. Les tics horloges synchronisent les changements de contextes.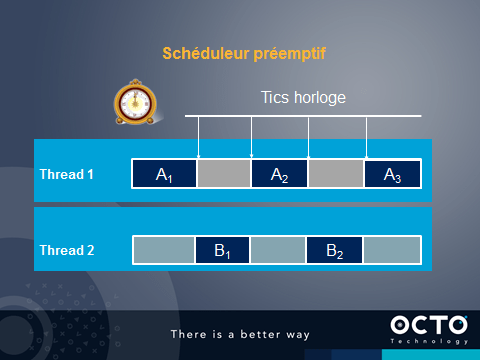
Un scheduleur collaboratif applique un autre modèle.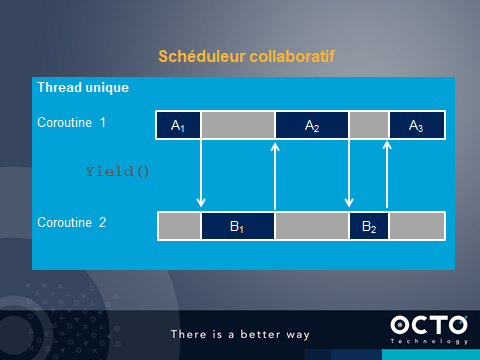
L’instruction ou la fonction yield() est vue par le programme comme une fonction vide, sans effet de bord. Mais dans les faits, le flux de traitement est dérouté vers une autre coroutine. Plus tard, le traitement peut revenir pour reprendre le cours de la coroutine après le yield().
Cela présente l'avantage de ne plus avoir d'accès concurrent à la mémoire. Chaque traitement d'une Coroutine est certain d'être le seul à s’exécuter.
Il existe deux types de coroutine : les symétriques donnant la main à la prochaine coroutine et les asymétrique permettant de spécifier le prochain bloc de code à exécuter (Yieldto()). Attention, il peut y avoir affinité entre les coroutines et les soft/hard-threads pouvant les exécuter.
Les coroutines permettent un basculement du flux de traitement très rapide, car le kernel n’intervient pas, mais présente le risque qu’un traitement monopolise le flux de la CPU sans jamais invoquer la méthode yield(). Par contre, si les développeurs respectent ce modèle, la consommation CPU est optimale. De plus, il n’y a pas de risque d’accès concurrents si un seul hard-threads est utilisé (choix de node.js).
Avec le langage C, les coroutines sont généralement implémentées à l’aide des instructions setjmp et longjmp. Ces instructions permettent de mémoriser un point précis dans la pile d’appel et d’y revenir. Cela permet de couper tous un empilement d’appel en cas d’erreur. C'est le même modèle que pour les exceptions. Pour schématiser, ces instructions permettent de sauver la valeur du pointeur de pile.
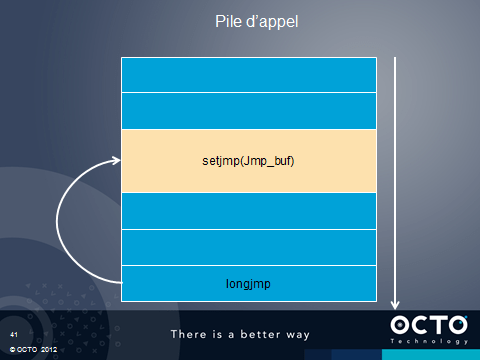
Il n’en faut pas plus pour créer des coroutines. Il suffit de créer des tampons pour de nouvelles pile, de manipuler l’objet généré par un setjmp pour basculer d’une pile à une autre via un changement du pointeur de pile dans la structure jmp_buf.
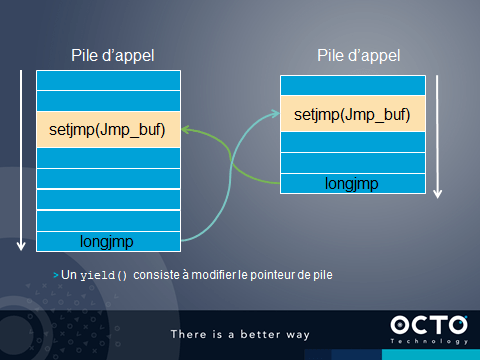
yield() permet alors de sauver tous les registres dans la pile, de changer le pointeur de pile et de restituer les valeurs de tous les registres pour continuer avec la prochaine coroutine.
En java, il existe la librairie Javaflow, proposée par la fondation Apache. Il s’agit d’un classloader qui va injecter du code dans toutes les classes. Ce code va maintenir une pile parallèle lors des appels, et permettre de basculer d’une pile à une autre. Tout est porté par une seule instruction de la JVM, instruction qu’un code java ne peut jamais proposer : this = … Techniquement, pour modifier la valeur de this vers une autre instance d’une coroutine, il faut exécuter l’opcode astore_0.
Voici le code de démarrage d’une coroutine et sa mise en pause.
// Java Continuation.startWith(new MyRunnable()); Continuation.suspend();
Pour pouvoir proposer des coroutines sans modifier la JVM, la librairie effectue des transformations importantes dans le code de toutes les méthodes.
Par exemple, le code suivant va être transformé.
public final class Simple implements Runnable { public int g = -1; public int l = -1;
public void run() { int local = -1; ++g; l=++local; Continuation.suspend(); // equivalent du Yield ++g; l=++local; Continuation.suspend(); ++g; l=++local; Continuation.suspend(); ++g; l=++local; } }
Le code est découpé en blocs délimités par l’invocation de méthodes. La méthode suspend() est traitée de façon particulière. Après son invocation, il y a sauvegarde de l’instance courante, sauvegarde de l’état des variables locales à la méthode, sauvegarde du numéro de bloc puis exécution d’un return. Puis, au début de la méthode, il y a injection d’un switch pour sélectionner le bon numéro de bloc à exécuter pour reprendre le traitement de la méthode.
Le début de la méthode run() ressemble à ceci :
StackRecorder sr=StackRecorder.get() if (sr==null || sr.isRestoring) goto block_0 switch (sr.popInt()) { // Num bloc case 0 : local=sr.popInt() // reinit les variables locales this=(Simple)sr.popObject() // reinit this. Changement de Coroutine goto save_block_0 case 1 : local=sr.popInt() this=(Simple)sr.popObject() goto save_block_1 case 2 : local.sr.popInt() this=(Simple)sr.popObject() goto save_block_2 … }
Puis les blocs sont proposés :
block_0: local = -1; ++g; l=++local; save_block_0: Continuation.suspend(); // Sauvegarde ? if (sr==null || !sr.isCapturing) goto block_1 sr.pushReference(this) sr.pushObject(this) sr.pushInt(local) sr.pushInt(0) // Numéro du bloc return block_1: ++g; l=++local; save_block_1: Continuation.suspend(); if (sr==null || !sr.isCapturing) goto block_2 …
Avant chaque bloc, il y a une vérification pour s’assurer qu’une demande de suspension n’est pas demandée. Si le traitement peut continuer, un goto est appliqué vers le bloc suivant. Sinon, le contexte est mémorisé dans le StackRecorder et un return est appliqué. Cela interrompt la méthode run(). La reprise s'effectuera en invoquant a nouveau run() sur l'instance.
L’impact n’est pas nul sur les performances. Il faut en effet maintenir une pile parallèle et ajouter de nombreux tests dans le code.
Les approches C et JavaFlow peuvent être comparées.
| LongJmp / SetJmp | JavaFlow |
|---|---|
| Propose une stack lors de la création d’une co-routine | Duplique la stack de la JVM lors de l’exécution |
| Accès possible à la stack | Pas d’accès à la stack |
| Modifie le pointeur de pile lors d’un changement de contexte | Modifie le pointeur this lors d’un changement de contexte |
| Contexte limité à la pile initiale. (4 Ko sous Ruby) | Utilise la pile de la JVM. |
| Pas de modification du code | Injection de code dans toutes les méthodes |
| Pas d’adhérence à un thread | Adhérence à un thread |
| Très efficace | A notre avis, non pertinent |
On trouve également des agents à la JVM qui se chargent des transformations du code.
Il est plus efficace d’intervenir directement sur la JVM pour proposer ce concept plus intimement. C’est ce que propose le projet « Coroutine for Java ». Un JSR a été ouvert avec une implémentation de référence. L’idée est de proposer une pile spécifique par coroutine dans la mémoire de l’OS (non exécutable). Un switch rapide entre coroutines est possible, en modifiant quelques registres. Techniquement, ce modèle s’approche de l’implémentation C.
La mémoire réservée aux coroutines est variable suivant les OS et partagée entre les coroutines : 32 Kb (Linux), 64 Kb (Windows) ou 10 Kb (Solaris). En 32 bit, il est possible d’allouer 25 000 piles pour les coroutines. En 64 bit, l’adressage permet d’avoir beaucoup plus de coroutines. Dans les faits, les coroutines maintiennent 1 ou 2 Ko en RAM pour maintenir leur état. Chaque thread java maintient une liste de coroutines et de piles pour les coroutines. Le ramasse miette intègre ces évolutions.
Un exemple d’utilisation :
Coroutine c=new Coroutine(new Runnable() {
for (int i=0;i<10;++i) {
System.out.println("i=" +i);
Coroutine.yield();
}
});
c.yield()
Une instance Coroutine est très proche d’une instance Thread.
Cette implémentation légère est très pertinente, mais demande une modification de la JVM.
On retrouve des implémentations pour d’autres langages, souvent appelés Fiber. C’est le cas de Javascript, Python, Ruby, Go, etc. La JVM est le parent pauvre. On retrouve également le terme "green thread".
Dans le cadre d'une utilisation dans une architecture réactive, un modèle similaire aux approches précédente est envisageable. L'idée est d'exposer des API apparemment bloquantes, mais qui en interne, invoque les API asynchrones de l'OS juste avant un Yield(). Lors de la réception de l'acquittement par l'OS, un Yield() est à nouveau invoqué.
Le tableau suivant résume les avantages et inconvénients des trois premières approches que nous avons parcourue.
| [Générateur](<a href=) | [Continuation](<a href=) | Coroutine | |
|---|---|---|---|
| Usages | Dans une boucle | Pour continuer après un traitement | Mise en pause d’un traitement |
| Limitations | Retourne un Itérateur Local à une fonction | Pile / Exception Boucles | JVM |
| Points forts | Généré | Généré | Garde la pile d'appel Compatible exceptions |
Cela achève notre troisième approche pour gérer du multitâche sans threads. Il nous reste encore deux approches : les pipelines/compositions et les async/await.
Philippe PRADOS et l'équipe "Réactive"