[MLOps] Monitoring & proactive notification d’une application de Machine Learning
En tant que développeur d’application embarquant une brique de Machine Learning notre principal objectif est d’avoir une application utilisée qui fonctionne sans bogue.
Une fois en production et utilisée, il faut anticiper ou identifier les bogues dans notre application et les résoudre au plus vite, afin de maintenir le service rendu et en tirer réellement profit.
Nous détaillerons plus précisément la notion de bogue en ML, mais pour commencer nous pouvons dire qu'un bogue en ML est soit une absence de prédiction, soit une erreur de prédiction acceptable mais trop fréquente soit une erreur de prédiction inacceptable.
Les bogues en Machine Learning (“ML” dans le reste de l’article) peuvent coûter très cher. Nous pouvons citer deux exemples parus ces dernières années dans la presse :
- Le cas Zillow : une entreprise qui achète des biens immobiliers “cash” pour les revendre après. Pour faire cela, elle a un modèle de ML qui prédit le prix des biens. À un moment donné, ce modèle s’est mis à prédire des prix trop élevés si bien qu'elle a acheté facilement de nombreux biens sans réussir à les revendre. L’impact immédiat est une immobilisation forte de capitaux et à moyen terme des ventes à perte. L’impact de ce bogue a été tellement important que l’avenir de l’entreprise a été remis en question et sa stratégie a été radicalement repensée. A posteriori, nous pourrions dire qu’ils ont grâce aux outils mis en place détecté assez tôt le problème en donc évité la faillite, mais identifier ce bogue encore plus tôt aurait été bien mieux. (Pour aller plus loin)
- La situation de Lyft en plein covid : Lyft est une société de VTC. Pour déterminer le prix des courses, elle utilise un modèle de pricing qui a comme variable le délai d'arrivée du chauffeur à votre localisation. En période de covid le trafic routier ayant fortement diminué, ce délai a diminué et donc tous les prix ont fortement diminué. Sans identifier ce bogue tôt, Lyft aurait pu perdre beaucoup d’argent et des chauffeurs. (Pour aller plus loin)
Maximiser l’utilisabilité du service (au sens de disponible et sans bogue) revient à raccourcir au plus court le temps entre le moment où un bogue apparaît, et le moment où il est corrigé. Ce délai se décompose en trois : le délai pour identifier le problème, le délai pour le diagnostiquer (passer de problème à cause) et le délai pour corriger (à la fois coder la correction et la déployer).
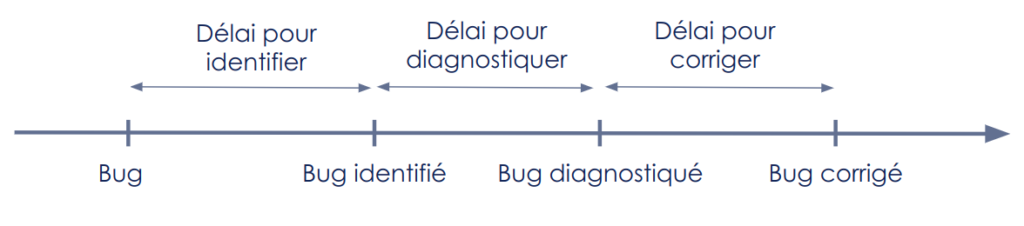
Figure 1 : Représentation du temps passé entre l’apparition et la résolution d’un bug
Monitoring et notification proactive visent à minimiser le délai pour identifier et peut avoir un impact positif sur le délai pour diagnostiquer en donnant des alertes précises. Le délai pour corriger lui sera diminué grâce à de nombreuses pratiques tels que les tests, le découplage de l’architecture, la CI/CD…
ML et erreur : une relation compliquée
Fonctionner n’a pas le même sens en ML
En Machine Learning nous décrivons comme erreur les inférences où le modèle ne fait pas la “prédiction idéale”. La prédiction idéale est la prédiction que l’on aurait aimé que le modèle fasse afin de maximiser l’impact du système. Elle n’est pas accessible au moment de l’inférence. (Cela a été défini dans cet article).
En logiciel sans ML, il est raisonnable de viser une application avec 0 erreur. En Machine Learning ceci est inimaginable, l’erreur est inhérente, les modèles feront toujours des erreurs. La question n’est donc plus “y a t-il des erreurs ?” mais “y a-t-il trop d’erreurs ?”.
Si vous vous trouvez dans une situation où votre modèle ne fait pas d’erreur, c’est soit que le problème aurait pu être résolu avec des règles métiers, soit qu’une erreur de modélisation a été commise.
En plus d’avoir nécessairement des erreurs, en ML, nous pouvons constater ces erreurs qu'a posteriori et parfois longtemps après que la prédiction ait été donnée.
Les raisons d’apparition des erreurs
Pour identifier efficacement les bogues en production, il est important d’avoir conscience des différentes sources d’erreurs.
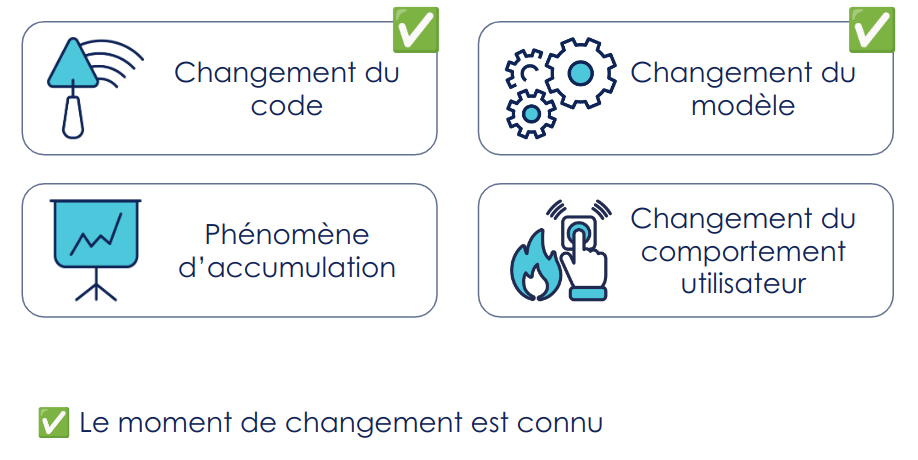
Figure 2 : différentes raisons pour lesquelles l'application peut dysfonctionner
Les deux premières sources d’erreurs potentielles sont des changements dont le moment d’apparition sont connus :
- Changement du code : comme en logiciel sans ML, le déploiement d’une nouvelle version du code peut causer l’apparition d’erreurs.
- Changement de modèle : après un réentraînement, si l’on choisit de mettre en production un nouveau modèle, des erreurs peuvent apparaître, par exemple s'il est moins performant pour certaines prédictions que le précédent modèle.
La troisième est “facilement” anticipable, il s’agit des phénomènes d’accumulation. Un exemple classique en logiciel est le fait d’avoir une base de données pleine. En ML, cela peut avoir lieu lorsque l’on réalise du Continuous Training (entraînement continu) où à chaque inférence le modèle est légèrement modifié. Par exemple, si une classe n’apparaît pas dans les données depuis un moment et qu’un mécanisme de sous pondération pour les observations anciennes est mis en place au moment du réentraînement alors au bout d’un certain temps le modèle ne prédira plus du tout cette classe même si cela aurait été pertinent.
La dernière et la plus dure à anticiper : il s’agit de changement de comportement des utilisateurs.
- En logiciel sans ML, il peut s'agir par exemple de publier plus des photos ou des mini-vidéos plutôt que du texte sur les réseaux sociaux. Cette source de changement est souvent ignorée, car difficile à mesurer. Une différente ou une non-utilisation du service a pour impact principal une évolution de la charge sur l’infrastructure. Les actions à mettre en place sont un monitoring des ressources ou un auto-scaling.
- En ML, le changement du comportement utilisateur peut avoir un impact beaucoup plus fort. Le changement de la typologie des utilisateurs, ou de leur façon d’utiliser, résulte dans un changement dans les distributions des données (data drift) ou dans la relation à la prédiction (concept drift) (Pour approfondir Introducing Concept Drifts). Ceci impactera les performances du modèle (c’est à dire qu’il fera plus fréquemment des erreurs). Ce changement est fréquent et complètement non maîtrisé par les développeurs. Il est donc extrêmement important d’en être vigilant.
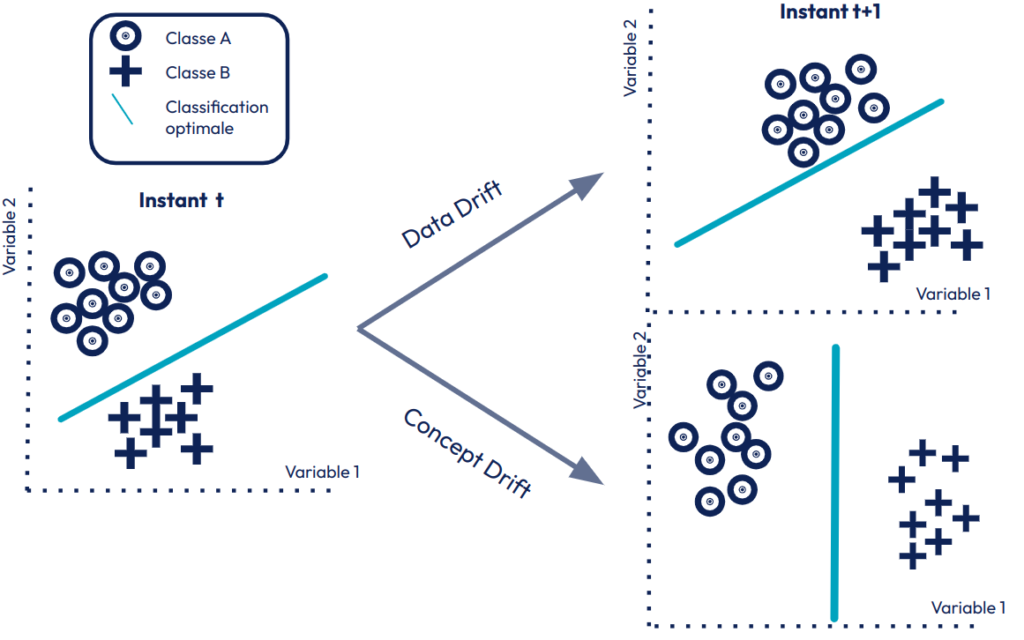
Figure 3 : Illustration des data drift versus concept drift
Les changements sont sécurisables avant d’aller en production : le code peut être testé, les modèles validés sur des données de tests, nous pouvons réaliser des canary releases… Mais ces sécurisations ne seront jamais exhaustives, le monitoring est donc clef pour attraper les erreurs non identifiées.
NB : Une représentation classique des sources de changements est code, modèle et données. Nous avons choisi dans cet article de répartir d’une manière plus actionnable d’un point de vue monitoring. Les changements dans les données sont inclus dans les phénomènes d’accumulation, dans les changements du code (en introduisant une représentation différente des mêmes informations, ou un changement du métier) et dans les changements des comportements utilisateurs.
Les différents type d’erreurs
Sachant que l’on a nécessairement des erreurs, il convient d’identifier les différents types d’erreurs possibles, celles à éviter absolument, celles à éviter si elles sont trop fréquentes.
Au-delà des erreurs de code, des erreurs lors du déploiement (pipeline de CI/CD rouge) mais aussi les hotfixes qu’on doit réaliser suite à un déploiement causé par des régressions nécessitant des actions, intéressons-nous aux erreurs de ML en particulier.
Nous pouvons séparer les erreurs en 4 catégories présentées dans la figure ci-dessous :

Figure 4 : Représentation des 4 types d’erreurs que l’on peut rencontrer en ML
Pour illustrer ces erreurs, voici un exemple par catégorie :
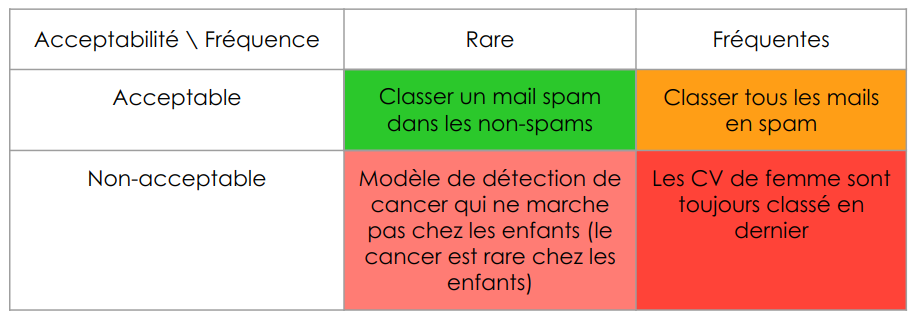
Figure 5 : Exemple d’erreurs par type
Nous pouvons maintenant donner une définition formelle de bogue en ML :
Nous disons qu’il y a un bogue en Machine Learning lorsque le système ne donne pas de prédiction alors qu’elle est attendue, lorsque le modèle réalise trop fréquemment des erreurs acceptables, lorsque le modèle réalise au moins une erreur inacceptable.
Les conséquences de cette relation à l’erreur
Cette relation “compliquée” à l’erreur a des conséquences importantes sur le maintien en condition opérationnelle de nos modèles.
Le traitement des erreurs est plus complexe :
- Il est souvent impossible de réagir dès la première erreur.
- Il est difficile de prendre une décision en se basant sur une erreur particulière : il faut faire des statistiques.
- La séparation entre bogue et demande d'évolution est encore plus floue qu’en logiciel (Si le modèle se trompe sur telle catégorie de situations, est-ce un bogue ou un nouveau besoin métier ?). D’ailleurs souvent, l’action de débogage et d’ajout d’une nouvelle fonctionnalité est la même : refaire un entraînement en ayant modifié le jeu de données d’entraînement.
Les métriques sont changées. Les métriques de stabilité proposées par Accelerate (mean time to repair et change failure rate) sont à redéfinir en fonction des erreurs considérées. Le délai pour identifier les problèmes est allongé. En machine learning le temps pour avoir un coup de téléphone parce qu’un système bogue est plus lent que celui du logiciel sans ML. Par exemple, pour identifier qu’un modèle d’octroi de crédit n’a pas réalisé la prédiction idéale, il faut attendre plusieurs mois avant que le client soit défaillant.
Ainsi la question du monitoring devient centrale pour suivre les "bogues" qui viennent progressivement dans le temps. Laisser un modèle en production sans le monitorer est une erreur grave. Cela nous pousse à shift right : aller vite en production pour tester un certain nombre d'hypothèses. Dans la plupart des cas, les tests Shift Right vont mettre en évidence des dysfonctionnements du côté de la donnée ou de l’infrastructure.
Le monitoring
“Le monitoring s’intéresse aux capacités de mesure et de débogage d’un système. L’équipe dispose-t-elle de moyens de suivi de l’état de ses ressources, services et applications ? L’équipe dispose-t-elle de moyens de recueil et de collecte d’informations (métriques, traces, logs) facilitant l’investigation et le débogage de ses systèmes ?” (source)
Le monitoring est en fait un maillon de la chaîne des boucles de feedback; c’est le test ultime.
“Monitoring. Yes, monitoring is a test too, or rather tests and monitoring are both forms of feedback. Monitoring abandons being predictive and to some degree being automated (modulo alerting).” Kent Beck
Que mesurer ?
En fait, se demander ce que nous souhaitons mesurer pour nous assurer que le modèle fonctionne bien revient à définir des Service Level Indicator (SLI). La notion de SLI est proposée par le domaine du SRE (Site Reliability Engineering). Il s’agit d'indicateurs choisis soigneusement pour décrire une partie du niveau de service rendu aux utilisateurs. Un SLI classique est la disponibilité. Pour approfondir cette notion, vous pouvez lire le chapitre 4 du livre Site Reliability Engineering par Betsy Beyer & Al.
Les métriques que nous serons amenés à définir pourrons être préventives (anticiper les problèmes) ou réactives (identifier les problèmes dès qu’ils arrivent).
Nous cherchons à choisir des bonnes métriques, c’est-à-dire des métriques :
- mesurables
- corrélées à un objectif organisationnel
- ne poussant pas à l’optimum local
- amenant un feedback rapide
- amenant un feedback qui permet d’agir / de prendre des décisions.
Les métriques métiers
Souhaitant des métriques corrélées à un objectif organisationnel, il convient de commencer par les métriques métiers.
La plus importante, north star metric, est l’objectif de l’organisation (l’argent pour les entreprises, minimiser le nombre de demandeurs d’emploi pour Pôle Emploi, …)
Nous sommes souvent amenés à prendre des proxys (approximations) de cette north star metric car elle est souvent très difficile à mesurer. Les boucles de feedbacks qui nous intéressent le plus sont souvent les plus chères et les plus lentes, il faut des proxys pour s’assurer que lorsque l’on aura le feedback, il sera bon. (L’article Data science en production : les difficultés pour récupérer la prédiction idéale explique en quoi les feedbacks en ML peuvent être long).
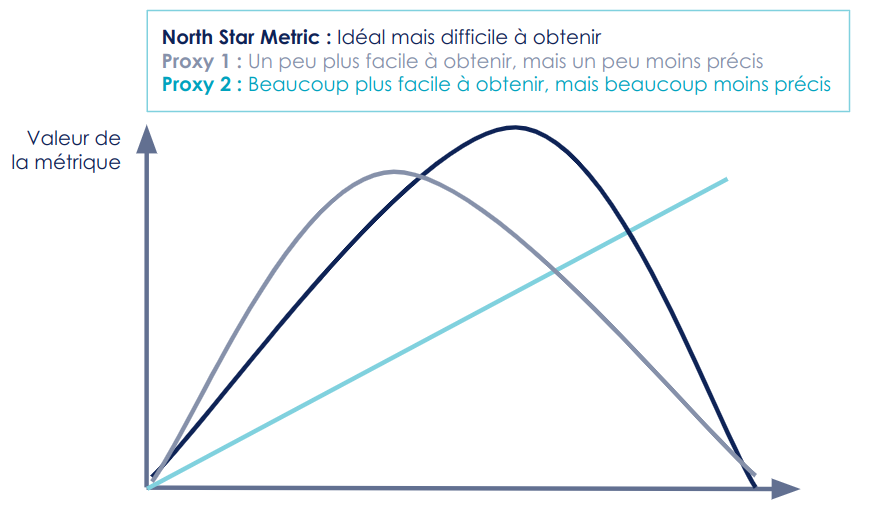
Figure 6 : Illustration de la north star metric et de différents proxys
Pour trouver de bons proxys, il faut les construire avec le métier. Par exemple en réalisant un atelier matrice d’erreur (L’atelier matrice d’erreur : démystifier les performances du ML avec ses utilisateurs) .
Détaillons ci-dessous deux exemples en donnant la north star metric et les proxys envisageables.
Exemple 1 : Réaliser + 10% de bénéfices par rapport à l’année précédente
L’objectif est d’augmenter les bénéfices. Pour cela, nous pouvons proposer un modèle qui vise à cibler les bonnes personnes pour une campagne d’emailing afin d’augmenter les ventes.
La métrique de pertinence de ce modèle serait les bénéfices générés par cette campagne.
Comme cela est difficile à mesurer (en effet, traquer quelle vente est réalisée grâce à la campagne et quelle vente aurait eu lieu même sans campagne n’est pas évident), nous pouvons prendre le proxy raisonnable suivant : Le nombre de ventes suite à clic sur un lien dans notre mail. Ce proxy nous fait, cependant, perdre les personnes qui achètent grâce à la campagne, mais quelques jours plus tard en accédant directement au site.
La métrique la plus simple à suivre est le taux d’ouverture de mail, mais ce proxy est assez lointain du besoin métier : un titre accrocheur peut causer un grand nombre d'ouvertures sans générer aucune vente.
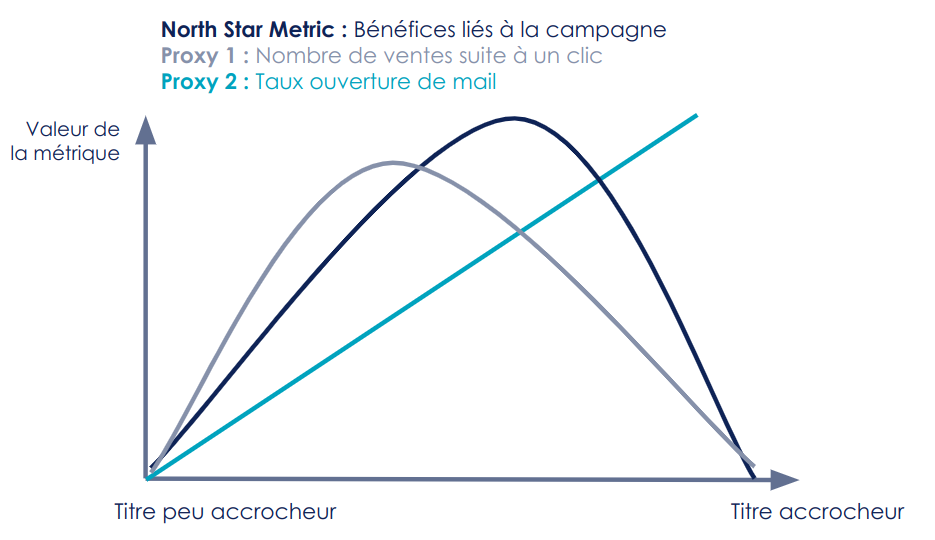
Figure 7 : Illustration de proxys qui sont corrélés à la north star metric, mais qu’ils convient de ne pas sur-optimiser
Exemple 2 : Diminuer le nombre de demandeurs d’emplois grâce à la formation
L’objectif est de diminuer le nombre de demandeurs d’emploi. Le modèle que l’on peut construire est un moteur de recommandation de formations pour maximiser le retour à l’emploi.
La métrique pour mesurer l’intérêt réel du modèle est le nombre de retours à l’emploi provoqués par des recommandations de bonnes formations.
Les différents proxys que l’on peut prendre sont le nombre de formations sur lesquels les demandeurs d’emploi s’inscrivent, puis le nombre de formations réellement suivies, puis le nombre de retours à l’emploi dans un emploi en lien avec cette formation.
NB : Selon les contextes, l'utilisateur peut avoir un rôle clef pour accélérer ces boucles de feedback. Notamment en lui proposant de signaler des erreurs de prédictions.
NB 2 : Les métriques métiers sont plutôt réactives, elles ne permettent pas d’anticiper les problèmes mais de les détecter.
Les métriques techniques
Le monitoring technique se décline en 3 grands pans : l’infrastructure, les données et le modèle.
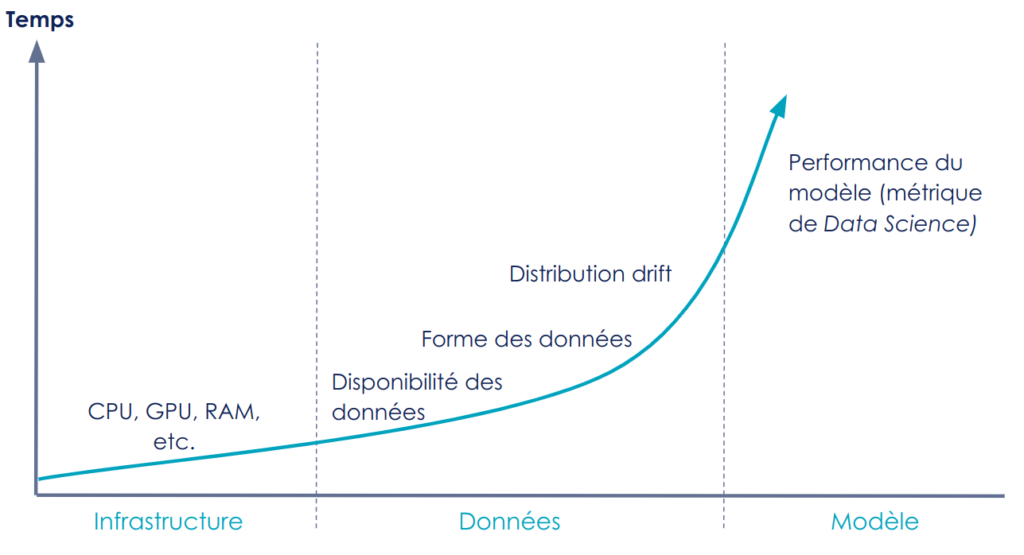
Figure 8 : Différentes techniques de monitoring en Data Science
Les métriques peuvent-être préventives, c’est à dire qu’elles permettent d’anticiper un problème, ou réactives, c’est à dire qu’elles permettent de détecter un problème en cours.
Le monitoring de métrique système (incluant CPU, GPU, RAM, …) doit être un non-sujet pour les Data Scientist. Il est souvent déjà mis en place par les équipes qui fournissent la plateforme ou à travers des services managés. Avoir ces métriques mises en place, disponibles et accessibles est un prérequis au déploiement de modèles de ML en production. Ces métriques sont préventives, être alertés lorsque nous sommes proches des 100% d’usage nous permettra d’augmenter la puissance disponible avant que le système soit défaillant.
Le monitoring des données se fait à plusieurs niveaux, au niveau du flux de données (Ex de métrique réactive : Est-ce que les données arrivent correctement dans mon système d’inférence ?), de la préparation de données (Exemple de métriques réactives : les données ont-elles la forme attendue ? les bonnes colonnes ? les bonnes modalités dans les colonnes ?), et enfin en entrée du modèle (Exemple de métrique proactive : la donnée utilisée pour prédire ressemble-t-elle à celles utilisées en entraînement, ou y a-t-il un drift de données ?).
Comme évoqué dans l’article “Une alternative au monitoring de distributions”, il faut être vigilant à ne pas monitorer des distributions de données dans tous les sens au risque d’avoir tellement d’indicateurs que l’on ne puisse plus en tirer de conclusions sur l’état du système. Si les données proviennent d’une source sûre gérée par des équipes matures en termes de monitoring, il est possible de leur faire confiance et limiter le monitoring des choses en double. Si vos données viennent d’un système cœur de votre organisation, (ex le système de virement inter-comptes pour une banque), alors vous pouvez sans doute faire confiance à la qualité de données, ou plus exactement il existe sûrement une équipe qui s’occupe de suivre la qualité des données.
Pour rappel, tout indicateur de monitoring doit être actionnable (i.e. s’il indique un problème l’équipe peut agir).
Le monitoring du modèle requiert de toujours stocker toutes les prédictions faites. La métrique la plus intéressante à suivre est celle choisie en phase d’entraînement, la suivre en phase d’inférence permet de s’assurer que le modèle se comporte comme lors du training. Si ce n’est pas le cas, c’est qu’une hypothèse prise se révèle fausse. Cette métrique est proactive, elle permettra de détecter des débuts de concept drift.
La mise en place d'un monitoring technique doit être parcimonieuse : Il faut trouver des sondes pertinentes; trouver un bon équilibre entre feedback loops exhaustives et feedback loops trop nombreuses. Il faut monitorer à tous les niveaux, mais ne pas tout monitorer.
Les erreurs classiques en monitoring
En monitoring, quelques erreurs sont souvent commises, cela est vrai aussi bien en logiciel que en Machine Learning :
- Monitorer uniquement de manière réactive : n’être prévenu que quand le système bogue. Cela vous forcera à être toujours en réaction plutôt qu'en anticipation. Un “bon” monitoring permet d’avoir des signes d’approche de zones critiques
- Monitorer sur un pan trop réduit de l’application : monitorer prédiction par prédiction n’a pas de sens en ML. (NB : Fournir une explication prédiction par prédiction peut être intéressant, voir cet article sur l’interprétabilité)
- Se concentrer sur des optimisations locales : se focaliser uniquement sur la justesse des prédictions sans regarder les impacts business peut pousser aux optimisations locales plutôt que globales.
- Tout monitorer : vous serez très vite noyé sous la quantité de signal.
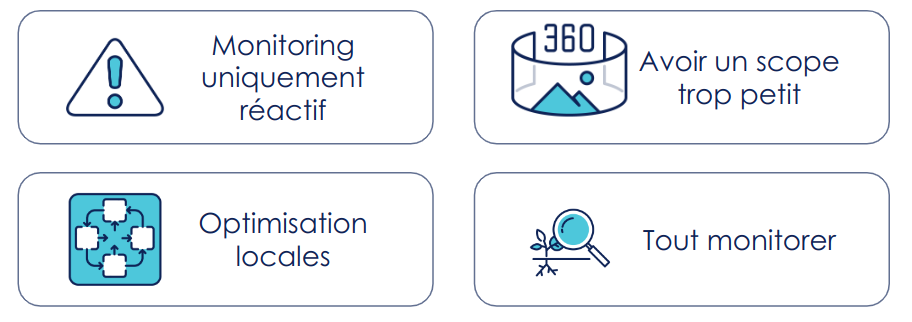
Figure 9 : Les 4 erreurs classiques en monitoring
Du monitoring à la notification proactive
Avoir des métriques pertinentes est une grosse première étape, mais n’est pas suffisante pour être informé au plus tôt d’un dysfonctionnement, il faut mettre en place des alertes ou des notifications proactives.
“Proactive Notification : Cette aptitude s’intéresse aux alertes mises en place sur notre SI afin d’assurer la détection des anomalies. Nous cherchons à valider que les erreurs de production (dépassement d’un seuil, variation trop importante d’une métrique…) remontent bien des alertes aux personnes susceptibles de résoudre le problème et que seules les alertes nécessitant une intervention humaine sont remontées. L’objectif est que le SI soit suffisamment bien monitoré pour qu’aucune anomalie ne soit remontée par les utilisateurs sans que les équipes ne soient au courant avant.” (source)
Choisir des seuils d’alertes pertinents
En Machine Learning il est impossible de mettre un critère “telle erreur d’inférence ne se produit pas” car cette alerte risque de sonner régulièrement sans qu’aucune action ne soit nécessaire. Il faut mettre un critère “telle situation ne se produit pas trop souvent” et il convient de qualifier le “trop”.
Sur les erreurs acceptables, il convient de fixer des seuils, en définissant des SLO / SLA (Service Level Objective / Agreement) avec votre métier. Pour cela, discutez avec eux du niveau minimum acceptable de performance pour votre modèle. Implémentez cette première version puis itérez, s'il y a trop d’alertes, rendez les seuils filtrants, sinon rendez les seuils moins filtrants.
Le niveau suivant peut être de s’intéresser à l’AI Ops, utiliser des modèles de ML pour prédire des valeurs non-normales pour les métriques de monitoring et remonter des alertes. Vous noterez le côté “meta” de cette approche, qui implique qu’il faudra monitorer à son tour ce système.
Sur les erreurs inacceptables, ce sont des problèmes que vous ne pouvez pas détecter seul sinon vous auriez déjà posé un filtre. Il est alors possible d’avoir deux approches : Une approche à base de feedback utilisateur : permettre à l’utilisateur de signaler des erreurs. Ou une approche exploratoire a posteriori pour identifier les erreurs passées non détectées. L’approche exploratoire peut consister à répondre aux questions suivantes (proposées par Google) étant donné un indicateur :
- Ses valeurs sont-elles relativement élevées ou faibles ?
- Est-ce que ses valeurs sont attendues, normales, cohérentes par rapport à votre expérience ?
- Anticipez-vous, dans les prochains jours / semaines, des changements ?
- En quoi ces données sont-elles différentes des rapports historiques ?
- Votre technologie ou votre infrastructure a-t-elle eu un impact sur les chiffres de manière intéressante ou non ?
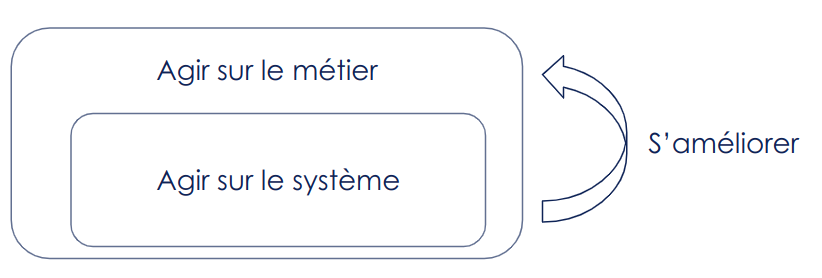
Figure 10 : Exemple d’une alerte automatique dans une messagerie instantanée
Pour les données, même si nous déconseillons le monitoring de distributions dans tous les sens, il est envisageable de créer des alertes lorsque les données en production semblent ne pas suivre la distribution type vue en entraînement :
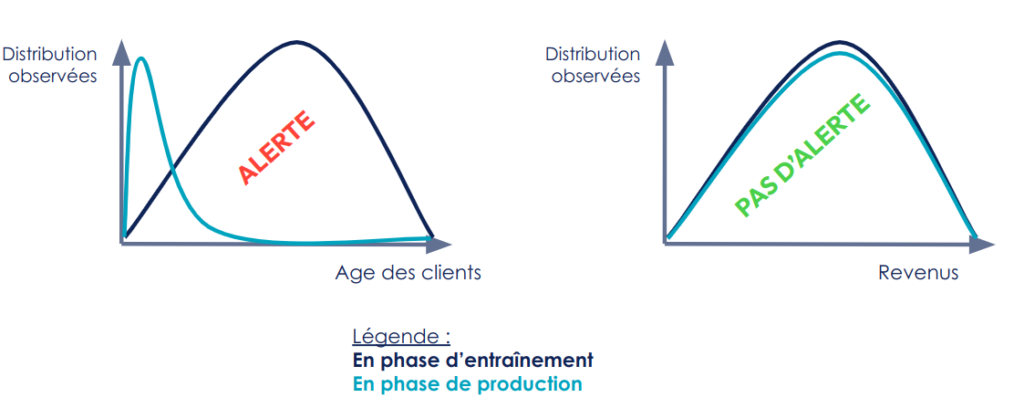
Figure 11 : Exemple de distributions de données causant une alerte ou non
Une fois que vous aurez des alertes, vous rencontrerez les challenges suivants : grouper les alertes qui sont liées au même problème, séparer les alertes qui sont liées à des problèmes différents, tagger les alertes pour suivre les vrais positifs et les faux positifs. Pour approfondir cela, vous pouvez lire le chapitre 16 “Tracking Outages” du livre Site Reliability Engineering.
Les actions permises par une notification
En parallèle de la définition des seuils d’alertes, il convient de définir à qui sont destinées ces alertes, comment les remonter efficacement et les actions à mettre en place suite à une alerte.
Les personnes recevant les alertes doivent être des personnes qui peuvent agir, les alertes doivent remonter dans des canaux régulièrement consultés (tel que mail, messageries instantanées) et non pas “cachées” dans une interface que personne ne regarde.
Figure 12 : Les 3 grands leviers d’actions post-alertes
Les alertes peuvent permettre les actions suivantes :
Agir sur le système :
- En cas d’erreurs inacceptables : mettre des règles métiers qui bornent les prédictions. Ex: mettre un range de prédiction acceptable et au-delà soit ne pas servir la prédiction, soit la limiter.
- En cas d’erreurs acceptables : debugger (cet article l’aborde en détail) ou réentraîner. Le réentraînement est d’ailleurs la solution la plus courante pour améliorer les performances du modèle. Ce réentraînement peut nécessiter un travail exploratoire sur les données, une modification de la base d’entraînement, etc.
Agir sur le métier en choisissant de pivoter la fonctionnalité servie par le modèle ou l’arrêter.
- Exemple 1 : Ne pas mettre à disposition le modèle de tous les utilisateurs mais uniquement les abonnées payants.
- Exemple 2 : Ne plus chercher à prédire l'occurrence le remboursement complet d’un crédit mais prédire qu’il n’y aura pas de retard de remboursement dans la première année.
S’améliorer : en faisant des post-mortem; afin de comprendre comment une telle erreur est arrivée, identifier des actions à mettre en place pour limiter les risques de nouvelles alertes ou augmenter la résilience du système, et potentiellement alimenter les prochaines expérimentations sur le modèle.
À la lecture de cette partie, vous pouvez noter que la description des actions post-alertes est bien plus simple que la description de la méthode pour avoir des alertes pertinentes. Cela est sans doute dû au fait que face à la complexité des problèmes que l’on résout, déboguer est souvent rédhibitoire et nous choisissons de refaire une phase d’entraînement en modifiant les données en espérant que le problème sera ainsi résolu.
Conclusion
Les éléments suivants sont essentiels à une surveillance efficace :
- La collecte de données provenant de domaines clés tout au long de la chaîne de valeur, notamment les performances des applications et l'infrastructure. En ML, stocker toutes les inférences réalisées
- Utiliser les données de monitoring collectées pour agir sur l’infrastructure, le modèle et pour prendre des décisions métier ou stratégiques.
Il convient de monitorer à tous les niveaux, mais de ne pas tout monitorer.
Une idée pour aller plus loin serait de mettre à disposition les métriques d’erreur aux utilisateurs (tel que proposé dans cet article)
Remerciements : Wassel Alazhar pour les nombreuses discussions qui ont permis d’aboutir à cet article. Sofia Calcagno, pour ses relectures et ses conseils qui ont contribué grandement à la qualité de cet article. Aurélien Massiot, Vincent Lafosse, Philippe Prados, Roberto Duarte, Godefroy Clair, Thu Hien Nguyen et Philippe Stepniewski pour leurs relectures.
Cet article fait partie de la série “Accélérer le Delivery de projets de Machine Learning”, traitant de l’application d’Accelerate [1] dans un contexte incluant du Machine Learning. Si vous n’êtes pas familier avec Accelerate, ou si vous souhaitez avoir plus de détails sur le contexte de cet article, nous vous invitons à commencer par lire l’article introduisant cette série. Vous y trouverez également le lien vers le reste des articles pour aller plus loin.