Mon DSI veut une MEP par jour, comment faire de l’architecture quand tout est en mouvement ? - Compte-rendu du talk de Fabien Arcellier à La Duck Conf 2020

Il y a quelques années on a découvert l’agile, qui nous a permis d’accorder métier et développeurs et ainsi mettre en place des transformations qui ont impacté le rôle d’architecte de système d’information. Aujourd’hui c’est le DevOps qu’on essaye de mettre en place, durant son talk Fabien va nous montrer comment cela se passe dans la réalité.
Mise en situation : un DSI vient nous voir en nous montrant une étude qu’il vient de lire, Accelerate. Il en a retenu le message suivant :
Les organisation les plus rapides à délivrer sont aussi les plus stables : entre vitesse et stabilité il n’y a pas de choix à faire.
Accelerate est une étude qui a été réalisée durant 7 ans, et qui a analysé les habitudes de delivery logiciel d’un panel de 30 000 personnes. Il en a ressorti 4 indicateurs qui permettent de mesurer la performance de delivery d’une organisation. Le premier indicateur est la fréquence de déploiement : un bon élève est capable de déployer en continu, soit au moins une fois par jour.
L’étude établit qu’une organisation dont le delivery est plus performant est plus à même d’atteindre les objectifs qu’elles se fixent. Accelerate présente une recette pour améliorer son organisation.
On pourrait penser que c’est uniquement possible avec du green field, ou sur certains systèmes. Là l’étude nous prend à contre-pied : il n’y a pas de corrélation entre le type de système et la capacité à délivrer. Que ca soit un nouveau logiciel en green field, un backoffice ou même un progiciel packagé, cela n’influe pas sur le fait qu’une organisation soit performante ou non dans son delivery. Nous allons voir par la suite ce que peut faire un architecte de SI exposé au challenge d’arriver à une mise en production par jour.
Avec l’arrivée de l’agile, le rôle d’un architecte de système d’information s’est adapté. On est passé d’une réflexion en amont sur le design à des pratiques aidant les architectures à être adaptables tout en assurant une cohérence :
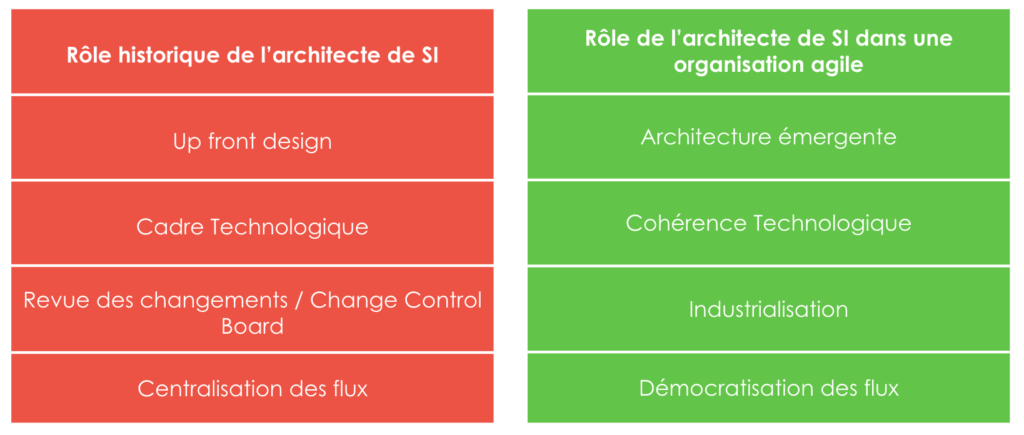
La mission de l’architecte reste cependant la même : fournir à l’organisation les moyens et outils pour gérer des produits interopérables. Il s’est adapté à l’agilité et il doit maintenant prendre en compte la philosophie DevOps qui peut arriver dans son organisation. Dans les projets qui ont connu une accélération du rythme de déploiement, voici plusieurs challenges que nous avons rencontré et comment nous les avons résolu :
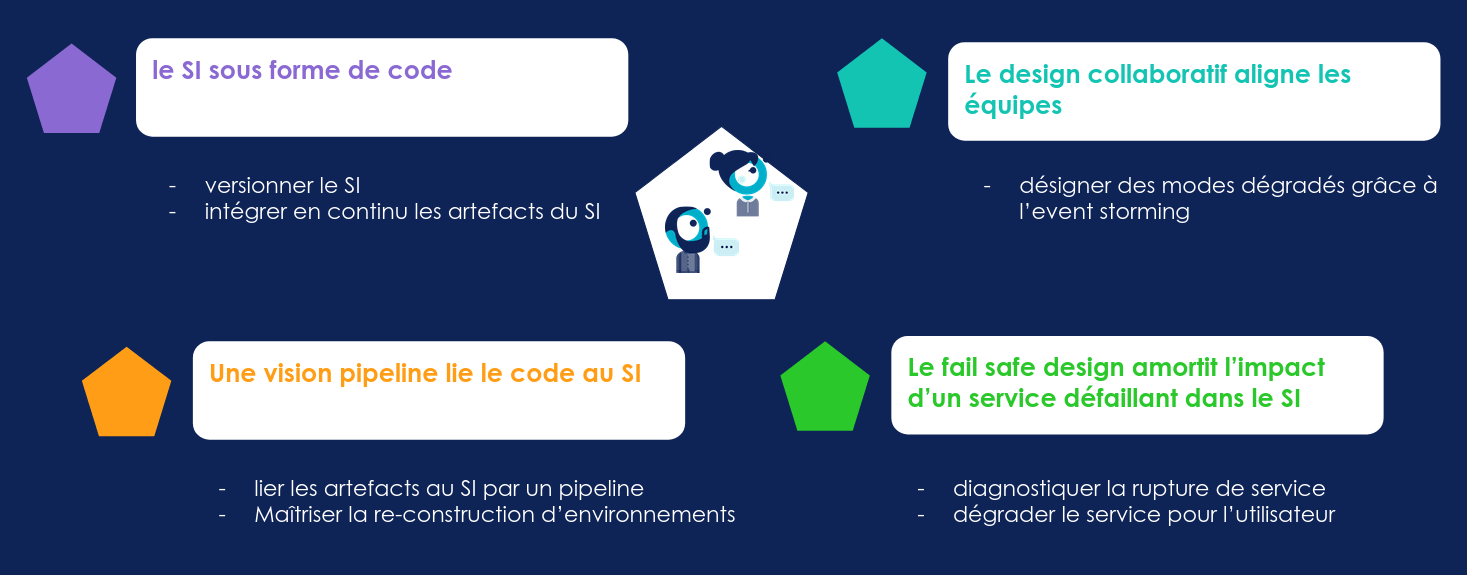
1er challenge : orchester le chaos des changements en les rendant visibles grâce à un SI sous forme de code.
2ème challenge : amener les changements dans le SI avec une vision pipeline qui relie le code au SI qui tourne.
3ème challenge : amortir l’impact des conflits entre les différents services en faisant du fail safe design. Cela permet de limiter les défaillances tout en préservant l’expérience utilisateur.
4ème challenge : harmoniser l’expérience utilisateur en faisant du design collaboratif.
Si en tant qu’architecte de SI, vous vous reconnaissez dans ces problématiques, voici 7 pratiques que nous avons mis en place pour y répondre
Comment avoir un SI sous forme de code ?
Versionner le SI sous forme de code
Au delà du code applicatif ce qui va être différenciant est de versionner l’infrastructure sous forme de code :
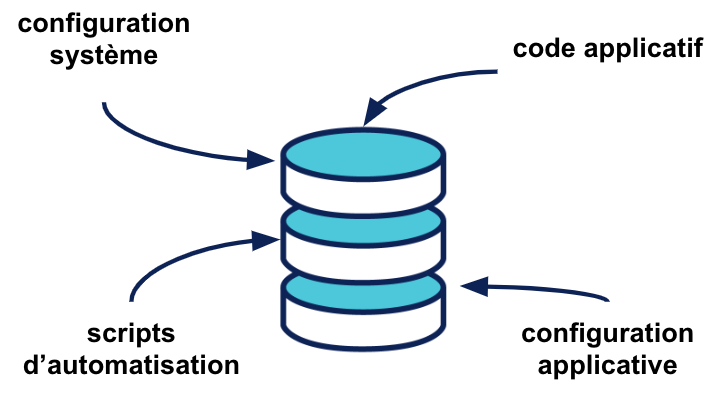
L’impact que cela va avoir est que toute l’organisation opérationnel convergera vers un workflow commun, qui est porté par le gestionnaire de version. Les éléments non versionnés doivent devenir l’exception. Par exemple, les secrets ne sont pas versionnés. L’impact de pratique est confirmée dans l’étude Accelerate. L’usage du contrôle de version pour la configuration système et la configuration applicative par les opérations a un impact significatif sur la fréquence de déploiement.
Intégrer en continu les artefacts du SI
Intégrer signifie que chaque changement, que ce soit du code, de la configuration ou autre va passer par un processus de validation standardisé. Ainsi chaque commit va être conforme au contrôle qualité, passer des tests automatisés, des tests de sécurités, etc. Cette pratique permet de capitaliser le long de la vie du projet, de tracer les décisions techniques et de remplacer les boards de revue des changements.
Attention cependant : l’intégration continue ne joue un rôle que si les développeurs et les opérations travaillent sur un code proche du tronc commun. Si vous utilisez Git, par exemple, nous recommandons de conserver des branches inférieur à la semaine pour limiter les effets tunnels qui auront pour effet de compliquer l’intégration des changements et la collaboration dans l’équipe. Nous casserons donc une idée reçue ici : ce n’est pas parce qu’une user story n’est pas terminée qu’elle ne peut pas être intégrée au code commun. Il existe des stratégies comme le feature flipping pour le gérer.
Comment amener les changements dans le SI ?
Une vision pipeline pour lier le code au SI
Cette vision pipeline est naturelle pour les opérations, il faut s’en emparer côté SI. Un pipeline est un moyen de garantir un processus de livraison à plusieurs étapes qui va s’interrompre si un changement dégrade le système d’information. Un conseil pour cela : vous pouvez encourager les équipes à tirer partie des sondes de monitoring pour faire des assertions sur les opérations qu’un système doit supporter. Ces sondes portent une seule assertion, par exemple : “est-ce que j’arrive à lire et écrire des données clients sur la base de données”.
L’avantage est que ce contrôle peut être utilisé par le monitoring mais aussi par la pipeline de livraison continue sur tous les environnements, de la dev à la production. L’objectif est de couvrir le maximum d’opérations. Ce pipeline permet de limiter le risque dû aux déploiements dans le SI.
Maîtriser la re-construction d’environnements
Lorsqu’un nœud ou un service va arrêter de fonctionner, il peut arriver qu’on ne sache plus dans quel état est la configuration de nos environnements alors qu’on doit les remonter. Avec une vision transverse, l’architecte de SI est dans la bonne position pour challenger les équipes de développement & opération au travers de la pratique du Game Day. L’idée est de faire des simulations où l’on va provoquer des incidents sous forme de scénarios. Selon votre niveau de maturité, certains scénarios pourront être joués sur la production. Pour commencer faute de haute disponibilité, vos équipes pourront travailler à côté : la base de données est tombée, montez-en une autre à côté. On peut alors varier les scénarios et les jouer de manière régulière afin se perfectionner. Ici le rôle de l’architecte est important pour amener son savoir faire dans l'élaboration des scénarios.
Comment amortir l’impact des conflits entre différents services ?
Le Fail Safe Design pour amortir l’impact d’un service défaillant dans le SI
L’accélération du rythme des changements, même si ceux ci sont plus petits, peut conduire à l’illusion d’avoir un SI instable et incontrôlable. Pour y palier, le diagnostic et la gestion appropriée de la rupture de service deviennent des activités de design dans le processus de delivery. L’architecte de SI a un rôle de conseil auprès des PO et UX dans ces activités.
Un exemple : un service de moteur de recherche ne répond pas, ou répond mal - cela peut être un payload mal formaté, ou un champs qu’on ne sait pas interpréter. Le système consommateur va alors lever un drapeau rouge et donner une réponse adéquate au non fonctionnement de ce service. Cette réponse va assurer la continuité de fonctionnement du SI.
Diagnostiquer la rupture de service
Un pipeline de déploiement garantit l’état des services individuellement mais en aucun cas il ne peut assurer que le système au global va fonctionner. Le diagnostic de rupture du service nécessite d’adopter une stratégie de monitoring de type double mesure. La mesure côté consommateur et la mesure côté producteur du service de la disponibilité du service.
Une défaillance qui se déclenche dans un service côté consommateur, par exemple, un payload auquel il manque un attribut qui vient d’être décommissionné par l’équipe à l’origine du service risque des créer des erreurs difficiles à diagnostiquer. Les équipes de développement doivent prendre en compte ce diagnostic au sein du service consommateur, et permettre 2 choses : générer un événement métier pour dégrader le service, et remonter une alerte au SI.
La remontée d’alerte peut se faire via la télémétrie, l’exception management ou faute d’une infrastructure de monitoring suffisante, juste dans les logs.
Dégrader le service pour l’utilisateur
Une fois que la défaillance est diagnostiquée il faut être capable de dégrader le service. Cela ne veut pas dire ne pas répondre, ou propager un code d’erreur, mais bien amener une réponse toujours valide du point de vue usage.
Par exemple : mon système est sous l’eau et commence à répondre des code 503 (Non disponible). Le système au dessus doit proposer une réponse sous la forme de notification, ou par l’inclusion d’un bloc préparé à l’avance qui informe l’utilisateur de la situation. On cherche également à proposer une solution à l’utilisateur en lui laissant la possibilité de poursuivre sa navigation.
Le point clé : pour designer les modes dégradés de services, l’architecte doit travailler conjointement avec le PO et l’UX pour les aider à comprendre l’impact et la portée d’une défaillance sur le système globale.
Comment designer les modes dégradés avec le métier pour les utilisateurs ?
Le design collaboratif pour aligner les équipes
Il existe plusieurs outils pour faciliter ce design collectif. Pour designer des modes dégradés avec PO et UX, nous avons utilisé des ateliers de type Event Storming. C’est une manière de décrire un processus sous la forme d’événements et de commandes. La rupture de service peut se modéliser en tant qu’événement, géré de manière transverse, et être adaptée en user story. Comme le ticket amène une valeur métier, il va être intégré à la roadmap du produit.
Ce design collaboratif peut se faire au niveau de plusieurs équipes, notamment lorsque l’on travaille sur une chaîne de valeur complète.
En quelques mots
Notre DSI veut une mise en production par jour : en tant qu’architecte cela impacte la manière dont on collabore avec les équipes et la posture que nous allons adopter. Dans une culture cycle en V, la planification est une activité clé. L’architecte adoptera un modèle prescripteur. Dans une culture Agile, l’architecte intervient davantage dans l’opérationnel et adopter une posture consultative.. Dans une culture Agile & DevOps comme essaie de mettre en place mon DSI, l’architecte a une posture de coaching et d’accompagnement pour aider les équipes à s’aligner entre elles et faire évoluer le SI de manière coordonné. L’architecte interviendra de manière régulière dans une relation de proximité avec les équipes de développement sur un modèle proche de celui du Delivery Manager, de l’UX ou du coach agile.
L’architecte SI est un rôle qui dépends fortement de l’environnement dans lequel il s’effectue. Dans une culture Agile & DevOps, voici un résumé des 7 pratiques que nous vous encourageons à essayer :
https://www.youtube.com/watch?v=q9T4tl1tmAY&t=1s
Pour en savoir plus
CR Matinale OCTO : Accelerate, la vitesse conditionne l'excellence