Supervisez votre infrastructure avec Telegraf, InfluxDB et Grafana

Dans un article précédent, nous avons vu comment monitorer avec Prometheus et Grafana une infrastructure dynamique basée sur Kubernetes.
Nous allons voir aujourd'hui comment monitorer une infrastructure plus classique avec Telegraf pour la collecte de métriques, InfluxDB pour le stockage et Grafana pour l’affichage et l’alerting. Nous nommerons cette solution TIG, dans la suite de cet article. Nous avons choisi ces outils, mais ils peuvent être remplacés par d’autres. Nous allons comparer également cette solution à d’autres outils du marché (Zabbix et Prometheus)

Architecture
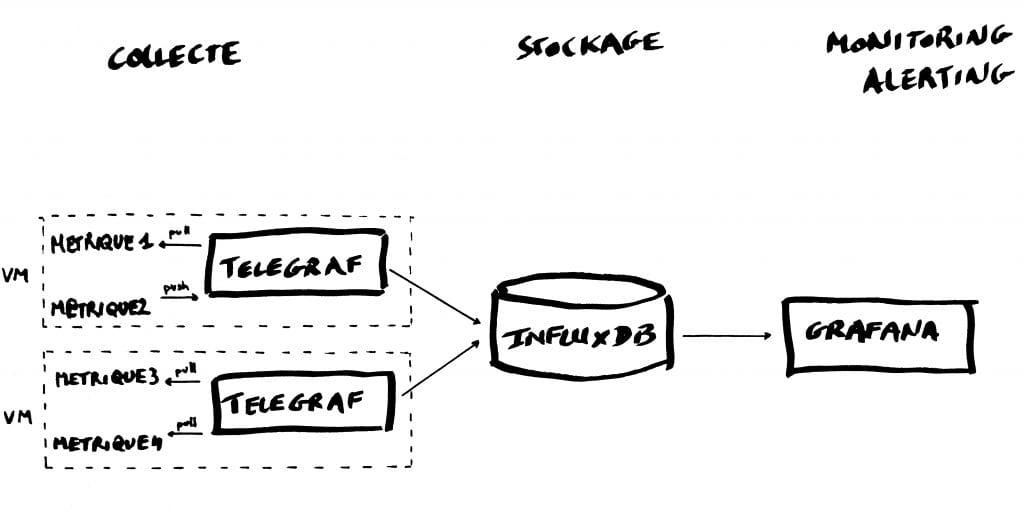
Telegraf
Telegraf est un agent de récupération de métriques, 1 seul agent est nécessaire par VM. Cet agent sait récupérer des métriques exposées au format Prometheus et propose 2 modes de récupération des métriques, via :
- push : la métrique est poussée dans Telegraf par le composant qui l’expose
- pull : Telegraf récupère la métrique en interrogeant le composant qui l’expose (le mode le plus utilisé)
Les métriques sont insérées au fil de l’eau dans InfluxDB.
InfluxDB
InfluxDB est une Time Series Database (TSDB) écrite en Go dont les principaux avantages sont les performances, la durée de rétention importante et la scalabilité (nous verrons plus loin sous quelles conditions).
Grafana
Grafana est un outil supervision simple et élégant, permettant de s’intégrer à une TSDB, ici InfluxDB. Grafana expose dans des dashboards les métriques brutes ou agrégées provenant d’InfluxDB et permet de définir de manière honteusement simple des seuils d’alertes et les actions associées.
Cas d’utilisation
Dans cet article, nous allons monitorer une architecture simple :
- une application web en Go exposée derrière un Nginx
- une base de donnée Mysql sollicitée par un cron
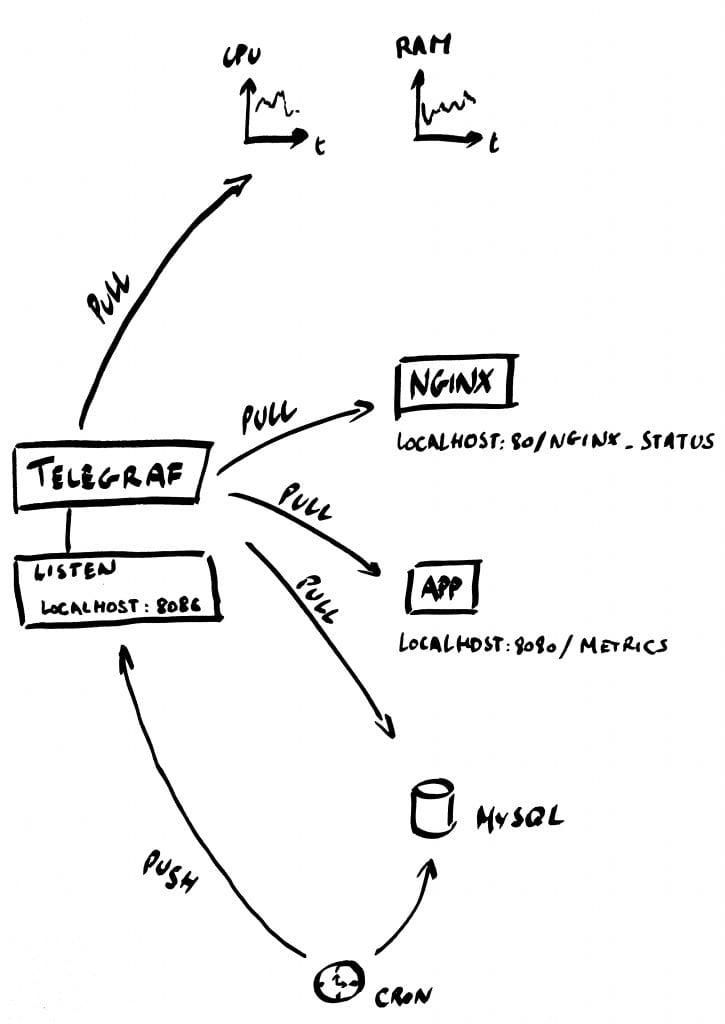
Telegraph permet de récupérer par le biais de plugins les métriques des composants, ainsi que les métriques systèmes. Dans le cas nominal, Telegraf récupère ses métriques en mode pull. Cependant, dans le cas d’un cron ou d’un batch qui s'exécute périodiquement, la récupération des métriques se fait en mode push (c’est au cron ou au batch d’envoyer les métriques à Telegraf). Pour ce cas d’usage, nous allons utiliser le plugin <br>http_listener<br> qui permet à Telegraf d’écouter en http sur un port afin de récupérer les métriques envoyées par le cron/batch.
Installation
Pour cet article, l’installation se fera sous Ubuntu 16.04 LTS.

InfluxDB
Ajoutons le repo APT officiel d’InfluxDB :
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
Installons le package :
sudo apt-get update
sudo apt-get install influxdb
Démarrons le service :
sudo systemctl start influxd
Telegraf
Ajoutons le repo APT officiel de Telegraf :
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
Installons le package :
sudo apt-get update
sudo apt-get install telegraf
Démarrons le service :
sudo systemctl start telegraf
Grafana
Ajoutons le repo APT officiel de Grafana :
curl https://packagecloud.io/gpg.key | sudo apt-key add -
echo "deb https://packagecloud.io/grafana/stable/debian/ jessie main" | sudo tee /etc/apt/sources.list.d/grafana.list
Installons le package :
sudo apt-get update
sudo apt-get install grafana
Démarrons le service :
systemctl daemon-reload
systemctl start grafana-server
Configuration

InfluxDB
Nous allons créer une base de données pour pouvoir pousser les données remontées par Telegraf :
influx -execute "CREATE DATABASE influx_db"
Créons l’utilisateur influx_user :
influx -execute “CREATE USER influx_user WITH PASSWORD 'influx_password'”
influx -execute “GRANT ALL ON influx_db TO influx_user
Il est possible de créer une retention policy pour déterminer la durée de conservation des données :
influx -execute ‘CREATE RETENTION POLICY "one_year" ON "influx_db" DURATION 365d’
Telegraf
Telegraf fonctionne sous forme de plugin à activer pour récupérer les métriques. L’écosystème de plugins est riche : il y a des plugins pour monitorer nginx, cassandra, haproxy, postgresql… Nous allons nous intéresser à quelques plugins en particulier pour notre exemple. Dans l’ensemble, les plugins sont simples à configurer.
Nous allons voir ici des extraits de configuration.
Mode pull
Métriques systèmes
Les plugins permettant de remonter les métriques systèmes :
- cpu
- disk
- diskio
- kernel
- mem
- processes
- swap
- system
$ head /etc/telegraf/telegraf.d/system.conf
[[inputs.cpu]]
Whether to report per-cpu stats or not
percpu = true
Whether to report total system cpu stats or not
totalcpu = true
If true, collect raw CPU time metrics.
collect_cpu_time = false
…
Métriques MySQL
$ head /etc/telegraf/telegraf.d/mysql.conf
[[inputs.mysql]]
servers = ["db_user:db_password@tcp(127.0.0.1:3306)/?tls=false"]
…
Métriques au format prometheus
Pour notre exemple, nous avons une application en Go qui expose des métriques au format prometheus sur l’url http://localhost:8080/metrics. Nous allons utiliser le plugin prometheus pour récupérer ces données :
$ cat /etc/telegraf/telegraf.d/app.conf
[[inputs.prometheus]]
urls = ["http://localhost:8080/metrics"]
Mode push
Plugin HTTP_LISTENER
Le plugin <br>http_listener<br> fonctionne en mode push. Il ouvre un port http et attend qu’on lui pousse des métriques.
$ cat /etc/telegraf/telegraf.d/http_listener.conf
Influx HTTP write listener
[[inputs.http_listener]]
Address and port to host HTTP listener on
service_address = ":8186"
timeouts
read_timeout = "10s"
write_timeout = "10s"
Il faut ensuite envoyer les métriques au format InfluxDB line-protocol :
$ curl -i -XPOST 'http://localhost:8186/write' --data-binary 'account_deleted,host=server01,region=us-west value=32 1434055562000000000'
Configuration du backend
Pour configurer le backend, nous allons utiliser le plugin output InfluxDB.
$ cat /etc/telegraf/telegraf.conf
…
[[outputs.influxdb]]
urls = ["http://localhost:8086"]
database = "influx_db"
username = "influx_user"
password = "influx_password"
…
Pour finir, redémarrons le service pour prendre en compte la configuration :
sudo systemctl restart telegraf
La configuration des plugins est documenté exhaustivement dans le fichier de configuration de base : <br>/etc/telegraf/telegraf.conf<br>
Grafana
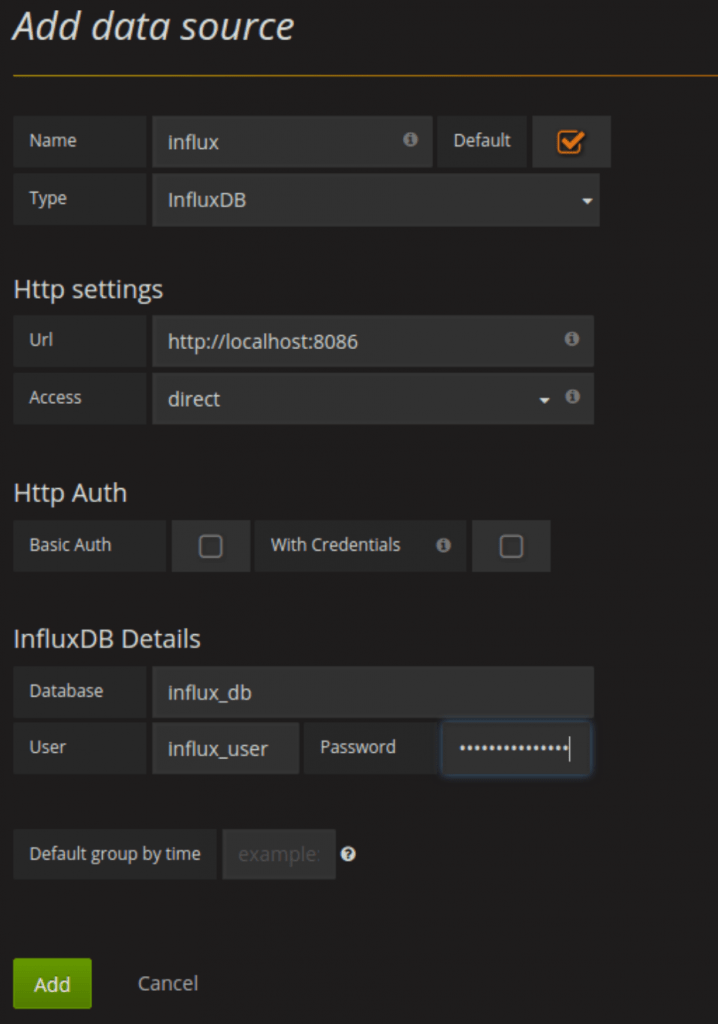
La première étape dans Grafana est d’ajouter la source de donnée (InfluxDB dans notre cas). Allons dans “Datasource” puis “Add Datasource” et ajoutons la base Influxdb.
Database : influx_db Username : influx_user Password : influx_password
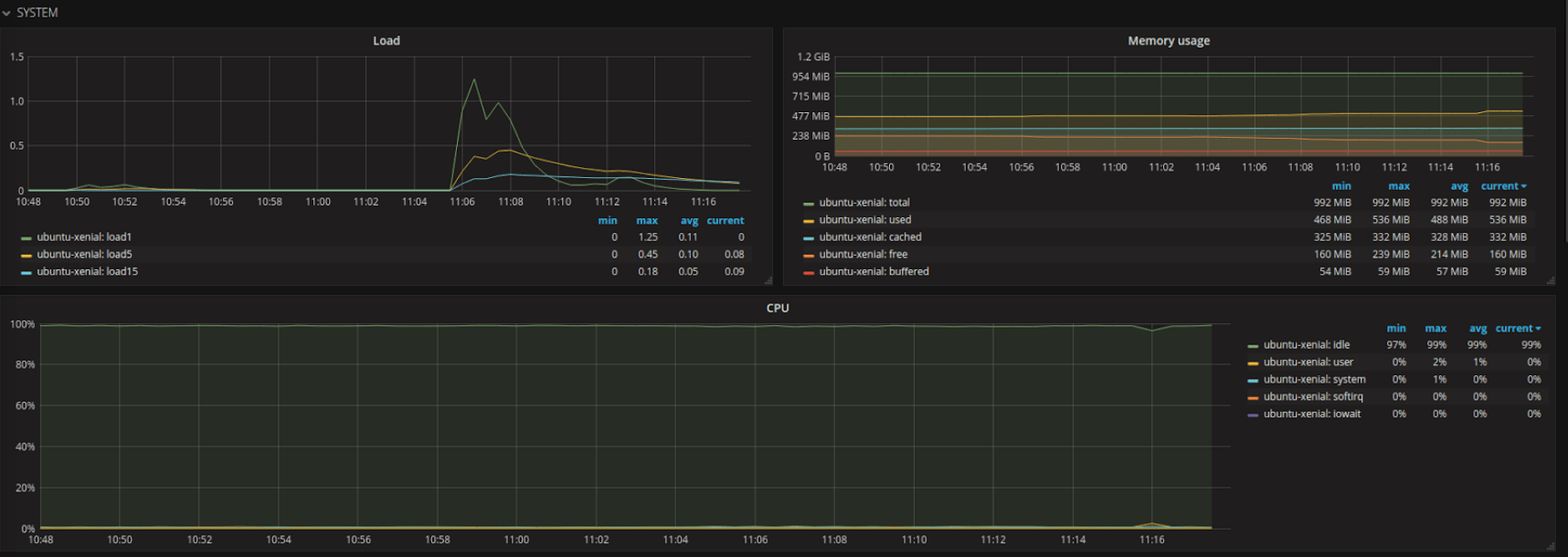
Ensuite pour créer les dashboards, vous pouvez récupérer des dashboards de la communauté Grafana ou créer vos propres dashboards. Pour notre exemple, nous avons importé le dashboard suivant prévu pour Telegraf.
Il est possible d’ajouter des alertes dans les dashboards, mais nous n’allons pas détailler ce point dans cet article. Vous pouvez trouver des informations dans la documentation.
Note : Si vous utilisez Grafana en HA, pour le moment l’alerting n’est pas implémenté en mode cluster. Du coup, il faut s’assurer de l’activer sur un seul des noeuds pour ne pas recevoir les alertes en double. Néanmoins, si le noeud tombe, il n’y a plus d’alerting.
Comparaison
TIG vs Zabbix
Avantages de TIG :
La configuration est plus simple (métriques et graphes)
- Pour récupérer une nouvelle métrique, il suffit de configurer en quelques lignes un plugin dans Telegraf, puis créer un dashboard dans Grafana.
La configuration est plus souple

- Dans Zabbix on a besoin de décrire précisément chacune des métriques remontées, alors que dans TIG, InfluxDB n’a pas besoin de connaître la métrique à l’avance pour pouvoir la stocker.
Simple sur une infra dynamique
- Exemple: Autoscaling sur les principaux cloud provider, les VMs nouvellement créés (avec Telegraf configuré) poussent auto-magiquement (sans configuration supplémentaire) dans InfluxDB.
Historique plus complet
- La profondeur d’historique de Zabbix et d’InfluxDB est équivalente, néanmoins Zabbix dispose d’une stratégie d’échantillonnage (configurable) entraînant une dégradation de la qualité de la donnée sur le long terme.
Les dashboards dans Grafana sont plus conviviaux et plus simples

Avantages de Zabbix :
- Gestion des droits
- La gestion des droits est plus fine sur Zabbix
- Utilisé en prod depuis des années
- Release 1.0 sorti le 23 mars 2004
- Stable, complet et reconnu
- Ressources de la communauté (templates, alertes, agent …)
- Les agents Zabbix sont disponibles pour de nombreux systèmes d’exploitation
- De nombreux templates pour configurer les métriques/alertes/graphes sont disponibles sur internet
TIG vs Prometheus

Avantages de TIG :
- Historique plus complet (plusieurs années vs plusieurs heures/semaines)
- Le but premier de Prometheus est le monitoring temps réel, la rétention par défaut est de 1 mois. Il est cependant possible d’augmenter cette rétention.
- Besoin d’un seul agent par VM
- Telegraf permet de récupérer plusieurs métriques avec un seul agent et pousse les données dans InfluxDB.
- C’est l’agent Telegraf qui envoie les données à InfluxDB
- Pas besoin d’ouvrir de multiples ports comme c’est le cas avec Prometheus.
Avantages de Prometheus :
- Prometheus peut utiliser des services discovery pour savoir quels sont les services à monitorer
- Exemple: Dans des environnements type Kubernetes, Docker, Prometheus est particulièrement adapté pour récupérer les métriques de conteneurs à durée de vie variable.
Conclusion
Dans la stack TIG nous avons apprécié la simplicité d’installation et de configuration, la souplesse de collecte des métriques et la profondeur d’historique.
La version opensource d’InfluxDB ne scale pas mais il est possible de scaler en passant sur les versions payantes InfluxEnterprise ou InfluxCloud. Nous n’avons, à l’heure actuelle, pas de retour d'expérience concernant ces deux derniers produits.
Pour la scalabilité, il est également possible d’utiliser OpenTSDB qui est une “Time Serie Database” open source, mais elle est bien plus compliquée à installer, et nous n’avons pas de retour sur son utilisation.
Il est possible de mettre Grafana en HA. Néanmoins, le mode cluster de l’alerting n’est pas encore implémenté. Cela signifie que soit on ne définit les alertes que sur un nœud, soit on les définit sur tous les nœuds mais les notifications seront dupliquées.
La modularité de cette stack nous permet si besoin d’utiliser :
- d’autres collecteurs tels que Snap (dans le cas, par exemple, où Telegraf ne proposerait pas de plugin adapté).
- d’autres outils d’alerting tels que Kapacitor que nous étudierons prochainement.
Le cas d’utilisation que nous avons présenté est disponible sur ce repo : https://gitlab.octo.com/tpatte/monitoring_influxdb