MLOps : En phase de run, le toil est un ennemi à regarder dans les yeux
De décembre à mars, nos experts OCTO vous proposent un cycle de contenus autour de la data et de l’IA. Le sujet vous intéresse ? Pour découvrir le programme et ne rien rater, inscrivez-vous sur notre page Intelligence Artificielle & Data Science.

Certaines organisations ont maintenant passé le cap de la mise en production des modèles de Machine Learning. Elles se retrouvent alors confrontées à un nouveau défi : le toil.
Dans cet article, nous parlerons de produits comportant une brique de Machine Learning, que nous appellerons Produits ML.
Si le nombre de personnes qui opèrent vos produits ML en phase de run est proportionnel au nombre de produits ML en production ; si la vitesse de développement de nouvelles fonctionnalités s’est écroulée au moment du passage en production ; le toil vous a, vous aussi, déjà paralysé sans que vous ne vous en rendiez compte.
Le run, une phase différente dans le cycle de vie d’un produit ML
Commençons par définir la phase de run d’un produit ML. La phase de run est vue différemment selon le point de vue des développeurs (data engineer/scientist, ML engineer, etc.) versus des managers.
Du côté des développeurs, le run, c’est quand le produit est en production : autrement dit, quand il y a au moins un utilisateur. Cette limite est parfois floue, puisqu’il est possible d’avoir des utilisateurs pendant que l’application est développée (c’est d’ailleurs recommandé).
Du côté des managers, le run, c’est quand le budget n’est plus des CAPEX mais des OPEX : autrement dit, le run, est la phase de retour sur investissement après une phase d’investissement. Pour rentabiliser l’investissement, il faut donc que le produit soit fiable, facile à opérer, ait un coût opérationnel limité.
Ces deux enjeux s’ajoutent puisqu’en phase de run, il faut continuer à développer de nouvelles fonctionnalités pour satisfaire les utilisateurs, tout en étant rentable.
D’un point de vue organisationnel, il existe deux modèles pour assurer le run :
- Le “You build it you run it” : l’équipe qui construit le produit, le run aussi,
- Le “centre de service” : l’équipe qui construit le produit transmet le run à une autre équipe.
Dans le premier cas, l’objectif est que les équipes puissent dégager du temps pour travailler sur d’autres fonctionnalités ou projets, dans l’autre cas l’objectif est de minimiser la taille de l’équipe nécessaire. Pourtant, de nombreuses équipes subissent une charge de run proportionnelle au nombre de modèles, d’utilisateurs, etc. Elles subissent de plein fouet le toil.
Le toil, nouvel ennemi au bestiaire
Le toil, à combattre comme le basilic, est un ensemble de tâches associées au run. Cette section explicite le sens de ce mot.
Signifiant labeur en français, le toil a été introduit par les équipes SRE de Google. Elles distinguent 3 types de tâches qui occupent une équipe :
- Le développement : la création de nouvelles fonctionnalités, les automatisations, etc.
- L’overhead : l’ensemble des activités administratives qui ne sont pas liées à la production et ne sont pas du développement. Par exemple, participer à des réunions, se connecter aux outils de travail, poser ses congés, etc.
- Et enfin le toil, l’ensemble des tâches liées à l’exploitation d’un service en production. Elles peuvent être répétitives, manuelles, automatisables, elles ne changent pas le service rendu par le système, elles peuvent augmenter de façon linéaire avec le nombre d’utilisateurs.

Voici quelques exemples de toil que nous avons rencontrés dans des équipes “ML” :
Exemple 1 : Réaliser des prédictions par batchs réguliers sur le laptop du data scientist.
- Cet exemple a notamment été vu dans des équipes de data science réalisant une sélection de clients pour des campagnes marketing.
- Cette tâche requiert de récupérer le modèle (ou le reconstruire), les données à jour, le code, et une fois la prédiction faite, l’envoyer aux équipes idoines.
Exemple 2 : Réentraîner manuellement un modèle de machine learning.
- Cet exemple a été vu dans des équipes qui, après avoir mis en production des modèles de détection de défaut sur des images, doivent réentraîner les modèles pour prendre en compte des nouveaux contextes.
- Cette tâche requiert alors de configurer la machine pour avoir un environnement qui permet de réaliser l’entraînement (version de package, variable d’environnement, les nouvelles données d'entraînement à télécharger de la production, etc.) Cela consiste souvent à lancer 15 lignes de commande d’affilée depuis l’historique de son terminal.
Exemple 3 : Mesurer manuellement dans un notebook la performance de modèles en production.
- Cet exemple a été vu lorsqu'un sponsor demande quelques mois plus tard si le modèle marche comme prévu.
- Cette tâche requiert alors de récupérer l’historique de prédiction, trouver la prédiction idéale, et récupérer le code d’évaluation (voire de le réimplémenter).
Ces exemples sont centrés sur le ML, mais comme un produit de ML embarque souvent beaucoup de data engineering, les tâches de toils sont aussi souvent liées aux données, par exemple la correction de problèmes de qualité.
Voici quelques exemples qui ne relèvent pas du toil :
- (overhead) Se connecter au VPN de l’entreprise
- (overhead) Relancer Teams pour la 8 ème fois
- (développement) Créer un dockerfile pour conteneuriser mon application
Les dégâts causés par le toil
Le toil dans l’absolu n’est pas mauvais. À petite dose, il peut être satisfaisant pour les équipes : par exemple, déployer manuellement en production un modèle peut donner la satisfaction du travail accompli ou donner un sentiment de maîtrise. De même, réentraîner un modèle à la main peut être gratifiant. Le problème vient de la quantité de ces tâches : dans ce dernier cas, si les données sont mises à jour une fois par an, le réentraînement manuel est adapté, en revanche si elles sont mises à jour régulièrement, cela ne l’est plus. Les coûts peuvent être alors :
Un coût en termes de ressources humaines, le toil va causer une corrélation entre le nombre de modèles en production, le nombre d’utilisateurs et le nombre de personnes nécessaires dans l’équipe. Des exemples sont :
- Le déploiement d’un produit ML dans une nouvelle région du monde qui requiert de staffer une nouvelle équipe d’une taille similaire.
- Lorsque l’équipe de run fait la même taille que l’équipe qui a développé le modèle.
Un coût sur l’équipe, Google relève que le toil à trop forte dose cause de la démotivation, de la confusion, de la perte de confiance en soi, un ralentissement de l’équipe, une hausse du turnover.
Dans le cas où l’équipe assure son propre run, l’équipe subit un coût de délai (cost of delay) pour les nouvelles fonctionnalités. Ce coût désigne le manque à gagner de ne pas faire la fonctionnalité maintenant. Par exemple :
- Une obligation réglementaire impose de développer une fonctionnalité avant le JJ/MM/YYYY, si cette date est dépassée une forte amende est infligée.
- Une fonctionnalité peut rapporter XXX € / jours, la perte est donc un multiple du temps d’attente * le ROI journalier.
Un coût dû aux erreurs humaines : Les tâches manuelles sont sujettes aux erreurs, si une erreur rend le service inutilisable pendant plusieurs heures / jours, le préjudice peut être important.
Google recommande, pour une équipe de SRE, de ne pas dépasser 50% de toil. Ce % est à adapter en fonction de la volonté de développement de nouveaux produits par l’équipe. Le même pattern peut s’appliquer aux équipes MLOps : au-delà de 50%, l’équipe n’a pas assez d’efficacité opérationnelle pour faire évoluer son produit ou en créer d’autres.
Comment évolue le toil ?
Le toil est souvent difficile à visualiser, car c’est une accumulation de petites tâches. Regardons alors son complémentaire : le temps passé à créer de la valeur métier.
Commençons avec l’hypothèse simplificatrice que le toil est constant, étant donné une équipe qui passe X % de son temps à créer de la valeur métier, elle est confrontée à un choix, est-ce que cette semaine, je diminue la valeur métier produite pour automatiser une tâche de toil, ou est-ce que je fais une User Story de plus ? Dans le choix de la User Story, l’équipe se retrouve sur le scénario bleu clair pointillé, dans le cas de la tâche de toil l’équipe se retrouve sur le scénario bleu foncé.
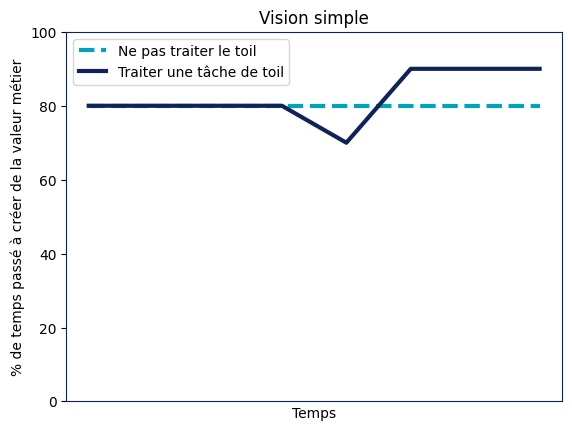
Traiter du toil peut-être d’outiller le débugging en ajoutant des logs ou des métriques calculées automatiquement ; de faciliter le monitoring en mettant en place un outil facilitant l’annotation de données ; en récoltant des métadonnées permettant de sélectionner facilement les images (par exemple les voitures vertes) pour un réentraînement ; de configurer automatiquement l’environnement d’entraînement de modèle.
En fait, comme annoncé, cette vision est très simpliste, le toil a tendance à augmenter au fur et à mesure que des modèles sont déployés en production, que l’application de ML est déployée dans plus de pays, d'usines, de régions, etc. En effet, plus il y a de modèles en production, plus il y a de tâches de monitoring ou de ré-entraînement à réaliser. 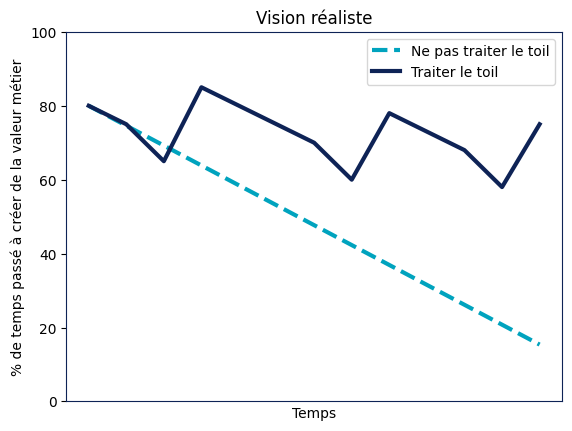
Dans le scénario bleu clair en pointillés, le toil s’accumule jusqu’à atteindre une paralysie totale. Dans le scénario bleu foncé en trait plein, en traitant régulièrement le toil, l’équipe parvient à maintenir le rythme des fonctionnalités.
Finalement, l’évolution du toil au sein d’une équipe dépend des choix qui sont effectués au quotidien, dont certains peuvent avoir un effet papillon sur la phase de run. Mais alors, pourquoi faire des mauvais choix, si le toil qui en découle est inexorable ?
Les larves du toil
Comme dit en introduction, certaines organisations ont passé le cap de la mise en production des modèles de ML. Comme entrer dans la chambre des secrets, passer la mise en production était un objectif difficile à atteindre qui a occupé les équipes pendant longtemps. Et c’est normal : un produit ML est différent d’un produit sans ML dû à l’interdépendance entre code, modèles et données. Dès lors, tous les écueils classiques des produits informatiques sans ML, mais aussi ceux liés au ML peuvent être rencontrés.
Les constats que nous avons régulièrement faits sont :
Un manque de compétence dans les équipes :
- Les Data Scientists n’étant pas toujours formés à l’architecture logicielle réalisent des choix qui s’avèrent limitants à long terme. Par exemple : mettre en production des notebooks.
- Les DS n’étant pas formés aux pratiques du logiciel, mettent en production un code peu efficace, mal testé, difficile à entretenir et plein de bugs.
Pour éviter cela, il convient de constituer des équipes pluridisciplinaires, de sensibiliser les DS à ces problématiques, de mettre à disposition un coaching.
Une peur face au non-déterminisme introduit par l’entraînement des modèles, pour le maîtriser les équipes fuient parfois l’automatisation. Il convient de prendre conscience que ce non-déterminisme reste cantonné à l’entraînement du modèle (et dans quelques rares cas à l’inférence) et l’automatisation peut s’appliquer à tout le reste : par exemple le déploiement de l’API, le monitoring des performances du modèle.
Le shadow IT : face à l’apparente lenteur ou les contraintes de l’IT qui doit répondre à des besoins opérationnels, les équipes IA classifiées comme innovantes choisissent de ne pas capitaliser sur les outils existants. Les exemples sont nombreux : pas de chaîne de CI/CD, pas d’environnement de développement, utiliser un cloud provider différents de l’IT, acheter des cartes graphiques et les faire tourner dans un placard, etc.
Les raccourcis pris pour séduire au plus vite les métiers : ils peuvent être des sacrifices sur la qualité du code, sur la rigueur scientifique dans la construction du modèle, etc. Pire encore, une fois le métier séduit, il souhaite avoir le démonstrateur en production demain. De peur de le décevoir, ou par manque de sensibilisation aux enjeux de la production, d’autres raccourcis sont pris.
Tous ces choix, toutes ces raisons sont valables, mais nous en avons parfois oublié que la 1ʳᵉ Mise En Production (MEP) n’est pas une fin en soi : il y a une vie après la 1ʳᵉ MEP. Ce n’est même que le début d’une longue aventure, la continuité d’une succession de choix à effectuer. Il est donc important de prendre conscience de ce qu’impliquent ces choix, puis, comme le veut l’expression, “il faut payer sa dette” a posteriori.
Combattre le toil
Combattre le toil est un combat de tous les jours, ou au moins de tous les sprints. Il faut s’intéresser à cette bataille à partir du moment où une application est en production. Même si la première mise en production date d’il y a longtemps, il n’est jamais trop tard, car plus vous passerez à l’échelle, plus le problème sera important.
Pour le combattre, la première étape est de le rendre visible, de le factualiser : Quelles tâches relèvent du toil ? Comment les catégoriser ? Combien de temps prennent-elles ?
NB : Même si en première approche, une estimation au doigt mouillé peut apporter beaucoup, le suivi du temps pris par ces tâches doit se faire dans le temps, et donc idéalement être automatisé, par exemple en loggant les tâches dans votre kanban avec un tag dédié.
Ensuite, il convient de prioriser les tâches à réduire en priorité. Ne traiter le sujet que si le coût d’automatisation est strictement inférieur au temps gagné pour réaliser la tâche * nombre de fois que la tâche sera réalisée sur les N prochaines années.
Ce type de tableau peut alors être produit :
| Tâche de toil | Temps pour la réalisation | Fréquence de réalisation | % d’erreur ou d’échec | Coût d’infrastructure supplémentaire | Coût d’automatisation | Priorité |
|---|---|---|---|---|---|---|
| T1 | 1h | 1 an | 10% | 0€ | 5 jours | + |
| T2 | 2h | 1 semaine | 5% | 0€ | 10 jours | ++ |
| T3 | 1h | 1 jour | 5% | 10k€ | 15j | +++ |
| T4 | 10min | 1 jour | 50% | 1k€ | 5 jours | ++++ |
Seront alors traitées en premier les tâches qui ont un ROI important, ou celles qui sont à faible risque, faible coût, faible stress et gratifiante pour l’équipe afin de lancer la dynamique.
Pour les traiter, les solutions sont classiques :
- Supprimer la tâche en transformant un processus.
- Automatiser tout ou partie de celle-ci.
Notons tout de même que la meilleure façon de combattre le toil est de ne pas le créer. Privilégier le pragmatisme et la simplicité en phase de build est la garantie de minimiser la quantité de choses à maintenir en production et donc de minimiser le toil.
Conclusion
Alors, terminerez-vous pétrifié ou vainqueur du basilic ? N’oubliez pas l’amélioration continue à chaque itération pour gagner en efficacité opérationnelle, sinon le toil vous paralysera et vous empêchera de développer de nouvelles fonctionnalités ou de nouveaux produits.
Les choix effectués impliquent un toil plus ou moins important. En particulier, les mauvais choix peuvent être dûs à un manque de recul, de la pression, un besoin utilisateur mal exprimé ou mal compris, etc. Et c’est normal, car le MLOps est une discipline en train de se construire, évolutive et mouvante. Après tout, les paradigmes de cet écosystème changent, les pratiques évoluent, et il faut dès lors prendre d’autant plus de temps à peser les choix en amont du développement, pendant le développement, mais aussi en phase de run.
Concevoir des produits ML adaptés, c’est aussi prendre le temps de les faire évoluer, de les simplifier. Quitte à supprimer des lignes de code ou changer des briques logicielles, car deux pas en arrière peuvent permettre de faire trois pas en avant. Ce n’est pas grave de décommisionner une fonctionnalité qui a coûté 100k€, si elle ne correspond plus à un besoin des utilisateurs. Après tout, Antoine de Saint-Exupéry disait : “La perfection est atteinte, non pas lorsqu'il n'y a plus rien à ajouter, mais lorsqu'il n'y a plus rien à retirer. “
Remerciements à nos relecteurs : Matthieu Lagacherie, Thomas Pesneau, Julien Alexandre, Mehdi Houacine, Maxime Gatineau, Godefroy Clair
Pour tout savoir sur les enjeux Data & IA, rendez-vous sur notre page dédiée. Découvrez aussi La Grosse Conf, la conférence Data & IA by OCTO qui pose un cadre à la mesure des enjeux. Programme, infos et billetterie sur lagrosseconf.com.