Modèle embarqué VS model as a service : quelle stratégie choisir ?

Introduction
Vous avez développé un super modèle de Machine Learning, les performances sont au top et il résout un vrai problème. Malheureusement, personne n’en aura jamais connaissance si vous ne le déployez pas en production. Votre modèle n’aura été qu’un POC parmi tant d’autres et ne créera jamais de valeur pour l’entreprise et pour vos utilisateurs.
Il y a quelques années, alors que les modèles n’étaient que très rarement déployés en production, la question de l’exposition était souvent anecdotique. Avec la croissance grandissante des projets de machine learning dans les entreprises, comme le rapporte Forbes dans un article publié en 2020, il a fallu trouver un moyen de structurer cette discipline avec des méthodologies inspirées du software engineering, telle que le MLOps, qui évite d’une part de mettre un mur entre les data scientists et la mise en production de leur modèle et qui permet d’autre part d'automatiser les tâches liées à la gestion du cycle de vie des différents modèles.
À la manière d’une application que l’on déploie, l’exposition du modèle de machine learning est un point critique. Le choix de la stratégie à adopter pour cette étape clé qui va permettre l'interaction entre le modèle et les utilisateurs repose sur plusieurs facteurs :
- Complexité de mise en place de l’infrastructure d’exposition
- Le couplage entre les briques applicatives du projet
- Ressources nécessaires (expertise, budget, temps de mise en place)
- Robustesse (résistance aux pannes, haute disponibilité)
- Maintenance (débugage, mise à jour, amélioration)
Comment choisir entre modèle embarqué et model as a service en fonction de ses besoins, de ses ressources et de la complexité ?
Contexte
Pour illustrer cet article, nous avons choisi un sujet d'actualité :
la classification d’images pour le tri des déchets, l’un des fers de lance de l'amélioration et l'évolution du recyclage. À titre d’exemple, “en France, en 2020, 68 % des emballages ménagers ont été recyclés soit 3.7 millions de tonnes” [1]. Le machine learning aide à améliorer ce taux en prédisant les classes de chaque déchet (plastique, verre, carton, papier, métal…).
Afin de simplifier la compréhension, nous prendrons l’exemple d'une simple application permettant la prédiction de ces classes.
Cette prédiction sera permise par l'interaction de trois briques :
Un front permettant l'interaction avec l’utilisateur (envoyer une photo de déchet, visualiser les résultats)
Un back permettant la gestion de l’image envoyée (traitement de l’image)
Un modèle qui va prédire la classe de l’image
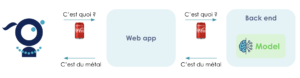
Illustration des différentes briques du système
1ère stratégie : Le modèle embarqué
La plupart du temps, après avoir fait de l’analyse de données et plusieurs tests de modélisation sur un notebook jupyter, on décide de sauvegarder le modèle qui nous convient le mieux. Souvent, il est sauvegardé au format pickle ou bien h5.
On se retrouve donc avec un artefact, notre modèle. Et l’on souhaite créer de la valeur le plus rapidement et le plus simplement possible en l’exposant.
Pour cela, il suffit de déplacer et stocker notre modèle directement au niveau des fichiers de notre application. Ainsi, lorsqu'un utilisateur demande une prédiction depuis le site web, sa requête va transiter par le back qui va faire la prédiction et la renvoyer pour l’afficher sur le site web.
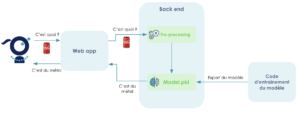
Illustration de la stratégie du “modèle embarqué”
Il s’agit de la méthode d’exposition appelée “modèle embarqué” ou “embedded model” en anglais.
C’est un moyen simple et efficace d’exposer rapidement un modèle à des utilisateurs. En effet, une fois la première version du modèle entraînée, il suffit de le sérialiser et de l’embarquer dans une application pour permettre l'interaction avec le modèle. Il n’y a donc pas besoin d’une infrastructure complexe ou lourde à déployer.
En mettant rapidement notre modèle en production, en plus de créer de la valeur immédiatement, cela nous permet d’appréhender plus vite des chantiers futurs tels que :
- Collecte de nouvelles données
- Monitoring
- Boucle de feedback
Les limites du modèle embarqué ?
Les limites du modèle embarqué sont chacune engendrées par une caractéristique propre à cette stratégie : le couplage entre la partie ML et applicative.
La raison est simple : un modèle a un cycle de vie intrinsèquement différent d’une application.
Pour illustrer cela simplement, reprenons notre projet de classification de déchets.
Nous avons détecté une baisse de performance de notre algorithme sur le métal, certaines canettes sont classées en tant que “verre”. En effet, les canettes de coca arborent un nouveau look pour Noël, ce qui implique une mauvaise classification de l’algorithme. Nous souhaitons pouvoir pousser en production notre nouveau modèle ré-entraîné, sans affecter l’application, les utilisateurs et les développeurs des autres briques applicatives.
Or pousser un nouveau modèle en production implique souvent l’évolution de tout un écosystème autour de l’algorithme (Validation des données, Versionning de modèles, Evaluation, Monitoring…). Cette évolution de l’écosystème est évidemment plus complexe quand celui-ci est couplé à une application elle-même déjà complexe. C’est certes possible, mais beaucoup plus laborieux et des contraintes supplémentaires viendront s’ajouter au redéploiement du modèle telles que :
- La gestion de l’interruption de service de notre application qui sera plus délicate. (ex: canary déploiement)
- Le couplage organisationnel des équipes qui devront se coordonner lors du redéploiement d’un modèle même si elles ne sont pas directement impliquées par ce changement.
- L’allocation des ressources ne pourra se faire de façon optimale. En effet, faire des prédictions peut demander des capacités de calculs et des ressources spécifiques (mémoire, GPU, etc.) qui ne sont, en aucun cas, comparables à celles par exemple d’une simple web application dans notre cas.
La stratégie du modèle embarqué peut donc devenir un fardeau dès lors que le modèle exposé est amené à évoluer, ce qui est tout de même censé être l'essence d’un modèle en production.
2e stratégie : Model as a Service
Les faiblesses du modèle embarqué énoncées précédemment nous amènent souvent à reconsidérer comment mieux exposer notre modèle de manière à ce que l’évolution et le redéploiement de notre algorithme soient plus efficaces pour toutes les parties impliquées : les utilisateurs finaux qui utilisent le modèle ainsi que les développeurs_._
Comment faire pour livrer un nouveau modèle de manière optimale, plusieurs fois par mois, semaine, voire jour ?
Comment tester un modèle en shadow production, ou bien faire de l’A/B testing ?
Comment avoir une infrastructure adaptative à nos besoins ?

L’équipe technique prenant en compte les différents besoins
Répondre à ces questions avec un modèle embarqué est compliqué, car elles nécessitent un découplage de la partie applicative et ML.
Introduisons donc une méthode d’exposition appelée Model as a Service. Comme son nom l’indique, il s'agit d'exposer un modèle comme un service à part entière, généralement via une API.
Pour illustrer cette méthode, reprenons le cas de notre application de classification de déchets.
L’utilisateur upload une image via une application web, celle-ci est pré-traitée dans le backend-end et ensuite envoyée au service dédié à l’inférence via une requête POST. Le résultat de la prédiction est ensuite renvoyé par l’API et affiché par notre front.
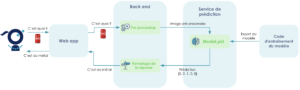
Illustration de la stratégie “model as a service”
Le model as a service introduit donc plusieurs avantages permettant de faire évoluer notre infrastructure de ML et scaler en conséquence comme :
- Avoir la liberté de déployer de nouveaux modèles de manière indépendante par rapport aux autres briques applicatives. Et ainsi simplifier le changement de modèle en production.
- Scaler les infrastructures en fonction des besoins respectifs des briques, le front aura peut-être moins besoin de ressources que l’exposition du modèle qui aura besoin de puissance pour faire le pré-processing et les prédictions rapidement.
Parlons pour finir des points faibles de cette approche :
- Il s’agit d’une méthode plus longue et plus coûteuse à mettre en place, car nous ajoutons des briques à notre projet. Ainsi, l'infrastructure est plus complexe à maintenir et cela peut demander de nouvelles compétences dans l’équipe. Le maintien en condition opérationnelle de ce service demande d’être attentif à sa santé, avec tout ce que cela implique, monitoring et alerte par exemple.
- Une nouvelle dépendance entre 2 applications qui communiquent par le réseau augmente le risque d’une rupture de service.
Conclusion
Comme nous avons pu le voir à travers cet article, exposer son modèle pour le rendre disponible en production dépend de plusieurs facteurs tels que l’avancement du projet ou les ressources.
Lorsqu’un projet débute et qu’on veut rapidement créer de la valeur en mettant en production notre modèle, on préférera la stratégie du modèle embarqué qui a l’avantage d’être simple et rapide à mettre en place. Après plusieurs entraînements sur un notebook, il suffira de sérialiser le modèle pour l’embarquer au projet afin qu’il soit directement mis en production.
Lorsque le projet avance et que nous voulons enrichir notre écosystème de Machine Learning en ajoutant par exemple du réentraînement, de la validation de donnée, ou bien de l’évaluation de modèle, il est plus facile de le faire lorsque nos briques sont correctement découplées et que les changements n’affecte que la brique concernée. De plus, cela permet d’allouer les ressources de façon pertinente aux différentes briques en fonction de leurs besoins. Pour finir, le découplage amène une plus grande liberté d’action à chacune des équipes travaillant sur le projet que ce soit pour l’ajout de nouvelles fonctionnalités ou l'allocation de ressources.
Une stratégie d’exposition peut et doit évoluer dans le temps pour répondre à de nouveaux besoins au fur et à mesure que ceux-ci émergent.