Modéliser l'évolution de la donnée en entreprise
Contexte
Je suis un fervent défenseur du paradigme du data-mesh depuis sa première proposition par Zhamak Dehghani. Quatre ans se sont écoulés, et le paradigme du data-mesh a effectivement gagné une large acceptation. Cependant, je n'ai pas encore vu de plan de transformation de data mesh concis et pratique au sein d'une organisation.
Quand je dis "défenseur", je veux dire que j'ai souligné les avantages de ce paradigme, qui sont ancrés dans ses quatre piliers principaux :
- L'orientation de la conception vers les domaines
- L'application d'une approche produit aux données (les données en tant que produit)
- La gouvernance computationnelle fédérée
- Le développement de plateformes de données en libre-service
La question qui se pose naturellement après avoir compris ces quatre piliers est alors : par où commencer concrètement à mettre en œuvre le maillage de données ?
En principe, toute organisation peut entamer son voyage vers le data-mesh en se concentrant sur un de ces quatre piliers.
Commencer par une conception orientée domaine jette les bases d'une compréhension approfondie du data-mesh. Cela signifie non seulement de définir le maillage de données comme un objectif, mais aussi de s'assurer que la décomposition du domaine corresponde à la structure existante de l'organisation. Cependant, il s'agit d'une approche profondément conceptuelle qui pourrait ne pas donner de résultats immédiats, et qui, de plus, manque de l'agilité qui est si bénéfique.
La gouvernance computationnelle fédérée et la plateforme de données en libre-service sont simplement des facilitateurs du data-mesh. Ils partagent un objectif commun : simplifier le développement des données en tant que produit et la création d'interconnexions, soutenant ainsi le maillage. On peut essayer de les mettre en œuvre comme fondation, mais pour mailler quoi ?
Ce qui reste alors, c'est de s'attaquer aux données en tant que produit, une pierre angulaire du data-mesh dont j'ai déjà parlé sur le blog OCTO.
Il est intéressant de noter que plusieurs organisations affirment avoir mis en œuvre le data-mesh "par accident", percevant ce paradigme comme l'évolution naturelle de la gestion des données.
Dans cet article, je tente d'appliquer un modèle de progression évolutive bien connu pour comprendre l'évolution des données. L'objectif est d'aider à visualiser la maturité des données et d'aider les entreprises à identifier leur point de bascule, c'est-à-dire le moment où elles commenceront à constater des avantages significatifs de la mise en œuvre de contrats de données et du traitement des données comme un produit.
Modélisation de l'évolution
Je vais d'abord expliquer le modèle que je vais utiliser. Ce modèle est connu sous le nom de modèle d'évolution de Simon Wardley et est mis en œuvre avec succès dans les cartes de Wardley. Mon but ici n'est pas de décrire le paysage d'une entreprise spécifique, je n'aurai donc pas besoin d'une carte complète. Au lieu de cela, j'utiliserai le modèle d'évolution et j'essaierai d'appliquer sa fonction d'usage général aux données.
Avertissement : Concernant le modèle : La théorie de l'évolution est bien adaptée à une application dans un environnement concurrentiel où tout évolue en fonction de l'offre et de la demande. Je considère les entreprises soumises à ces contraintes de concurrence et, par conséquent, je considère que leurs données suivront également ces règles et que donc le modèle s'appliquera.
Pourquoi modéliser l'évolution ? Comprendre l'évolution, c'est comprendre comment les composants changent au fil du temps. Modéliser l'évolution, c'est trouver un schéma pour potentiellement fournir des informations sur les trajectoires futures de ces composants.
Le modèle en un coup d'œil
Simon Warldey avait besoin d'un moyen de représenter l'évolution des composants sur ses cartes. Il ne pouvait pas s'appuyer sur une échelle de temps car cela l'empêcherait de comparer des éléments hétérogènes et briserait la cohérence du mouvement.
Par exemple, sur une échelle de temps, la distance entre la genèse et la maturité d'une voiture (environ 100 ans) aurait été beaucoup plus grande que la distance entre les mêmes points pour un smartphone (environ 10 ans). Il a découvert que l'évolution est une fonction de son ubiquité et de sa certitude.
Dans une économie de marché, l'ubiquité est menée par la demande. Plus de demande induit plus de présence. C'est une déclinaison de la théorie de la diffusion des innovations de Rogger. La certitude vient de la matrice de Stacey. La matrice postule qu'à mesure que la disponibilité des composants ou des informations clés augmente, la certitude concernant les résultats de la prise de décision augmente également, ce qui permet une planification et une exécution plus prévisibles et éclairées. En un sens, la certitude est pilotée par l'offre.
Par exemple, prenons une entreprise manufacturière qui produit des gadgets électroniques. Dans ce scénario, l'un des composants essentiels dont ils ont besoin sont les puces semi-conductrices. Lorsque l'offre de ces puces est faible en raison de pénuries sur le marché ou de problèmes logistiques, l'entreprise est confrontée à une grande incertitude quant à ses calendriers de production et à sa capacité à répondre à la demande des clients.
Une analyse empirique a conduit à cette représentation :
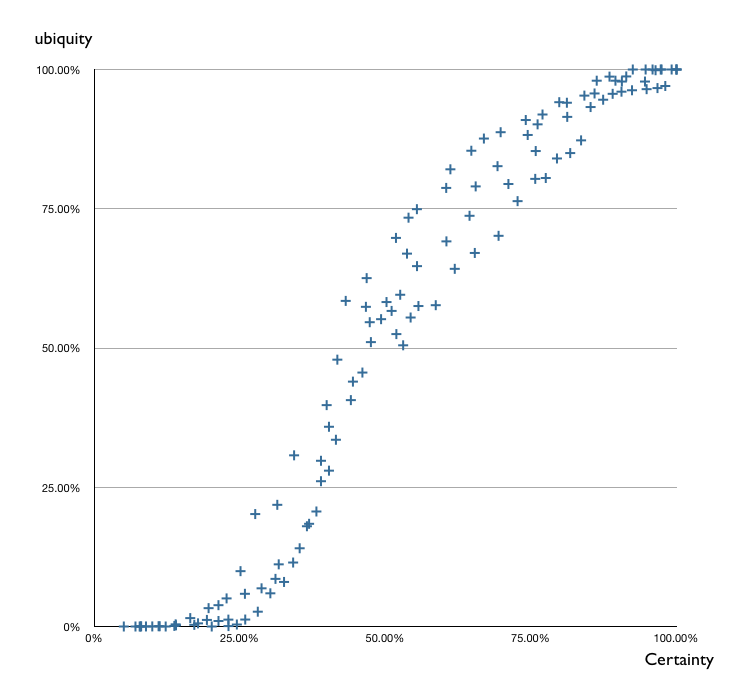
(source blog de Simon Wardley.garvediance.org)
Le modèle est une sorte de courbe en S.
Le modèle des données selon Wardley
L'analyse du modèle a permis de formaliser quatre étapes d'évolution étiquetées par défaut Genèse, Construction sur mesure, Produit et Marchandise :
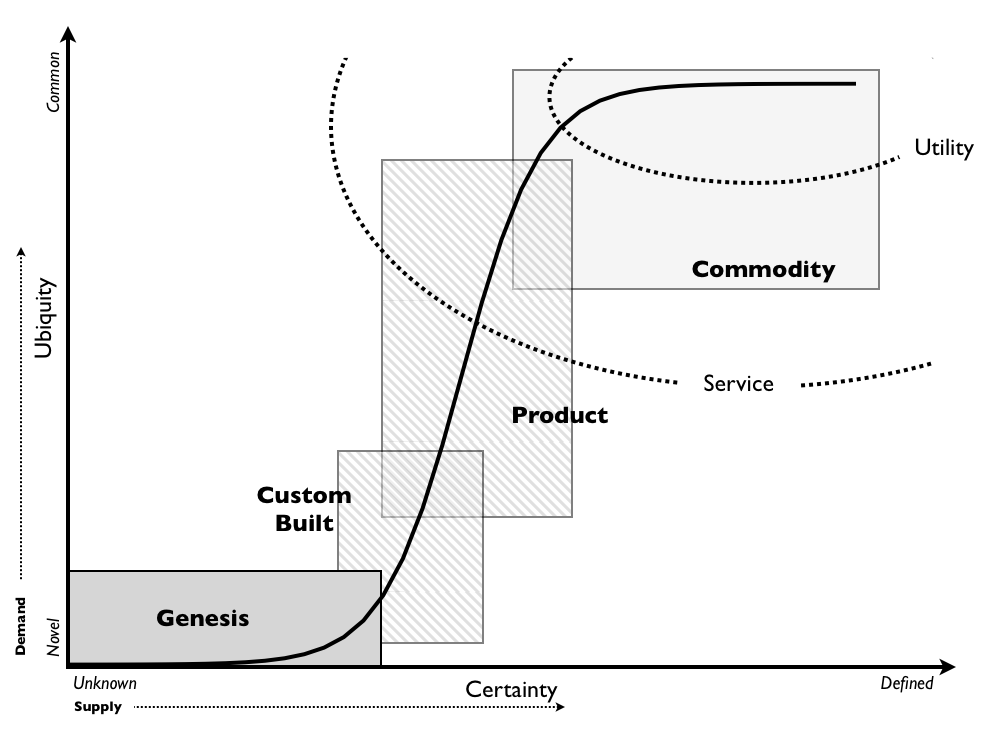
Ce ne sont que des étiquettes courantes pour une certaine forme de produits.
Pour les données, selon la théorie de Wardley, les étiquettes des quatre étapes sont : __Non modélisées, divergentes, convergentes et modélisées__ : 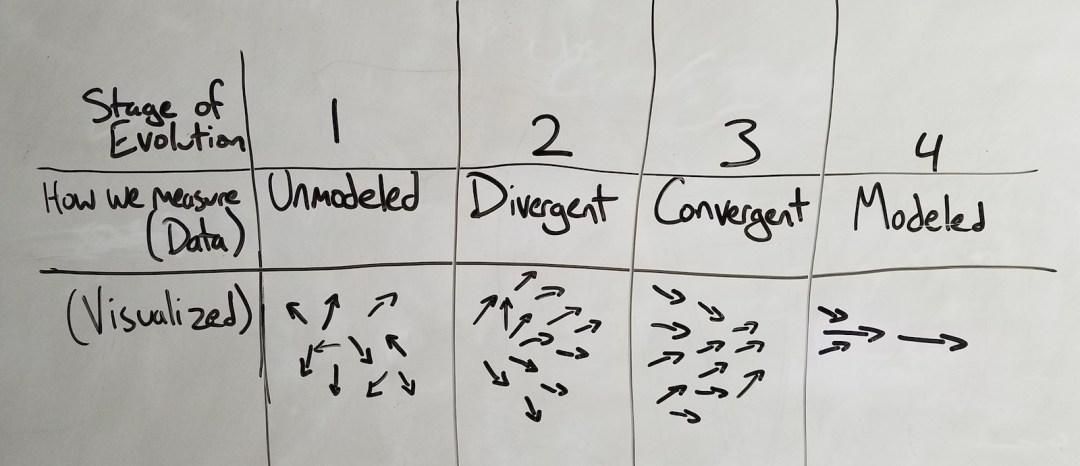
Dérivation du modèle
Certitude des données
Revenons au mécanisme de certitude pour déterminer si nous pouvons ajuster le modèle pour tenir compte de l'évolution des données au sein d'une entreprise. Je considère la certitude comme l'équivalent du niveau de confiance dans la décision prise sur la base de ces données. Voici les étiquettes que j'utiliserai :
- Données brutes : D'après mon expérience, les données commencent à l'état brut pendant la phase exploratoire. Elles manquent d'ubiquité, résidant uniquement dans la base de données et accessibles uniquement via un service et/ou une API, essentiellement un produit de données (un produit piloté par les données).
- Données organisées : Ceci marque la deuxième étape de la certitude des données. Des experts en données entrent en jeu pour garantir l'exactitude et la pertinence de la représentation des données pour l'entreprise.
- Autoritaires : La dernière étape de la certitude. Les données sont pertinentes, complètes, cohérentes, documentées et approuvées par des experts du domaine.
Les données brutes correspondent à la première étape de l'évolution. C'est une étape où nous définissons des preuves de concept par exemple. Ensuite, les données organisées sont liées aux phases deux et trois. Et finalement, la dernière étape est lorsque les données sont autoritaires.
Les étiquettes des quatre étapes de l'évolution
Concernant la notion de certitude et d'ubiquité, catégorisons les 4 étapes de l'évolution :
- POC : Cette étape implique la validation de concepts.
- Application : Dans cette étape, les données sont étroitement liées à un cas d'utilisation spécifique.
- Domaine : C'est là que cela devient intéressant : les données représentent une solution qui peut être utilisée pour traiter divers cas d'utilisation au sein du même domaine (considérez le domaine comme un espace de problèmes, similaire à celui du DDD).
- Entreprise : Cette étape englobe tous les domaines, représentant le total de tous les problèmes traités par une entreprise.
Voici la représentation de ces éléments sur un diagramme :
La représentation
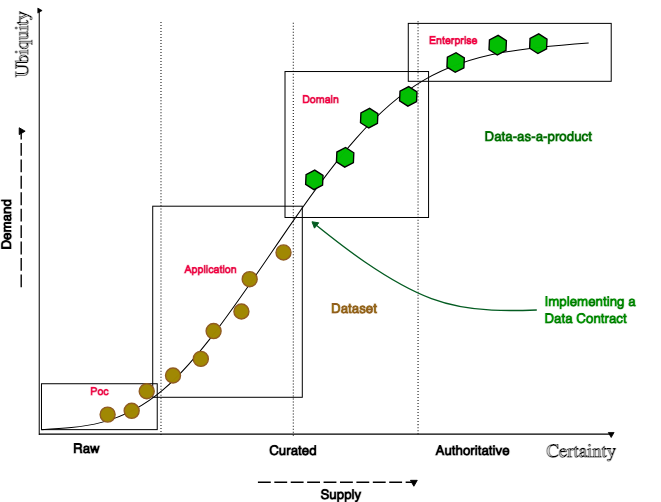
Utilisation du diagramme : Les données en tant que produit et contrat de données
Maintenant, utilisons le diagramme.
Les données suivront probablement la courbe en S de l'évolution. Ce qui est intéressant, c'est l'évolution des propriétés des données. Transformer des données brutes en données organisées est maîtrisé. Il existe des processus de conception majeurs qui sont utiles dans une telle transition.
Transformer les données organisées en données autoritaires implique que les données sont accessibles et utilisables, maintenues, exactes, mais le changement principal est que les données sont approuvées par des parties de confiance. À l'échelle de l'entreprise, cela signifie que le domaine est responsable et redevable de ses données, car le domaine est, par défaut, une partie de confiance dans l'organisation concernant un domaine d'activité spécifique.
La transition n'est pas si nette lorsque les données quittent leur prison : lorsqu'elles sont exposées au domaine.
C'est le point où la pensée produit appliquée aux données apporte de la valeur. Et c'est le point où un contrat de données est utile pour :
- Faciliter l'intégration dans d'autres cas d'utilisation du domaine
- Apporter de la confiance dans les données
Par conséquent, considérer les données comme un produit, comme tout autre produit, est quelque chose qui est nécessaire dans la phase d'exploration (cela peut même être considéré comme de la sur-ingénierie), mais le modèle illustre à quel point il est important de traiter les données comme un produit pour servir un objectif général à l'entreprise.
Conclusion
En résumé, je me suis toujours débattu avec une question : par où commencer lorsqu'on cherche à mettre en œuvre le paradigme du data-mesh ? Tout au long de l'exploration de ce concept, ma plus récente et profonde intuition est la suivante : le point de départ le plus stratégique réside dans lle fait de considérer la donnée comme un produit.
Le modèle présenté souligne le rôle essentiel du produit de données. Il est projeté comme une solution efficace à un problème impératif : son importance significative devient évidente lorsque les données migrent d'une seule sphère d'application vers un domaine plus large. Au-delà de cela, il devient absolument essentiel lorsque les données sont censées fournir une valeur tangible qui dépasse son domaine original.
La prochaine phase de notre parcours dans la compréhension du paradigme du data-mesh implique la formalisation d'une méthode pour évaluer avec précision la maturité des données. En examinant chaque élément de données, contrat par contrat et domaine par domaine, nous nous rapprochons de la construction d'un maillage complet et efficace. Tout au long de ce processus, il est crucial de se rappeler de considérer les données comme un produit. Ce faisant, une organisation en récoltera les fruits à mesure qu'elle évolue et gagne en maturité dans ses stratégies de gestion des données.